As you review the content in this book and work toward earning that 5 on your AP STATISTICS exam, here are five things that you MUST know:
1
Graders want to give you credit—help them! Make them understand what you are doing, why you are doing it, and how you are doing it. Don’t make the reader guess at what you are doing.
• Communication is just as important as statistical knowledge!
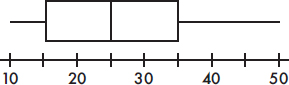
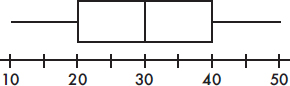
• Be sure you understand exactly what you are being asked to do or find or explain.
• Naked or bald answers will receive little or no credit! You must show where answers come from.
• On the other hand, don’t give more than one solution to the same problem—you will receive credit only for the weaker one.
2
Random sampling and random assignment are different ideas!
• Random sampling is use of chance in selecting a sample from a population.
– A simple random sample (SRS) is when every possible sample of a given size has the same chance of being selected.
– A stratified random sample is when the population is divided into homogeneous units called strata, and random samples are chosen from each strata.
– A cluster sample is when the population is divided into heterogeneous units called clusters, and a random sample of the clusters is chosen.
• Random assignment in experiments is when subjects are randomly assigned to treatments.
– This randomization evens out effects over which we have no control.
– Randomized block design refers to when the randomization occurs only within groups of similar experimental units called blocks.
3
Distributions describe variability! Understand the difference between:
• a population distribution (variability in an entire population),
• a sample distribution (variability in a particular sample), and
• a sampling distribution (variability between samples).
• The larger the sample size, the more the sample distribution looks like the population distribution.
• Central Limit Theorem: the larger the sample size, the more the sampling distribution (probability distribution of the sample means) looks like a normal distribution.
4
Check assumptions!
• Be sure the assumptions to be checked are stated correctly, but don’t just state them!
• Verifying assumptions and conditions means more than simply listing them with little check marks—you must show work or give some reason to confirm verification.
• If you refer to a graph, whether it is a histogram, boxplot, stemplot, scatterplot, residuals plot, normal probability plot, or some other kind of graph, you should roughly draw it. It is not enough to simply say, “I did a normal probability plot of the residuals on my calculator and it looked linear.”
5
Calculating the P-value is not the final step of a hypothesis test!
• There must be a decision to reject or fail to reject the null hypothesis.
• You must indicate how you interpret the P-value, that is, you need linkage. So, “Given that P = 0.007, I reject …” isn’t enough. You need something like, “Because P = 0.007 is less than 0.05, there is sufficient evidence to reject …”
• Finally, you need a conclusion in context of the problem.
The contents of this book cover the topics recommended by the AP Statistics Development Committee. A review of each of the 15 topics is followed by multiple-choice and free-response questions on that topic. Detailed explanations are provided for all answers. It should be noted that some of the topic questions are not typical AP exam questions but rather are intended to help review the topic. Finally, there is a diagnostic exam, and there are five full-length practice exams, totaling 276 questions, all with instructive, complete answers. An optional disk contains two new, full-length exams with 92 more questions.
Several points with regard to particular answers should be noted. First, step-by-step calculations using the given tables sometimes give minor differences from calculator answers due to round-off error. Second, calculator packages easily handle degrees of freedom that are not whole numbers, also resulting in minor answer differences. In the above cases, multiple-choice answers in this book have only one reasonable correct answer, and written explanations are necessary when answering free-response questions.
Students taking the AP Statistics Examination will be furnished with a list of formulas (from descriptive statistics, probability, and inferential statistics) and tables (including standard normal probabilities, t-distribution critical values, critical values, and random digits). While students will be expected to bring a graphing calculator with statistics capabilities to the examination, answers should not be in terms of calculator syntax. Furthermore, many students have commented that calculator usage was less than they had anticipated. However, even though the calculator is simply a tool, to be used sparingly, as needed, students should be proficient with this technology.
The examination will consist of two parts: a 90-minute section with 40 multiple-choice problems and a 90-minute free-response section with five open-ended questions and an investigative task to complete. In grading, the two sections of the exam will be given equal weight. Students have remarked that the first section involves “lots of reading,” while the second section involves “lots of writing.” The percentage of questions from each content area is approximately 25% data analysis, 15% experimental design, 25% probability, and 35% inference. Questions in both sections may involve reading generic computer output.
Note that in the multiple-choice section the questions are much more conceptual than computational, and thus use of the calculator is minimal. The score on the multiple-choice section is based on the number of correct answers, with no points deducted for incorrect answers. Blank answers are ignored.
In the free-response section, students must show all their work, and communication skills go hand in hand with statistical knowledge. Methods must be clearly indicated, as the problems will be graded on the correctness of the methods as well as on the accuracy of the results and explanation. That is, the free-response answers should address why a particular test was chosen, not just how the test is performed. Even if a statistical test is performed on a calculator such as the TI-84, formulas should still be stated. Choice of test, in inference, must include confirmation of underlying assumptions, and answers must be stated in context, not just as numbers.
Free-response questions are scored on a 0 to 4 scale with 1 point for a minimal response, 2 points for a developing response, 3 points for a substantial response, and 4 points for a complete response. Individual parts of these questions are scored as E for essentially correct, P for partially correct, and I for incorrect. Note that essentially correct does not mean perfect. Work is graded holistically, that is, a student’s complete response is considered as a whole whenever scores do not fall precisely on an integral value on the 0 to 4 scale.
Each open-ended question counts 15% of the total free-response score and the investigative task counts 25% of the free-response score. The first open-ended question is typically the most straightforward, and after doing this one to build confidence, students might consider looking at the investigative task since it counts more. Each completed AP examination paper will receive a grade based on a 5-point scale, with 5 the highest score and 1 the lowest score. Most colleges and universities accept a grade of 3 or better for credit or advanced placement or both.
While a review book such as this can be extremely useful in helping prepare students for the AP exam (practice problems, practice more problems, and practice even more problems are the three strongest pieces of advice), nothing can substitute for a good high school teacher and a good textbook. This author personally recommends the following texts from among the many excellent books on the market: Stats: Modeling the World by Bock, Velleman, and DeVeaux; The Practice of Statistics by Starnes, Yates, and Moore; Workshop Statistics: Discovery with Data by Rossman and Chance, Introduction to Statistics and Data Analysis by Peck, Olsen, and Devore; and Statistics: The Art and Science of Learning from Data by Agresti and Franklin.
Other wonderful sources of information are the College Board’s websites: www.collegeboard.org for students and parents, and www.apcentral.collegeboard.com for teachers.
A good piece of advice is for the student from day one to develop critical practices (like checking assumptions and conditions), to acquire strong technical skills, and to always write clear and thorough, yet to the point, interpretations in context. Final answers to most problems should be not numbers, but rather sentences explaining and analyzing numerical results. To help develop skills and insights to tackle AP free response questions (which often choose contexts students haven’t seen before), pick up newspapers and magazines and figure out how to apply what you are learning to better understand articles in print that reference numbers, graphs, and statistical studies.
The student who uses this Barron’s review book should study the text and illustrative examples carefully and try to complete the practice problems before referring to the solution keys. Simply reading the detailed explanations to the answers without first striving to work through the problems on one’s own is not the best approach. There is an old adage: Mathematics is not a spectator sport! Teachers clearly may use this book with a class in many profitable ways. Ideally, each individual topic review, together with practice problems, should be assigned after the topic has been covered in class. The full-length practice exams should be reserved for final review shortly before the AP examination.
For reference only.
BAR CHARTS
DOTPLOTS
HISTOGRAMS
STEMPLOTS
CENTER AND SPREAD
CLUSTERS AND GAPS
OUTLIERS
MODES
SHAPE
CUMULATIVE RELATIVE FREQUENCY PLOTS
SKEWNESS
There are a variety of ways to organize and arrange data. Much information can be put into tables, but these arrays of bare figures tend to be spiritless and sometimes even forbidding. Some form of graphical display is often best for seeing patterns and shapes and for presenting an immediate impression of everything about the data. Among the most common visual representations of data are dotplots, bar charts, histograms, and stemplots. It is important to remember that all graphical displays should be clearly labeled, leaving no doubt what the picture represents—AP Statistics scoring guides harshly penalize the lack of titles and labels!
TIP
The first thing to do with data is to draw a picture—always.
TIP
Just because a variable has numerical values doesn’t necessarily mean that it’s quantitative.
Bar charts are useful with regard to categorical (or qualitative) variables, that is, variables that note the category to which each individual belongs. This is in contrast to quantitative variables, which take on numerical values. Sizes can be measured as frequencies or percents.
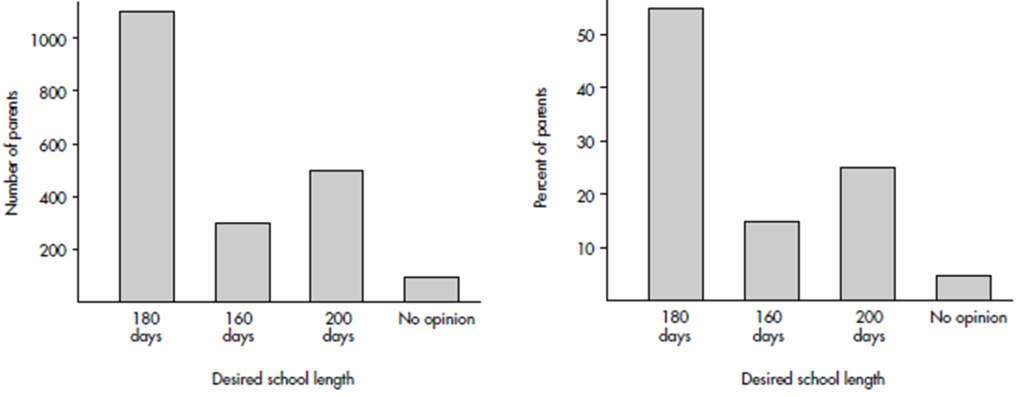
EXAMPLE 1.1
In a survey taken during the first week of January 2015, 1100 parents wanted to keep the school year to the current 180 days, 300 wanted to shorten it to 160 days, 500 wanted to extend it to 200 days, and 100 expressed no opinion. (Or noting that there were 2000 parents surveyed, percentages can be calculated.)
TIP
Graphs must have appropriate labeling and scaling, or they will lose credit!
Dotplots can be used with categorical or quantitative variables.
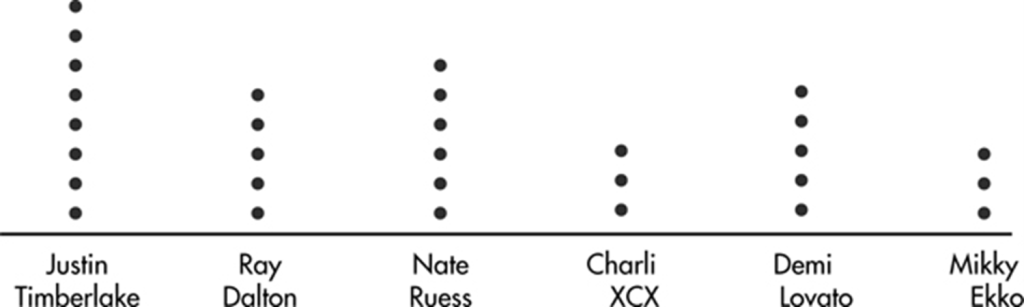
EXAMPLE 1.2
When asked to choose their favorite dance music artist, 8 students chose Justin Timberlake, 5 picked Ray Dalton, 6 picked Nate Ruess, 3 picked Charli XCX, 5 picked Demi Lovato, and 3 picked Mikky Ekko. These data can be displayed in the following dotplot.
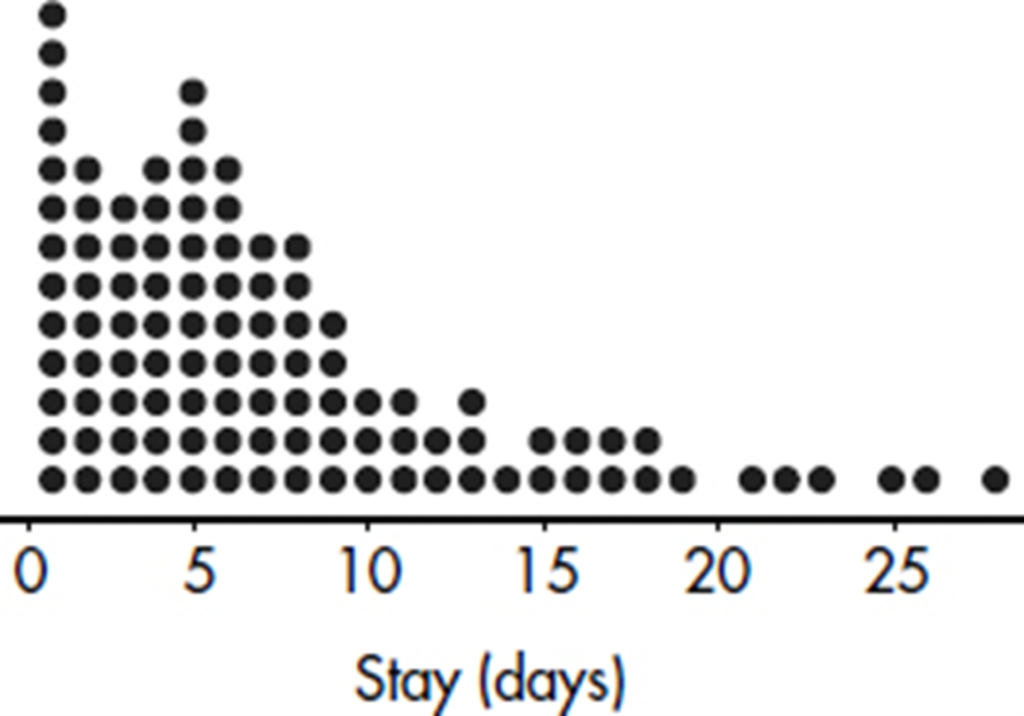
EXAMPLE 1.3
The dotplot below shows the lengths of stay (in days) for all patients admitted to a rural hospital during the first week in January 2015.
Histograms, useful for large data sets involving quantitative variables, show counts or percents falling either at certain values or between certain values. While the AP Statistics Exam does not stress construction of histograms, there are often questions on interpreting given histograms.
To construct a histogram using the TI-84, go to STAT → EDIT and put the data in a list, then turn a STAT PLOT on, choose the histogram icon under Type, specify the list where the data is, and use ZoomStat and/or adjust the WINDOW. Note that XSCL determines the width of the bin or class.
EXAMPLE 1.4
Suppose there are 2200 seniors in a city’s 6 high schools. Four hundred of the seniors are taking no AP classes, 500 are taking one, 900 are taking two, 300 are taking three, and 100 are taking four. These data can be displaced in the following histogram:
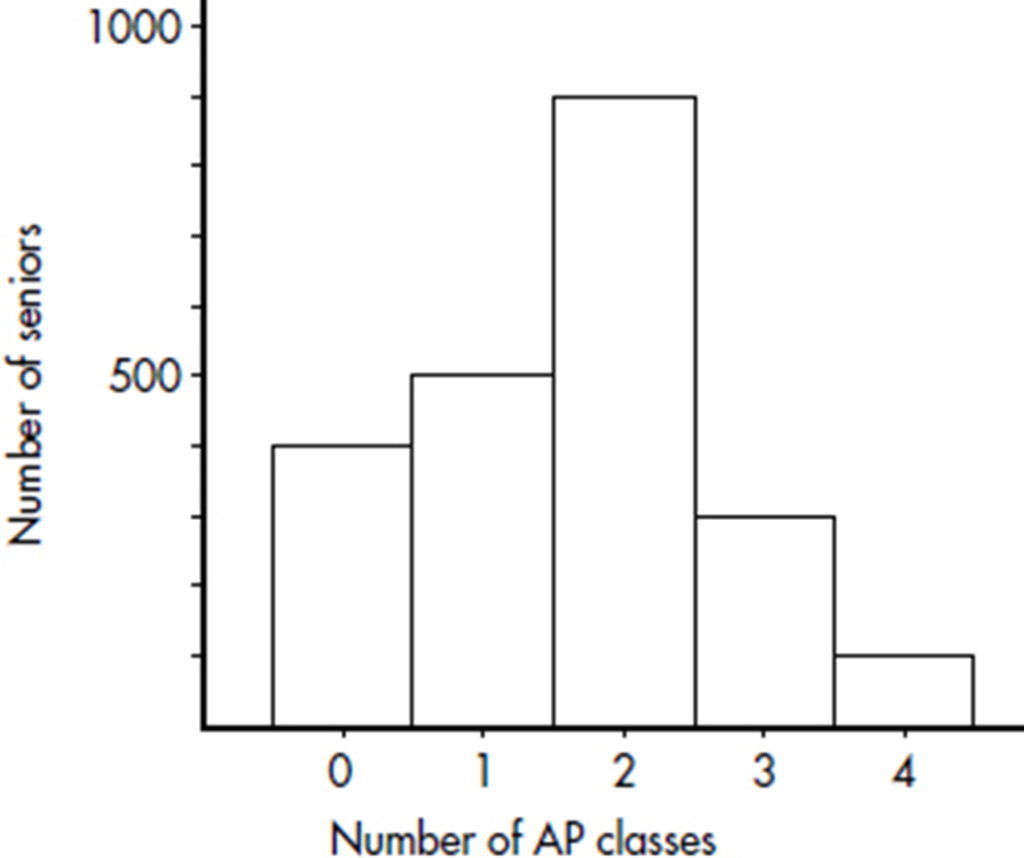
Sometimes, instead of labeling the vertical axis with frequencies, it is more convenient or more meaningful to use relative frequencies, that is, frequencies divided by the total number in the population.
Number of AP classes | Frequency | Relative frequency |
0 | 400 | 400/2200 = 0.18 |
1 | 500 | 500/2200 = 0.23 |
2 | 900 | 900/2200 = 0.41 |
3 | 300 | 300/2200 = 0.14 |
4 | 100 | 100/2200 = 0.05 |
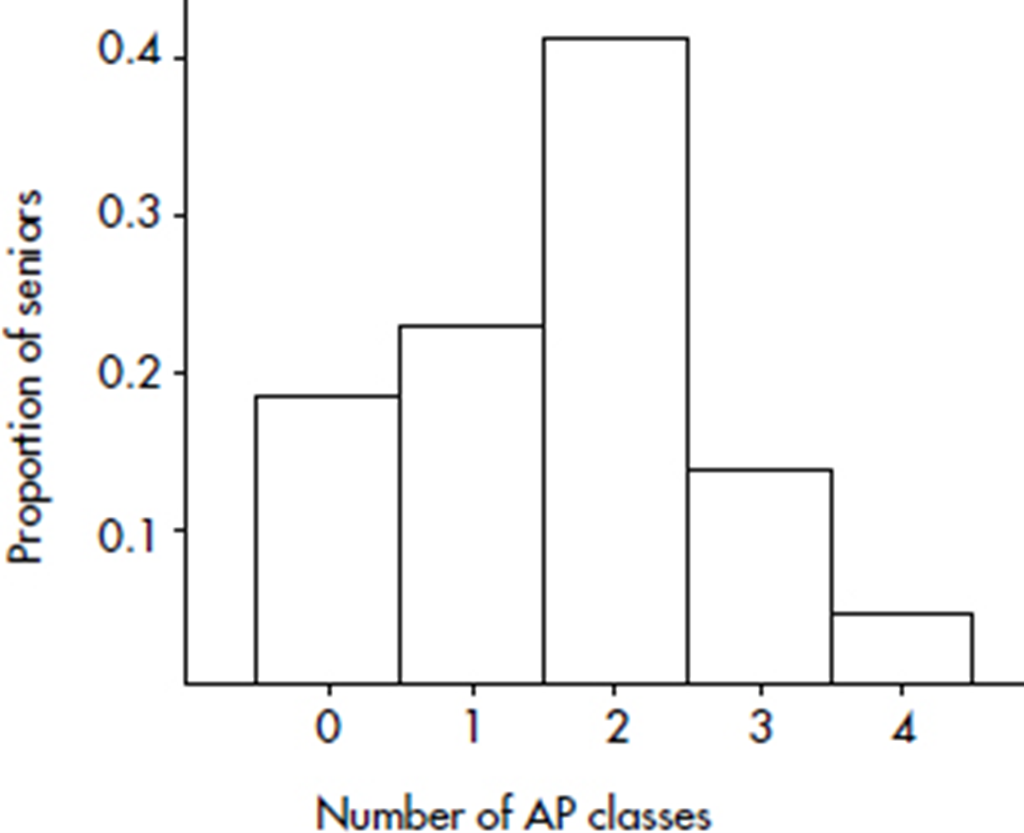
Note that the shape of the histogram is the same whether the vertical axis is labeled with frequencies or with relative frequencies. Sometimes we show both frequencies and relative frequencies on the same graph.
EXAMPLE 1.5
Consider the following histogram of the numbers of pairs of shoes owned by 2000 women.
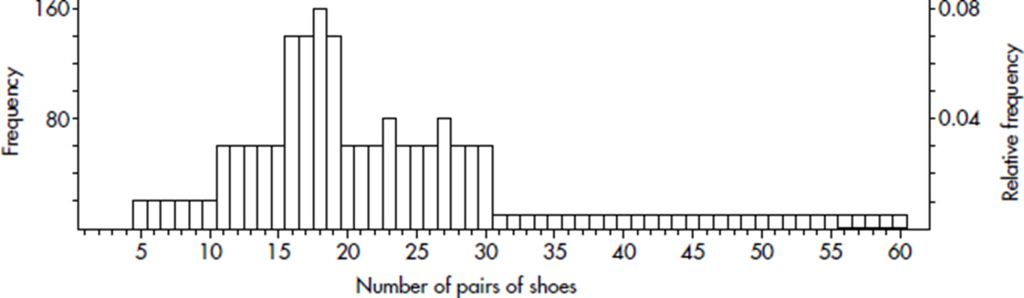
What can we learn from this histogram? For example, none of the women had fewer than 5 or more than 60 pairs of shoes. One hundred sixty of the women had 18 pairs of shoes. Twenty women had 5 pairs of shoes. Half the total area is less than or equal to 19, so half the women have 19 or fewer pairs of shoes. Fifteen percent of the area is more than 30, so 15 percent of the women have more than 30 pairs of shoes. Five percent of the area is more than 50, so 5 percent of the women have more than 50 pairs of shoes.
EXAMPLE 1.6
Consider the following histogram of exam scores, where the vertical axis has not been labeled.
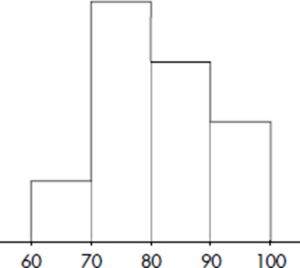
What can we learn from this histogram?
Answer: It is impossible to determine the actual frequencies, that is, we have no idea if there were 25 students, 100 students, or any particular number of students who took the exam. However, we can determine the relative frequencies by noting the fraction of the total area that is over any interval.
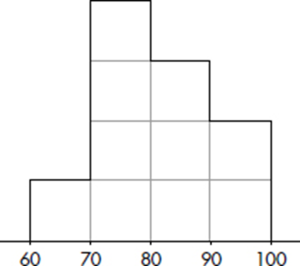
We can divide the area into ten equal portions, and then note that 10% of the area is between 60 and 70, so 10% of the students scored between 60 and 70. Similarly, 40% scored between 70 and 80, 30% scored between 80 and 90, and 20% scored between 90 and 100.
Although it is usually not possible to divide histograms so nicely into ten equal areas, the principle of relative frequencies corresponding to relative areas still applies. Also note how this example shows the number of exam scores falling between certain values, whereas the previous two examples showed the number of AP classes taken and number of shoes owned for each value.
TIP
Relative frequencies are the usual choice when comparing distributions of different size populations.
Although a histogram may show how many scores fall into each grouping or interval, the exact values of individual scores are lost. An alternative pictorial display, called a stemplot (also called a stem-and-leaf display) retains this individual information and is useful for giving a quick overview of a distribution, displaying the relative density and shape of the data. A stemplot contains two columns separated by a vertical line. The left column contains the stems, and the right column contains the leaves.
EXAMPLE 1.7
Bisphenol A (BPA) is an industrial chemical that is found in many hard plastic bottles. Recent studies have shown a possible link between BPA exposure and childhood obesity. In one study of 27 elementary school children, urinary BPA levels in nanograms/milliliter (ng/mL) were as follows: {0.2, 0.4, 0.7, 0.7, 0.8, 0.8, 0.9, 1.0, 1.0, 1.3, 1.4, 1.4, 1.4, 1.7, 1.9, 2.1, 2.4, 2.5, 2.8, 2.8, 3.0, 3.3, 3.3, 3.8, 4.2, 4.5, 5.2}
TIP
All stemplots must have keys!
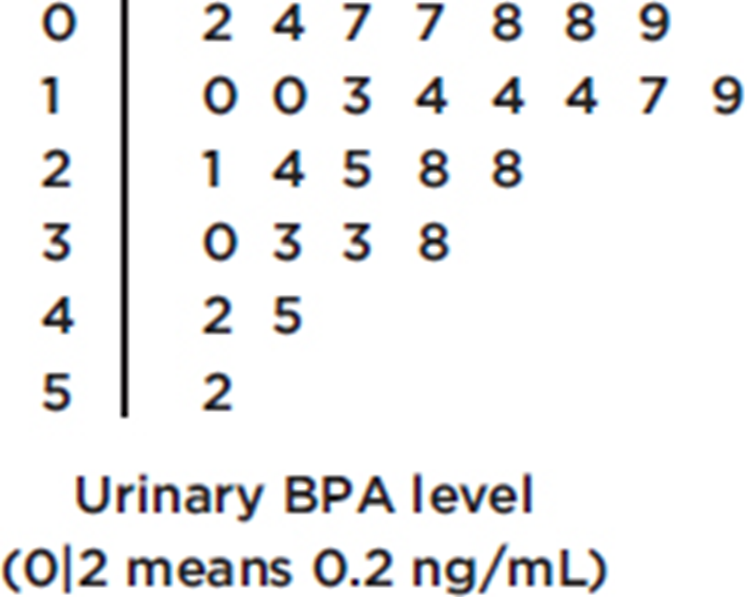
Note: Those with urine BPA level of 2 ng/mL or higher had more than twice the risk of being overweight.
EXAMPLE 1.8
How many nonstop pushups can a 15–18-year-old teenager do? In one study in a mixed gender high school gym class, the numbers of pushups were {2, 5, 7, 10, 12, 12, 14, 16, 16, 18, 19, 20, 21, 29, 32, 34, 35, 37, 37, 38, 39, 39, 42, 44, 50}
TIP
Center and spread should always be described together.
Looking at a graphical display, we see that two important aspects of the overall pattern are
1. the center, which separates the values (or area under the curve in the case of a histogram) roughly in half, and
2. the spread, that is, the scope of the values from smallest to largest.
In the histogram of Example 1.4, the center is 2 AP classes while the spread is from 0 to 4 AP classes.
In the histogram of Example 1.5 the center is about 19, and the spread is from 5 to 60; in the histogram of Example 1.6, the center is about 80, and the spread is from 60 to 100.
In the stemplot of Example 1.7, the center is 1.7 (middle of the 27 values), and the spread is from 0.2 to 5.2; in the stemplot of Example 1.8, the center is 21 (middle of the 25 values), and the spread is from 2 to 50.
Other important aspects of the overall pattern are
1. clusters, which show natural subgroups into which the values fall (for example, the salaries of teachers in Ithaca, NY, fall into three overlapping clusters, one for public school teachers, a higher one for Ithaca College professors, and an even higher one for Cornell University professors), and
2. gaps, which show holes where no values fall (for example, the Office of the Dean sends letters to students being put on the honor roll and to those being put on academic warning for low grades; thus the GPA distribution of students receiving letters from the Dean has a huge middle gap).
EXAMPLE 1.9
Hodgkin’s lymphoma is a cancer of the lymphatic system, the system that drains excess fluid from the blood and protects against infection. Consider the following histogram:
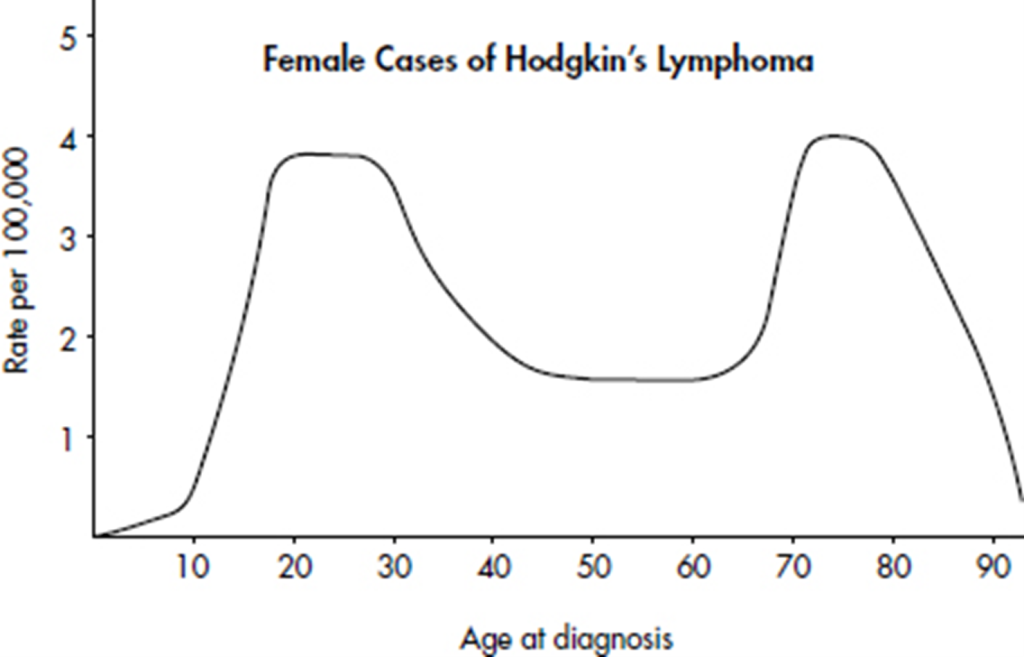
Simply saying that the average age at diagnosis for female cases is around 50 clearly misses something. The distribution of ages at diagnosis for female cases of Hodgkin’s lymphoma is bimodal with two distinct clusters, centered at 25 and 75.
TIP
Pay attention to outliers!
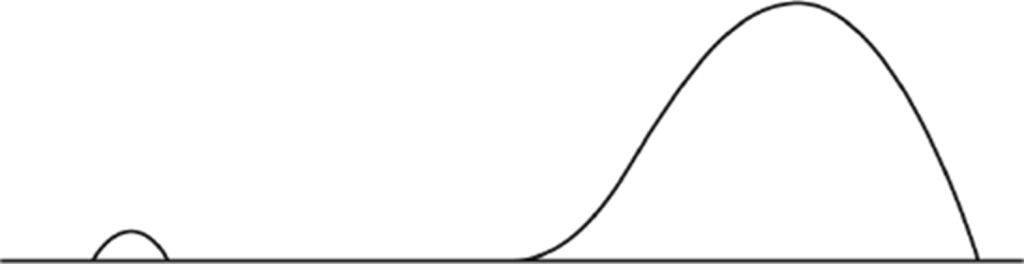
Extreme values, called outliers, are found in many distributions. Sometimes they are the result of errors in measurements and deserve scrutiny; however, outliers can also be the result of natural chance variation. Outliers may occur on one side or both sides of a distribution.
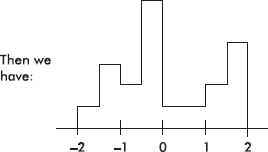
Some distributions have one or more major peaks, called modes. (The values with the peaks above them are the modes.) With exactly one or two such peaks, the distribution is said to be unimodal or bimodal, respectively. But every little bump in the data is not a mode! You should always look at the big picture and decide whether or not two (or more) phenomena are affecting the histogram.
TIP
Some distributions have many little ups (and downs), which should not be confused with modes.
EXAMPLE 1.10
The histogram below shows employee computer usage (number accessing the Internet) at given times at a company main office.

Note that this is a bimodal distribution. Computer usage at this company appears heaviest at midmorning and midafternoon, with a dip in usage during the noon lunch hour. There is an evening outlier possibly indicating employees returning after dinner (or perhaps custodial cleanup crews taking an Internet break!).
Note that, as illustrated above, it is usually instructive to look for reasons behind outliers and modes.
TIP
When describing a distribution, always comment on Shape, Outliers, Center, and Spread (SOCS). Or, alternatively, Center, Unusual values, Shape, and Spread (CUSS). And always describe in context.
Distributions come in an endless variety of shapes; however, certain common patterns are worth special mention:
1. A symmetric distribution is one in which the two halves are mirror images of each other. For example, the weights of all people in some organizations fall into symmetric distributions with two mirror-image bumps, one for men’s weights and one for women’s weights.
2. A distribution is skewed to the right if it spreads far and thinly toward the higher values. For example, ages of nonagenarians (people in their 90s) is a distribution with sharply decreasing numbers as one moves from 90-year-olds to 99-year-olds.
3. A distribution is skewed to the left if it spreads far and thinly toward the lower values. For example, scores on an easy exam show a distribution bunched at the higher end with few low values.
4. A bell-shaped distribution is symmetric with a center mound and two sloping tails. For example, the distribution of IQ scores across the general population is roughly symmetric with a center mound at 100 and two sloping tails.
5. A distribution is uniform if its histogram is a horizontal line. For example, tossing a fair die and noting how many spots (pips) appear on top yields a uniform distribution with 1 through 6 all equally likely.
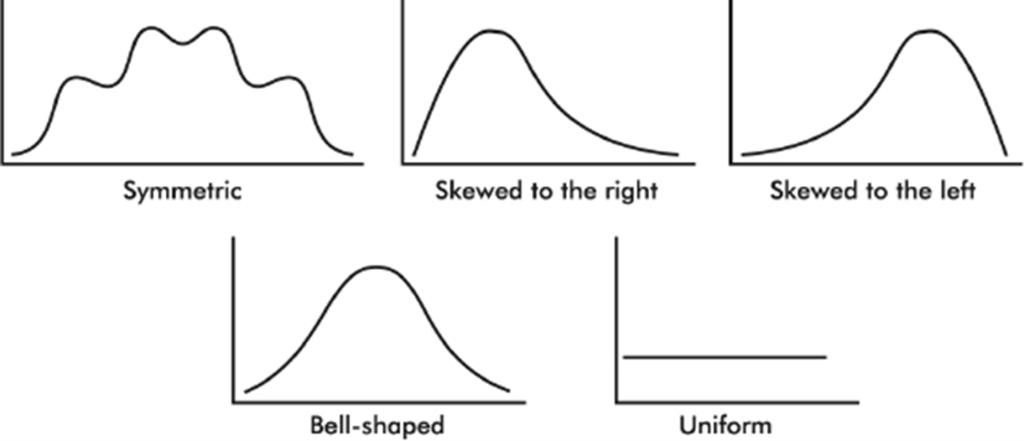
Even when a basic shape is noted, it is important also to note if some of the data deviate from this shape.
TIP
In the real world, distributions are rarely perfectly symmetric or perfectly uniform, so we usually say “roughly” or “approximately” symmetric or uniform.
CUMULATIVE RELATIVE FREQUENCY PLOTS
Sometimes we sum frequencies and show the result visually in a cumulative relative frequency plot (also known as an ogive).
EXAMPLE 1.11
The following graph shows 2015 school enrollment in the United States by age.
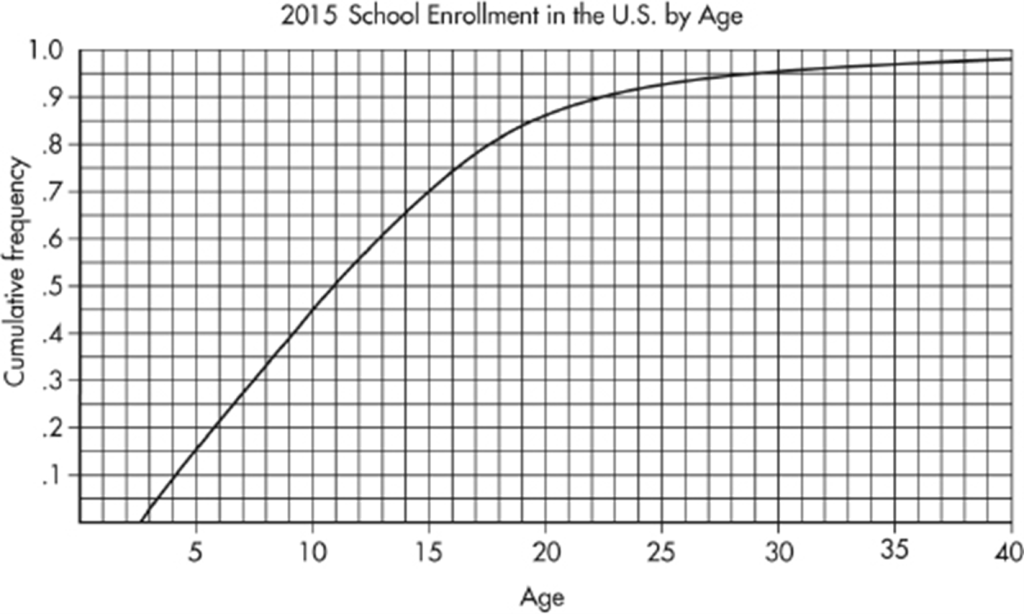
What can we learn from this cumulative relative frequency plot? For example, going up to the graph from age 5, we see that 0.15 or 15% of school enrollment is below age 5. Going over to the graph from 0.5 on the vertical axis, we see that 50% of the school enrollment is below and 50% is above a middle age of 11. Going up from age 30, we see that 0.95 or 95% of the enrollment is below age 30, and thus 5% is above age 30. Going over from 0.25 and 0.75 on the vertical axis, we see that the middle 50% of school enrollment is between ages 6 and 7 at the lower end and age 16 at the upper end.
CUMULATIVE RELATIVE FREQUENCY AND SKEWNESS
A distribution skewed to the left has a cumulative frequency plot that rises slowly at first and then steeply later, while a distribution skewed to the right has a cumulative frequency plot that rises steeply at first and then slowly later.
EXAMPLE 1.12
Consider the essay grading policies of three teachers, Abrams, who gives very high scores, Brown, who gives equal numbers of low and high scores, and Connors, who gives very low scores. Histograms of the grades (with 1 the highest score and 4 the lowest score) are as follows:
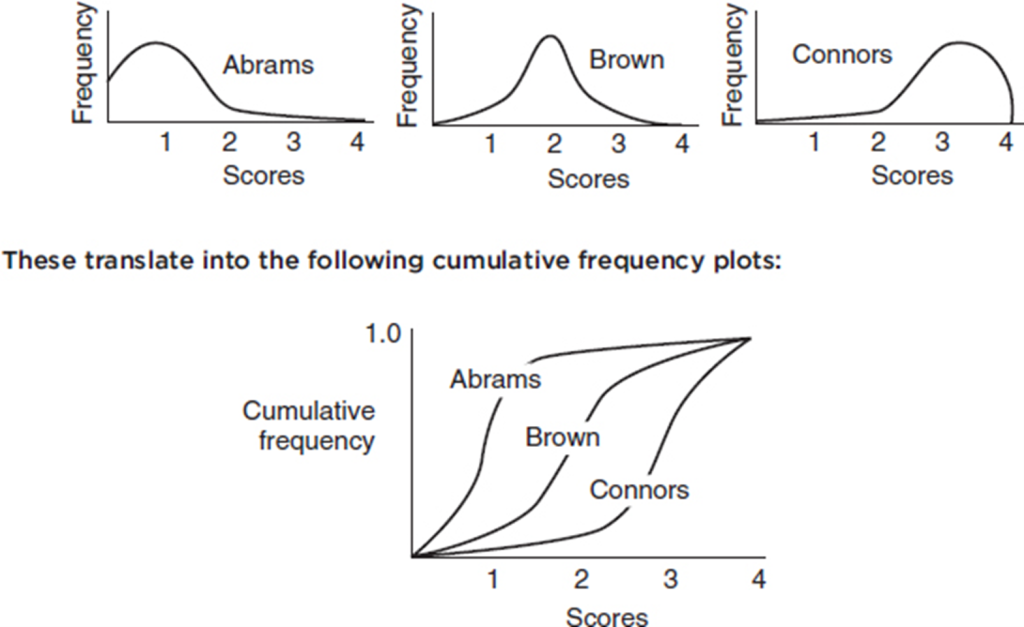
SUMMARY
The three keys to describing a distribution are shape, center, and spread.
Also consider clusters, gaps, modes, and outliers.
Always provide context.
Look for reasons behind any unusual features.
A few common shapes arise from symmetric, skewed to the right, skewed to the left, bell-shaped, and uniform distributions.
For categorical (qualitative) data, dotplots and bar charts give useful displays.
For quantitative data, histograms, cumulative relative frequency plots (ogives), and stemplots give useful displays.
In a histogram, relative area corresponds to relative frequency.
Multiple-Choice Questions
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. The stemplot below shows ages of CEOs of a select group of corporations.

Which of the following is not a correct statement about this distribution?
(A) The distribution is bell-shaped.
(B) The distribution is skewed left and right.
(C) The center is around 60.
(D) The spread is from 22 to 90.
(E) There are no outliers.
2. Which of the following is a true statement?
(A) Stemplots are useful both for quantitative and categorical data sets.
(B) Stemplots are equally useful for small and very large data sets.
(C) Stemplots can show symmetry, gaps, clusters, and outliers.
(D) Stemplots may or may not show individual values.
(E) Stems may be skipped if there is no data value for a particular stem.
3. Which of the following is an incorrect statement?
(A) In histograms, relative areas correspond to relative frequencies.
(B) In histograms, frequencies can be determined from relative heights.
(C) Symmetric histograms may have multiple peaks.
(D) Two students working with the same set of data may come up with histograms that look different.
(E) Displaying outliers may be more problematic when using histograms than when using stemplots.
4. Following is a histogram of test scores.
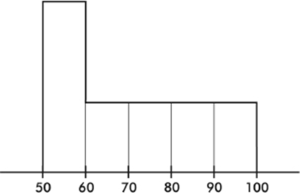
Which of the following is a true statement?
(A) The middle (median) score was 75.
(B) The mean score was 70.
(C) The mean score is probably less than the median score.
(D) If the passing score was 60, most students failed.
(E) More students scored between 50 and 60 than between 90 and 100.
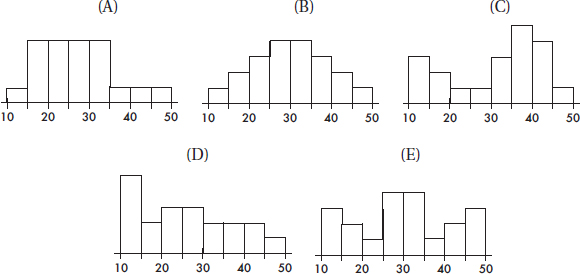
Questions 5–9 refer to the following five cumulative relative frequency plots:
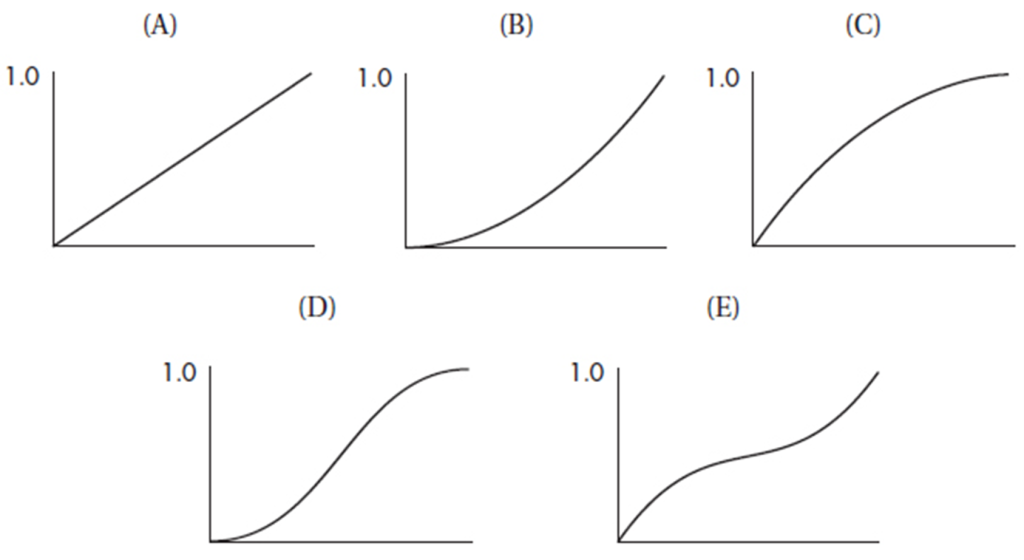
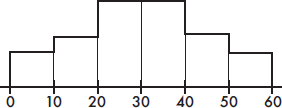
5. To which of the above cumulative relative frequency plots does the following histogram correspond?
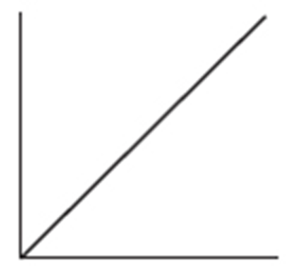
(A) A
(B) B
(C) C
(D) D
(E) E
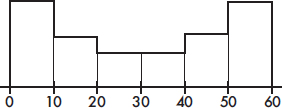
6. To which of the above cumulative relative frequency plots does the following histogram correspond?
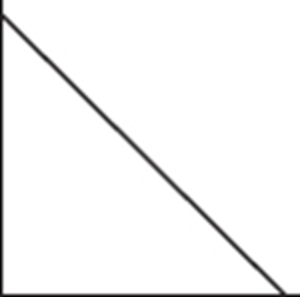
(A) A
(B) B
(C) C
(D) D
(E) E
7. To which of the above cumulative relative frequency plots does the following histogram correspond?
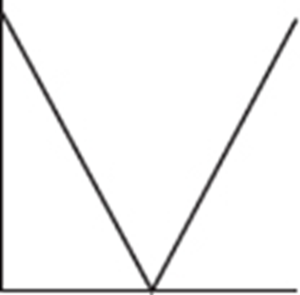
(A) A
(B) B
(C) C
(D) D
(E) E
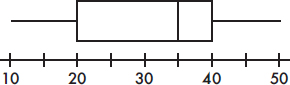
8. To which of the above cumulative relative frequency plots does the following histogram correspond?
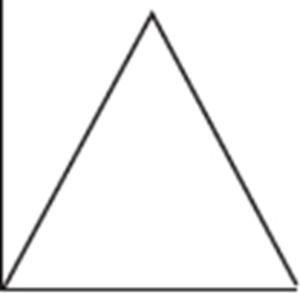
(A) A
(B) B
(C) C
(D) D
(E) E
9. To which of the above cumulative relative frequency plots does the following histogram correspond?

(A) A
(B) B
(C) C
(D) D
(E) E
Free-Response Questions
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your final answers.
THREE OPEN-ENDED QUESTIONS
1. The dotplot below shows the numbers of goals scored by the 20 teams playing in a city’s high school soccer games on a particular day.
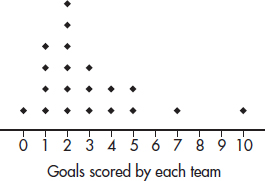
(a) Describe the distribution.
(b) One superstar scored six goals, but his team still lost. What are all possible final scores for that game? Explain.
(c) Is it possible that all the teams scoring exactly two goals won their games? Explain.
2. The winning percentages for a major league baseball team over the past 22 years are shown in the following stemplot:

(a) Interpret the lowest value.
(b) Describe the distribution.
(c) Give a reason that one might argue that the team is more likely to lose a given game than win it.
(d) Give a reason that one might argue that the team is more likely to win a given game than lose it.
3. A college basketball team keeps records of career average points per game of players playing at least 75% of team games during their college careers. The cumulative relative frequency plot below summarizes statistics of players graduating over the past 10 years.
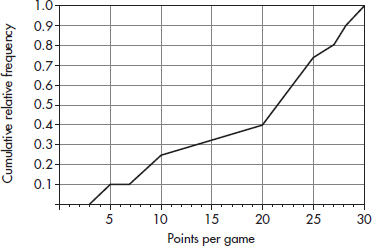
(a) Interpret the point (20, 0.4) in context.
(b) Interpret the intersection of the plot with the horizontal axis in context.
(c) Interpret the horizontal section of plot from 5 to 7 points per game in context.
(d) The players with the top 10% of the career average points per game achievements will be listed on a plaque. What is the cutoff score for being included on the plaque?
(e) What proportion of the players averaged between 10 and 20 points per game?
AN INVESTIGATIVE TASK
A company engineer creates a diagnostic measurement, ![]() , which should be at least 24.10 in a sample of size 12 if certain machinery is operating correctly. To explore this diagnostic measurement, the machine is perfectly calibrated. Then 100 random samples of size 12 of the product are taken from the assembly line. For each of these 100 samples, the diagnostic measurement W is calculated and shown plotted below.
, which should be at least 24.10 in a sample of size 12 if certain machinery is operating correctly. To explore this diagnostic measurement, the machine is perfectly calibrated. Then 100 random samples of size 12 of the product are taken from the assembly line. For each of these 100 samples, the diagnostic measurement W is calculated and shown plotted below.
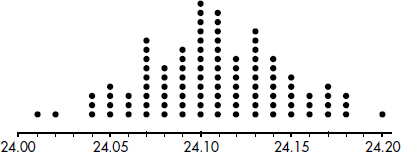
Each day, one sample of size 12 is taken from the assembly line and the diagnostic measurement W is calculated. If W drops too low, a decision to recalibrate the machinery is made.
(a) From the dotplot above, estimate a measure of center and a measure of variability for the distribution.
(b) For the dotplot above, do there appear to be any outliers (no calculations required)? Justify your answer.
One day the random sample is {24.2, 24.84, 25.05, 23.43, 23.9, 25.01, 23.01, 24.5, 24.23, 23.76, 24.69, 23.21}.
(c) Based on the dotplot above, does the engineer have sufficient evidence to conclude that recalibration is necessary? Justify your answer.
MULTIPLE-CHOICE
1. (B) There is no such thing as being skewed both left and right.
2. (C) Stemplots are not used for categorical data sets, are too unwieldy to be used for very large data sets, and show every individual value. Stems should never be skipped over—gaps are important to see.
3. (B) Histograms give information about relative frequencies (relative areas correspond to relative frequencies) and may or may not have an axis with actual frequencies. Symmetric histograms can have any number of peaks. Choice of width and number of classes changes the appearance of a histogram. Stemplots clearly show outliers; however, in histograms outliers may be hidden in large class widths.
4. (E) The median score splits the area in half, and so the median is not 75. The median appears to be about 70 (with equal area on each side), and since the data are skewed right, the mean will be larger than the median, so the mean is greater than 70. The area between 50 and 60 is greater than the area between 90 and 100 but is less than the area between 60 and 100.
5. (B) A histogram with little area under the curve early and much greater area later results in a cumulative relative frequency plot which rises slowly at first and then at a much faster rate later.
6. (C) A histogram with large area under the curve early and much less area later results in a cumulative relative frequency plot which rises quickly at first and then at a much slower rate later.
7. (E) A histogram with little area under the curve in the middle and much greater area on both ends results in a cumulative relative frequency plot which rises quickly at first, then almost levels off, and finally rises quickly at the end.
8. (D) A histogram with little area under the curve on the ends and much greater area in the middle results in a cumulative relative frequency plot which rises slowly at first, then quickly in the middle, and finally slowly again at the end.
9. (A) Uniform distributions result in cumulative relative frequency plots which rise at constant rates, thus linear.
FREE-RESPONSE
1. (a) A complete answer considers shape, center, and spread.
Shape: unimodal, skewed right, outlier at 10
Center: around 2 or 3
Spread: from 0 to 10
(b) If the player scored six goals, his/her team must have scored either 7 or 10, but they lost, so they scored 7, and the only possible final score is that they lost by a score of 10 to 7.
(c) No, there were six teams that scored exactly two goals, but there were only five teams that scored less than two goals, so not all the two-goal teams could have won.
2. (a) The lowest winning percentage over the past 22 years is 46.0%.
(b) A complete answer considers shape, center, and spread.
Shape: two clusters, each somewhat bell-shaped
Center: around 50%
Spread: from 46.0 to 55.6%
(c) The team had more losing seasons (13) than winning seasons (9).
(d) The cluster of winning percentages is further above 50% than the cluster of losing percentages is below 50%.
3. (a) 40% of the players averaged fewer than 20 points per game.
(b) All the players averaged at least 3 points per game.
(c) No players averaged between 5 and 7 points per game because the cumulative relative frequency was 10% for both 5 and 7 points.
(d) Go over to the plot from 0.9 on the vertical axis, and then down to the horizontal axis to result in 28 points per game.
(e) Reading up to the plot and then over from 10 and from 20 shows that 0.25 of the players averaged under 10 points per game and 0.4 of the players averaged under 20 points per game. Thus, 0.4 – 0.25 = 0.15 gives the proportion of players who averaged between 10 and 20 points per game.
AN INVESTIGATIVE TASK
(a) The center is roughly between 24.10 and 24.11, and the data are spread from 24.01 to 24.20.
(b) There seems to be two “low” data points, 24.01 and 24.02, and one “high” data point, 24.20. These three data points are distinctly separated from the other points.
(c) For this day’s sample, ![]() A value of 24.03 or less occurred only twice in the 100 samples. Thus, if the machinery was operating properly, a W measurement of 24.03 would be very unusual. The conclusion should be to recalibrate the machine.
A value of 24.03 or less occurred only twice in the 100 samples. Thus, if the machinery was operating properly, a W measurement of 24.03 would be very unusual. The conclusion should be to recalibrate the machine.
MEASURING THE CENTER
MEASURING SPREAD
MEASURING POSITION
EMPIRICAL RULE
HISTOGRAMS
BOXPLOTS
CHANGING UNITS
Given a raw set of data, often we can detect no overall pattern. Perhaps some values occur more frequently, a few extreme values may stand out, and the range of values is usually apparent. The presentation of data, including summarizations and descriptions, and involving such concepts as representative or average values, measures of dispersion, positions of various values, and the shape of a distribution, falls under the broad topic of descriptive statistics. This aspect of statistics is in contrast to statistical analysis, the process of drawing inferences from limited data, a subject discussed in later topics.
MEASURING THE CENTER: MEDIAN AND MEAN
The word average is used in phrases common to everyday conversation. People speak of bowling and batting averages or the average life expectancy of a battery or a human being. Actually the word average is derived from the French avarie, which refers to the money that shippers contributed to help compensate for losses suffered by other shippers whose cargo did not arrive safely (i.e., the losses were shared, with everyone contributing an average amount). In common usage average has come to mean a representative score or a typical value or the center of a distribution. Mathematically, there are a variety of ways to define the average of a set of data. In practice, we use whichever method is most appropriate for the particular case under consideration. However, beware of a headline with the word average; the writer has probably chosen the method that emphasizes the point he or she wishes to make.
In the following paragraphs we consider the two primary ways of denoting an average:
1. The median, which is the middle number of a set of numbers arranged in numerical order.
2. The mean, which is found by summing items in a set and dividing by the number of items.
EXAMPLE 2.1
Consider the following set of home run distances (in feet) to center field in 13 ballparks: {387, 400, 400, 410, 410, 410, 414, 415, 420, 420, 421, 457, 461}. What is the average?
Answer: The median is 414 (there are six values below 414 and six values above), while the mean is
![]()
REMEMBER
Don’t forget to put the data in order before finding the median.
Median
The word median is derived from the Latin medius which means “middle.” The values under consideration are arranged in ascending or descending order. If there is an odd number of values, the median is the middle one. If there is an even number, the median is found by adding the two middle values and dividing by 2. Thus the median of a set has the same number of elements above it as below it.
The median is not affected by exactly how large the larger values are or by exactly how small the smaller values are. Thus it is a particularly useful measurement when the extreme values, called outliers, are in some way suspicious or when we want do diminish their effect. For example, if ten mice try to solve a maze, and nine succeed in less than 15 minutes while one is still trying after 24 hours, the most representative value is the median (not the mean, which is over 2 hours). Similarly, if the salaries of four executives are each between \$240,000 and \$245,000 while a fifth is paid less than \$20,000, again the most representative value is the median (the mean is under \$200,000). It is often said that the median is “resistant” to extreme values.
In certain situations the median offers the most economical and quickest way to calculate an average. For example, suppose 10,000 lightbulbs of a particular brand are installed in a factory. An average life expectancy for the bulbs can most easily be found by noting how much time passes before exactly one-half of them have to be replaced. The median is also useful in certain kinds of medical research. For example, to compare the relative strengths of different poisons, a scientist notes what dosage of each poison will result in the death of exactly one-half the test animals. If one of the animals proves especially susceptible to a particular poison, the median lethal dose is not affected.
Mean
While the median is often useful in descriptive statistics, the mean, or more accurately, the arithmetic mean, is most important for statistical inference and analysis. Also, for the layperson, the average is usually understood to be the mean.
The mean of a whole population (the complete set of items of interest) is often denoted by the Greek letter µ (mu), while the mean of a sample (a part of a population) is often denoted by $\overline{x}$. For example, the mean value of the set of all houses in the United States might be µ = \$56,400, while the mean value of 100 randomly chosen houses might be $\overline{x}$ = \$52,100 or perhaps $\overline{x}$ = \$63,800 or even $\overline{x}$ = \$124,000.
In statistics we learn how to estimate a population mean from a sample mean. Throughout this book, the word sample often implies a simple random sample (SRS), that is, a sample selected in such a way that every possible sample of the desired size has an equal chance of being included. (It is also true that each element of the population will have an equal chance of being included.) In the real world, this process of random selection is often very difficult to achieve, and so we proceed, with caution, as long as we have good reason to believe that our sample is representative of the population.
Mathematically, the mean $ \frac{\sum x}{n}$ where $\sum x$ represents the sum of all the elements of the set under consideration and n is the actual number of elements. $\sum$ is the uppercase Greek letter sigma.
EXAMPLE 2.2
Suppose that the numbers of unnecessary procedures recommended by five doctors in a 1-month period are given by the set {2, 2, 8, 20, 33}. Note that the median is 8 and the mean is $\frac{2+2+8+20+33}{5}=13$ If it is discovered that the fifth doctor also recommended an additional 25 unnecessary procedures, how will the median and mean be affected?
Answer: The set is now {2, 2, 8, 20, 58}. The median is still 8; however, the mean changes to $\frac{2+2+8+20+58}{5}=18$
The above example illustrates how the mean, unlike the median, is sensitive to a change in any value.
EXAMPLE 2.3
Suppose the salaries of six employees are \$3000, \$7000, \$15,000, \$22,000, \$23,000, and \$38,000, respectively.
a. What is the mean salary?
Answer:
$\frac{3000+7000+15000+22000+23000+38000}{6}=18000$
b. What will the new mean salary be if everyone receives a $3000 increase?
Answer:
$\frac{6000+10000+18000+25000+26000+41000}{6}=21000$
Note that \$18,000 + \$3000 = \$21,000.
c. What if everyone receives a 10% raise?
Answer:
$\frac{3300+7700+16500+24200+25300+41800}{6}=19800$
Note that 110% of \$18,000 is \$19,800.
The above example illustrates how adding the same constant to each value increases the mean (and median) by a like amount. Similarly, multiplying each value by the same constant multiplies the mean (and median) by a like amount.
TIP
Understanding variation is the key to understanding statistics.
MEASURING SPREAD: RANGE, INTERQUARTILE RANGE, VARIANCE, AND STANDARD DEVIATION
In describing a set of numbers, not only is it useful to designate an average value but it is also important to be able to indicate the variability or the dispersion of the measurements. An explosion engineer in mining operations aims for small variability—it would not be good for his 30-minute fuses actually to have a range of 10–50 minutes before detonation. On the other hand, a teacher interested in distinguishing better students from poorer students aims to design exams with large variability in results—it would not be helpful if all her students scored exactly the same. The players on two basketball teams may have the same average height, but this observation doesn’t tell the whole story. If the dispersions are quite different, one team may have a 7-foot player, whereas the other has no one over 6 feet tall. Two Mediterranean holiday cruises may advertise the same average age for their passengers. One, however, may have only passengers between 20 and 25 years old, while the other has only middle-aged parents in their forties together with their children under age 10.
There are four primary ways of describing variability or dispersion:
1. The range, which is the difference between the largest and smallest values
2. The interquartile range, IQR, which is the difference between the largest and smallest values after removing the lower and upper quarters (i.e., IQR is the range of the middle 50%); that is, IQR = Q3 – Q1 = 75th percentile minus 25th percentile
3. The variance, which is determined by averaging the squared differences of all the values from the mean
4. The standard deviation, which is the square root of the variance
EXAMPLE 2.4
The monthly rainfall in Monrovia, Liberia, where May through October is the rainy season and November through April the dry season, is as follows:
| Month: | Jan | Feb | Mar | Apr | May | June | July | Aug | Sept | Oct | Nov | Dec | |
| Rain (in.): | 1 | 2 | 4 | 6 | 18 | 37 | 31 | 16 | 28 | 24 | 9 | 4 |
The mean is
$\frac{1+2+4+6++18+37+31++16+28+24+9+4}{12}=15$ inches
What are the measures of variability?
Answer: Range: The maximum is 37 inches (June), and the minimum is 1 inch (January). Thus the range is 37 – 1 = 36 inches of rain.
Interquartile range: Removing the lower and upper quarters leaves 4, 6, 9, 16, 18, and 24. Thus the interquartile range is 24 – 4 = 20. [The interquartile range is sometimes calculated as follows: The median of the lower half is $Q_1=\frac{4+4}{2}=4$ the median of the upper half is $Q_3=\frac{24+28}{2}=26$ and the interquartile range is Q3 – Q1 = 22. When there is a large number of values in the set, the two methods give the same answer.]
Variance:
$\frac{14^2+13^2+11^2+9^2+3^2+22^2+16^2+1^2+13^2+9^2+6^2+11^2}{12}=143.7$
Standard deviation: $\sqrt{143.7}=12.0$ inches
Range
The simplest, most easily calculated measure of variability is the range. The difference between the largest and smallest values can be noted quickly, and the range gives some impression of the dispersion. However, it is entirely dependent on the two extreme values and is insensitive to the ones in the middle.
One use of the range is to evaluate samples with very few items. For example, some quality control techniques involve taking periodic small samples and basing further action on the range found in several such samples.
Interquartile Range
Finding the interquartile range is one method of removing the influence of extreme values on the range. It is calculated by arranging the data in numerical order, removing the upper and lower quarters of the values, and noting the range of the remaining values. That is, it is the range of the middle 50% of the values.
The numerical rule for designating outliers is to calculate 1.5 times the interquartile range (IQR) and then call a value an outlier if it is more than 1.5 × IQR below the first quartile or 1.5 × IQR above the third quartile.
EXAMPLE 2.5
Suppose that the starting salaries (in $1000) for college graduates who took AP Statistics in high school and at least one additional statistics class in college have the following characteristics: the smallest value is 18.8, 10% of the values are below 25.6, 25% are below 41.1, the median is 59.3, 60% are below 84.3, 75% are below 101.9, 90% are below 118.0, and the top value is 201.7.
a. What is the range?
Answer: The range is 201.7 – 18.8 = 182.9 (thousand dollars) = $182,900.
b. What is the interquartile range?
Answer: The interquartile range, that is, the range of the middle 50% of the values, is Q3 – Q1 = 101.9 – 41.1 = 60.8 (thousand dollars) = $60,800.
c. When the numerical rule is used for outliers, should either the smallest or largest value be called an outlier?
Answer: 1.5 × IQR = 1.5 × 60.8 = 91.2. If a value is more than 91.2 below the first quartile, 41.1, or more than 91.2 above the third quartile, 101.9, then it will be called an outlier. Since the largest value, 201.7, is greater than 101.9 + 91.2 = 193.1, it is considered an outlier by the given numerical rule.
Variance
Dispersion is often the result of various chance happenings. For example, consider the motion of microscopic particles suspended in a liquid. The unpredictable motion of any particle is the result of many small movements in various directions caused by random bumps from other particles. If we average the total displacements of all the particles from their starting points, the result will not increase in direct proportion to time. If, however, we average the squares of the total displacements of all the particles, this result will increase in direct proportion to time.
The same holds true for the movement of paramecia. Their seemingly random motions as seen under a microscope can be described by the observation that the average of the squares of the displacements from their starting points is directly proportional to time. Also, consider ping-pong balls dropped straight down from a high tower and subjected to chance buffeting in the air. We can measure the deviations from a center spot on the ground to the spots where the balls actually strike. As the height of the tower is increased, the average of the squared deviations increases proportionately.
In a wide variety of cases we are in effect trying to measure dispersion from the mean due to a multitude of chance effects. The proper tool in these cases is the average of the squared deviations from the mean; it is called the variance and is denoted by $\sigma^2$ ($\sigma$ is the lowercase Greek letter sigma):
$\sigma^2=\frac{\sum(x-\mu)^2}{n}$
For circumstances specified later, the variance of a sample, denoted by s2, is calculated as
$s^2=\frac{\sum(x-\overline{x})^2}{n-1}$
TIP
Most calculators give the standard deviation, and this must be squared to find the variance.
EXAMPLE 2.6
The Points Per Game (PPG) during the 2012–2013 season of the New York Knicks players were {14.2, 28.7, 10.4, 1.8, 6.6, 13.9, 6.0, 18.1, 6.8, 7.0, 8.7, 3.5, 7.2}. What was the variance?
Answer: The variance can be quickly found on any calculator with a simple statistical package, or it can be found as follows:
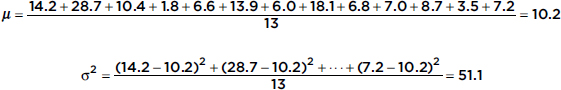
Standard Deviation
Suppose we wish to pick a representative value for the variability of a certain population. The preceding discussions indicate that a natural choice is the value whose square is the average of the squared deviations from the mean. Thus we are led to consider the square root of the variance. This value is called the standard deviation, is denoted by $\sigma$, and is calculated on your calculator or as follows:
![]()
Similarly, the standard deviation of a sample is denoted by s and is calculated on your calculator or as follows:
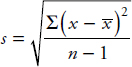
While variance is measured in square units, standard deviation is measured in the same units as are the data.
For the various x-values, the deviations $x-\overline{x}$ are called residuals, and s is a “typical value” for the residuals. While s is not the average of the residuals (the average of the residuals is always 0), s does give a measure of the spread of the x-values around the sample mean.
EXAMPLE 2.7
The number of calories in 12-ounce servings of five popular beers are {95, 152, 188, 205, 131}. Using the TI-84, 1-Var Stats gives
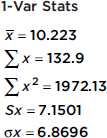
Since these data represent a sample of beers, the standard deviation is 7.1501.
MEASURING POSITION: SIMPLE RANKING, PERCENTILE RANKING, AND Z-SCORE
We have seen several ways of choosing a value to represent the center of a distribution. We also need to be able to talk about the position of any other values. In some situations, such as wine tasting, simple rankings are of interest. Other cases, for example, evaluating college applications, may involve positioning according to percentile rankings. There are also situations in which position can be specified by making use of measurements of both central tendency and variability.
There are three important, recognized procedures for designating position:
1. Simple ranking, which involves arranging the elements in some order and noting where in that order a particular value falls
2. Percentile ranking, which indicates what percentage of all values fall below the value under consideration
3. The z-score, which states very specifically by how many standard deviations a particular value varies from the mean.
EXAMPLE 2.8
It is recommended that the “good cholesterol,” high-density lipoprotein (HDL), be present in the blood at levels of at least 40 mg/dl. Suppose a 50-member high school football team are all tested with resulting HDL levels of {53, 26, 45, 33, 64, 29, 73, 29, 21, 58, 70, 41, 48, 55, 55, 39, 57, 48, 9, 59, 56, 39, 68, 50, 65, 30, 38, 54, 49, 35, 56, 70, 43, 86, 52, 40, 28, 40, 67, 50, 47, 54, 59, 29, 29, 42, 45, 37, 51, 40}. What is the position of the HDL score of 41?
Answer: Since there are 31 higher HDL levels on the list, the 41 has a simple ranking of 32 out of 50. Eighteen HDL levels are lower, so the percentile ranking is 18/50 = 36%. The above list has a mean of 47.22 with a standard deviation of 15.05, so the HDL score of 41 has a z-score of (41 – 47.22)/15.05 = –0.413.
Simple Ranking
Simple ranking is easily calculated and easily understood. We know what it means for someone to graduate second in a class of 435, or for a player from a team of size 30 to have the seventh-best batting average. Simple ranking is useful even when no numerical values are associated with the elements. For example, detergents can be ranked according to relative cleansing ability without any numerical measurements of strength.
Percentile Ranking
Percentile ranking, another readily understood measurement of position, is helpful in comparing positions with different bases. We can more easily compare a rank of 176 out of 704 with a rank of 187 out of 935 by noting that the first has a rank of 75%, and the second, a rank of 80%. Percentile rank is also useful when the exact population size is not known or is irrelevant. For example, it is more meaningful to say that Jennifer scored in the 90th percentile on a national exam rather than trying to determine her exact ranking among some large number of test takers.
The quartiles, Q1 and Q3, lie one-quarter and three-quarters of the way up a list, respectively. Their percentile ranks are 25% and 75%, respectively. The interquartile range defined earlier can also be defined to be Q3 – Q1. The deciles lie one-tenth and nine-tenths of the way up a list, respectively, and have percentile ranks of 10% and 90%.
z-Score
The z-score is a measure of position that takes into account both the center and the dispersion of the distribution. More specifically, the z-score of a value tells how many standard deviations the value is from the mean. Mathematically, x – µ gives the raw distance from µ to x; dividing by $\sigma$ converts this to number of standard deviations. Thus $z=\frac{x-\mu}{\sigma}$, where x is the raw score, µ is the mean, and $\sigma$ is the standard deviation. If the score x is greater than the mean µ, then z is positive; if x is less than µ, then z is negative.
Given a z-score, we can reverse the procedure and find the corresponding raw score. Solving for x gives $x=\mu+z\sigma$.
EXAMPLE 2.9
Suppose the average (mean) price of gasoline in a large city is \$3.80 per gallon with a standard deviation of \$0.05. Then \$3.90 has a z-score of $\frac{3.65-3.80}{0.05}=+2,$ while \$3.65 has a z-score of $\frac{3.65-3.80}{0.05}=-3$. Alternatively, a z-score of +2.2 corresponds to a raw score of 3.80 + 2.2(0.05) = 3.80 + 0.11 = 3.91, while a z-score of –1.6 corresponds to 3.80 – 1.6(0.05) = 3.72.
It is often useful to portray integer z-scores and the corresponding raw scores as follows:

EXAMPLE 2.10
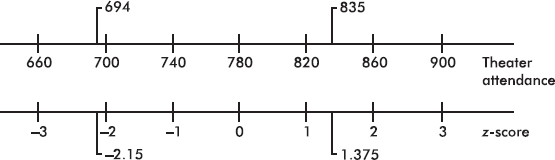
Suppose the attendance at a movie theater averages 780 with a standard deviation of 40. Adding multiples of 40 to and subtracting multiples of 40 from the mean 780 gives

A theater attendance of 835 is converted to a z-score as follows: $\frac{835-780}{40}=1.375$
A z-score of –2.15 is converted to a theater attendance as follows: 780 – 2.15(40) = 694.
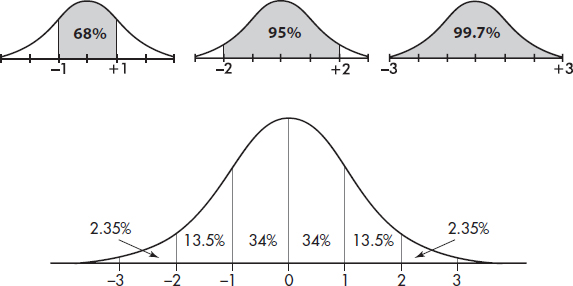
The empirical rule (also called the 68-95-99.7 rule) applies specifically to symmetric bell-shaped data (not to skewed data!). In this case, about 68% of the values lie within 1 standard deviation of the mean, about 95% of the values lie within 2 standard deviations of the mean, and more than 99% of the values lie within 3 standard deviations of the mean.
In the following figure the horizontal axis shows z-scores:
EXAMPLE 2.11
Suppose that taxicabs in New York City are driven an average of 75,000 miles per year with a standard deviation of 12,000 miles. What information does the empirical rule give us?
Answer: Assuming that the distribution is bell-shaped, we can conclude that approximately 68% of the taxis are driven between 63,000 and 87,000 miles per year, approximately 95% are driven between 51,000 and 99,000 miles, and virtually all are driven between 39,000 and 111,000 miles.
The empirical rule also gives a useful quick estimate of the standard deviation in terms of the range. We can see in the figure above that 95% of the data fall within a span of 4 standard deviations (from –2 to +2 on the z-score line) and 99.7% of the data fall within 6 standard deviations (from –3 to +3 on the z-score line). It is therefore reasonable to conclude that for these data the standard deviation is roughly between one-fourth and one-sixth of the range. Since we can find the range of a set almost immediately, the empirical rule technique for estimating the standard deviation is often helpful in pointing out gross arithmetic errors.
EXAMPLE 2.12
If the range of a bell-shaped data set is 60, what is an estimate for the standard deviation?
Answer: By the empirical rule, the standard deviation is expected to be between $\frac{1}{6}.60=10$ and $\frac{1}{4}.60=15$. If the standard deviation is calculated to be 0.32 or 87, there is probably an arithmetic error; a calculation of 12, however, is reasonable.
However, it must be stressed that the above use of the range is not intended to provide an accurate value for the standard deviation. It is simply a tool for pointing out unreasonable answers rather than, for example, blindly accepting computer outputs.
HISTOGRAMS AND MEASURES OF CENTRAL TENDENCY
Suppose we have a detailed histogram such as
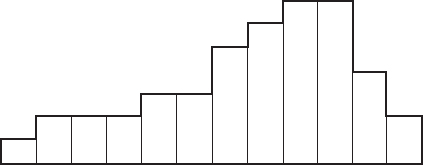
Our measures of central tendency fit naturally into such a diagram.
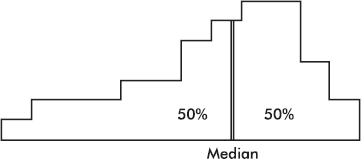
The median divides a distribution in half, so it is represented by a line that divides the area of the histogram in half.
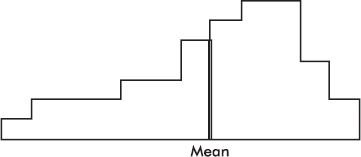
The mean is affected by the spacing of all the values. Therefore, if the histogram is considered to be a solid region, the mean corresponds to a line passing through the center of gravity, or balance point.
The above distribution, spread thinly far to the low side, is said to be skewed to the left. Note that in this case the mean is usually less than the median. Similarly, a distribution spread far to the high side is skewed to the right, and its mean is usually greater than its median.
EXAMPLE 2.13
Suppose that the faculty salaries at a college have a median of \$82,500 and a mean of \$88,700. What does this indicate about the shape of the distribution of the salaries?
Answer: The median is less than the mean, and so the salaries are probably skewed to the right. There are a few highly paid professors, with the bulk of the faculty at the lower end of the pay scale.
It should be noted that the above principle is a useful, but not hard-and-fast, rule.
EXAMPLE 2.14
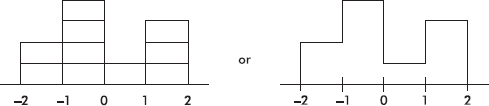
The set given by the dotplot below is skewed to the right; however, its median (3) is greater than its mean (2.97).

HISTOGRAMS, Z-SCORES, AND PERCENTILE RANKINGS
We have seen that relative frequencies are represented by relative areas, and so labeling the vertical axis is not crucial. If we know the standard deviation, the horizontal axis can be labeled in terms of z-scores. In fact, if we are given the percentile rankings of various z-scores, we can construct a histogram.
EXAMPLE 2.15
Suppose we are asked to construct a histogram from these data:
z-score: | –2 | –1 | 0 | 1 | 2 |
|
Percentile ranking: | 0 | 20 | 60 | 70 | 100 |
We note that the entire area is less than z-score +2 and greater than z-score –2. Also, 20% of the area is between z-scores –2 and –1, 40% is between –1 and 0, 10% is between 0 and 1, and 30% is between 1 and 2. Thus the histogram is as follows:
Now suppose we are given four in-between z-scores as well:
z-score | Ranking |
2.0 | 100 |
1.5 | 80 |
1.0 | 70 |
0.5 | 65 |
0.0 | 60 |
–0.5 | 30 |
–1.0 | 20 |
–1.5 | 5 |
–2.0 | 0 |
With 1000 z-scores perhaps the histogram would look like
The height at any point is meaningless; what is important is relative areas. For example, in the final diagram above, what percentage of the area is between z-scores of +1 and +2?
Answer: Still 30%.
What percent is to the left of 0?
Answer: Still 60%.
A boxplot (also called a box and whisker display) is a visual representation of dispersion that shows the smallest value, the largest value, the middle (median), the middle of the bottom half of the set (Q1), and the middle of the top half of the set (Q3).
TIP
The IQR is the length of the box, not the box itself. So the median is in the box, or is between Q1 and Q3, but is not in the IQR.
EXAMPLE 2.16
After an AP Statistics teacher hears that every one of her 27 students received a 3 or higher on the AP exam, she treats the class to a game of bowling. The individual student scores are 210, 130, 150, 140, 150, 210, 150, 125, 85, 200, 70, 150, 75, 90, 150, 115, 120, 125, 160, 140, 100, 95, 100, 215, 130, 160, and 200. Their students note that the greatest score is 215, the smallest is 70, the middle is 140, the middle of the top half is 160, and the middle of the bottom half is 100. A boxplot of these five numbers is
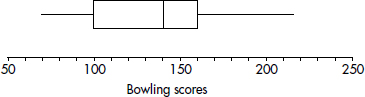
TIP
Be careful about describing the shape of a distribution when all that one has is a boxplot. For example, “approximately normal” is never a possible conclusion.
Note that the display consists of two “boxes” together with two “whiskers”—hence the alternative name. The boxes show the spread of the two middle quarters; the whiskers show the spread of the two outer quarters. This relatively simple display conveys information not immediately available from histograms or stem and leaf displays.
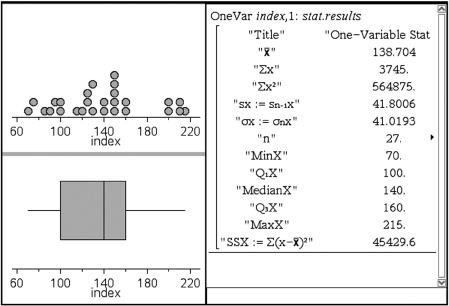
Putting the above data into a list, for example, L1, on the TI-84, not only gives the five-number summary
1-Var Stats
minX=70
Q1=100
Med=140
Q3=160
MaxX=215
TIP
Note that a boxplot gives one measure of center (the median) and two measures of variability (the range and the IQR).
but also gives the boxplot itself using STAT PLOT, choosing the boxplot from among the six type choices, and then using ZoomStat or in WINDOW letting Xmin=0 and Xmax=225.
On the TI-Nspire the data can be put in a list (here called index), and then a simultaneous multiple view is possible.
When a distribution is strongly skewed, or when it has pronounced outliers, drawing a boxplot with its five-number summary including median, quartiles, and extremes, gives a more useful description than calculating a mean and a standard deviation.
Usually, values more than 1.5 × IQR (1.5 times the interquartile range) outside the two boxes are plotted separately as outliers. (The TI-84 has a modified boxplot option. Note the two options in the second row of Type in StatPlot.)
EXAMPLE 2.17
Inputting the lengths of words in a selection of Shakespeare’s plays results in a calculator output of

Outliers consist of any word lengths less than Q1 – 1.5(IQR) = 3 – 1.5(5 – 3) = 0 or greater than Q3 + 1.5(IQR) = 5 + 1.5(5 – 3) = 8. A boxplot indicating outliers, together with a histogram (on the TI-84 up to three different graphs can be shown simultaneously) is
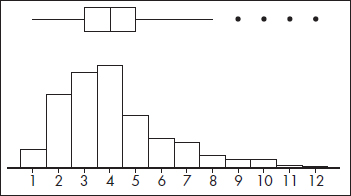
Note: Some computer output shows two levels of outliers—mild (between 1.5 IQR and 3 IQR) and extreme (more than 3 IQR). In this example, the word length of 12 would be considered an extreme outlier since it is greater than 5 + 3(5 – 3) = 11.
It should be noted that two sets can have the same five-number summary and thus the same boxplots but have dramatically different distributions.
EXAMPLE 2.18
Let A = {0, 5, 10, 15, 25, 30, 35, 40, 45, 50, 71, 72, 73, 74, 75, 76, 77, 78, 100} and B = {0, 22, 23, 24, 25, 26, 27, 28, 29, 50, 55, 60, 65, 70, 75, 85, 90, 95, 100}. Simple inspection indicates very different distributions, however the TI-84 gives identical boxplots with Min = 0, Q1 = 25, Med = 50, Q3 = 75, and Max = 100 for each.
Changing units, for example, from dollars to rubles or from miles to kilometers, is common in a world that seems to become smaller all the time. It is instructive to note how measures of center and spread are affected by such changes.
Adding the same constant to every value increases the mean and median by that same constant; however, the distances between the increased values stay the same, and so the range and standard deviation are unchanged.
EXAMPLE 2.19
A set of experimental measurements of the freezing point of an unknown liquid yield a mean of 25.32 degrees Celsius with a standard deviation of 1.47 degrees Celsius. If all the measurements are converted to the Kelvin scale, what are the new mean and standard deviation?
Answer: Kelvins are equivalent to degrees Celsius plus 273.16. The new mean is thus 25.32 + 273.16 = 298.48 kelvins. However, the standard deviation remains numerically the same, 1.47 kelvins. Graphically, you should picture the whole distribution moving over by the constant 273.16; the mean moves, but the standard deviation (which measures spread) doesn’t change.
Multiplying every value by the same constant multiplies the mean, median, range, and standard deviation all by that constant.
EXAMPLE 2.20
Measurements of the sizes of farms in an upstate New York county yield a mean of 59.2 hectares with a standard deviation of 11.2 hectares. If all the measurements are converted from hectares (metric system) to acres (one acre was originally the area a yoke of oxen could plow in one day), what are the new mean and standard deviation?
Answer: One hectare is equivalent to 2.471 acres. The new mean is thus 2.471 × 59.2 = 146.3 acres with a standard deviation of 2.471 × 11.2 = 27.7 acres. Graphically, multiplying each value by the constant 2.471 both moves and spreads out the distribution.
SUMMARY
The two principle measurements of the center of a distribution are the mean and the median.
The principle measurements of the spread of a distribution are the range (maximum value minus minimum value), the interquartile range (IQR = Q3 – Q1), the variance, and the standard deviation.
Adding the same constant to every value in a set adds the same constant to the mean and median but leaves all the above measures of spread unchanged.
Multiplying every value in a set by the same constant multiplies the mean, median, range, IQR, and standard deviation by that constant.
The mean, range, variance, and standard deviation are sensitive to extreme values, while the median and interquartile range are not.
The principle measurements of position are simple ranking, percentile ranking, and the z-score (which measures the number of standard deviations from the mean).
The empirical rule (the 68-95-99.7 rule) applies specifically to symmetric bell-shaped data.
In skewed left data, the mean is usually less than the median, while in skewed right data, the mean is usually greater than the median.
Boxplots visually show the five-number summary: the minimum value, the first quartile (Q1), the median, the third quartile (Q3), and the maximum value; and usually indicate outliers as distinct points.
Note that two sets can have the same five-number summary and thus the same boxplots but have dramatically different distributions.
Multiple-Choice Questions
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. The graph below shows household income in Laguna Woods, California.
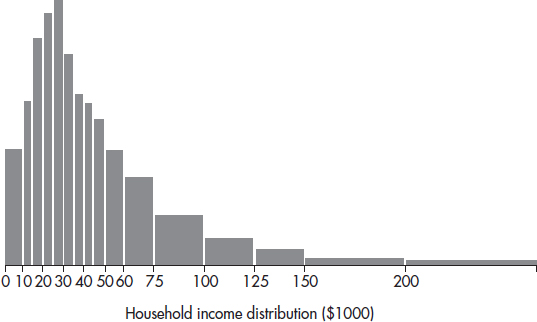
What can be said about the ratio $\frac{\text{Mean family income}}{\text{Median family income}}$?
(A) Approximately zero
(B) Less than one, but definitely above zero
(C) Approximately one
(D) Greater than one
(E) Cannot be answered without knowing the standard deviation
2. Which of the following are true statements?
I. The range of the sample data set is never greater than the range of the population.
II. The interquartile range is half the distance between the first quartile and the third quartile.
III. While the range is affected by outliers, the interquartile range is not.
(A) I only
(B) II only
(C) III only
(D) I and II
(E) I and III
3. Dieticians are concerned about sugar consumption in teenagers’ diets (a 12-ounce can of soft drink typically has 10 teaspoons of sugar). In a random sample of 55 students, the number of teaspoons of sugar consumed for each student on a randomly selected day is tabulated. Summary statistics are noted below:
Min = 10 Max = 60 First quartile = 25 Third quartile = 38
Median = 31 Mean = 31.4 n = 55 s = 11.6
Which of the following is a true statement?
(A) None of the values are outliers.
(B) The value 10 is an outlier, and there can be no others.
(C) The value 60 is an outlier, and there can be no others.
(D) Both 10 and 60 are outliers, and there may be others.
(E) The value 60 is an outlier, and there may be others at the high end of the data set.
Problems 4–6 refer to the following five boxplots.
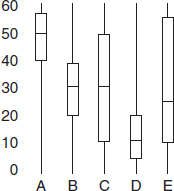
4. To which of the above boxplots does the following histogram correspond?
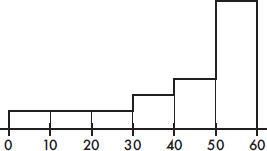
(A) A
(B) B
(C) C
(D) D
(E) E
5. To which of the above boxplots does the following histogram correspond?
(A) A
(B) B
(C) C
(D) D
(E) E
6. To which of the above boxplots does the following histogram correspond?
(A) A
(B) B
(C) C
(D) D
(E) E
Problems 7–9 refer to the following five histograms:
7. To which of the above histograms does the following boxplot correspond?
(A) A
(B) B
(C) C
(D) D
(E) E
8. To which of the above histograms does the following boxplot correspond?
(A) A
(B) B
(C) C
(D) D
(E) E
9. To which of the above histograms does the following boxplot correspond?
(A) A
(B) B
(C) C
(D) D
(E) E
10. Below is a boxplot of CO2 levels (in grams per kilometer) for a sampling of 2008 vehicles.

Suppose follow-up testing determines that the low outlier should be 10 grams per kilometer less and the two high outliers should each be 5 grams per kilometer greater. What effect, if any, will these changes have on the mean and median CO2 levels?
(A) Both the mean and median will be unchanged.
(B) The median will be unchanged, but the mean will increase.
(C) The median will be unchanged, but the mean will decrease.
(D) The mean will be unchanged, but the median will increase.
(E) Both the mean and median will change.
11. Below is a boxplot of yearly tuition and fees of all four year colleges and universities in a Western state. The low outlier is from a private university that gives full scholarships to all accepted students, while the high outlier is from a private college catering to the very rich.

Removing both outliers will effect what changes, if any, on the mean and median costs for this state’s four year institutions of higher learning?
(A) Both the mean and the median will be unchanged.
(B) The median will be unchanged, but the mean will increase.
(C) The median will be unchanged, but the mean will decrease.
(D) The mean will be unchanged, but the median will increase.
(E) Both the mean and median will change.
12. Suppose the average score on a national test is 500 with a standard deviation of 100. If each score is increased by 25, what are the new mean and standard deviation?
(A) 500, 100
(B) 500, 125
(C) 525, 100
(D) 525, 105
(E) 525, 125
13. Suppose the average score on a national test is 500 with a standard deviation of 100. If each score is increased by 25%, what are the new mean and standard deviation?
(A) 500, 100
(B) 525, 100
(C) 625, 100
(D) 625, 105
(E) 625, 125
14. If quartiles Q1 = 20 and Q3 = 30, which of the following must be true?
I. The median is 25.
II. The mean is between 20 and 30.
III. The standard deviation is at most 10.
(A) I only
(B) II only
(C) III only
(D) All are true.
(E) None are true.
15. A 1995 poll by the Program for International Policy asked respondents what percentage of the U.S. budget they thought went to foreign aid. The mean response was 18%, and the median was 15%. (The actual amount is less than 1%.) What do these responses indicate about the likely shape of the distribution of all the responses?
(A) The distribution is skewed to the left.
(B) The distribution is skewed to the right.
(C) The distribution is symmetric around 16.5%.
(D) The distribution is bell-shaped with a standard deviation of 3%.
(E) The distribution is uniform between 15% and 18%.
16. Assuming that batting averages have a bell-shaped distribution, arrange in ascending order:
I. An average with a z-score of –1.
II. An average with a percentile rank of 20%.
III. An average at the first quartile, Q1.
(A) I, II, III
(B) III, I, II
(C) II, I, III
(D) II, III, I
(E) III, II, I
17. Which of the following are true statements?
I. If the sample has variance zero, the variance of the population is also zero.
II. If the population has variance zero, the variance of the sample is also zero.
III. If the sample has variance zero, the sample mean and the sample median are equal.
(A) I and II
(B) I and III
(C) II and III
(D) I, II, and III
(E) None of the above gives the complete set of true responses.
18. When there are multiple gaps and clusters, which of the following is the best choice to give an overall picture of a distribution?
(A) Mean and standard deviation
(B) Median and interquartile range
(C) Boxplot with its five-number summary
(D) Stemplot or histogram
(E) None of the above are really helpful in showing gaps and clusters.
19. Suppose the starting salaries of a graduating class are as follows:
Number of Students | Starting Salary ($) |
10 | 15,000 |
17 | 20,000 |
25 | 25,000 |
38 | 30,000 |
27 | 35,000 |
21 | 40,000 |
12 | 45,000 |
What is the mean starting salary?
(A) $30,000
(B) $30,533
(C) $32,500
(D) $32,533
(E) $35,000
20. When a set of data has suspect outliers, which of the following are preferred measures of central tendency and of variability?
(A) mean and standard deviation
(B) mean and variance
(C) mean and range
(D) median and range
(E) median and interquartile range
21. If the standard deviation of a set of observations is 0, you can conclude
(A) that there is no relationship between the observations.
(B) that the average value is 0.
(C) that all observations are the same value.
(D) that a mistake in arithmetic has been made.
(E) none of the above.
22. A teacher is teaching two AP Statistics classes. On the final exam, the 20 students in the first class averaged 92 while the 25 students in the second class averaged only 83. If the teacher combines the classes, what will the average final exam score be?
(A) 87
(B) 87.5
(C) 88
(D) None of the above
(E) More information is needed to make this calculation.
23. Suppose 10% of a data set lie between 40 and 60. If 5 is first added to each value in the set and then each result is doubled, which of the following is true?
(A) 10% of the resulting data will lie between 85 and 125.
(B) 10% of the resulting data will lie between 90 and 130.
(C) 15% of the resulting data will lie between 80 and 120.
(D) 20% of the resulting data will lie between 45 and 65.
(E) 30% of the resulting data will lie between 85 and 125.
24. The 70 highest dams in the world have an average height of 206 meters with a standard deviation of 35 meters. The Hoover and Grand Coulee dams have heights of 221 and 168 meters, respectively. The Russian dams, the Nurek and Charvak, have heights with z-scores of +2.69 and –1.13, respectively. List the dams in order of ascending size.
(A) Charvak, Grand Coulee, Hoover, Nurek
(B) Charvak, Grand Coulee, Nurek, Hoover
(C) Grand Coulee, Charvak, Hoover, Nurek
(D) Grand Coulee, Charvak, Nurek, Hoover
(E) Grand Coulee, Hoover, Charvak, Nurek
25. The first 115 Kentucky Derby winners by color of horse were as follows: roan, 1; gray, 4; chestnut, 36; bay, 53; dark bay, 17; and black, 4. (You should “bet on the bay!”) Which of the following visual displays is most appropriate?
(A) Bar chart
(B) Histogram
(C) Stemplot
(D) Boxplot
(E) Time plot
For Questions 26 and 27 consider the following: The graph below shows cumulative proportions plotted against grade point averages for a large public high school.
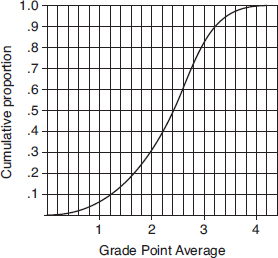
26. What is the median grade point average?
(A) 0.8
(B) 2.0
(C) 2.4
(D) 2.5
(E) 2.6
27. What is the interquartile range?
(A) 1.0
(B) 1.8
(C) 2.4
(D) 2.8
(E) 4.0
28. The following dotplot shows the speeds (in mph) of 100 fastballs thrown by a major league pitcher.

Which of the following is the best estimate of the standard deviation of these speeds?
(A) 0.5 mph
(B) 1.1 mph
(C) 1.6 mph
(D) 2.2 mph
(E) 6.0 mph
FREE-REPONSE QUESTIONS
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your final answers.
FOUR OPEN-ENDED QUESTIONS
1. Victims spend from 5 to 5840 hours repairing the damage caused by identity theft with a mean of 330 hours and a standard deviation of 245 hours.
(a) What would be the mean, range, standard deviation, and variance for hours spent repairing the damage caused by identity theft if each of the victims spent an additional 10 hours?
(b) What would be the mean, range, standard deviation, and variance for hours spent repairing the damage caused by identity theft if each of the victims’ hours spent increased by 10%?
2. In a study of all school districts in a state, the median 4-year graduation rate was 78.0% with Q1 = 60.4% and Q3 = 82.6%. The only rates below Q1 or above Q3 were 26.4%, 32.2%, 49.0%, 57.9%, 88.3%, and 98.1%.
(a) Draw a boxplot.
(b) Describe the distribution.
(c) Is the mean 4-year graduation rate probably close to, below, or above 78.0%? Explain.
(d) Would a stemplot give more, less, or basically the same information?
3. The Children’s Health Insurance Program (CHIP) provides health benefits to children from families whose incomes exceed the eligibility for Medicaid. Each state sets its own eligibility criteria. The following boxplot shows recent yearly expenditures on this program by state.
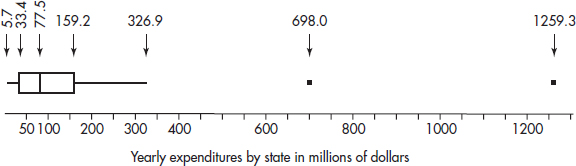
(a) What are the median and interquartile range of the distribution of yearly state expenditures in the CHIP program?
(b) Suppose the federal government takes over three million dollars of administrative costs from the state CHIP expenditures. What are the median and interquartile range of the new reduced expenditure distribution?
(c) Suppose instead the federal government picks up the tab for half of all state CHIP expenditures. What are the median and interquartile range of this new reduced expenditure distribution?
(d) Based on the above boxplot, which of the following is the most reasonable value for the mean state expenditure (in millions of dollars): 78, 135, 325, 630, or 750? Explain.
4. Suppose a distribution has mean 300 and standard deviation 25. If the z-score of Q1 is –0.7 and the z-score of Q3 is 0.7, what values would be considered to be outliers?
5. (a) Draw the boxplot for the data set {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10}. Very different sets can have the same boxplot.
(b) Find the data set with sample size n = 11, with each value an integer between 0 and 10, and with the same boxplot as in (a), which has the smallest possible mean.
(c) Find the data set with sample size n = 11, with each value an integer between 0 and 10, and with the same boxplot as in (a), which has the largest possible standard deviation.
AN INVESTIGATIVE TASK
A measure of variability is the median absolute deviation (MAD) defined as the median deviation from the median, that is, as the median of the absolute values of the deviations from the median. For example, the median of {1, 3, 7, 10, 11, 12} is 8.5, the absolute deviations from the median are {7.5, 5.5, 1.5, 1.5, 2.5, 3.5}, and the median of these deviations, MAD, is (2.5 + 3.5)/2 = 3.
The 12 students in an AP Statistics class all score above 33 (the cutoff score that year for achieving a 3 or above): {35, 38, 38, 42, 44, 48, 50, 52, 56, 60, 62, 71}.
(a) Calculate the median of these data.
(b) Calculate the MAD for these data. Show your work.
(c) Show that half of these data values are closer than one MAD to the median and half are further than one MAD from the median.
(d) How would the calculation of MAD have changed if the top score was 76 rather than 71? Justify your answer.
(e) What does the answer to (d) say about one difference between the two measures of variability: MAD versus standard deviation?
MULTIPLE-CHOICE
1. (D) The distribution is clearly skewed right, so the mean is greater than the median, and the ratio is greater than one.
2. (E) All elements of the sample are taken from the population, and so the smallest value in the sample cannot be less than the smallest value in the population; similarly, the largest value in the sample cannot be greater than the largest value in the population. The interquartile range is the full distance between the first quartile and the third quartile. Outliers are extreme values, and while they may affect the range, they do not affect the interquartile range when the lower and upper quarters have been removed before calculation.
3. (E) Outliers are any values below Q1 – 1.5(IQR) = 5.5 or above Q3 + 1.5(IQR) = 57.5.
4. (A) The value 50 seems to split the area under the histogram in two, so the median is about 50. Furthermore, the histogram is skewed to the left with a tail from 0 to 30.
5. (B) Looking at areas under the curve, Q1 appears to be around 20, the median is around 30, and Q3 is about 40.
6. (C) Looking at areas under the curve, Q1 appears to be around 10, the median is around 30, and Q3 is about 50.
7. (C) The boxplot indicates that 25% of the data lie in each of the intervals 10–20, 20–35, 35–40, and 40–50. Counting boxes, only histogram C has this distribution.
8. (D) The boxplot indicates that 25% of the data lie in each of the intervals 10–15, 15–25, 25–35, and 35–50. Counting boxes, only histogram D has this distribution.
9. (E) The boxplot indicates that 25% of the data lie in each of the intervals 10–20, 20–30, 30–40, and 40–50. Counting boxes, only histogram E has this distribution.
10. (A) Subtracting 10 from one value and adding 5 to two values leaves the sum of the values unchanged, so the mean will be unchanged. Exactly what values the outliers take will not change what value is in the middle, so the median will be unchanged.
11. (C) The high outlier is further from the mean than is the low outlier, so removing both will decrease the mean. However, removing the lowest and highest values will not change what value is in the middle, so the median will be unchanged.
12. (C) Adding the same constant to every value increases the mean by that same constant; however, the distances between the increased values and the increased mean stay the same, and so the standard deviation is unchanged. Graphically, you should picture the whole distribution as moving over by a constant; the mean moves, but the standard deviation (which measures spread) doesn’t change.
13. (E) Multiplying every value by the same constant multiplies both the mean and the standard deviation by that constant. Graphically, increasing each value by 25% (multiplying by 1.25) both moves and spreads out the distribution.
14. (E) The median is somewhere between 20 and 30, but not necessarily at 25. Even a single very large score can result in a mean over 30 and a standard deviation over 10.
15. (B) The median is less than the mean, and so the responses are probably skewed to the right; there are a few high guesses, with most of the responses on the lower end of the scale.
16. (A) Given that the empirical rule applies, a z-score of –1 has a percentile rank of about 16%. The first quartile Q1 has a percentile rank of 25%.
17. (C) If the variance of a set is zero, all the values in the set are equal. If all the values of the population are equal, the same holds true for any subset; however, if all the values of a subset are the same, this may not be true of the whole population. If all the values in a set are equal, the mean and the median both equal this common value and so equal each other.
18. (D) Stemplots and histograms can show gaps and clusters that are hidden when one simply looks at calculations such as mean, median, standard deviation, quartiles, and extremes.
19. (B) There are a total of 10 + 17 + 25 + 38 + 27 + 21 + 12 = 150 students. Their total salary is 10(15,000) + 17(20,000) + 25(25,000) + 38(30,000) + 27(35,000) + 21(40,000) + 12(45,000)
= $4,580,000. The mean is 
20. (E) The mean, standard deviation, variance, and range are all affected by outliers; the median and interquartile range are not.
21. (C) Because of the squaring operation in the definition, the standard deviation (and also the variance) can be zero only if all the values in the set are equal.
22. (A) The sum of the scores in one class is 20 × 92 = 1840, while the sum in the other is 25 × 83 = 2075. The total sum is 1840 + 2075 = 3915. There are 20 + 25 = 45 students, and
so the average score is 
23. (B) Increasing every value by 5 gives 10% between 45 and 65, and then doubling gives 10% between 90 and 130.
24. (A) 206 + 2.69(35) = 300; 206 – 1.13(35) = 166.
25. (A) Bar charts are used for categorical variables.
26. (C) The median corresponds to the 0.5 cumulative proportion.
27. (A) The 0.25 and 0.75 cumulative proportions correspond to Q1 = 1.8 and Q3 = 2.8, respectively, and so the interquartile range is 2.8 – 1.8 = 1.0.
28. (B) With bell-shaped data the empirical rule applies, giving that the spread from 92 to 98 is roughly 6 standard deviations, and so one SD is about 1.
FREE-RESPONSE
1. (a) Adding 10 to each value increases the mean by 10, but leaves measures of variability unchanged, so the new mean is 340 hours while the range stays at 5835 hours, the standard deviation remains at 245 hours, and the variance remains at 2452 = 60,025 hr2.
(b) Increasing each value by 10% (multiplying by 1.10) will increase the mean to 1.1(330) = 363 hours, the range to 1.1(5835) = 6418.5 hours, the standard deviation to 1.1(245) = 269.5 hours, and the variance to (269.5)2 = 72,630.25 hr2. (Note that the variance increases by a multiple of (1.1)2 not by a multiple of 1.1.)
2. (a) Check for outliers: IQR = 82.6 – 60.4 = 22.2. Q1 – 1.5(IQR) = 27.1 while Q3 + 1.5(IQR) = 115.9, so the only outlier is 26.4.
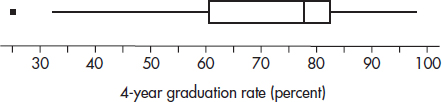
(b) A complete answer considers shape, center, and spread.
Shape: appears skewed left with an outlier at 26.4
Center: median is 78.0
Spread: from 26.4 to 98.1
(c) When the distribution is skewed left, the mean is usually less than the median.
(d) A stemplot would show more information because it shows all the original data, not just the few values given above; a stemplot can show clusters and gaps which are hidden by a boxplot.
3. (a) The median is 77.5 (millions of dollars), and the IQR = Q3 – Q1 = 159.2 – 33.4 = 125.8 (millions of dollars).
(b) Reducing every value by 3 will reduce the median by 3 but leave measures of variability unchanged, so the new mean is 77.5 – 3 = 74.5 (millions of dollars), and the IQR will still be 125.8 (millions of dollars).
(c) Reducing every value by 50% reduces the median to (0.5)(77.5) = 38.75 (millions of dollars) and reduces the IQR to (0.5)(125.8) = 62.9 (millions of dollars).
(d) The boxplot indicates that the distribution is skewed right, so the mean will be greater than the median. It is unlikely that the two outliers will pull the mean out as far as 325, so the most reasonable value for the mean is 135 (millions of dollars).
4. Z-scores give the number of standard deviations from the mean, so
Q1 = 300 – 0.7(25) = 282.5 and Q3 = 300 + 0.7(25) = 317.5.
The interquartile range is IQR = 317.5 – 282.5 = 35, and 1.5(IQR) = 1.5(35) = 52.5.
The standard definition of outliers encompasses all values less than Q1 – 52.5 = 230 and all values greater than Q3 + 52.5 = 370.
5. (a)
(b) Note that must keep Min = 0, Q1 = 2, Med = 5, Q3 = 8, and Max = 10, with the same totals of in-between values, so move in-between values to the left, and the answer is
{0, 0, 2, 2, 2, 5, 5, 5, 8, 8, 10}.
(c) Note that must keep Min = 0, Q1 = 2, Med = 5, Q3 = 8, and Max = 10, with the same totals of in-between values, so move in-between values outward, and the answer is
{0, 0, 2, 2, 2, 5, 8, 8, 8, 10, 10}.
INVESTIGATIVE TASK
(a) The median of the data values is (48 + 50)/2 = 49.
(b) The absolute deviations from the median are {14, 11, 11, 7, 5, 1, 1, 3, 7, 11, 13, 22}.
In ascending order, these deviations are {1, 1, 3, 5, 7, 7, 11, 11, 11, 13, 14, 22}.
The median of these deviations is MAD = (7 + 11)/2 = 9.
(c) One MAD less than the median is 49 – 9 = 40, and one MAD greater than the median is 49 + 9 = 58. Half of the values (6 values) are between 40 and 58: {42, 44, 48, 50, 52, 56} are all between 40 and 58, whereas half of the values (6 values) are either less than 40 or greater than 58: {35, 38, 38, 60, 62, 71}.
(d) If the top score was 76 rather than 71, the median of the data values would still be 49. The greatest deviation would be 27 rather than 22, but the median deviation would still be 9.
(e) The presence of outliers does not change the value of the MAD (MAD is resistant to outliers). In contrast, the standard deviation (SD) is very sensitive to the presence of outliers (the squares of every deviation from the mean enters the SD calculation).
DOTPLOTS
DOUBLE BAR CHARTS
BACK-TO-BACK STEMPLOTS
PARALLEL BOXPLOTS
CUMULATIVE FREQUENCY PLOTS
Many real-life applications of statistics involve comparisons of two populations. Such comparisons can involve modifications of graphical displays such as dotplots, bar charts, stemplots, boxplots, and cumulative frequency plots to portray both sets simultaneously.
TIP
When asked for a comparison, don’t forget to address shape, outliers (unusual values), center and spread (SOCS or CUSS), and to refer to context. You must use comparative words, that is, you must state which center and which spread is larger (or if they are approximately the same). Simply making two separate lists is not enough and will be penalized.
EXAMPLE 3.1
The caloric intakes of 25 people on each of two weight loss programs are recorded as follows:
Program A: 1000, 1000, 1100, 1100, 1100, 1200, 1200, 1200, 1200, 1300, 1300, 1300, 1300, 1300, 1400, 1400, 1400, 1400, 1400, 1500, 1500, 1600, 1600, 1700, 1900
Program B: 1000, 1100, 1100, 1200, 1200, 1200, 1300, 1300, 1300, 1400, 1400, 1400, 1400, 1500, 1500, 1500, 1500, 1500, 1600, 1600, 1600, 1700, 1700, 1800, 1800
These data can be compared with dotplots, one above the other, using the same horizontal scale.
Program A appears to be associated with a lower average caloric intake than Program B. Comparing shape, center, and spread, we have:
TIP
Don’t forget to label and provide a scale for all graphs!
Shape: We see that both sets of data are roughly bell-shaped (the empirical rule applies), and Program A has an outlier at 1900 calories (while Program B has no outliers).
Center: Visually, or by counting dots, the centers of the two distributions are 1300 and 1400 calories, for Programs A and B respectively. (A calculator gives means of xA = 1336 and xB = 1424.) By any method, the center for Program B is higher.
Spread: The spreads are approximately the same, 1000 to 1900 calories for Program A and 1000 to 1800 calories for Program B. (A calculator gives standard deviations of sA = 218 and sB = 218.)
EXAMPLE 3.2
A study tabulated the percentages of young adults who recognized various photographs as follows: Joe Stalin (10%), Joe Camel (95%), Senator Simpson of Wyoming (5%), Bart Simpson (80%), Al Gore (30%), Al Bundy (60%), Mickey Mantle (20%), Mickey Mouse (100%), Charlie Chaplin (25%), Charlie the Tuna (90%). These data can be illustrated with a bar chart appropriately displayed in pairs of bars.
The pairs of bar graphs visually indicate the reason for concern felt by some educators.
EXAMPLE 3.3
In a 40-year study, survival years were measured for cancer patients undergoing one of two different chemotherapy treatments. The data for 25 patients on the first drug and 30 on the second were as follows:
Drug A: 5, 10, 17, 39, 29, 25, 20, 4, 8, 31, 21, 3, 12, 11, 19, 10, 4, 22, 17, 18, 13, 28, 11, 14, 21
Drug B: 19, 12, 20, 28, 22, 35, 1, 21, 21, 26, 18, 28, 29, 20, 15, 32, 31, 24, 22, 26, 18, 20, 22, 35, 30, 18, 25, 24, 19, 21
In drawing a back-to-back stemplot of the above data, we place a vertical line on each side of the column of stems and then arrange one set of leaves extending out to the right while the other extends out to the left.
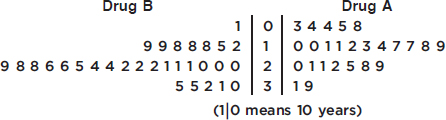
Note that even though drug A showed the longest-surviving patient (39 years) and drug B showed the shortest-surviving patient (1 year), the back-to-back stemplot indicates that the bulk of patients on drug B survived longer than the bulk of patients on drug A.
Comparing shape, center, and spread, we have:
Shape: Both distributions are roughly bell-shaped (the empirical rule applies). The drug A distribution appears to have a high outlier at 39, while the drug B distribution appears to have a low outlier at 1.
Center: Visually, or by counting values, the centers of the two distributions are 17 and 22, respectively. (A calculator gives means of xA = 16.48 and xB = 22.73.) By either method, the drug B distribution has a greater center.
Spread: The spreads are 3 to 39 survival years for drug A and 1 to 35 survival years for drug B. (A calculator gives standard deviations of sA = 9.25 and sB = 6.97.) By either method, the drug A distribution has a greater spread than the drug B distribution.
EXAMPLE 3.4
Mail-order labs and 1-hour minilabs were compared with regard to price for developing and printing one 24-exposure roll of 35-millimeter color-print film. Prices included shipping and handling charges where applicable. Following is a computer output describing the results:
For mail-order labs:
Mean = 5.37 Standard deviation = 1.92 Min = 3.51
Max = 8.00 N = 18 Median = 4.77
Quartiles = 3.92, 6.45
For 1-hour minilabs:
Mean = 10.11 Standard deviation = 1.32 Min = 8.58
Max = 11.95 N = 15 Median = 10.08
Quartiles = 8.97, 11.51
In drawing parallel boxplots (also called side-by-side boxplots) of the above data, we place both on the same diagram:
Boxplots show the minimum, maximum, median, and quartile values. The distribution of mail-order lab prices is lower and more spread out than that of prices of 1-hour minilabs. Both are slightly skewed toward the upper end (the skewness can also be noted from the computer output showing the mean to be greater than the median in both cases.)
Parallel boxplots are useful in presenting a picture of the comparison of several distributions.
EXAMPLE 3.5
Following are parallel boxplots showing the daily price fluctuations of a certain common stock over the course of 5 years. What trends do the boxplots show?
The parallel boxplots show that from year to year the median daily stock price has steadily risen 20 points from about \$58 to about \$78, the third quartile value has been roughly stable at about \$84, the yearly low has never decreased from that of the previous year, and the interquartile range has never increased from one year to the next.
EXAMPLE 3.6
The graph below compares cumulative frequency plotted against age for the U.S. population in 1860 and in 1980.
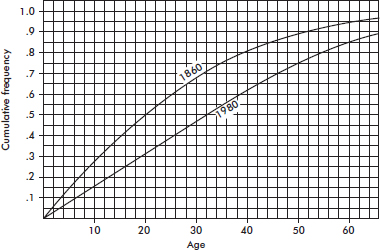
How do the medians and interquartile ranges compare?
Answer: Looking across from .5 on the vertical axis, we see that in 1860 half the population was under the age of 20, while in 1980 all the way up to age 32 must be included to encompass half the population. Looking across from .25 and .75 on the vertical axis, we see that for 1860, Q1 = 9 and Q3 = 35 and so the interquartile range is 35 – 9 = 26 years, while for 1980, Q1 = 16 and Q3 = 50 and so the interquartile range is 50 – 16 = 34 years. Thus, both the median and the interquartile range were greater in 1980 than in 1860.
SUMMARY
To visually compare two or more distributions use:
Dotplots, either one above the other or side-by-side
Double bar charts
Histograms, either one above the other or side-by-side
Back-to-back stemplots
Parallel boxplots
Cumulative frequency plots on the same grid
For all the above, make note of any similarities and differences in shape, center, and spread.
Multiple-Choice Questions
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. The dotplots below show the yearly wages of all male and female executives at a large firm.
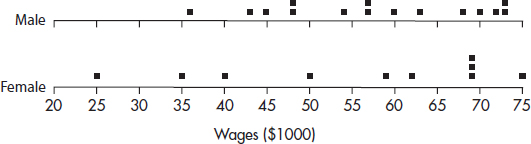
Which of the following conclusions cannot be drawn from the plots?
(A) A greater proportion of male employees than female employees are executives at this firm.
(B) No executive receives a salary less than $25,000.
(C) The median salary paid to male executives is less than the median salary paid to female executives.
(D) The range of salaries paid to male executives is less than the range of salaries paid to female executives.
(E) More male than female executives have salaries over $70,000.
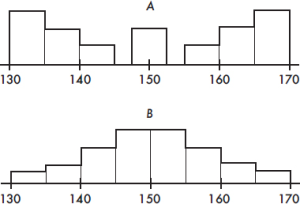
2. Which of the following statements about the two histograms above is true?
(A) The empirical rule applies only to set A.
(B) The mean of set A looks to be greater than the mean of set B.
(C) The mean of set B looks to be greater than the mean of set A.
(D) Both sets have roughly the same variance.
(E) The standard deviation of set B is greater than 5.
3. Consider the following back-to-back stemplots comparing car battery lives (in months) of samples of two popular brands.
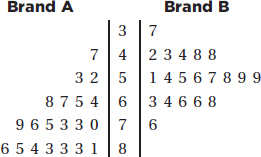
Which of the following are true statements?
I. The sample sizes are the same.
II. The ranges are the same.
III. The variances are the same.
IV. The means are the same.
V. The medians are the same.
(A) I and II
(B) I and IV
(C) II and V
(D) III and V
(E) I, II, and III
4. The following boxplots were constructed from SAT math scores of boys and girls at a high school:
Which of the following is a possible boxplot for the combined scores of all the students?
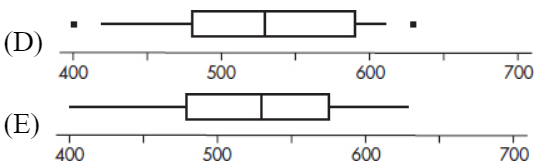
Questions 5–7 refer to the following population pyramids (source: U.S. Census Bureau).
5. What is the approximate median age of the Liberian population?
(A) 0–4
(B) 15–19
(C) 30–34
(D) 40–44
(E) There is insufficient information to approximate the median.
6. Which country has more children younger than 10 years of age?
(A) Liberia
(B) Canada
(C) You can’t tell without calculating means.
(D) You can’t tell without calculating medians.
(E) You can’t tell without calculating some measure of variability.
7. Which of the following statements are plausible, given the graphs?
I. Canadian women tend to live longer than men.
II. The recent civil war in Liberia, with the extensive use of child soldiers, has had an impact on the population age distribution.
III. Canadian demographics show a decreasing birth rate.
(A) I only
(B) I and II only
(C) I and III only
(D) II and III only
(E) All three are plausible.
8. Looking at very large sets of communications metadata, mainly phone call and e-mail logs, a government agency tracks connections starting with intelligence targets overseas and extending to “contact chains” of different lengths. During January 2014 and January 2015, the lengths of contact chains analyzed are shown in the following histograms.
In which month did the chain length distribution have the greater standard deviation?
(A) January 2014 because of its bell-shaped distribution
(B) January 2014 because the 2015 distribution is roughly uniform
(C) January 2015 because of similar means, but a later date
(D) January 2015 because more data are further from the mean
(E) This cannot be answered without more information.
Free-Response Questions
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your final answers.
FOUR OPEN-ENDED QUESTIONS
1. Are women better than men at multitasking? Suppose in one study of multitasking a random sample of 200 female and 200 male high school students were assigned several tasks at the same time, such as solving simple mathematics problems, reading maps, and answering simple questions while talking on a telephone. Total times taken to complete all the tasks are given in the histograms below.
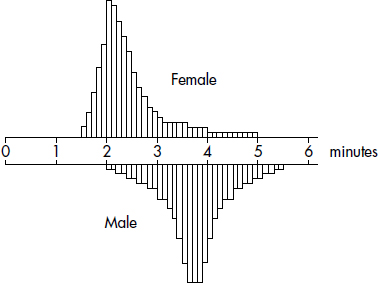
Write a few sentences comparing the distributions of times to complete all tasks by females and by males.
2. In independent random samples of 20 men and 20 women, the number of minutes spent on grooming on a given day were:
Men: 27, 32, 82, 36, 43, 75, 45, 16, 23, 48, 51, 57, 60, 64, 39, 40, 69, 72, 54, 57
Women: 49, 50, 35, 69, 75, 35, 49, 54, 98, 58, 22, 34, 60, 38, 47, 65, 79, 38, 42, 87
Using back-to-back stemplots. compare the two distributions.
3. To analyze the social media behavior differences between boys and girls, Mrs. V’s FDA high school AP Statistics class was asked to count the number of text messages that they sent over a long three-day weekend. The following table summarizes the data:
| Values under Q1 | Q1 | Median | Q3 | Values over Q3 |
Females | 15, 43, 100 | 130 | 175 | 358 | 450, 573, 1098 |
Males | 3, 59 | 72 | 183 | 273 | 293, 337 |
(a) Construct parallel boxplots of this set of data.
(b) Do the data indicate that females or males had the greater mean number of texts? Explain.
4. Cumulative frequency graphs of the ages of people on three different Caribbean cruises (A, B, and C) are given below:
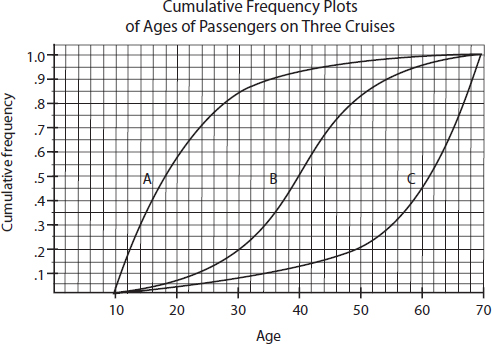
Write a few sentences comparing the distributions of ages of people on the three cruises.
AN INVESTIGATIVE TASK
The NFL quarterback rating formula provides a means of comparing passing performances. The graphs below show the quarterback ratings for two players during one 16-game season.
(a) Construct dotplots showing the frequencies of each rating for each player.
(b) Compare the distributions of quarterback ratings for the two players.
(c) What information is more apparent from the dotplots than from the above 16-game graphs?
(d) What information is more apparent from the above 16-game graphs than from the dotplots?
A central moving average is calculated using data equally spaced either side of the point in the series where the mean is calculated. The first few lines of the 3-game central moving averages for the quarterback ratings of the two players are as follows:
(e) Fill in the two blank spaces corresponding to the fourth game above. Show your calculations.
MULTIPLE-CHOICE
1. (A) The numbers of male and female employees are not given so proportions who are executives cannot be determined.
2. (E) The empirical rule applies to bell-shaped data like those found in set B, not in set A. Both sets are roughly symmetric around 150 and so both should have means about 150. Set A is much more spread out than set B, and so set A has the greater variance. For bell-shaped data, about 95% of the values fall within two standard deviations of the mean and 99.7% fall within three. However, in the histogram for set B, one sees that 95% of the data are not between 140 and 160, and 99.7% are not between 135 and 165. Thus, the standard deviation for set B must be greater than 5.
3. (A) Both sets have 20 elements. The ranges, 76 − 37 = 39 and 86 − 47 = 39, are equal. Brand A clearly has the larger mean and median, and with its skewness it also has the larger variance.
4. (E) The minimum of the combined set of scores must be the min of the boys since it is lower; the maximum of the combined set of scores must be the max of the girls since it is higher; the first quartile must be the same as the identical first quartiles of the two original distributions. There are no outliers (scores more than 1.5(IQR) from the first and third quartiles).
5. (B) Roughly 50% of total bar length is above and below the 15–19 interval.
6. (B) There are about 1.2 million younger than the age of 10 in Liberia (boys and girls) and roughly 3.5 million in Canada.
7. (E) In the Canadian graph, all higher age groups show greater numbers of women than men. In the Liberian graph, the smaller 15–19 age group shows a definite break with the overall pattern (a great number of child soldiers died in the fighting). In the Canadian graph, the narrowing base indicates a decreasing birth rate.
8. (D) The standard deviation is defined in terms of squared deviations from the mean. In the 2014 distribution, more data are concentrated closer to the mean, whereas in the 2015 distribution, more data are further from the mean.
FREE-RESPONSE
1. A complete answer compares shape, center, and spread and mentions context in at least one of the responses.
Shape: The distribution of times to complete all tasks by females is skewed right (toward the higher values), whereas the distributions of times to complete all tasks by males is roughly bell-shaped.
Center: The center of the distribution of female times (at around $2\frac{1}{4}$ minutes) is less than the center of the distribution of male times (at around $3\frac{3}{4}$ minutes).
Spread: The spreads of the two distributions are roughly the same; the range of the female times ($5-1\frac{1}{2}=3\frac{1}{2}$ minutes) equals the range of the male times ($5\frac{1}{2}-2=3\frac{1}{2}$ minutes).
2.

A complete answer compares shape, center, and spread and mentions context in at least one of the responses.
Shape: The men’s distribution of hours grooming is roughly symmetric, whereas the women’s distribution of hours grooming is skewed right (toward higher values).
Center: The center of the men’s distribution is about the same as the center of the women’s distribution, both about 50 min.
Spread: The spread of the men’s distribution (with a range of 82 – 16 = 66 min) is less than the spread of the women’s distribution (with a range of 98 – 22 = 76 min).
3. (a) For females, Q1 – 1.5(IQR) = 130 – 1.5(358 – 130) = –212 and Q3 + 1.5(IQR) = 700, so 1098 is an outlier. For males, Q1 – 1.5(IQR) = 72 – 1.5(273 – 72) = –229.5 and Q3 + 1.5(IQR) = 574.5, so there are no outliers.
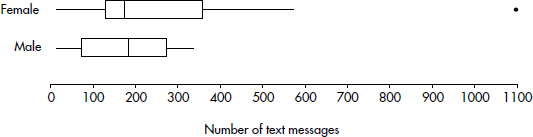
(b) The medians are roughly equal. The male distribution appears roughly symmetric, so the mean is close to the median; however, the female distribution shows extreme right skewness, so the mean is much greater than the median. Thus, the females had a greater mean number of text messages than did the males.
4. A complete answer compares shape, center, and spread and mentions context in at least one of the responses.
Shape: Cruise A, for which the cumulative frequency plot rises steeply at first, has more younger passengers, and thus a distribution skewed to the right (towards the higher ages). Cruise C, for which the cumulative frequency plot rises slowly at first and then steeply towards the end, has more older passengers, and thus a distribution skewed to the left (towards the younger ages). Cruise B, for which the cumulative frequency plot rises slowly at each end and steeply in the middle, has a more bell-shaped distribution.
Center: Considering the center to be a value separating the area under the histogram roughly in half, the centers will correspond to a cumulative frequency of 0.5. Reading across from 0.5 to the intersection of each graph, and then down to the x-axis, shows centers of approximately 18, 40, and 61 years, respectively. Thus, the center of distribution A is the least, and the center of distribution C is the greatest.
Spread: The spreads of the age distributions of all three cruises are the same: from 10 to 70 years.
AN INVESTIGATIVE TASK
(a)
(b) Shape: The Player A distribution is roughly uniform, whereas the Player B distribution is skewed right. (Also, the Player A distribution has no outliers, whereas the Player B distribution looks to have an outlier at 80.)
Center: The center of the Player A distribution (at about 110) is greater than the center of the Player B distribution (at about 35).
Spread: The variability in the Player B distribution is greater than the variability of the Player A distribution (for example, the range in the A distribution is 130 – 90 = 40, whereas the range in the B distribution is 80 – 25 = 55.
(c) The shapes (uniform for A and skewed right for B) are more apparent in the dotplots.
(d) With the dotplots, it’s impossible to see the game to game variability. Also the dotplot for the B distribution doesn’t show the end of year upswing in ratings.
(e) For Player ![]() and for Player
and for Player ![]()
SCATTERPLOTS
CORRELATION AND LINEARITY
LEAST SQUARES REGRESSION LINE
RESIDUAL PLOTS
OUTLIERS AND INFLUENTIAL POINTS
TRANSFORMATIONS TO ACHIEVE LINEARITY
Our studies so far have been concerned with measurements of a single variable. However, many important applications of statistics involve examining whether two or more variables are related to one another. For example, is there a relationship between the smoking histories of pregnant women and the birth weights of their children? Between SAT scores and success in college? Between amount of fertilizer used and amount of crop harvested?
Two questions immediately arise. First, how can the strength of an apparent relationship be measured? Second, how can an observed relationship be put into functional terms? For example, a real estate broker might not only wish to determine whether a relationship exists between the prime rate and the number of new homes sold in a month but might also find useful an expression with which to predict the number of home sales given a particular value of the prime rate.
A graphical display, called a scatterplot, gives an immediate visual impression of a possible relationship between two variables, while a numerical measurement, called a correlation coefficient, is often used as a quantitative value of the strength of a linear relationship. In either case, evidence of a relationship is not evidence of causation.
Suppose a relationship is perceived between two quantitative variables X and Y, and we graph the pairs (x, y). We are interested in the strength of this relationship, the scatterplot arising from the relationship, and any deviation from the basic pattern of this relationship. In this topic we examine whether the relationship can be reasonably explained in terms of a linear function, that is, one whose graph is a straight line.
TIP
Recognize explanatory (x) and response (y) variables in context.
For example, we might be looking at a plot such as
We need to know what the term best-fitting straight line means and how we can find this line. Furthermore, we want to be able to gauge whether the relationship between the variables is strong enough so that finding and making use of this straight line is meaningful.
Patterns in Scatterplots
When larger values of one variable are associated with larger values of a second variable, the variables are called positively associated. When larger values of one are associated with smaller values of the other, the variables are called negatively associated.
EXAMPLE 4.1
The strength of the association is gauged by how close the plotted points are to a straight line.
EXAMPLE 4.2
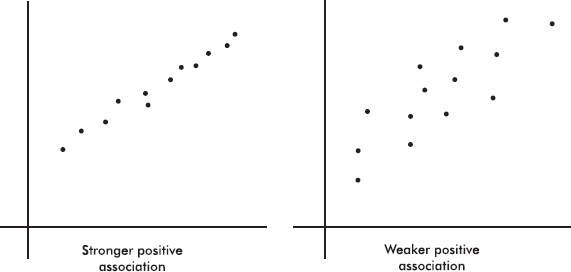
Sometimes different dots in a scatterplot are labeled with different symbols or different colors to show a categorical variable. The resulting labeled scatterplot might distinguish between men and women, between stocks and bonds, and so on.
EXAMPLE 4.3
The above diagram is a labeled scatterplot distinguishing men with plus signs and women with square dots to show a categorical variable.
When analyzing the overall pattern in a scatterplot, it is also important to note clusters and outliers.
EXAMPLE 4.4
An experiment was conducted to note the effect of temperature and light on the potency of a particular antibiotic. One set of vials of the antibiotic was stored under different temperatures, but under the same lighting, while a second set of vials was stored under different lightings, but under the same temperature.
In the first scatterplot note the linear pattern with one outlier far outside this pattern. A possible explanation is that the antibiotic is more potent at lower temperatures, but only down to a certain temperature at which it drastically loses potency.
TIP
Note when the data falls in distinct groups.
In the second histogram note the two clusters. It appears that below a certain light intensity the potency is one value, while above that intensity it is another value. In each cluster there seems to be no association between intensity and potency.
IMPORTANT
Correlation does not imply causation!
Although a scatter diagram usually gives an intuitive visual indication when a linear relationship is strong, in most cases it is quite difficult to visually judge the specific strength of a relationship. For this reason there is a mathematical measure called correlation (or the correlation coefficient). Important as correlation is, we always need to keep in mind that significant correlation does not necessarily indicate causation and that correlation measures the strength only of a linear relationship.
Correlation, designated by r, has the formula
![]()
in terms of the means and standard deviations of the two sets. We note that the formula is actually the sum of the products of the corresponding z-scores divided by 1 less than the sample size. However, you should be able to quickly calculate correlation using the statistical package on your calculator. (Examining the formula helps you understand where correlation is coming from, but you will NOT have to use the formula to calculate r.)
Note from the formula that correlation does not distinguish between which variable is called x and which is called y. The formula is also based on standardized scores (z-scores), and so changing units does not change the correlation. Finally, since means and standard deviations can be strongly influenced by outliers, correlation is also strongly affected by extreme values.
TIP
With standardized data (z-scores), r is the slope of the regression line.
The value of r always falls between –1 and +1, with –1 indicating perfect negative correlation and +1 indicating perfect positive correlation. It should be stressed that a correlation at or near zero doesn’t mean there isn’t a relationship between the variables; there may still be a strong nonlinear relationship.
EXAMPLE 4.5
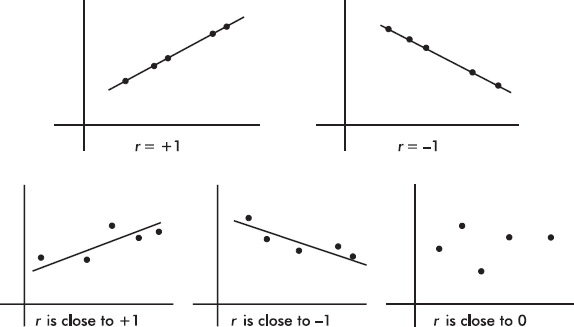
NOTE
We can also say that r2 gives the percentage of variation in y that can be explained by the regression line, with x as the explanatory variable.
It can be shown that r2, called the coefficient of determination, is the ratio of the variance of the predicted values $ \widehat{y}$ to the variance of the observed values y. That is, there is a partition of the y-variance, and r2 is the proportion of this variance that is predictable from a knowledge of x. Alternatively, we can say that r2 gives the percentage of variation in y that is explained by the variation in x. In either case, always interpret r2 in context of the problem. Remember when calculating r from r2 that r may be positive or negative.
While the correlation r is given as a decimal between –1.0 and 1.0, the coefficient of determination r2 is usually given as a percentage. An r2 of 100% is a perfect fit, with all the variation in y explained by variation in x. How large a value of r2 is desirable depends on the application under consideration. While scientific experiments often aim for an r2 in the 90% or above range, observational studies with r2 of 10% to 20% might be considered informative. Note that while a correlation of .6 is twice a correlation of .3, the corresponding r2 of 36% is four times the corresponding r2 of 9%.
What is the best-fitting straight line that can be drawn through a set of points?
TIP
If a scatterplot indicates a non-linear relationship, don’t try to force a straight-line fit.
On the basis of our experience with measuring variances, by best-fitting straight line we mean the straight line that minimizes the sum of the squares of the vertical differences between the observed values and the values predicted by the line.
TIP
A hat over a variable means it is a predicted version of the variable.
That is, in the above figure, we wish to minimize
![]()
It is reasonable, intuitive, and correct that the best-fitting line will pass through ($\overline{x},\overline{y}$) where $\overline{x}$ and $\overline{y}$ are the means of the variables X and Y. Then, from the basic expression for a line with a given slope through a given point, we have
The slope b1 can be determined from the formula
$b_1=r.\frac{s_y}{s_x}$
where r is the correlation and sx and sy are the standard deviations of the two sets. That is, each standard deviation change in x results in a change of r standard deviations in y. If you graph z-scores for the y-variable against z-scores for the x-variable, the slope of the regression line is precisely r, and, in fact, the linear equation becomes zy = rzx.
This best-fitting straight line, that is, the line that minimizes the sum of the squares of the differences between the observed values and the values predicted by the line, is called the least squares regression line or simply the regression line. It can be calculated directly by entering the two data sets and using the statistics package on your calculator.
TIP
Just because we can calculate a regression line doesn’t mean it is useful.
EXAMPLE 4.6
An insurance company conducts a survey of 15 of its life insurance agents. The average number of minutes spent with each potential customer and the number of policies sold in a week are noted for each agent. Letting X and Y represent the average number of minutes and the number of sales, respectively, we have
X: 25 23 30 25 20 33 18 21 22 30 26 26 27 29 20
Y: 10 11 14 12 8 18 9 10 10 15 11 15 12 14 11
Find the equation of the best-fitting straight line for the data.
Answer: Plotting the 15 points (25, 10), (23, 11), …, (20, 11) gives an intuitive visual impression of the relationship:
TIP
Be sure to label axes and show number scales whenever possible.
This scatterplot indicates the existence of a relationship that appears to be linear; that is, the points lie roughly on a straight line. Furthermore, the linear relationship is positive; that is, as one variable increases, so does the other (the straight line slopes upward).
Using a calculator, we find the correlation to be r = .8836, the coefficient of determination to be r2 = .78 (indicating that 78% of the variation in the number of policies is explained by the variation in the number of minutes spent), and the regression line to be
$\widehat{y}=\overline{y}+b_1(x-\overline{x})$
= 12 + 0.5492(x – 25)
= –1.73 + 0.5492x
We also write: $\widehat{\text{Policies}}=-1.73+0.5492$ Minutes
Adding this to our scatterplot yields
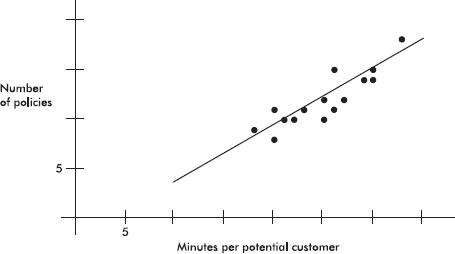
Thus, for example, we might predict that agents who average 24 minutes per customer will average 0.5492(24) – 1.73 = 11.45 sales per week. We also note that each additional minute spent seems to produce an average 0.5492 extra sale.
EXAMPLE 4.7
Following are advertising expenditures and total sales for six detergent products:
Advertising (\$1000) (x): 2.3 5.7 4.8 7.3 5.9 6.2
Total sales (\$1000) (y): 77 105 96 118 102 95
Predict the total sales if \$5000 is spent on advertising and interpret the slope of the regression line. What if \$100,000 is spent on advertising?
Answer: With your calculator, the equation of the regression line is found to be
$\widehat{y}$ = 98.833 + 7.293(x – 5.367) = 59.691 + 7.293x
TIP
Use meaningful variable names.
(A calculator like the TI-84, with less round-off error, directly gives $\widehat{y}$ = 59.683 + 7.295x.)
It is also worthwhile to replace the x and y with more appropriately named variables, resulting, for example, in
![]()
The regression line predicts that if \$5000 is spent on advertising, the resulting total sales will be 7.293(5) + 59.691 = 96.156 thousands of dollars (\$96,156).
The slope of the regression line indicates that every extra \$1000 spent on advertising will result in an average of \$7293 in added sales.
If \$100,000 is spent on advertising, we calculate 7.293(100) + 59.691 = 788.991 thousands of dollars (≈\$789,000). How much confidence should we have in this answer? Not much! We are trying to use the regression line to predict a value far outside the range of the data values. This procedure is called extrapolation and must be used with great care.
TIP
Be careful about extrapolation beyond the observed x-values.
It should be noted that when we use the regression line to predict a y-value for a given x-value, we are actually predicting the mean y-value for that given x-value. For any given x-value, there are many possible y-values, and we are predicting their mean. So if \$5000 is spent many times on advertising, various resulting total sales figures may result, but their predicted average is \$96,156.
The TI-Nspire gives
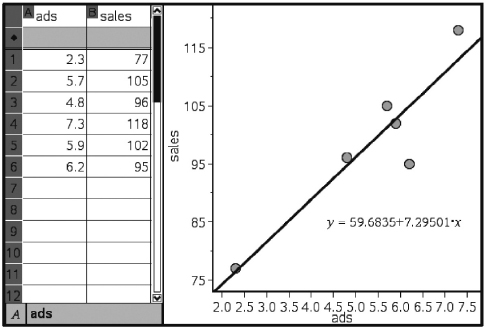
EXAMPLE 4.8
A random sample of 30 U.S. farm regions surveyed during the summer of 2003 produced the following statistics:
Average temperature (°F) during growing season: $\overline{x}$ = 81, sx = 3
Average corn yield per acre (bu.): $\overline{y}$ = 131, sy = 5
Correlation r = .32
Based on this study, what is the mean predicted corn yield for a region where the average growing season temperature is 76.5°F?
Answer: 76.5 is $\frac{76.5-81}{3}=-1.5$ standard deviations below the average temperature reported in the study, so with a correlation of r = .32, the predicted corn yield is .32(–1.5) = –0.48 standard deviations below the average corn yield, or 131 – 0.48(5) = 128.6 bushels per acre.
Alternatively, we could have found the linear regression equation relating these variables: slope=$r\frac{s_y}{s_x}=.32\frac{5}{3}\approx 0.533$ intercept ≈ 131 – 81(0.533) ≈ 87.8, and thus $\widehat{\text{Yield}} $ = 0.533 Temp + 87.8. Then 0.533(76.5) + 87.8 ≈ 128.6.
CAREFUL!
Order is important; residual equals observed – predicted.
The difference between an observed and predicted value is called the residual. When the regression line is graphed on the scatterplot, the residual of a point is the vertical distance the point is from the regression line.
NOTE
When the data point is above the regression line, the residual is positive; a data point below the line gives a negative residual.
The regression line is the line that minimizes the sum of the squares of the residuals.
EXAMPLE 4.9
We calculate the predicted values from the regression line in Example 4.7 and subtract from the observed values to obtain the residuals:

Note that the sum of the residuals is
0.5 + 3.7 + 1.3 + 5.1 – 0.7 – 9.9 = 0.0
The TI-Nspire easily shows the “squares of the residuals,” the sum of which is minimized by the regression line.
The above equation is true in general; that is, the sum and thus the mean of the residuals is always zero.
The notation for residuals is $\widehat{e_i}=y_i-\widehat{y_i}$ and so $\sum_{i=1}^{n}\widehat{e_i}=0$. The standard deviation of the residuals is calculated as follows:
![]()
se gives a measure of how the points are spread around the regression line.
Plotting the residuals gives further information. In particular, a residual plot with a definite pattern is an indication that a nonlinear model will show a better fit to the data than the straight regression line. In addition to whether or not the residuals are randomly distributed, one should look at the balance between positive and negative residuals and also the size of the residuals in comparison to the associated y-values.
The residuals can be plotted against either the x-values or the $\widehat{y}$-values (since $\widehat{y}$ is a linear transformation of x, the plots are identical except for scale and a left-right reversal when the slope is negative).
It is also important to understand that a linear model may be appropriate, but weak, with a low correlation. And, alternatively, a linear model may not be the best model (as evidenced by the residual plot), but it still might be a very good model with high r2.
EXAMPLE 4.10
Suppose the drying time of a paint product varies depending on the amount of a certain additive it contains.
Additive (oz), x: | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
Drying time (hr), y: | 4 | 2.1 | 1.5 | 1 | 1.2 | 1.7 | 2.5 | 3.6 | 4.9 | 6.1 |
Using a calculator, we find the regression line $\widehat{y}$ = 0.327x + 1.062, and we find the residuals:
x: | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
y – $\widehat{y}$: | 2.61 | 0.38 | –0.54 | –1.37 | –1.5 | –1.32 | –0.85 | –0.08 | 0.89 | 1.77 |
The resulting residual plot shows a strong pattern:
This pattern indicates that a nonlinear model will be a better fit than a straight-line model. A scatterplot of the original data shows clearly what is happening:
The ability to interpret computer output is important not only to do well on the AP Statistics exam, but also to understand statistical reports in the business and scientific world.
EXAMPLE 4.11
Miles per gallon versus speed for a new model automobile is fitted with a least squares regression line. The graph of the residuals and some computer output for the regression are as follows:
Regression Analysis: MPG Versus Speed
The regression equation is
MPG = 38.9 – 0.218 Speed
Predictor | Coef | SE Coef | T | P |
|
Constant | 38.929 | 5.651 | 6.89 | 0.000 |
|
Speed | –0.2179 | 0.1119 | –1.95 | 0.099 |
|
Analysis of Variance
Source | DF | SS | MS | F | P |
Regression | 1 | 199.34 | 199.34 | 3.79 | 0.099 |
Residual Error | 6 | 315.54 | 52.59 |
|
|
Total | 7 | 514.88 |
|
|
|
a. Interpret the slope of the regression line in context.
Answer: The slope of the regression line is –0.2179, indicating that, on average, the MPG drops by 0.2179 for every increase of one mile per hour in speed.
b. What is the mean predicted MPG at a speed of 30 mph?
Answer: At 30 mph, the mean predicted MPG is –0.2179(30) + 38.929, or about 32.4 MPG.
c. What was the actual MPG at a speed of 30 mph?
Answer: The residual for 30 mph is about +3.5, and since residual = actual – predicted, we estimate the actual MPG to be 32.4 + 3.5, or about 36 MPG.
d. Is a line the most appropriate model? Explain.
Answer: The fact that the residuals show such a strong curved pattern indicates that a nonlinear model would be more appropriate.
e. What does “S = 7.252” refer to?
Answer: The standard deviation of the residuals, se = 7.252, is a “typical value” of the residuals and gives a measure of how the points are spread around the regression line.
EXAMPLE 4.12
The number of youngsters playing Little League baseball in Ithaca, New York, during the years 1995–2003 is fitted with a least squares regression line. The graph of the residuals and some computer output for their regression are as follows:
Regression Analysis: Number of Players Versus Years Since 1995
Predictor | Coef | SE Coef | T | P |
Constant | 123.800 | 1.798 | 68.84 | 0.000 |
Years | 12.6333 | 0.3778 | 33.44 | 0.000 |
S = 2.926, R–Sq = 99.4%, R–Sq(adj) = 99.3%
Analysis of Variance
Source | DF | SS | MS | F | P | |
Regression | 1 | 9576.1 | 9576.1 | 1118.45 | 0.000 | |
Residual Error | 7 | 59.9 | 8.6 |
|
|
|
Total | 8 | 9636.0 |
|
|
|
|
TIP
Simply using a calculator to find a regression line is not enough; you must understand it (for example, be able to interpret the slope and intercepts in context).
a. Does it appear that a line is an appropriate model for the data? Explain.
Answer: Yes. R–Sq = 99.4% is large, and the residual plot shows no pattern. Thus a linear model is appropriate.
b. What is the equation of the regression line (in context)?
Answer: Predicted # of players = 123.8 + 12.6 (years since 1995)
c. Interpret the slope of the regression line in the context of the problem.
Answer: The slope of the regression line is 12.6, indicating that, on average, the predicted number of children playing Little League baseball in Ithaca increased by 12 or 13 players per year during the 1995–2003 time period.
d. Interpret the y-intercept of the regression line in the context of the problem.
Answer: The y-intercept, 123.8, refers to the year 1995. Thus the number of players in Little League in Ithaca in 1995 was predicted to be around 124.
e. What is the predicted number of players in 1997?
Answer: For 1997, x = 2, so the predicted number of players is 12.6(2) + 123.8 = 149.
f. What was the actual number of players in 1997?
Answer: The residual for 1997 (x = 2) from the residual plot is +5, so actual – predicted = 5, and thus the actual number of players in 1997 must have been 5 + 149 = 154.
g. What years, if any, did the number of players decrease from the previous year? Explain.
Answer: The number would decrease if one residual were more than 12.6 greater than the next residual. This never happens, so the number of players never decreased.
OUTLIERS AND INFLUENTIAL POINTS
In a scatterplot, regression outliers are indicated by points falling far away from the overall pattern. That is, a point is an outlier if its residual is an outlier in the set of residuals.
EXAMPLE 4.13
A scatterplot of grade point average (GPA) versus weekly television time for a group of high school seniors is as follows:
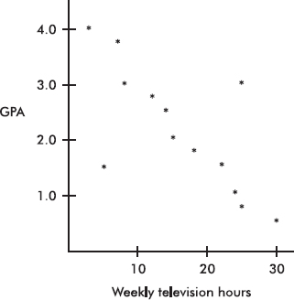
By direct observation of the scatterplot, we note that there are two outliers: one person who watches 5 hours of television weekly yet has only a 1.5 GPA, and another person who watches 25 hours weekly yet has a 3.0 GPA. Note also that while the value of 30 weekly hours of television may be considered an outlier for the television hours variable and the 0.5 GPA may be considered an outlier for the GPA variable, the point (30, 0.5) is not an outlier in the regression context because it does not fall off the straight-line pattern.
Scores whose removal would sharply change the regression line are called influential scores. Sometimes this description is restricted to points with extreme x-values. An influential score may have a small residual but still have a greater effect on the regression line than scores with possibly larger residuals but average x-values.
EXAMPLE 4.14
Consider the following scatterplot of six points and the regression line:
The heavy line in the scatterplot on the left below shows what happens when point A is removed, and the heavy line in the scatterplot on the right below shows what happens when point B is removed.
Note that the regression line is greatly affected by the removal of point A but not by the removal of point B. Thus point A is an influential score, while point B is not. This is true in spite of the fact that point A is closer to the original regression line than point B.
TRANSFORMATIONS TO ACHIEVE LINEARITY
Often a straight-line pattern is not the best model for depicting a relationship between two variables. A clear indication of this problem is when the scatterplot shows a distinctive curved pattern. Another indication is when the residuals show a distinctive pattern rather than a random scattering. In such a case, the nonlinear model can sometimes be revealed by transforming one or both of the variables and then noting a linear relationship. Useful transformations often result from using the log or ln buttons on your calculator to create new variables.
EXAMPLE 4.15
Consider the following years and corresponding populations:
Year, x: | 1950 | 1960 | 1970 | 1980 | 1990 |
Population (1000s), y: | 50 | 67 | 91 | 122 | 165 |
The scatterplot and residual plot indicate that a nonlinear relationship would be an even stronger model.
Letting log y be a new variable, we obtain
x: | 1950 | 1960 | 1970 | 1980 | 1990 |
log y: | 1.70 | 1.83 | 1.96 | 2.09 | 2.22 |
The scatterplot and residual plot now indicate a stronger linear relationship.
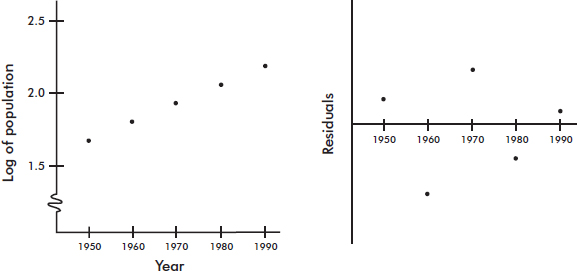
A regression analysis yields $\widehat{\log y}=0.013x-23.65.$ In context we have: $\widehat{\text{log(Pop)}}=$ –23.65 + 0.013(Year). So, for example, the population predicted for the year 2000 would be calculated $\widehat{\text{log(Pop)}}=$ 0.013(2000) – 23.65 = 2.35, and so Pop = 102.35 ≈ 224 thousand, or 224,000. The “linear” equation $\widehat{\text{log y}}=$ 0.013x – 23.65 can be re-expressed as $\widehat{y}$ = 100.013x–23.65 [= 10–23.65 × (100.013)x = 2.2387E–24 × 1.0304x].
There are many useful transformations. For example:
Log y as a linear function of x, log y = ax + b, re-expresses as an exponential:
y = 10ax+b or y = b110ax where b1 = 10b
Log y as a linear function of log x, log y = a log x + b, re-expresses as a power:
y = 10a log x+b or y = b1xa where b1 = 10b
$\sqrt{y}$ as a linear function of x, $\sqrt{y}$ = ax + b, re-expresses as a quadratic:
y = (ax + b)2
$\frac{1}{y}$ as a linear function of x, $\frac{1}{y}$ = ax + b, re-expresses as a reciprocal:
$y=\frac{1}{ax+b}$
y as a linear function of log x, y = a log x + b, is a logarithmic function.
Note: Although you need to be able to recognize the need for a transformation, justify its appropriateness (residuals plot), use whichever is appropriate from above to create a linear model, and use the model to make predictions, you do not have to be able to re-express the linear equation in the manner shown above.
EXAMPLE 4.16
What are possible models for the following data?
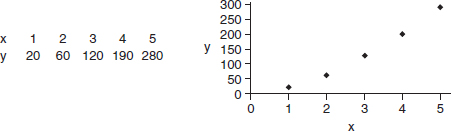
Answer: A linear fit to x and y gives $\widehat{y}$ = 65x – 61 with r = 0.99.
A linear fit to x and log y gives log y = 0.279x + 1.139 with r = 0.98. This results in an exponential relationship:
$\widehat{y}$ = 100.279x+1.139 = 13.77(100.279x) = 13.77(1.901x)
A linear fit to log x and log y gives log y = 1.639 log x + 1.295, also with r = 0.99. This results in a power relationship:
$\widehat{y}$ = 101.639 log x+1.295 = 19.72(x1.639)
All three models give high correlation and are reasonable fits. Further analysis can be done by examining the residual plots:
The first two residual plots have distinct curved patterns. The third residual plot illustrates both a more random pattern and smaller residuals. (One can also create residual plots using the derived curved models, but we choose to restrict our attention to residual plots of the linear models.) Among the above three models, the power model $\widehat{y}$ = 19.72(x1.639), appears to be best.
SUMMARY
A scatterplot gives an immediate indication of the shape (linear or not), strength, and direction (positive or negative) of a possible relationship between two variables.
If the relationship appears roughly linear, then the correlation coefficient, r, is a useful measurement.
The value of r is always between –1 and +1, with positive values indicating positive association and negative values indicating negative association; and values close to –1 or +1 indicating a stronger linear association than values close to 0, which indicate a weaker linear association.
Evidence of an association is not evidence of a cause-and-effect relationship!
Correlation is not affected by which variable is called x and which y or by changing units.
Correlation can be strongly affected by extreme values.
The differences between the observed and predicted values are called residuals.
The best-fitting straight line, called the regression line, minimizes the sum of the squares of the residuals.
For the linear regression model, the mean of the residuals is always 0.
A definite pattern in the residual plot indicates that a nonlinear model may fit the data better than the straight regression line.
The coefficient of determination, r2, gives the percentage of variation in y that is accounted for by the variation in x.
Influential scores are scores whose removal would sharply change the regression line.
Nonlinear models can sometimes be studied by transforming one or both variables and then noting a linear relationship.
It is very important to be able to interpret generic computer output.
Multiple-Choice Questions
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. A study collects data on average combined SAT scores (math, critical reading, and writing) and percentage of students who took the exam at 100 randomly selected high schools. Following is part of the computer printout for regression:

Which of the following is a correct conclusion?
(A) SAT in the variable column indicates that SAT is the dependent (response) variable.
(B) The correlation is ±0.875, but the sign cannot be determined.
(C) The y-intercept indicates the mean combined SAT score if percent of students taking the exam has no effect on combined SAT scores.
(D) The R2 value indicates that the residual plot does not show a strong pattern.
(E) Schools with lower percentages of students taking the exam tend to have higher average combined SAT scores.
2. A simple random sample of 35 world-ranked chess players provides the following statistics:
Number of hours of study per day: $\overline{x} $ = 6.2, sx = 1.3
Yearly winnings: $\overline{y} $ = $208,000, sy = $42,000
Correlation r = 0.15
Based on this data, what is the resulting linear regression equation?
(A) $\widehat{\text{Winnings}}
$ = 178,000 + 4850 Hours
(B) $\widehat{\text{Winnings}}
$ = 169,000 + 6300 Hours
(C) $\widehat{\text{Winnings}}
$ = 14,550 + 31,200 Hours
(D) $\widehat{\text{Winnings}}
$ = 7750 + 32,300 Hours
(E) $\widehat{\text{Winnings}}
$ = –52,400 + 42,000 Hours
3. A rural college is considering constructing a windmill to generate electricity but is concerned over noise levels. A study is performed measuring noise levels (in decibels) at various distances (in feet) from the campus library, and a least squares regression line is calculated with a correlation of 0.74. Which of the following is a proper and most informative conclusion for an observation with a negative residual?
(A) The measured noise level is 0.74 times the predicted noise level.
(B) The predicted noise level is 0.74 times the measured noise level.
(C) The measured noise level is greater than the predicted noise level.
(D) The predicted noise level is greater than the measured noise level.
(E) The slope of the regression line at that point must also be negative.
4. Consider the following three scatterplots:
Which has the greatest correlation coefficient?
(A) I
(B) II
(C) III
(D) They all have the same correlation coefficient.
(E) This question cannot be answered without additional information.
5. Suppose the correlation is negative. Given two points from the scatterplot, which of the following is possible?
I. The first point has a larger x-value and a smaller y-value than the second point.
II. The first point has a larger x-value and a larger y-value than the second point.
III. The first point has a smaller x-value and a larger y-value than the second point.
(A) I only
(B) II only
(C) III only
(D) I and III
(E) I, II, and III
6. Consider the following residual plot:
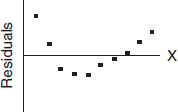
Which of the following scatterplots could have resulted in the above residual plot? (The y-axis scales are not the same in the scatterplots as in the residual plot.)
(A)

(B)

(C)

(D)

(E) None of these could result in the given residual plot.
7. Suppose the regression line for a set of data, $\widehat{y} $ = 3x + b, passes through the point (2, 5). If $\overline{x}$ and $\overline{y}$ are the sample means of the x– and y-values, respectively, then $\overline{y}$ =
(A) $\overline{x}$.
(B) $\overline{x}$ – 2.
(C) $\overline{x}$ + 5.
(D) 3$\overline{x}$.
(E) 3$\overline{x}$ – 1.
8. Suppose a study finds that the correlation coefficient relating family income to SAT scores is r = +1. Which of the following are proper conclusions?
I. Poverty causes low SAT scores.
II. Wealth causes high SAT scores.
III. There is a very strong association between family income and SAT scores.
(A) I only
(B) II only
(C) III only
(D) I and II
(E) I, II, and III
9. A study of department chairperson ratings and student ratings of the performance of high school statistics teachers reports a correlation of r = 1.15 between the two ratings. From this information we can conclude that
(A) chairpersons and students tend to agree on who is a good teacher.
(B) chairpersons and students tend to disagree on who is a good teacher.
(C) there is little relationship between chairperson and student ratings of teachers.
(D) there is strong association between chairperson and student ratings of teachers, but it would be incorrect to infer causation.
(E) a mistake in arithmetic has been made.
10. Which of the following statements about correlation r is true?
(A) A correlation of 0.2 means that 20% of the points are highly correlated.
(B) Perfect correlation, that is, when the points lie exactly on a straight line, results in r = 0.
(C) Correlation is not affected by which variable is called x and which is called y.
(D) Correlation is not affected by extreme values.
(E) A correlation of 0.75 indicates a relationship that is 3 times as linear as one for which the correlation is only 0.25.
Questions 11–13 refer to the following:
The relationship between winning game proportions when facing the sun and when the sun is on one’s back is analyzed for a random sample of 10 professional players. The computer printout for regression is below:
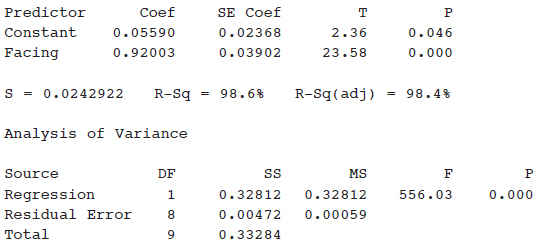
11. What is the equation of the regression line, where face and back are the winning game proportions when facing the sun and with back to the sun, respectively?
12. What is the correlation?
(A) –0.984
(B) –0.986
(C) 0.984
(D) 0.986
(E) 0.993
13. For one player, the winning game proportions were 0.55 and 0.59 for facing and back, respectively. What was the associated residual?
(A) –0.028
(B) 0.028
(C) –0.0488
(D) 0.0488
(E) 0.3608
14. Which of the following statements about residuals are true?
I. The mean of the residuals is always zero.
II. The regression line for a residual plot is a horizontal line.
III. A definite pattern in the residual plot is an indication that a nonlinear model will show a better fit to the data than the straight regression line.
(A) I and II
(B) I and III
(C) II and III
(D) I, II, and III
(E) None of the above gives the complete set of true responses.
15. Data are obtained for a group of college freshmen examining their SAT scores (math plus writing plus critical reading) from their senior year of high school and their GPAs during their first year of college. The resulting regression equation is
$\widehat{\text{GPA}}=$ 0.55 + 0.00161 (SAT total) with r = 0.632
What percentage of the variation in GPAs can be explained by looking at SAT scores?
(A) 0.161%
(B) 16.1%
(C) 39.9%
(D) 63.2%
(E) This value cannot be computed from the information given.
16. In a study of whether the structure of the adult human brain changes when a new skill is learned, the gray matter volume of four individuals was measured before and after learning a new cognitive skill. The resulting scatterplot was:
The correlation above is 0. Three researchers each run the experiment on a new subject and each obtain an additional data point:
Match the above scatterplots with their new correlations.
(A) | I: –0.33 | II: 0 | III: 0.33 |
(B) | I: 0 | II: 0.33 | III: 0.64 |
(C) | I: 0 | II: 0.33 | III: 1.0 |
(D) | I: –0.33 | II: 0 | III: 1.0 |
(E) | I: 0 | II: 0.50 | III: 1.0 |
17. In a study of winning percentage in home games versus average home attendance for professional baseball teams, the resulting regression line is:
![]()
What is the residual if a team has a winning percentage of 55% with an average attendance of 34,000?
(A) –11.0
(B) –0.8
(C) 0.8
(D) 11.0
(E) 23.0
18. Consider the following scatterplot of midterm and final exam scores for a class of 15 students.
Which of the following is incorrect?
(A) The same number of students scored 100 on the midterm exam as scored 100 on the final exam.
(B) Students who scored higher on the midterm exam tended to score higher on the final exam.
(C) The scatterplot shows a moderate negative correlation between midterm and final exam scores.
(D) The coefficient of determination here is positive.
(E) No one scored 90 or above on both exams.
19. If every woman married a man who was exactly 2 inches taller than she, what would the correlation between the heights of married men and women be?
(A) Somewhat negative
(B) 0
(C) Somewhat positive
(D) Nearly 1
(E) 1
20. Suppose the correlation between two variables is r = 0.23. What will the new correlation be if 0.14 is added to all values of the x-variable, every value of the y-variable is doubled, and the two variables are interchanged?
(A) 0.23
(B) 0.37
(C) 0.74
(D) –0.23
(E) –0.74
21. Suppose the correlation between two variables is –0.57. If each of the y-scores is multiplied by –1, which of the following is true about the new scatterplot?
(A) It slopes up to the right, and the correlation is –0.57.
(B) It slopes up to the right, and the correlation is +0.57.
(C) It slopes down to the right, and the correlation is –0.57.
(D) It slopes down to the right, and the correlation is +0.57.
(E) None of the above is true.
22. Consider the set of points {(2, 5), (3, 7), (4, 9), (5, 12), (10, n)}. What should n be so that the correlation between the x– and y-values is 1?
(A) 21
(B) 24
(C) 25
(D) A value different from any of the above.
(E) No value for n can make r = 1.
23. Consider the following three scatterplots:
Which of the following is a true statement about the correlations for the three scatterplots?
(A) None are 0.
(B) One is 0, one is negative, and one is positive.
(C) One is 0, and both of the others are positive.
(D) Two are 0, and the other is 1.
(E) Two are 0, and the other is close to 1.
24. Consider the three points (2, 11), (3, 17), and (4, 29). Given any straight line, we can calculate the sum of the squares of the three vertical distances from these points to the line. What is the smallest possible value this sum can be?
(A) 6
(B) 9
(C) 29
(D) 57
(E) None of these values
25. Suppose that the scatterplot of log X and log Y shows a strong positive correlation close to 1. Which of the following is true?
(A) The variables X and Y also have a correlation close to 1.
(B) A scatterplot of the variables X and Y shows a strong nonlinear pattern.
(C) The residual plot of the variables X and Y shows a random pattern.
(D) A scatterplot of X and log Y shows a strong linear pattern.
(E) A cause-and-effect relationship can be concluded between log X and log Y.
26. Consider n pairs of numbers. Suppose $\overline{x}$ = 2, sx = 3, $\overline{y}$ = 4, and sy = 5. Of the following, which could be the least squares line?
(A) $\widehat{y} $ = –2 + x
(B) $\widehat{y} $ = 2x
(C) $\widehat{y} $ = –2 + 3x
(D) $\widehat{y}=\frac{5}{3}-x$
(E) $\widehat{y} $ = 6 – x
Free-Response Questions
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your final answers.
TEN OPEN-ENDED QUESTIONS
1. Average home attendance and number of home wins for the 2009–2010 NBA Pacific Division teams were as follows:
| Lakers | Suns | Clippers | Warriors | Kings |
Average attendance | 18,997 | 17,648 | 16,343 | 18,027 | 13,254 |
Home wins | 34 | 32 | 21 | 18 | 18 |
(a) Does a winning team bring out the fans? Can average attendance be predicted from number of wins? Find the equation of the best-fitting straight line.
(b) Interpret the slope.
(c) Predict the average attendance for a team with 25 home wins.
(d) What number of home wins will predict an average of 17,000 fans?
(e) What is the residual for the Lakers average attendance?
2. The shoe sizes and the number of ties owned by ten corporate vice presidents are as follows:
Shoe size, x: | 8 | 9.5 | 9 | 11 | 9 | 9.5 | 8.5 | 9 | 9 | 9.5 |
Number of ties, y: | 10 | 10 | 8 | 15 | 12 | 13 | 16 | 7 | 12 | 4 |
(a) Draw a scatterplot for these data.
(b) Find the correlation r.
(c) Can we find the best-fitting straight-line approximation to the above data? Does it make sense to use this equation to predict the number of ties owned by a corporate executive who wears size 10 shoes? Explain.
3. Following is a scatterplot of the average life expectancies and per capita incomes (in thousands of dollars) for people in a sample of 50 countries.
(a) Estimate the mean for the set of 50 life expectancies and for the set of 50 per capita incomes.
(b) Estimate the standard deviation for the set of life expectancies and for the set of per capita incomes. Explain your reasoning.
(c) Does the scatterplot show a correlation between per capita income and life expectancy? Is it positive or negative? Is it weak or strong?
4. (a) Find the correlation r for each of the three sets:
A = {(5, 5), (5, 10), (10, 5), (10, 10)}
B = {(50, 50), (50, 55), (55, 50), (55, 55)}
C = {(90, 90), (90, 95), (95, 90), (95, 95)}
(b) Find the correlation for the set consisting of the 12 scores from A, B, and C.
(c) Comment on the above results.
5. An outlier can have a striking effect on the correlation r. For example, comment on the following three scatterplots:
6. Fuel economy y (in miles per gallon) is tabulated for various speeds x (in miles per hour) for a certain car model. A linear regression model gives Predicted fuel economy = 34.8 – 0.16 (Speed) with the following residual plot:
A quadratic regression model gives $\widehat{y}$ = –0.0032x2 + 0.26x + 23.8 with the following residual plot:
(a) What does each model predict for fuel economy at 50 miles per hour?
(b) Which model is a better fit? Explain.
7. The following scatterplot shows the grades for research papers for a sociology professor’s class plotted against the lengths of the papers (in pages).
Mary turned in her paper late and was told by the professor that her grade would have been higher if she had turned it in on time. A computer printout fitting a straight line to the data (not including Mary’s score) by the method of least squares gives
Grade = 46.51 + 1.106 Length
R–sq = 74.6%
(a) Find the correlation coefficient for the relationship between grade and length of paper based on these data (excluding Mary’s paper).
(b) What is the slope of the regression line and what does it signify?
(c) How will the correlation coefficient change if Mary’s paper is included? Explain your answer.
(d) How will the slope of the regression line change if Mary’s paper is included? Explain your answer.
(e) What grade did Mary receive? Predict what she would have received if her paper had been on time.
8. Data show a trend in winning long jump distances for an international competition over the years 1972–92. With jumps recorded in inches and dates in years since 1900, a least squares regression line is fit to the data. The computer output and a graph of the residuals are as follows:
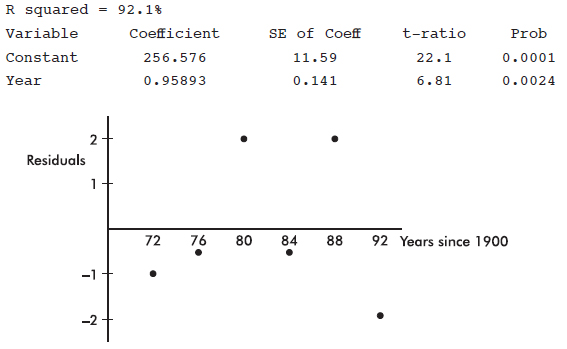
(a) Does a line appear to be an appropriate model? Explain.
(b) What is the slope of the least squares line? Give an interpretation of the slope.
(c) What is the correlation?
(d) What is the predicted winning distance for the 1980 competition?
(e) What was the actual winning distance in 1980?
9. A scatterplot of the number of accidents per day on a particular interstate highway during a 30-day month is as follows:
(a) Draw a histogram of the frequencies of the number of accidents.
(b) Draw a boxplot of the number of accidents.
(c) Name a feature apparent in the scatterplot but not in the histogram or boxplot.
(d) Name a feature clearly shown by the histogram and boxplot but not as obvious in the scatterplot.
10. The following scatterplot shows the pulse rate drop (in beats per minute) plotted against the amount of medication (in grams) of an experimental drug being field-tested in several hospitals.
A computer printout showing the results of fitting a straight line to the data by the method of least squares gives
PulseRateDrop = –1.68 + 8.5 Grams
R–sq = 81.9%
(a) Find the correlation coefficient for the relationship between pulse rate drop and grams of medication.
(b) What is the slope of the regression line and what does it signify?
(c) Predict the pulse rate drop for a patient given 2.25 grams of medication.
(d) A patient given 5 grams of medication has his pulse rate drop to zero. Does this invalidate the regression equation? Explain.
(e) How will the size of the correlation coefficient change if the 3-gram result is removed from the data set? Explain.
(f) How will the size of the slope of the least squares regression line change if the 3-gram result is removed from the data set? Explain.
MULTIPLE-CHOICE
1. (E) The variable column indicates the independent (explanatory) variable. The sign of the correlation is the same as the sign of the slope (negative here). In this example, the y-intercept is meaningless (predicted SAT result if no students take the exam). There can be a strong linear relation, with high R2 value, but still a distinct pattern in the residual plot indicating that a non-linear fit may be even stronger. The negative value of the slope (–2.84276) gives that the predicted combined SAT score of a school is 2.84 points lower for each one unit higher in the percentage of students taking the exam, on average.
2. (A) ![]()
3. (D) Residual = Measured – Predicted, so if the residual is negative, the predicted must be greater than the measured (observed).
4. (D) The correlation coefficient is not changed by adding the same number to each value of one of the variables or by multiplying each value of one of the variables by the same positive number.
5. (E) A negative correlation shows a tendency for higher values of one variable to be associated with lower values of the other; however, given any two points, anything is possible.
6. (A) This is the only scatterplot in which the residuals go from positive to negative and back to positive.
7. (E) Since (2, 5) is on the line y = 3x + b, we have 5 = 6 + b and b = –1. Thus the regression line is y = 3x – 1. The point (x, y) is always on the regression line, and so we have y = 3x – 1.
8. (C) The correlation r measures association, not causation.
9. (E) The correlation r cannot take a value greater than 1.
10. (C) If the points lie on a straight line, r = ±1. Correlation has the formula ![]() so x and y are interchangeable, and r does not depend on which variable is called x or y. However, since means and standard deviations can be strongly influenced by outliers, r too can be strongly affected by extreme values. While r = 0.75 indicates a better fit with a linear model than r = 0.25 does, we cannot say that the linearity is threefold.
so x and y are interchangeable, and r does not depend on which variable is called x or y. However, since means and standard deviations can be strongly influenced by outliers, r too can be strongly affected by extreme values. While r = 0.75 indicates a better fit with a linear model than r = 0.25 does, we cannot say that the linearity is threefold.
11. (B) The “Predictor” column indicates the independent variable with its coefficient to the right.
12. (E) ![]()
13. (B) $ \widehat{back}$ = 0.056 + 0.920 (0.55) = 0.562 and so the residual = 0.59 – 0.562 = 0.028
14. (D) The sum and thus the mean of the residuals are always zero. In a good straight-line fit, the residuals show a random pattern.
15. (C) The coefficient of determination r2 gives the proportion of the y-variance that is predictable from a knowledge of x. In this case r2 = (0.632)2 = 0.399 or 39.9%.
16. (B) The point I doesn’t contribute to a line with negative or positive slope. In none of the scatterplots do the points fall on a straight line, so none of them have correlation 1.0.
17. (C) Predicted winning percentage = 44 + 0.0003(34,000) = 54.2, and
Residual = Observed – Predicted = 55 – 54.2 = 0.8.
18. (B) On each exam, two students had scores of 100. There is a general negative slope to the data showing a moderate negative correlation. The coefficient of determination, r2, is always $\geq$ 0. While several students scored 90 or above on one or the other exam, no student did so on both exams.
19. (E) On the scatterplot all the points lie perfectly on a line sloping up to the right, and so r = 1.
20. (A) The correlation is not changed by adding the same number to every value of one of the variables, by multiplying every value of one of the variables by the same positive number, or by interchanging the x– and y-variables.
21. (B) The slope and the correlation coefficient have the same sign. Multiplying every y-value by –1 changes this sign.
22. (E) A scatterplot readily shows that while the first three points lie on a straight line, the fourth point does not lie on this line. Thus no matter what the fifth point is, all the points cannot lie on a straight line, and so r cannot be 1.
23. (E) All three scatterplots show very strong nonlinear patterns; however, the correlation r measures the strength of only a linear association. Thus r = 0 in the first two scatterplots and is close to 1 in the third.
24. (A) Using your calculator, find the regression line to be $ \widehat{y}$ = 9x – 8. The regression line, also called the least squares regression line, minimizes the sum of the squares of the vertical distances between the points and the line. In this case (2, 10), (3, 19), and (4, 28) are on the line, and so the minimum sum is (10 – 11)2 + (19 – 17)2 + (28 – 29)2 = 6.
25. (B) When transforming the variables leads to a linear relationship, the original variables have a nonlinear relationship, their correlation (which measures linearity) is not close to 1, and the residuals do not show a random pattern. While r close to 1 indicates strong association, it does not indicate cause and effect.
26. (E) The least squares line passes through $(\overline{x},\overline{y})=(2,4)$, and the slope b satisfies![]()
FREE-RESPONSE
1. (a) A calculator gives $\widehat{Attendance}=$ 12,416 + 180.4 (Wins).
(b) Each additional home win raises the average attendance by about 180 people, on average.
(c) 12,416 + 180.4(25) = 16,926
(d) 17,000 = 12,416 + 180.4(Wins) gives Wins = 25.4 so 26 wins needed to average at least 17,000 average attendance.
(e) With 34 wins, the predicted average attendance is 12,416 + 180.4(34) = 18,550 so the residual is 18,997 – 18,550 = 447.
2. (a)
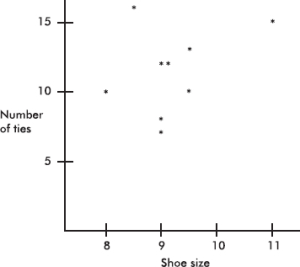
(b) A calculator gives r = 0.1568.
(c) The correlation r is low for this number of data scores, and the scatterplot shows no linear pattern whatsoever. Although theoretically we could use our techniques to find the best-fitting straight-line approximation, the result would be meaningless and should not be used for predictions.
3. (a) By visual inspection $\overline{x}$ ≈ 68 and $\overline{y}$ ≈ 21.
(b) The range of the life expectancies is 80 – 54 = 26, and so the standard deviation is roughly 26/4=6.5. Similarly the standard deviation of the per capita incomes is roughly $\frac{30-10}{4}=5$.
(c) While the points generally fall from the lower left to the upper right, they are still widely scattered. Thus the scatterplot shows a weak positive correlation between per capita income and life expectancy.
4. (a) The correlation for each of the three sets is 0.
(b) The correlation for the set consisting of all 12 scores is 0.9948.
(c) The data from each set taken separately show no linear pattern. However, together they show a strong linear fit. Note the positions of the data from the separate sets in the complete scatterplot.
5. In the first scatterplot, the points fall exactly on a downward sloping straight line, so r = –1. In the second scatterplot, the isolated point is an influential point, and r is close to +1. In the third scatterplot, the isolated point is also influential, and r is close to 0.
6. (a) $\widehat{y}$ = –0.16(50) + 34.8 = 26.8 miles per gallon, and $\widehat{y}$ = –0.0032(50)2 + 0.258(50) + 23.8 = 28.7 miles per gallon.
(b) Model 2 is the better fit. First, the residuals are much smaller for model 2, indicating that this model gives values much closer to the observed values. Second, a curved residual pattern like that in model 1 indicates that a nonlinear model would be better. A more uniform residual scatter as in model 2 indicates a better fit.
7. (a) The correlation coefficient is ![]() It is positive because the slope of the regression line is positive.
It is positive because the slope of the regression line is positive.
(b) The slope is 1.106, signifying that each additional page raises a grade by 1.106.
(c) Including Mary’s paper will lower the correlation coefficient because her result seems far off the regression line through the other points.
(d) Including Mary’s paper will swing the regression line down and lower the value of the slope.
(e) From the graph, Mary received an 82. From the regression line, Mary would have received $\widehat{y}$ = 46.51 + 1.106(45) = 96.3 if she had turned in her paper on time.
8. (a) Yes. The residual graph is not curved, does not show fanning, and appears to be random or scattered.
(b) The slope is 0.95893, indicating that the winning jump improves 0.95893 inches per year on average or about 3.8 inches every four years on average.
(c) With r2 = 0.921, the correlation r is 0.96.
(d) 0.95893(80) + 256.576 ≈ 333.3 inches
(e) The residual for 1980 is +2, and so the actual winning distance must have been 333.3 + 2 = 335.3 inches.
9. (a)
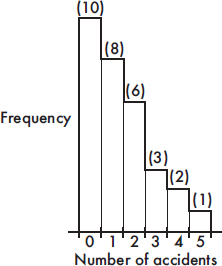
(b)
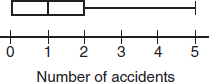
(c) There is a roughly linear trend with daily accidents increasing during the month.
(d) The daily number of accidents is strongly skewed to the right.
10. (a) The correlation coefficient ![]() It is positive because the slope of the regression line is positive.
It is positive because the slope of the regression line is positive.
(b) The slope is 8.5, signifying that each gram of medication lowers the pulse rate by 8.5 beats per minute.
(c) $\widehat{y}$ = –1.68 + 8.5(2.25) = 17.4 beats per minute.
(d) There is always danger in using a regression line to extrapolate beyond the values of x contained in the data. In this case, the 5 grams was an overdose, the patient died, and the regression line cannot be used for such values beyond the data set.
(e) Removing the 3-gram result from the data set will increase the correlation coefficient because the 3-gram result appears to be far off a regression line through the remaining points.
(f) Removing the 3-gram result from the data set will swing the regression line upward so that the slope will increase.
MARGINAL FREQUENCIES AND DISTRIBUTIONS
CONDITIONAL FREQUENCIES AND DISTRIBUTIONS
While many variables such as age, income, and years of education are quantitative or numerical in nature, others such as gender, race, brand preference, mode of transportation, and type of occupation are qualitative or categorical. Quantitative variables, too, are sometimes grouped into categorical classes.
MARGINAL FREQUENCIES AND DISTRIBUTIONS
Qualitative data often encompass two categorical variables that may or may not have a dependent relationship. These data can be displayed in a two-way contingency table.
EXAMPLE 5.1
The Cuteness Factor: A Japanese study had volunteers look at pictures of cute baby animals, adult animals, or tasty-looking foods, after which they tested their focus in solving puzzles.
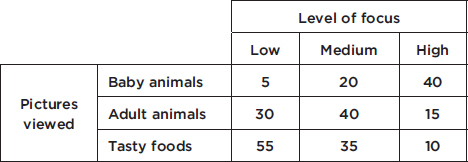
Pictures viewed is the row variable, whereas level of focus is the column variable. One method of analyzing these data involves calculating the totals for each row and each column.
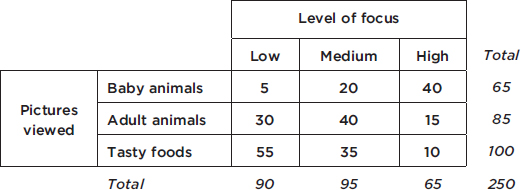
These totals are placed in the right and bottom margins of the table and thus are called marginal frequencies (or marginal totals). These marginal frequencies can then be put in the form of proportions or percentages. The marginal distribution of the level of focus is
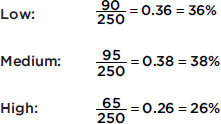
This distribution can be displayed in a bar graph as follows;
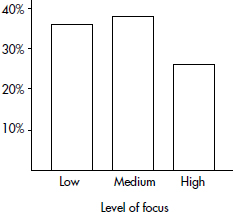
Similarly, we can determine the marginal distribution for the pictures viewed:
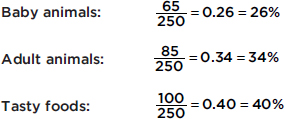
The representative bar graph is
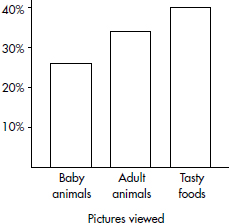
CONDITIONAL FREQUENCIES AND DISTRIBUTIONS
The marginal distributions described and calculated above do not describe or measure the relationship between the two categorical variables. For this we must consider the information in the body of the table, not just the sums in the margins.
EXAMPLE 5.2
We are interested in predicting the level of focus from the pictures viewed, and so we look at conditional frequencies for each row separately. For example, in Example 5.1 what proportion or percentage of the participants who viewed baby animals then had each of the levels of focus?
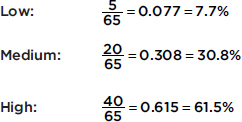
This conditional distribution can be displayed either with groupings of bars or by a segmented bar chart where each segment has a length corresponding to its relative frequency:
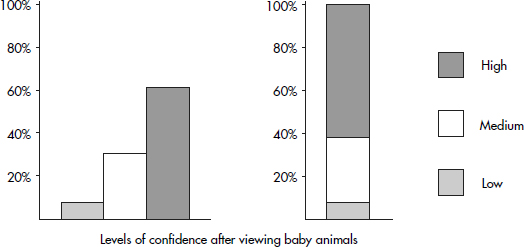
Similarly, the conditional distribution for the participants who viewed adult animals are
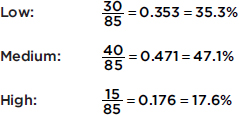
For the participants who viewed the tasty foods, we have
Both of the following bar charts give good visual pictures:
EXAMPLE 5.3
A study was made to compare year in high school with preference for vanilla or chocolate ice cream with the following results:
What are the conditional relative frequencies for each class?
In such a case, where all the conditional relative frequency distributions are identical, we say that the two variables show perfect independence. (However, it should be noted that even if the two variables are completely independent, the chance is very slim that a resulting contingency table will show perfect independence.)
EXAMPLE 5.4
Suppose you need heart surgery and are trying to decide between two surgeons, Dr. Fixit and Dr. Patch. You find out that each operated 250 times last year with the following results:
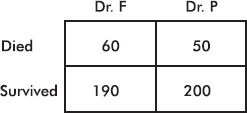
Whom should you go to? Among Dr. Fixit’s 250 patients 190 survived, for a survival rate of 190/250=0.76 or 76%, while among Dr. Patch’s 250 patients 200 survived, for a survival rate of 200/250=0.80 or 80%. Your choice seems clear.
However, everything may not be so clear-cut. Suppose that on further investigation you determine that the surgeons operated on patients who were in either good or poor condition with the following results:

Note that adding corresponding boxes from these two tables gives the original table above.
How do the surgeons compare when operating on patients in good health? Dr. Fixit’s 68 patients in good condition have a survival rate of 60/68=0.882 or 88.2%, while Dr. Patch’s 137 patients in good condition have a survival rate of 120/137=0.876 or 87.6%. Similarly, we note that Dr. Fixit’s 182 patients in poor condition have a survival rate of 130/182=0.714 or 71.4%, while Dr. Patch’s 113 patients in poor condition have a survival rate of 80/113=0.708 or 70.8%.
Thus Dr. Fixit does better with patients in good condition (88.2% versus Dr. Patch’s 87.6%) and also does better with patients in poor condition (71.4% versus Dr. P’s 70.8%). However, Dr. Fixit has a lower overall patient survival rate (76% versus Dr. Patch’s 80%)! How can this be?
This problem is an example of Simpson’s paradox, where a comparison can be reversed when more than one group is combined to form a single group. The effect of another variable, sometimes called a lurking variable, is masked when the groups are combined. In this particular example, closer scrutiny reveals that Dr. Fixit operates on many more patients in poor condition than Dr. Patch, and these patients in poor condition are precisely the ones with lower survival rates. Thus even though Dr. Fixit does better with all patients, his overall rating is lower. Our original table hid the effect of the lurking variable related to the condition of the patients.
SUMMARY
Two-way contingency tables are useful in showing relationships between two categorical variables.
The row and column totals lead to calculations of the marginal distributions.
Focusing on single rows or columns leads to calculations of conditional distributions.
Segmented bar charts are a useful visual tool to show conditional distributions.
Simpson’s paradox occurs when the results from a combined grouping seem to contradict the results from the individual groups.
Multiple-Choice Questions
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
Questions 1–5 are based on the following: To study the relationship between party affiliation and support for a balanced budget amendment, 500 registered voters were surveyed with the following results:
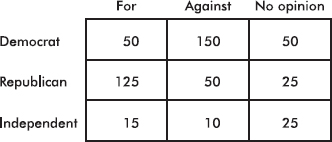
1. What percentage of those surveyed were Democrats?
(A) 10%
(B) 20%
(C) 30%
(D) 40%
(E) 50%
2. What percentage of those surveyed were for the amendment and were Republicans?
(A) 25%
(B) 38%
(C) 40%
(D) 62.5%
(E) 65.8%
3. What percentage of Independents had no opinion?
(A) 5%
(B) 10%
(C) 20%
(D) 25%
(E) 50%
4. What percentage of those against the amendment were Democrats?
(A) 30%
(B) 42%
(C) 50%
(D) 60%
(E) 71.4%
5. Voters of which affiliation were most likely to have no opinion about the amendment?
(A) Democrat
(B) Republican
(C) Independent
(D) Republican and Independent, equally
(E) Democrat, Republican, and Independent, equally
Questions 6–10 are based on the following: A study of music preferences in three geographic locations resulted in the following segmented bar chart:
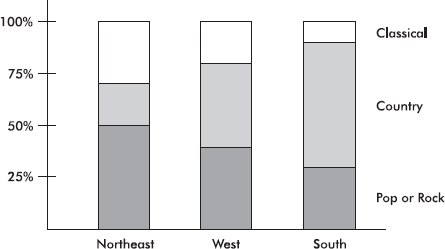
6. What percentage of those surveyed from the Northeast prefer country music?
(A) 20%
(B) 30%
(C) 40%
(D) 50%
(E) 70%
7. Which of the following is greatest?
(A) The percentage of those from the Northeast who prefer classical.
(B) The percentage of those from the West who prefer country.
(C) The percentage of those from the South who prefer pop or rock.
(D) The above are all equal.
(E) It is impossible to determine the answer without knowing the actual numbers of people involved.
8. Which of the following is greatest?
(A) The number of people in the Northeast who prefer pop or rock.
(B) The number of people in the West who prefer classical.
(C) The number of people in the South who prefer country.
(D) The above are all equal.
(E) It is impossible to determine the answer without knowing the actual numbers of people involved.
9. All three bars have a height of 100%.
(A) This is a coincidence.
(B) This happened because each bar shows a complete distribution.
(C) This happened because there are three bars each divided into three segments.
(D) This happened because of the nature of musical patterns.
(E) None of the above is true.
10. Based on the given segmented bar chart, does there seem to be a relationship between geographic location and music preference?
(A) Yes, because the corresponding segments of the three bars have different lengths.
(B) Yes, because the heights of the three bars are identical.
(C) Yes, because there are three segments and three bars.
(D) No, because the heights of the three bars are identical.
(E) No, because summing the corresponding segments for classical, summing the corresponding segments for country, and summing the corresponding segments for pop or rock all give approximately the same total.
11. In the following table, what value for n results in a table showing perfect independence?
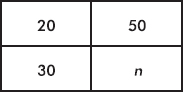
(A) 10
(B) 40
(C) 60
(D) 75
(E) 100
12. A company employs both men and women in its secretarial and executive positions. In reports filed with the government, the company shows that the percentage of female employees who receive raises is higher than the percentage of male employees who receive raises. A government investigator claims that the percentage of male secretaries who receive raises is higher than the percentage of female secretaries who receive raises, and that the percentage of male executives who receive raises is higher than the percentage of female executives who receive raises. Is this possible?
(A) No, either the company report is wrong or the investigator’s claim is wrong.
(B) No, if the company report is correct, then either a greater percentage of female secretaries than of male secretaries receive raises or a greater percentage of female executives than of male executives receive raises.
(C) No, if the investigator is correct, then by summation of the corresponding numbers, the total percentage of male employees who receive raises would have to be greater than the total percentage of female employees who receive raises.
(D) All of the above are true.
(E) It is possible for both the company report to be true and the investigator’s claim to be correct.
Free-Response Questions
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your final answers.
TWO OPEN-ENDED QUESTIONS
1. The following table gives the numbers (in thousands) of officers and enlisted personnel by military branch in the U.S. armed forces.
Army | Navy | Marine Corps | Air Force | |
Officers | 88 | 52 | 20 | 65 |
Enlisted | 452 | 276 | 178 | 258 |
(a) Calculate the percentage
i. of military men and women who are enlisted.
ii. of military men and women who are not Marine Corps officers.
iii. of officers who are in the Navy.
(b) Construct a graphical display showing the association between career path (officer vs. enlisted) and military branch.
(c) Summarize what the graphical display illustrates about the association between career path (officer vs. enlisted) and military branch.
2. The graduate school at the University of California at Berkeley reported that in 1973 they accepted 44% of 8442 male applicants and 35% of 4321 female applicants. Concerned that one of their programs was guilty of gender bias, the graduate school analyzed admissions to the six largest graduate programs and obtained the following results:
Program | Men Accepted | Men Rejected | Women Accepted | Women Rejected |
A | 511 | 314 | 89 | 19 |
B | 352 | 208 | 17 | 8 |
C | 120 | 205 | 202 | 391 |
D | 137 | 270 | 132 | 243 |
E | 53 | 138 | 95 | 298 |
F | 22 | 351 | 24 | 317 |
(a) Find the percentage of men and the percentage of women accepted by each program. Comment on any pattern or bias you see.
(b) Find the percentage of men and the percentage of women accepted overall by these six programs. Does this appear to contradict the results from part (a)?
(c) If you worked in the Graduate Admissions Office, what would you say to an inquiring reporter who is investigating gender bias in graduate admissions?
MULTIPLE-CHOICE
1. (E) Of the 500 people surveyed, 50 + 150 + 50 = 250 were Democrats, and 250/500=0.5 or 50%.
2. (A) Of the 500 people surveyed, 125 were both for the amendment and Republicans, and 125/500=0.25 ỏ 25%.
3. (E) There were 15 + 10 + 25 = 50 Independents; 25 of them had no opinion, and 25/50= 0.5 or 50%.
4. (E) There were 150 + 50 + 10 = 210 people against the amendment; 150 of them were Democrats, and 150/210=0.714 ỏ 71.4%.
5. (C) The percentages of Democrats, Republicans, and Independents with no opinion are 20%, 12.5%, and 50%, respectively.
6. (A) In the bar corresponding to the Northeast, the segment corresponding to country music stretches from the 50% level to the 70% level, indicating a length of 20%.
7. (B) Based on lengths of indicated segments, the percentage from the West who prefer country is the greatest.
8. (E) The given bar chart shows percentages, not actual numbers.
9. (B) In a complete distribution, the probabilities sum to 1, and the relative frequencies total 100%.
10. (A) The different lengths of corresponding segments show that in different geographic regions different percentages of people prefer each of the music categories.
11. (D) Relative frequencies must be equal. Either looking at rows gives $\frac{20}{70}=\frac{30}{30+n}$ or looking at columns gives $\frac{20}{50}=\frac{50}{50+n}$. We could also set up a proportion $\frac{n}{30}=\frac{50}{20}$ or $\frac{n}{50}=\frac{30}{20}$ Solving any of these equations gives n = 75.
12. (E) It is possible for both to be correct, for example, if there were 11 secretaries (10 women, 3 of whom receive raises, and 1 man who receives a raise) and 11 executives (10 men, 1 of whom receives a raise, and 1 woman who does not receive a raise). Then 100% of the male secretaries receive raises while only 30% of the female secretaries do; and 10% of the male executives receive raises while 0% of the female executives do. However, overall 3 out of 11 women receive raises, while only 2 out of 11 men receive raises. This is an example of Simpson’s paradox.
FREE-RESPONSE
1. (a)
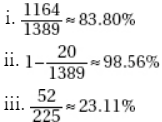
(b) Calculate row or column totals, and then show either a side-by-side bar graph or a segmented bar graph, showing percentages, and conditioned on either career path (officer vs. enlisted) or military branch:
(c) The Army and the Navy have about the same percentage of officers (16%), while the Air Force has a higher percentage of officers (20%), and the Marine Corps has a lower percentage of officers (10%).
OR
Among the officers and the enlisted career paths there are about the same percentage Army (39%), and about the same percentage Navy (23%), while the officers have a lower percentage Marine Corps than the enlisted (9% vs. 16%) and the officers have a higher percentage Air Force than the enlisted (29% vs. 22%).
2. (a)
Program | Percentage of Men Accepted (%) | Percentage of Women Accepted (%) |
A | 62 | 82 |
B | 63 | 68 |
C | 37 | 34 |
D | 33 | 35 |
E | 28 | 24 |
F | 6 | 7 |
There doesn’t appear to be any real pattern; however, women seem to be favored in four of the programs, while men seem to be slightly favored in the other two programs.
(b) Overall, 1195 out of 2681 male applicants were accepted, for a 45% acceptance rate, while 559 out of 1835 female applicants were accepted, for a 30% acceptance rate. This appears to contradict the results from part a.
(c) You should tell the reporter that while it is true that the overall acceptance rate for women is 30% compared to the 44% acceptance rate for men, program by program women have either higher acceptance rates or only slightly lower acceptance rates than men. The reason behind this apparent paradox is that most men applied to programs A and B, which are easy to get into and have high acceptance rates. However, most women applied to programs C, D, E, and F, which are much harder to get into and have low acceptance rates.
CENSUS
SAMPLE SURVEY
EXPERIMENT
OBSERVATIONAL STUDY
In the real world, time and cost considerations usually make it impossible to analyze an entire population. Does the government question you and your parents before announcing the monthly unemployment rates? Does a television producer check every household’s viewing preferences before deciding whether a pilot program will be continued? In studying statistics we learn how to estimate population characteristics by considering a sample. For example, later in this book we will see how to estimate population means and proportions by looking at sample means and proportions.
To derive conclusions about the larger population, we need to be confident that the sample we have chosen represents that population fairly. Analyzing the data with computers is often easier than gathering the data, but the frequently quoted “Garbage in, garbage out” applies here. Nothing can help if the data are badly collected. Unfortunately, many of the statistics with which we are bombarded by newspapers, radio, and television are based on poorly designed data collection procedures.
A census is a complete enumeration of an entire population. In common use, it is often thought of as an official attempt to contact every member of the population, usually with details regarding age, marital status, race, gender, occupation, income, years of school completed, and so on. Every 10 years the U.S. Bureau of the Census divides the nation into nine regions and attempts to gather information about everyone in the country. A massive amount of data is obtained, but even with the resources of the U.S. government, the census is not complete. For example, many homeless people are always missed, or counted at two temporary residences, and there are always households that do not respond even after repeated requests for information. It is estimated that the 2010 census missed about 2.1% of Black Americans and 1.5% of Hispanics, together accounting for some 1.5 million people.
In most studies, both in the private and public sectors, a complete census is unreasonable because of time and cost involved. Furthermore, attempts to gather complete data have been known to lead to carelessness. Finally, and most important, a well-designed, well-conducted sample survey is far superior to a poorly designed study involving a complete census. For example, a poorly worded question might give meaningless data even if everyone in the population answers.
The census tries to count everyone; it is not a sample. A sample survey aims to obtain information about a whole population by studying a part of it, that is, a sample. The goal is to gather information without disturbing or changing the population. Numerous procedures are used to collect data through sampling, and much of the statistical information distributed to us comes from sample surveys. Often, controlled experiments are later undertaken to demonstrate relationships suggested by sample surveys.
However, the one thing that most quickly invalidates a sample and makes useful information impossible to obtain is bias. A sample is biased if in some critical way it does not represent the population. The main technique to avoid bias is to incorporate randomness into the selection process. Randomization protects us from effects and influences, both known and unknown. Finally, the larger the sample, the better the results, but what is critical is the sample size, not the percentage or fraction of the population. That is, a random sample of size 500 from a population of size 100,000 is just as representative as a random sample of size 500 from a population of size 1,000,000.
In a controlled study, called an experiment, the researcher should randomly divide subjects into appropriate groups. Some action is taken on one or more of the groups, and the response is observed. For example, patients may be randomly given unmarked capsules of either aspirin or acetaminophen and the effects of the medication measured. Experiments often have a treatment group and a control group; in the ideal situation, neither the subjects nor the researcher knows which group is which. The Salk vaccine experiment of the 1950s, in which half the children received the vaccine and half were given a placebo, with not even their doctors knowing who received what, is a classic example of this double-blind approach. Controlled experiments can indicate cause-and-effect relationships.
The critical principles behind good experimental design include control (outside of who receives what treatments, conditions should be as similar as possible for all involved groups), blocking (the subjects can be divided into representative groups to bring certain differences directly into the picture), randomization (unknown and uncontrollable differences are handled by randomizing who receives what treatments), replication (treatments need to be repeated on a sufficient number of subjects), and generalizability (ability to repeat an experiment in a variety of settings).
Sample surveys are one example of what are called observational studies. In observational studies there is no choice in regard to who goes into the treatment and control groups. For example, a researcher cannot ethically tell 100 people to smoke three packs of cigarettes a day and 100 others to smoke only one pack per day; he can only observe people who habitually smoke these amounts. In observational studies the researcher strives to determine which variables affect the noted response. While results may suggest relationships, it is difficult to conclude cause and effect.
Observational studies are primary, vital sources of data; however, they are a poor method of measuring the effect of change. To evaluate responses to change, one must impose change, that is, perform an experiment. Furthermore, observational studies on the impact of some variable on another variable often fail because explanatory variables are confounded with other variables.
SUMMARY
A complete census is usually unreasonable because of time and cost constraints.
Estimate population characteristics (called parameters) by considering statistics from a sample.
Analysis of badly gathered sample data is usually a meaningless exercise.
A sample is biased if in some critical way it does not represent the population.
The main technique to avoid bias is to incorporate randomness into the selection process.
Experiments involve applying a treatment to one or more groups and observing the responses.
Observational studies involve observing responses to choices people make.
Multiple-Choice Questions
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. When travelers change airlines during connecting flights, each airline receives a portion of the fare. Several years ago, the major airlines used a sample trial period to determine what percentage of certain fares each should collect. Using these statistical results to determine fare splits, the airlines now claim huge savings over previous clerical costs. Which of the following is true?
(A) The airlines ran an experiment using a trial period for the control group.
(B) The airlines ran an experiment using fare splits as treatments.
(C) The airlines ran an observational study using the calculations from a trial period as a sample.
(D) The airlines ran an observational study, but fare splits were a confounding variable.
(E) The airlines tried to gather a census but ended up with a sample.
2. Which of the following is not true?
(A) In an experiment some treatment is intentionally forced on one group to note the response.
(B) In an observational study information is gathered on an already existing situation.
(C) Sample surveys are observational studies, not experiments.
(D) While observational studies may suggest relationships, it is usually not possible to conclude cause and effect because of the lack of control over possible confounding variables.
(E) A complete census is the only way to establish a cause-and-effect relationship absolutely.
3. In one study on the effect of niacin on cholesterol level, 100 subjects who acknowledged being long-time niacin takers had their cholesterol levels compared with those of 100 people who had never taken niacin. In a second study, 50 subjects were randomly chosen to receive niacin and 50 were chosen to receive a placebo.
(A) The first study was a controlled experiment, while the second was an observational study.
(B) The first study was an observational study, while the second was a controlled experiment.
(C) Both studies were controlled experiments.
(D) Both studies were observational studies.
(E) Each study was part controlled experiment and part observational study.
4. In one study subjects were randomly given either 500 or 1000 milligrams of vitamin C daily, and the number of colds they came down with during a winter season was noted. In a second study people responded to a questionnaire asking about the average number of hours they sleep per night and the number of colds they came down with during a winter season.
(A) The first study was an experiment without a control group, while the second was an observational study.
(B) The first study was an observational study, while the second was a controlled experiment.
(C) Both studies were controlled experiments.
(D) Both studies were observational studies.
(E) None of the above is a correct statement.
5. In a 1992 London study, 12 out of 20 migraine sufferers were given chocolate whose flavor was masked by peppermint, while the remaining eight sufferers received a similar-looking, similar-tasting tablet that had no chocolate. Within 1 day, five of those receiving chocolate complained of migraines, while no complaints were made by any of those who did not receive chocolate. Which of the following is a true statement?
(A) This study was an observational study of 20 migraine sufferers in which it was noted how many came down with migraines after eating chocolate.
(B) This study was a sample survey in which 12 out of 20 migraine sufferers were picked to receive peppermint-flavored chocolate.
(C) A census of 20 migraine sufferers was taken, noting how many were given chocolate and how many developed migraines.
(D) A study was performed using chocolate as a placebo to study one cause of migraines.
(E) An experiment was performed comparing a treatment group that was given chocolate to a control group that was not.
6. Suppose you wish to compare the average class size of mathematics classes to the average class size of English classes in your high school. Which is the most appropriate technique for gathering the needed data?
(A) Census
(B) Sample survey
(C) Experiment
(D) Observational study
(E) None of these methods is appropriate.
7. Two studies are run to compare the experiences of families living in high-rise public housing to those of families living in townhouse subsidized rentals. The first study interviews 25 families who have been in each government program for at least 1 year, while the second randomly assigns 25 families to each program and interviews them after 1 year. Which of the following is a true statement?
(A) Both studies are observational studies because of the time period involved.
(B) Both studies are observational studies because there are no control groups.
(C) The first study is an observational study, while the second is an experiment.
(D) The first study is an experiment, while the second is an observational study.
(E) Both studies are experiments.
8. Two studies are run to determine the effect of low levels of wine consumption on cholesterol level. The first study measures the cholesterol levels of 100 volunteers who have not consumed alcohol in the past year and compares these values with their cholesterol levels after 1 year, during which time each volunteer drinks one glass of wine daily. The second study measures the cholesterol levels of 100 volunteers who have not consumed alcohol in the past year, randomly picks half the group to drink one glass of wine daily for a year while the others drink no alcohol for the year, and finally measures their levels again. Which of the following is a true statement?
(A) The first study is an observational study, while the second is an experiment.
(B) The first study is an experiment, while the second is an observational study.
(C) Both studies are observational studies, but only one uses both randomization and a control group.
(D) The first study is a census of 100 volunteers, while the second study is an experiment.
(E) Both studies are experiments.
MULTIPLE-CHOICE
1. (C) This study is not an experiment in which responses are being compared. It is an observational study in which the airlines use split fare calculations from a trial period as a sample to indicate the pattern of all split fare transactions. A census listing all possible connecting flights was not attempted.
2. (E) The first two sentences can be considered part of the definitions of experiment and observational study. A sample survey does not impose any treatment; it simply counts a certain outcome, and so it is an observational study, not an experiment. A complete census can provide much information about a population, but it doesn’t necessarily establish a cause-and-effect relationship among seemingly related population parameters.
3. (B) The first study was observational because the subjects were not chosen for treatment.
4. (A) The first study was an experiment with two treatment groups and no control group. The second study was observational; the researcher did not randomly divide the subjects into groups and have each group sleep a designated number of hours per night.
5. (E) This study was an experiment in which the researchers divided the subjects into treatment and control groups. A census would involve a study of all migraine sufferers, not a sample of 20. The response of the treatment group receiving chocolate was compared to the response of the control group receiving a placebo. The peppermint tablet with no chocolate was the placebo.
6. (A) The main office at your school should be able to give you the class sizes of every math and English class. If need be, you can check with every math and English teacher.
7. (C) In the first study the families were already in the housing units, while in the second study one of two treatments was applied to each family.
8. (E) Both studies apply treatments and measure responses, and so both are experiments.
SIMPLE RANDOM SAMPLING
CHARACTERISTICS OF A WELL-DESIGNED, WELL-CONDUCTED SURVEY
SAMPLING ERROR
SOURCES OF BIAS
OTHER SAMPLING METHODS
Most data collection involves observational studies, not controlled experiments. Furthermore, while most data collection has some purpose, many studies come to mind after the data have been assembled and examined. For data collection to be useful, the resulting sample must be representative of the population under consideration.
How can a good, that is, a representative, sample be chosen? One technique would be to write the name of each member of the population on a card, mix the cards thoroughly in a large box, and pull out a specified number of cards. This method would give everyone in the population an equal chance of being selected as part of the sample. Unfortunately, this method is usually too time-consuming and too costly, and bias might still creep in if the mixing is not thorough. A simple random sample, that is, one in which every possible sample of the desired size has an equal chance of being selected, can more easily be obtained by assigning a number to everyone in the population and using a random number table or having a computer generate random numbers to indicate choices.
EXAMPLE 7.1
Suppose 80 students are taking an AP Statistics course and the teacher wants to randomly pick out a sample of 10 students to try out a practice exam. She first assigns the students numbers 01, 02, 03, …, 80. Reading off two digits at a time from a random number table, she ignores any over 80 and ignores repeats, stopping when she has a set of ten. If the table began 75425 56573 90420 48642 27537 61036 15074 84675, she would choose the students numbered 75, 42, 55, 65, 73, 04, 27, 53, 76, and 10. Note that 90 and 86 are ignored because they are over 80, and the second and third occurrences of 42 are ignored because they are repeats.
CHARACTERISTICS OF A WELL-DESIGNED, WELL-CONDUCTED SURVEY
A well-designed survey always incorporates chance, such as using random numbers from a table or a computer. However, the use of probability techniques is not enough to ensure a representative sample. Often we don’t have a complete listing of the population, and so we have to be careful about exactly how we are applying “chance.” Even when subjects are picked by chance, they may choose not to respond to the survey or they may not be available to respond, thus calling into question how representative the final sample really is. The wording of the questions must be neutral—subjects give different answers depending on the phrasing.
EXAMPLE 7.2
Suppose we are interested in determining the percentage of adults in a small town who eat a nutritious breakfast. How about randomly selecting 100 numbers out of the telephone book, calling each one, and asking whether the respondent is intelligent enough to eat a nutritious breakfast every morning?
Answer: Random selection is good, but a number of questions should be addressed. For example, are there many people in the town without telephones or with unlisted numbers? How will the time of day the calls are made affect whether the selected people are reachable? If people are unreachable, will replacements be randomly chosen in the same way or will this lead to a certain class of people being underrepresented? Finally, even if these issues are satisfactorily addressed, the wording of the question is clearly not neutral—unless the phrase intelligent enough is dropped, answers will be almost meaningless.
SAMPLING ERROR: THE VARIATION INHERENT IN A SURVEY
No matter how well-designed and well-conducted a survey is, it still gives a sample statistic as an estimate for a population parameter. Different samples give different sample statistics, all of which are estimates for the same population parameter, and so error, called sampling error, is naturally present. This error can be described using probability; that is, we can say how likely we are to have a certain size error. Generally, the chance of this error occurring is smaller when the sample size is larger. However, the way the data are obtained is crucial—a large sample size cannot make up for a poor survey design or faulty collection techniques. Only a complete census can prevent sampling error; that is, whenever a sample is taken, sampling error will be present.
EXAMPLE 7.3
Each of four major news organizations surveys likely voters and separately reports that the percentage favoring the incumbent candidate is 53.4%, 54.1%, 52.0%, and 54.2%, respectively. What is the correct percentage? Did three or more of the news organizations make a mistake?
Answer: There is no way of knowing the correct population percentage from the information given. The four surveys led to four statistics, each an estimate of the population parameter. No one made a mistake unless there was a bad survey, for example, one without the use of chance, or not representative of the population, or with poor wording of the question. Sampling differences are natural.
TIP
Sampling error is to be expected, while bias is to be avoided.
Poorly designed sampling techniques result in bias, that is, in a tendency to favor the selection of certain members of a population. If a study is biased, size doesn’t help—a large sample size will simply result in a large worthless study. Think about bias before running a study, because once all the data comes in, there is no way to recover if the sample was biased. Sometimes pilot testing with a small sample will show bias that can be corrected before a larger sample is obtained. Although each of the following sources of bias is defined separately, there is overlap, and many if not most examples of bias involve more than one of the following.
HOUSEHOLD BIAS: When a sample includes only one member of any given household, members of large households are underrepresented. To respond to this, pollsters sometimes give greater weight to members of larger households.
NONRESPONSE BIAS: A good example is that of most mailed questionnaires, as they tend to have very low response percentages, and it is often unclear which part of the population is responding. Sometimes people chosen for a survey simply refuse to respond or are unreachable or too difficult to contact. Answering machines and caller ID prevent easy contacts. To maximize response rates, one can use multiple follow-up contacts and cash or other incentives. Also, short, easily understood surveys generally have higher response rates.
QUOTA SAMPLING BIAS: This results when interviewers are given free choice in picking people, for example, to obtain a particular percentage men, a particular percentage Catholic, or a particular percentage African-American. This flawed technique resulted in misleading polls leading to the Chicago Tribune making an early incorrect call of Thomas E. Dewey as the winner over Harry S. Truman in the 1948 presidential election.
RESPONSE BIAS: The very question itself can lead to misleading results. People often don’t want to be perceived as having unpopular or unsavory views and so may respond untruthfully when face to face with an interviewer or when filling out a questionnaire that is not anonymous. Patients may lie about following doctors’ orders, dieters may be dishonest about how strictly they’ve followed a weight loss program, students may shade the truth about how many hours they’ve studied for exams, and viewers may not want to admit they they watch certain television programs.
SELECTION BIAS: An often-cited example is the Literary Digest opinion poll that predicted a landslide victory for Alfred Landon over Franklin D. Roosevelt in the 1936 presidential election. The Digest surveyed people with cars and telephones, but in 1936 only the wealthy minority, who mainly voted Republican, had cars and telephones. In spite of obtaining more than two million responses, the Digest picked a landslide for the wrong man!
TIP
Think about potential bias before collecting data.
SIZE BIAS: Throwing darts at a map to decide in which states to sample would bias in favor of geographically large states. Interviewing people checking out of the hospital would bias in favor of patients with short stays, since due to costs, more people today have shorter stays. Having each student pick one coin out of a bag of 1000 coins to help estimate the total monetary value of the coins in the bag would bias in favor of large coins, for example, quarters over dimes.
UNDERCOVERAGE BIAS: This happens when there is inadequate representation. For example, telephone surveys simply ignore all those possible subjects who don’t have telephones. In the 2008 presidential election surveys, phone surveys went only to land line phones, leaving out many young adults who have only cell phones. Another example is convenience samples, like interviews at shopping malls, which are based on choosing individuals who are easy to reach. These interviews tend to produce data highly unrepresentative of the entire population. Door-to-door household surveys typically miss college students and prison inmates, as well as the homeless.
VOLUNTARY RESPONSE BIAS: Samples based on individuals who offer to participate typically give too much emphasis to people with strong opinions. For example, radio call-in programs about controversial topics such as gun control, abortion, and school segregation do not produce meaningful data on what proportion of the population favor or oppose related issues. Online surveys posted to websites are a modern source of voluntary response bias.
WORDING BIAS: Nonneutral or poorly worded questions may lead to answers that are very unrepresentative of the population. To avoid such bias, do not use leading questions, and write questions that are clear and relatively short. Also be careful of sequences of questions that lead respondents toward certain answers.
Note: Again, it should be understood that there is considerable overlap among the above classifications. For example, a nonneutral question may be said to have both response bias and wording bias. Selection bias and undercoverage bias often go hand in hand. Voluntary response bias and nonresponse bias are clearly related.
Time- and cost-saving modifications are often used to implement sampling procedures other than simple random samples.
Systematic sampling involves listing the population in some order (for example, alphabetically), choosing a random point to start, and then picking every tenth (or hundredth, or thousandth, or kth) person from the list. This gives a reasonable sample as long as the original order of the list is not in any way related to the variables under consideration.
TIP
Know the difference between strata and clusters.
In stratified sampling the population is divided into homogeneous groups called strata, and random samples of persons from all strata are chosen. For example, we can stratify by age or gender or income level or race and pick a sample of people from each stratum. Note that all individuals in a given stratum have a characteristic in common. We could further do proportional sampling, where the sizes of the random samples from each stratum depend on the proportion of the total population represented by the stratum.
In cluster sampling the population is divided into heterogeneous groups called clusters, and we then take a random sample of clusters from among all the clusters. For example, to survey high school seniors we could randomly pick several senior class homerooms in which to conduct our study. Note that each cluster should resemble the entire population.
Multistage sampling refers to a procedure involving two or more steps, each of which could involve any of the various sampling techniques. The Gallup organization often follows a procedure in which nationwide locations are randomly selected, then neighborhoods are randomly selected in each of these locations, and finally households are randomly selected in each of these neighborhoods.
EXAMPLE 7.4
Suppose a sample of 100 high school students from a school of size 5000 is to be chosen to determine their views on the death penalty. One method would be to have each student write his or her name on a slip of paper, put the papers in a box, and have the principal reach in and pull out 100 of the papers. However, questions could arise regarding how well the papers are mixed up in the box. For example, how might the outcome be affected if all students in one homeroom toss in their names at the same time so that their papers are clumped together? Another method would be to assign each student a number from 1 to 5000 and then use a random number table, picking out four digits at a time and tossing out repeats and numbers over 5000 (simple random sampling). What are alternative procedures?
Answer: From a list of the students, the surveyor could simply note every fiftieth name (systematic sampling). Since students in each class have certain characteristics in common, the surveyor could use a random selection method to pick 25 students from each of the separate lists of freshmen, sophomores, juniors, and seniors (stratified sampling). The researcher could separate the homerooms by classes; then randomly pick five freshmen homerooms, five sophomore homerooms, five junior homerooms, and five senior homerooms (cluster sampling); and then randomly pick five students from each of the homerooms (multistage sampling). The surveyor could separately pick random samples of males and females (stratified sampling), the size of each of the two samples chosen according to the proportion of male and female students attending the school (proportional sampling).
It should be noted that none of the alternative procedures in the above example result in a simple random sample because every possible sample of size 100 does not have an equal chance of being selected.
SUMMARY
A simple random sample (SRS) is one in which every possible sample of the desired size has an equal chance of being selected.
Sampling error is not an error, but rather refers to the natural variability between samples.
Bias is the tendency to favor the selection of certain members of a population.
Nonresponse bias occurs when a large fraction of those sampled do not respond (most mailed questionnaires are good examples).
Response bias happens when the question itself leads to misleading results (for example, people don’t want to be perceived as having unpopular, unsavory, or illegal views).
Undercoverage bias occurs when part of the population is ignored (for example, telephone surveys miss all those without phones).
Voluntary response bias occurs when individuals choose whether to respond (for example, radio call-in surveys).
Systematic sampling involves listing the population, choosing a random point to start, and then picking every nth person for some n.
Stratified sampling involves dividing the population into homogeneous groups called strata and then picking random samples from each of the strata.
Cluster sampling involves dividing the population into heterogeneous groups called clusters, and then picking everyone in a random sample of the clusters.
Multistage sampling refers to procedures involving two or more steps, each of which could involve any of the sampling techniques.
Multiple-Choice Questions
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. Ann Landers, who wrote a daily advice column appearing in newspapers across the country, once asked her readers, “If you had it to do over again, would you have children?” Of the more than 10,000 readers who responded, 70% said no. What does this show?
(A) The survey is meaningless because of voluntary response bias.
(B) No meaningful conclusion is possible without knowing something more about the characteristics of her readers.
(C) The survey would have been more meaningful if she had picked a random sample of the 10,000 readers who responded.
(D) The survey would have been more meaningful if she had used a control group.
(E) This was a legitimate sample, randomly drawn from her readers and of sufficient size to allow the conclusion that most of her readers who are parents would have second thoughts about having children.
2. Which of the following is a true statement?
(A) If bias is present in a sampling procedure, it can be overcome by dramatically increasing the sample size.
(B) There is no such thing as a “bad sample.”
(C) Sampling techniques that use probability techniques effectively eliminate bias.
(D) Convenience samples often lead to undercoverage bias.
(E) Voluntary response samples often underrepresent people with strong opinions.
3. Two possible wordings for a questionnaire on gun control are as follows:
I. The United States has the highest rate of murder by handguns among all countries. Most of these murders are known to be crimes of passion or crimes provoked by anger between acquaintances. Are you in favor of a 7-day cooling-off period between the filing of an application to purchase a handgun and the resulting sale?
II. The United States has one of the highest violent crime rates among all countries. Many people want to keep handguns in their homes for self-protection. Fortunately, U.S. citizens are guaranteed the right to bear arms by the Constitution. Are you in favor of a 7-day waiting period between the filing of an application to purchase a needed handgun and the resulting sale?
One of these questions showed that 25% of the population favored a 7-day waiting period between application for purchase of a handgun and the resulting sale, while the other question showed that 70% of the population favored the waiting period. Which produced which result and why?
(A) The first question probably showed 70% and the second question 25% because of the lack of randomization in the choice of pro-gun and anti-gun subjects as evidenced by the wording of the questions.
(B) The first question probably showed 25% and the second question 70% because of a placebo effect due to the wording of the questions.
(C) The first question probably showed 70% and the second question 25% because of the lack of a control group.
(D) The first question probably showed 25% and the second question 70% because of response bias due to the wording of the questions.
(E) The first question probably showed 70% and the second question 25% because of response bias due to the wording of the questions.
4. Each of the 29 NBA teams has 12 players. A sample of 58 players is to be chosen as follows. Each team will be asked to place 12 cards with its players’ names into a hat and randomly draw out two names. The two names from each team will be combined to make up the sample. Will this method result in a simple random sample of the 348 basketball players?
(A) Yes, because each player has the same chance of being selected.
(B) Yes, because each team is equally represented.
(C) Yes, because this is an example of stratified sampling, which is a special case of simple random sampling.
(D) No, because the teams are not chosen randomly.
(E) No, because not each group of 58 players has the same chance of being selected.
5. To survey the opinions of bleacher fans at Wrigley Field, a surveyor plans to select every one-hundredth fan entering the bleachers one afternoon. Will this result in a simple random sample of Cub fans who sit in the bleachers?
(A) Yes, because each bleacher fan has the same chance of being selected.
(B) Yes, but only if there is a single entrance to the bleachers.
(C) Yes, because the 99 out of 100 bleacher fans who are not selected will form a control group.
(D) Yes, because this is an example of systematic sampling, which is a special case of simple random sampling.
(E) No, because not every sample of the intended size has an equal chance of being selected.
6. Which of the following is a true statement about sampling error?
(A) Sampling error can be eliminated only if a survey is both extremely well designed and extremely well conducted.
(B) Sampling error concerns natural variation between samples, is always present, and can be described using probability.
(C) Sampling error is generally larger when the sample size is larger.
(D) Sampling error implies an error, possibly very small, but still an error, on the part of the surveyor.
(E) Sampling error is higher when bias is present.
7. What fault do all these sampling designs have in common?
I. The Wall Street Journal plans to make a prediction for a presidential election based on a survey of its readers.
II. A radio talk show asks people to phone in their views on whether the United States should pay off its huge debt to the United Nations.
III. A police detective, interested in determining the extent of drug use by teenagers, randomly picks a sample of high school students and interviews each one about any illegal drug use by the student during the past year.
(A) All the designs make improper use of stratification.
(B) All the designs have errors that can lead to strong bias.
(C) All the designs confuse association with cause and effect.
(D) None of the designs satisfactorily controls for sampling error.
(E) None of the designs makes use of chance in selecting a sample.
8. A state auditor is given an assignment to choose and audit 26 companies. She lists all companies whose name begins with A, assigns each a number, and uses a random number table to pick one of these numbers and thus one company. She proceeds to use the same procedure for each letter of the alphabet and then combines the 26 results into a group for auditing. Which of the following is a true statement?
(A) Each company has an equal probability of being audited.
(B) Each set of 26 companies has an equal chance of being selected.
(C) Her procedure results in a simple random sample.
(D) Her procedure doesn’t truly make use of chance.
(E) She could have used a calculator random number generator in place of using a random number table to achieve similar results.
9. A researcher planning a survey of heads of households in a particular state has census lists for each of the 23 counties in that state. The procedure will be to obtain a random sample of heads of households from each of the counties rather than grouping all the census lists together and obtaining a sample from the entire group. Which of the following is an incorrect statement about the resulting stratified sample?
(A) It is not a simple random sample.
(B) It is easier and less costly to obtain than a simple random sample.
(C) It gives comparative information that a simple random sample wouldn’t give.
(D) A cluster sample would have been more appropriate.
(E) Differences in county sizes could be taken into account by making the size of the random sample from each county depend on the proportion of the total population represented by the county.
10. To find out the average occupancy size of student-rented apartments, a researcher picks a simple random sample of 100 such apartments. Even after one follow-up visit, the interviewer is unable to make contact with anyone in 27 of these apartments. Concerned about nonresponse bias, the researcher chooses another simple random sample and instructs the interviewer to continue this procedure until contact is made with someone in a total of 100 apartments. The average occupancy size in the final 100-apartment sample is 2.78. Is this estimate probably too low or too high?
(A) Too low, because of undercoverage bias.
(B) Too low, because convenience samples overestimate average results.
(C) Too high, because of undercoverage bias.
(D) Too high, because convenience samples overestimate average results.
(E) Too high, because voluntary response samples overestimate average results.
11. To conduct a survey of long-distance calling patterns, a researcher opens a telephone book to a random page, closes his eyes, puts his finger down on the page, and then reads off the next 50 names. Which of the following is incorrect?
(A) The survey design incorporates chance.
(B) Assuming the page and starting point on the page are randomly selected, each person in the phone book has an equal chance of being selected.
(C) The procedure could easily result in selection bias.
(D) The procedure does not result in a simple random sample.
(E) This is the typical methodology of a systematic sample.
12. Consider the following three events:
I. Although 18% of the student body are minorities, in a random sample of 20 students, 5 are minorities.
II. In a survey about sexual habits, an embarrassed student deliberately gives the wrong answers.
III. A surveyor mistakenly records answers to one question in the wrong space.
Which of the following correctly characterizes the above?
(A) I, sampling error; II, response bias; III, human mistake
(B) I, sampling error; II, nonresponse bias; III, hidden error
(C) I, hidden bias; II, voluntary sample bias; III, sampling error
(D) I, undercoverage error; II, voluntary error; III, unintentional error
(E) I, small sample error; II, deliberate error; III, mistaken error
13. A researcher plans a study to examine the depth of belief in God among the adult population. He obtains a simple random sample of 100 adults as they leave church one Sunday morning. All but one of them agree to participate in the survey. Which of the following is a true statement?
(A) Proper use of chance as evidenced by the simple random sample makes this a well-designed survey.
(B) The high response rate makes this a well-designed survey.
(C) Selection bias makes this a poorly designed survey.
(D) The validity of this survey depends on whether or not the adults attending this church are representative of all churches.
(E) The validity of this survey depends upon whether or not similar numbers of those surveyed are male and female.
Free-Response Questions
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your final answers.
SEVEN OPEN-ENDED QUESTIONS
1. Cell phones emit a form of electromagnetic radiation, and there is a concern on how this affects the human body. A World Health Organization (WHO) study of 12,000 people found no connection between moderate cell phone use and brain cancer, although the report does mention a higher incidence of brain cancer for heavy users (defined as those who used their phone for at least half an hour a day). A study of 420,095 persons in Denmark found no correlation between length of cell phone subscriptions (in years) and brain tumor incidence.
(a) Were these studies observational studies or experiments or one of each? Explain.
(b) Does the WHO study definition of “heavy users” seem reasonable? Explain.
(c) Neither study tries to distinguish between voice or text messaging use of the cell phone. Should this have any affect on conclusions? Explain.
(d) What is a weakness in the Denmark study that the WHO study does take into account?
2. A questionnaire is being designed to determine whether most people are or are not in favor of legislation protecting the habitat of the spotted owl. Give two examples of poorly worded questions, one biased toward each response.
3. To obtain a sample of 25 students from among the 500 students present in school one day, a surveyor decides to pick every twentieth student waiting in line to attend a required assembly in the gym.
(a) Explain why this procedure will not result in a simple random sample of the students present that day.
(b) Describe a procedure that will result in a simple random sample of the students present that day.
4. A hot topic in government these days is welfare reform. Suppose a congresswoman wishes to survey her constituents concerning their opinions on whether the federal government should turn welfare over to the states. Discuss possible sources of bias with regard to the following four options: (1) conducting a survey via random telephone dialing into her district, (2) sending out a mailing using a registered voter list, (3) having a pollster interview everyone who walks past her downtown office, and (4) broadcasting a radio appeal urging interested citizens in her district to call in their opinions to her office.
5. You and nine friends go to a restaurant and check your coats. You all forget to pick up the ticket stubs, and so when you are ready to leave, Hilda, the hatcheck girl, randomly gives each of you one of the ten coats. You are surprised that one person actually receives the correct coat. You would like to explore this further and decide to use a random number table to simulate the situation. Describe how the random number table can be used to simulate one trial of the coat episode. Explain what each of the digits 0 through 9 will represent.
6.
You are supposed to interview the residents of two of the above five houses.
(a) How would you choose which houses to interview?
(b) You plan to visit the homes at 9 a.m. If someone isn’t home, explain the reasons for and against substituting another house.
(c) Are there any differences you might expect to find among the residents based on the above sketch?
7. A cable company plans to survey potential customers in a small city currently served by satellite dishes. Two sampling methods are being considered. Method A is to randomly select a sample of 25 city blocks and survey every family living on those blocks. Method B is to randomly select a sample of families from each of the five natural neighborhoods making up the city.
(a) What is the statistical name for the sampling technique used in Method A, and what is a possible reason for using it rather than an SRS?
(b) What is the statistical name for the sampling technique used in Method B, and what is a possible reason for using it rather than an SRS?
AN INVESTIGATIVE TASK
A basic problem in ecology is to estimate the number of animals in a wildlife population. Suppose a wildlife management team captures and tags 27 deer in a state forest. The deer are released and given time to mingle with the deer population. One month later a second capture is made of 20 deer, among which 3 are noted to be tagged from the original capture.
(a) Assuming that the number of tagged individuals within the second sample is proportional to the number of tagged individuals in the whole population, estimate the total number of deer in the forest.
(b) A formula for variance of this estimate is Var(N)=$\frac{(a+1)(c+1)(a-b)(c-b)}{(b+1)^2(b+2)}$ where N = estimate of total population size, a = number of animals originally captured and tagged, b = number of tagged animals who are recaptured, and c = number of animals in second sample. What is the standard deviation for the population size estimate above?
(c) Given the answers to (a) and (b), would it be unexpected for the true deer population to be 225? Explain and show your work.
(d) What would a more accurate population estimate be, if it took into account that 6 of the tagged deer were shot by hunters before they could rejoin with the herd?
MULTIPLE-CHOICE
1. (A) This survey provides a good example of voluntary response bias, which often overrepresents negative opinions. The people who chose to respond were most likely parents who were very unhappy, and so there is very little chance that the 10,000 respondents were representative of the population. Knowing more about her readers, or taking a sample of the sample would not have helped.
2. (D) If there is bias, taking a larger sample just magnifies the bias on a larger scale. If there is enough bias, the sample can be worthless. Even when the subjects are chosen randomly, there can be bias due, for example, to non-response or to the wording of the questions. Convenience samples, like shopping mall surveys, are based on choosing individuals who are easy to reach, and they typically miss a large segment of the population. Voluntary response samples, like radio call-in surveys, are based on individuals who offer to participate, and they typically overrepresent persons with strong opinions.
3. (E) The wording of the questions can lead to response bias. The neutral way of asking this question would simply have been: Are you in favor of a 7-day waiting period between the filing of an application to purchase a handgun and the resulting sale?
4. (E) In a simple random sample, every possible group of the given size has to be equally likely to be selected, and this is not true here. For example, with this procedure it will be impossible for all the Bulls to be together in the final sample. This procedure is an example of stratified sampling, but stratified sampling does not result in simple random samples.
5. (E) In a simple random sample, every possible group of the given size has to be equally likely to be selected, and this is not true here. For example, with this procedure it will be impossible for all the early arrivals to be together in the final sample. This procedure is an example of systematic sampling, but systematic sampling does not result in simple random samples.
6. (B) Different samples give different sample statistics, all of which are estimates of a population parameter. Sampling error relates to natural variation between samples, can never be eliminated, can be described using probability, and is generally smaller if the sample size is larger.
7. (B) The Wall Street Journal survey has strong selection bias; that is, people who read the Journal are not very representative of the general population. The talk show survey results in a voluntary response sample, which typically gives too much emphasis to persons with strong opinions. The police detective’s survey has strong response bias in that students may not give truthful responses to a police detective about their illegal drug use.
8. (E) While the auditor does use chance, each company will have the same chance of being audited only if the same number of companies have names starting with each letter of the alphabet. This will not result in a simple random sample because each possible set of 26 companies does not have the same chance of being picked as the sample. For example, a group of companies whose names all start with A will not be chosen. Calculator random number generators and random number tables have similar uses and results.
9. (D) This is not a simple random sample because all possible sets of the required size do not have the same chance of being picked. For example, a set of households all from just half the counties has no chance of being picked to be the sample. Stratified samples are often easier and less costly to obtain and also make comparative data available. In this case responses can be compared among various counties. There is no reason to assume that each county has heads of households with the same characteristics and opinions as the state as a whole, so cluster sampling is not appropriate. When conducting stratified sampling, proportional sampling is used when one wants to take into account the different sizes of the strata.
10. (C) It is most likely that the apartments at which the interviewer had difficulty finding someone home were apartments with fewer students living in them. Replacing these with other randomly picked apartments most likely replaces smaller-occupancy apartments with larger-occupancy ones.
11. (E) While the procedure does use some element of chance, all possible groups of size 50 do not have the same chance of being picked, and so the result is not a simple random sample. There is a very real chance of selection bias. For example, a number of relatives with the same name and similar long-distance calling patterns might be selected. The typical methodology of a systematic sample involves picking every nth member from the list, where n is roughly the population size divided by the desired sample size.
12. (A) The natural variation in samples is called sampling error. Embarrassing questions and resulting untruthful answers are an example of response bias. Inaccuracies and mistakes due to human error are one of the real concerns of researchers.
13. (C) Surveying people coming out of any church results in a very unrepresentative sample of the adult population, especially given the question under consideration. Using chance and obtaining a high response rate will not change the selection bias and make this into a well-designed survey.
Free-Response
1. (a) Both studies were observational because no treatments were applied.
(b) Typical cell phone use today, especially among younger people, is well over half an hour, so half an hour does not seem to be a reasonable split between moderate and heavy use.
(c) This absolutely affects conclusions in that both studies look for relationships with brain cancer. While voice conversation involves holding the phone against one’s head, text messaging does not.
(d) The Denmark study looks at how many years individuals used their cell phones, but not at the extent of daily use, while the WHO study does consider daily usage.
2. There are many possible examples, such as Are you in favor of protecting the habitat of the spotted owl, which is almost extinct and desperately in need of help from an environmentally conscious government? and Are you in favor of protecting the habitat of the spotted owl no matter how much unemployment and resulting poverty this causes among hard-working loggers?
3. (a) To be a simple random sample, every possible group of size 25 has to be equally likely to be selected, and this is not true here. For example, if there are 40 students who always rush to be first in line, this procedure will allow for only 2 of them to be in the sample. Or if each homeroom of size 20 arrives as a unit, this procedure will allow for only 1 person from each homeroom to be in the sample.
(b) A simple random sample of the students can be obtained by numbering them from 001 to 500 and then picking three digits at a time from a random number table, ignoring numbers over 500 and ignoring repeats, until a group of 25 numbers is obtained. The students corresponding to these 25 numbers will be a simple random sample.
4. The direct telephone and mailing options will both suffer from undercoverage bias. For example, especially affected by the legislation under discussion are the homeless, and they do not have telephones or mailing addresses. The pollster interviews will result in a convenience sample, which can be highly unrepresentative of the population. In this case, there might be a real question concerning which members of her constituency spend any time in the downtown area where her office is located. The radio appeal will lead to a voluntary response sample, which typically gives too much emphasis to persons with strong opinions.
5. In numbering the people 0 through 9, each digit stands for whose coat someone receives. Pick the digits, omitting repeats, until a group of ten different digits is obtained. Check for a match (1 appearing in the first position corresponding to person 1, or 2 appearing in the next position corresponding to person 2, and so on, up to 0 appearing in the last position corresponding to person 10).
6. (a) To obtain an SRS, you might use a random number table and note the first two different numbers between 1 and 5 that appear. Or you could use a calculator to generate numbers between 1 and 5, again noting the first two different numbers that result.
(b) Time and cost considerations would be the benefit of substitution. However, substitution rather than returning to the same home later could lead to selection bias because certain types of people are not and will not be home at 9 a.m. With substitution the sample would no longer be a simple random sample.
(c) Corner lot homes like homes 1 and 5 might have different residents (perhaps with higher income levels) than other homes.
7. (a) Method A is an example of cluster sampling, where the population is divided into heterogeneous groups called clusters and individuals from a random sample of the clusters are surveyed. It is often more practical to simply survey individuals from a random sample of clusters (in this case, a random sample of city blocks) than to try to randomly sample a whole population (in this case the entire city population).
(b) Method B is an example of stratified sampling, where the population is divided into homogeneous groups called strata and random individuals from each stratum are chosen. Stratified samples can often give useful information about each stratum (in this case, about each of the five neighborhoods) in addition to information about the whole population (the city population).
AN INVESTIGATIVE TASK
(a) 27/N = 3/20 gives N = 180.
(b) ![]()
(c) No, this would not have been unexpected because 45, the absolute difference between 180 and 225, is less than the standard deviation of 54.76.
(d) 21/N = 3/20gives N=140.
EXPERIMENTS VERSUS OBSERVATIONAL STUDIES
CONFOUNDING, CONTROL GROUPS, PLACEBO EFFECTS, BLINDING
TREATMENTS, EXPERIMENTAL UNITS, RANDOMIZATION
REPLICATION, BLOCKING, GENERALIZABILITY OF RESULTS
There are several primary principles dealing with the proper planning and conducting of experiments. First, possible confounding variables must be controlled for, usually through the use of comparison. Second, chance should be used in assigning which subjects are to be placed in which groups for which treatment. Third, natural variation in outcomes can be lessened by using more subjects.
EXPERIMENTS VERSUS OBSERVATIONAL STUDIES VERSUS SURVEYS
In an experiment we impose some change or treatment and measure the result or response. In an observational study we simply observe and measure something that has taken place or is taking place, while trying not to cause any changes by our presence. A sample survey is an observational study in which we draw conclusions about an entire population by considering an appropriately chosen sample to look at. An experiment often suggests a causal relationship, while an observational study may show only the existence of associations.
EXAMPLE 8.1
A study is to be designed to determine whether daily calcium supplements benefit women by increasing bone mass. How can an observational study be performed? An experiment? Which is more appropriate here?
Answer: An observational study might interview and run tests on women seen purchasing calcium supplements in a pharmacy. Or perhaps all patients hospitalized during a particular time period could be interviewed with regard to taking calcium and then their bone mass measured. The bone mass measurements of those taking calcium supplements could then be compared to that of those not taking supplements.
An experiment could be performed by selecting some number of subjects, using chance to pick half to receive calcium supplements while the other half receives similar-looking placebos, and noting the difference in bone mass before and after treatment for each group.
The experimental approach is more appropriate here. With the observational study there could be many explanations for any bone mass difference noted between patients who take calcium and those who don’t. For example, women who have voluntarily been taking calcium supplements might be precisely those who take better care of themselves in general and thus have higher bone mass for other reasons. The experiment tries to control for lurking variables by randomly giving half the subjects calcium.
EXAMPLE 8.2
A study is to be designed to examine the life expectancies of tall people versus those of short people. Which is more appropriate, an observational study or an experiment?
Answer: An observational study, examining medical records of heights and ages at time of death, seems straightforward. An experiment where subjects are randomly chosen to be made short or tall, followed by recording age at death, would be groundbreaking (and, of course, nonsensical).
EXAMPLE 8.3
A study is to be designed to examine the GPAs of students who take marijuana regularly and those who don’t. Which is more appropriate, an observational study or an experiment?
Answer: As much as some researchers might want to randomly require half the subjects to take an illegal drug, this would be unethical. The proper procedure here is an observational study, having students anonymously fill out questionnaires asking about marijuana usage and GPA.
Experiments involve explanatory variables, called factors, that are believed to have an effect on response variables. A group is treated with some level of the explanatory variable, and the outcome on the response variable is measured.
EXAMPLE 8.4
To test the value of help sessions outside the classroom, students could be divided into three groups, with one group receiving 4 hours of help sessions per week outside the classroom, a second group receiving 2 hours of help sessions outside the classroom, and a third group receiving no help outside the classroom. What are the explanatory and response variables and what are the levels?
Answer: The explanatory variable, help sessions outside the classroom, is being given at three levels: 4 hours weekly, 2 hours weekly, and 0 hours weekly. The response variable is not specified but might be a final exam score or performance on a particular test.
The different factor-level combinations are called treatments. In Example 8.4, there are three treatments (corresponding to the three levels of the one factor). Suppose the students were further randomly divided into a morning class and an afternoon class. There would then be two factors, one with three levels and one with two levels, and a total of six treatments (AM class with 4 hours help, AM class with 2 hours help, AM class with 0 hours help, PM class with 4 hours help, PM class with 2 hours help, and PM class with 0 hours help).
CONFOUNDING, CONTROL GROUPS, PLACEBO EFFECTS, AND BLINDING
When there is uncertainty with regard to which variable is causing an effect, we say the variables are confounded. For example, suppose two fertilizers require different amounts of watering. In an experiment it might be difficult to determine if the difference in fertilizers or the difference in watering is the real cause of observed differences in plant growth. Sometimes we can control for confounding. For example, we can have many test plots using one or the other of the fertilizers, with equal numbers of sunny and shady plots for each fertilizer, so that fertilizer and sun are not confounded.
Sometimes a variable drives two other variables, creating the mistaken impression that the two other variables are related by cause and effect. For example, elementary school students with larger shoe sizes appear to have higher reading levels. However, there is a variable, age, which drives both the other variables. That is, older students tend to wear larger shoes than younger students, and older students also tend to have higher reading levels. Wearing larger shoes will not improve reading skills! There is a common response; that is, changes in both shoe size and reading level are caused by changes in age.
In an experiment there is a group that receives the treatment, and there is a control group that doesn’t. The experiment compares the responses in the treatment group to the responses in the control group. Randomly putting subjects into treatment and control groups can help reduce the problems posed by confounding and lurking variables. Thus these problems are easier to control for when doing experiments than when doing observational studies.
It is a fact that many people respond to any kind of perceived treatment. This is called the placebo effect. For example, when given a sugar pill after surgery but told that it is a strong pain reliever, many patients feel immediate relief from their pain. In many studies, subjects appear to consciously or subconsciously want to help the researcher prove a point. Thus when responses are noticed in any experiment, there is concern whether real physical responses are being caused by the psychological placebo effect. Blinding occurs when the subjects or the response evaluators don’t know which subjects are receiving different treatments such as placebos.
TIP
Blinding and placebos in experiments are important but are not always feasible. You can still have “experiments” without these.
EXAMPLE 8.5
A study is intended to test the effects of vitamin E and beta carotene on heart attack rates. How should it be set up?
Answer: Using randomization, the subjects should be split into four groups: those who will be given just vitamin E, just beta carotene, both vitamin E and beta carotene, and neither vitamin E nor beta carotene. For example, as each subject joins the test, the next digit in a random number table can be read off, ignoring 0 and 5–9, and with 1, 2, 3, and 4 designating which group the subject is placed in. Or if the total number of subjects is known and available, for example, 800, then each can be assigned a number and three digits at a time be read off the random number table. With repeats and numbers over 800 thrown away, the first 200 numbers picked represent one group, the next 200 another, and so on. More meaningful results will be obtained if the study is double-blind, that is, if not only are the subjects unaware of what kind of tablets they are taking but so are the doctors evaluating whether or not they have heart problems. Many diagnoses are not clear-cut, and doctors can be influenced if they know exactly which potential preventive their patients are taking.
TREATMENTS, EXPERIMENTAL UNITS, AND RANDOMIZATION
An experiment is performed on objects called experimental units, and if the units are people, they are called subjects. The experimental units or subjects are often divided into two groups. One group receives a treatment and is called the treatment group. A comparison is made between the response noted in the treatment group and the response noted in the control group, the group that receives no treatment.
To help minimize the effect of lurking variables, and of confounding, it is important to use randomization, that is, to use chance in deciding which subjects go into which group. It is not sufficient to try to systematically match characteristics between the two groups. It seems reasonable, for example, to hand-sort subjects so that both the treatment group and the control group have the same number of women, the same number of Catholics, the same number of Hispanics, the same number of short people, and so on, but this method does not work well. There are always other variables that one might not think of considering until after the results of the experiment start coming in. The best method to use is randomization employing a computer, a hat with names in it, or a random number table.
Note that randomization usually refers to how given subjects are assigned to treatments, not to how a group of subjects are chosen from an entire population. The object of an experiment is to see if different treatments lead to different responses, and so we randomly assign subjects to treatments to balance unknown sources of variability. Random assignment to treatments is critical, especially if the subjects are not randomly selected, as is the case in medical/drug experiments. Generalizing the findings of the study is a separate question, one that depends on how the initial group of subjects was assembled.
COMPLETELY RANDOMIZED DESIGN FOR TWO TREATMENTS
Comparing two treatments using randomization is often the design of choice. To help minimize hidden bias, it is best if subjects do not know which treatment they are receiving. This is called single-blinding. Another precaution is the use of double-blinding, in which neither the subjects nor those evaluating their responses know who is receiving which treatment.
EXAMPLE 8.6
There is a pressure point on the wrist that some doctors believe can be used to help control the nausea experienced following certain medical procedures. The idea is to place a band containing a small marble firmly on a patient’s wrist so that the marble is located directly over the pressure point. Describe how an experiment might be run on 50 postoperative patients.
Answer: Assign each patient a number from 01 to 50. From a random number table read off two digits at a time, throwing away repeats, 00, and numbers over 50, until 25 numbers have been selected. Put wristbands with marbles over the pressure point on the patients with these assigned numbers. Put wristbands with marbles on the remaining patients also, but not over the pressure point. Have a researcher check by telephone with all 50 patients at designated time intervals to determine the degree of nausea being experienced. Neither the patients nor the researcher on the telephone should know which patients have the marbles over the correct pressure point.
EXAMPLE 8.7
A chemical fertilizer company wishes to test whether using their product results in superior vegetables. After dividing a large field into small plots, how might the experiment proceed?
Answer: If the company has one recommended fertilizer application level, half the plots can be randomly selected (assigning the plots numbers and using a random number table) to receive the prescribed dosage of fertilizer. This random selection of plots is to ensure that neither fertilized plants nor unfertilized plants are inadvertently given land with better rainfall, sunshine, soil type, and so on. To avoid possible bias on the part of employees who will weed and water the plants, they should not know which plots have received the fertilizer. It might be necessary to have containers, one for each plot, of a similar-looking, similar-smelling substance, half of which contain the fertilizer while the rest contain a chemically inactive material. Finally, if the vegetables are to be judged by quantity and size, the measurements will be less subject to bias. However, if they are to be judged qualitatively, for example, by taste, the judges should not know which vegetables were treated with the fertilizer and which were not.
If the researchers also wish to consider level, that is, the amount of fertilizer, randomization should be used for more groupings. For example, if there are 60 plots on which to test four levels of fertilizer, the first 12 different two-digit numbers in the range 01–60 appearing on a random number table might receive one level, the next 12 new two-digit numbers a second level, and so on, with the last 12 plots receiving the “placebo” treatment.
RANDOMIZED PAIRED COMPARISON DESIGN
Two treatments can be compared based on the responses of paired subjects, one of whom receives one treatment while the other receives the second treatment. Often the paired subjects are really single subjects who are given both treatments, one at a time.
EXAMPLE 8.8
The famous Pepsi-Coke tests had subjects compare the taste of samples of each drink. How could such a paired comparison test be set up?
Answer: It is crucial that such a test be blind, that is, that the subjects not know which cup contains which drink. Furthermore, to help avoid hidden bias, which drink the subjects taste first should be decided by chance. For example, as each subject arrives, the researcher could read off the next digit from a random number table, with the subject receiving Pepsi or Coke first depending on whether the digit is odd or even.
Note: Even though the subjects are being given a drink, and there is some randomization going on, some statisticians consider this to be a sample survey aimed at estimating a population proportion rather than a true experiment.
EXAMPLE 8.9
Does seeing pictures of accidents caused by drunk drivers influence one’s opinion on penalties for drunk drivers? How could a comparison test be designed?
Answer: The subjects could be asked questions about drunk driving penalties before and then again after seeing the pictures, and any change in answers noted. This would be a poor design because there is no control group, there is no use of randomization, and subjects might well change their answers because they realize that that is what is expected of them after seeing the pictures.
A better design is to use randomization to split the subjects into two groups, half of whom simply answer the questions while the other half first see the pictures and then answer the questions.
Another possibility is to use a group of twins as subjects. One of each set of twins is randomly picked (e.g., based on choosing an odd or even digit from a random number table) to answer the questions without seeing the pictures, while the other first sees the pictures and then answers the questions. The answers could be compared from each set of twins. This is a paired comparison test that might help minimize lurking variables due to family environment, heredity, and so on.
REPLICATION, BLOCKING, AND GENERALIZABILITY OF RESULTS
When differences are observed in a comparison test, the researcher must decide whether these differences are statistically significant or whether they can be explained by natural variation. One important consideration is the size of the sample—the larger the sample, the more significant the observation. This is the principle of replication; that is, the treatment should be repeated on a sufficient number of subjects so that real response differences are more apparent.
Just as stratification in sampling design first divides the population into representative groups called strata, blocking in experiment design first divides the subjects into representative groups called blocks. One can think of blocking as running a separate experiment on each block. This technique helps control certain lurking variables by bringing them directly into the picture and helps make conclusions more specific. The paired comparison design is a special case of blocking in which each pair (or each subject if the subjects serve as their own controls) can be considered a block.
TIP
Use proper terminology! The language of experiments is different from the language of observational studies—you shouldn’t mix up blocking and stratification.
EXAMPLE 8.10
There is a rising trend for star college athletes to turn professional without finishing their degrees. A study is performed to assess whether reading an article about professional salaries has an impact on such decisions. Randomization can be used to split the subjects into two groups, and those in one group given the article before answering questions. How can a block design be incorporated into the design of this experiment?
Answer: The subjects can be split into two blocks, underclass and upperclass, before using randomization to assign some to read the article before questioning. With this design, the impact of the salary article on freshmen and sophomores can be distinguished from the impact on juniors and seniors.
Similarly, blocking can be used to separately analyze men and women, those with high GPAs and those with low GPAs, those in different sports, those with different majors, and so on.
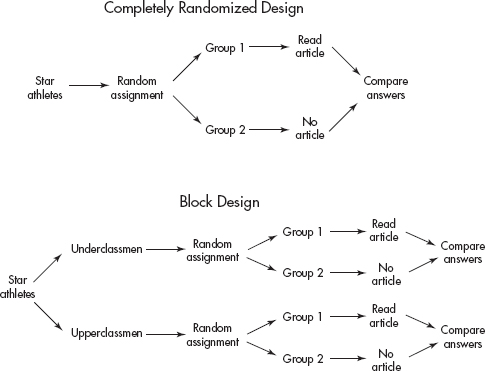
A major goal of experiments is to be able to generalize the results to broader populations. Often an experiment must be repeated in a variety of settings. For example, it is hard to generalize from the effect a television commercial has on students at a private midwestern high school to the effect the same commercial has on retired senior citizens in Florida. Generally, comparison and randomization are important, blinding is sometimes critical, and taking care to avoid hidden bias as much as possible is always indicative of a well-designed experiment. However, knowledge of the subject so that realistic situations can be created in testing should also be emphasized. Testing and experimenting on people does not put them in natural states, and this situation can lead to artificial responses.
SUMMARY
Experiments involve applying a treatment to one or more groups and observing the responses.
Experiments often have a treatment group and a control group.
Blocking is the process of dividing the subjects into representative groups to bring certain differences into the picture (for example, blocking by gender, age, or race).
Random assignment of subjects to treatment groups is extremely important in handling unknown and uncontrollable differences.
Random assignment refers to what is done with subjects after they’ve been picked for a study, whereas random sampling refers to how subjects are selected for a study.
Variables are said to be confounded when there is uncertainty as to which variable is causing an effect.
The placebo effect refers to the fact that many people respond to any kind of perceived treatment.
Blinding refers to subjects not knowing which treatment they are receiving.
Double-blinding refers to subjects and those evaluating their responses not knowing who received which treatments.
Completely randomized designs refer to experiments in which everyone has an equal chance of receiving any treatment.
Randomized block designs refer to experiments in which the randomization occurs only within blocks.
Randomized paired comparison designs refer to experiments in which subjects are paired and randomization is used to decide who in each pair receives what treatment.
Multiple-Choice Questions
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. A study is made to determine whether taking AP Statistics in high school helps students achieve higher GPAs when they go to college. In comparing records of 200 college students, half of whom took AP Statistics in high school, it is noted that the average college GPA is higher for those 100 students who took AP Statistics than for those who did not. Based on this study, guidance counselors begin recommending AP Statistics for college bound students. Which of the following is incorrect?
(A) While this study indicates a relation, it does not prove causation.
(B) There could well be a confounding variable responsible for the seeming relationship.
(C) Self-selection here makes drawing the counselors’ conclusion difficult.
(D) A more meaningful study would be to compare an SRS from each of the two groups of 100 students.
(E) This is an observational study, not an experiment.
2. In a 1927–32 Western Electric Company study on the effect of lighting on worker productivity, productivity increased with each increase in lighting but then also increased with every decrease in lighting. If it is assumed that the workers knew a study was in progress, this is an example of
(A) the effect of a treatment unit.
(B) the placebo effect.
(C) the control group effect.
(D) sampling error.
(E) voluntary response bias.
3. When the estrogen-blocking drug tamoxifen was first introduced to treat breast cancer, there was concern that it would cause osteoporosis as a side effect. To test this concern, cancer subjects were randomly selected and given tamoxifen, and their bone density was measured before and after treatment. Which of the following is a true statement?
(A) This study was an observational study.
(B) This study was a sample survey of randomly selected cancer patients.
(C) This study was an experiment in which the subjects were used as their own controls.
(D) With the given procedure, there cannot be a placebo effect.
(E) Causation cannot be concluded without knowing the survival rates.
4. In designing an experiment, blocking is used
(A) to reduce bias.
(B) to reduce variation.
(C) as a substitute for a control group.
(D) as a first step in randomization.
(E) to control the level of the experiment.
5. Which of the following is incorrect?
(A) Blocking is to experiment design as stratification is to sampling design.
(B) By controlling certain variables, blocking can make conclusions more specific.
(C) The paired comparison design is a special case of blocking.
(D) Blocking results in increased accuracy because the blocks have smaller size than the original group.
(E) In a randomized block design, the randomization occurs within the blocks.
6. Consider the following studies being run by three different nursing home establishments.
I. One nursing home has pets brought in for an hour every day to see if patient morale is improved.
II. One nursing home allows hourly visits every day by kindergarten children to see if patient morale is improved.
III. One nursing home administers antidepressants to all patients to see if patient morale is improved.
Which of the following is true?
(A) None of these studies uses randomization.
(B) None of these studies uses control groups.
(C) None of these studies uses blinding.
(D) Important information can be obtained from all these studies, but none will be able to establish causal relationships.
(E) All of the above
7. A consumer product agency tests miles per gallon for a sample of automobiles using each of four different octanes of gasoline. Which of the following is true?
(A) There are four explanatory variables and one response variable.
(B) There is one explanatory variable with four levels of response.
(C) Miles per gallon is the only explanatory variable, but there are four response variables corresponding to the different octanes.
(D) There are four levels of a single explanatory variable.
(E) Each explanatory level has an associated level of response.
8. Is hot oatmeal with fruit or a Western omelet with home fries a more satisfying breakfast? Fifty volunteers are randomly split into two groups. One group is fed oatmeal with fruit, while the other is fed Western omelets with home fries. Each volunteer then rates his/her breakfast on a one to ten scale for satisfaction. If the Western omelet with home fries receives a substantially higher average score, what is a reasonable conclusion?
(A) In general, people find Western omelets with home fries more satisfying for breakfast than hot oatmeal with fruit.
(B) There is no reasonable conclusion because the subjects were volunteering rather than being randomly selected from the general population.
(C) There is no reasonable conclusion because of the small size of the sample.
(D) There is no reasonable conclusion because blinding was not used.
(E) There is no reasonable conclusion because there are too many possible confounding variables such as age, race, and ethnic background of the individual volunteers and season when the study was performed.
9. Which of the following is a true statement?
(A) In well-designed observational studies, responses are systematically influenced during the collection of data.
(B) In well-designed experiments, the treatments result in responses that are as similar as possible.
(C) A well-designed experiment always has a single treatment but may test that treatment at different levels.
(D) Causation and association are unrelated concepts.
(E) In well-designed, well-conducted experiments, strong association implies cause and effect.
10. Which of the following is not important in the design of experiments?
(A) Control of confounding variables
(B) Randomization in assigning subjects to different treatments
(C) Replication of the experiment using sufficient numbers of subjects
(D) Care in observing without imposing change
(E) Isolating variability due to differences between blocks
11. Which of the following is a true statement about the design of matched-pair experiments?
(A) Each subject might receive both treatments.
(B) Each pair of subjects receives the identical treatment, and differences in their responses are noted.
(C) Blocking is one form of matched-pair design.
(D) Stratification into two equal sized strata is an example of matched pairs.
(E) Randomization is unnecessary in true matched pair designs.
12. Do teenagers prefer sports drinks colored blue or green? Two different colorings, which have no effect on taste, are used on the identical drink to result in a blue and a green beverage; volunteer teenagers are randomly assigned to drink one or the other colored beverage; and the volunteers then rate the beverage on a one to ten scale. Because of concern that sports interest may affect the outcome, the volunteers are first blocked by whether or not they play on a high school team. Is blinding possible in this experiment?
(A) No, because the volunteers know whether they are drinking a blue or green drink.
(B) No, because the volunteers know whether or not they play on a high school team.
(C) Yes, by having the experimenter in a separate room randomly pick one of two containers and remotely have a drink poured from that container.
(D) Yes, by having the statistician analyzing the results not know which volunteer sampled which drink.
(E) Yes, by having the volunteers drink out of solid colored thermoses, so that they don’t know the color of the drink they are tasting.
13. Some researchers believe that too much iron in the blood can raise the level of cholesterol. The iron level in the blood can be lowered by making periodic blood donations. A study is performed by randomly selecting half of a group of volunteers to give periodic blood donations while the rest do not. Is this an experiment or an observational study?
(A) An experiment with a single factor
(B) An experiment with control group and blinding
(C) An experiment with blocking
(D) An observational study with comparison and randomization
(E) An observational study with little if any bias
Free-Response Questions
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your final answers.
ELEVEN OPEN-ENDED QUESTIONS
1. The belief that sugar causes hyperactivity is the most popular example of how people believe that food influences behavior.
(a) Many parents, witnessing the aftermath of cake and ice cream at birthday parties, attest to the relationship between sugar and hyperactivity. Are these observational studies or experiments? Explain.
(b) Name a confounding variable to the above and explain how it is confounded with sugar.
(c) Design a study to allow a parent to determine whether sugar causes hyperactivity in his/her child and explain why double blinding is so important here.
2. Suppose a new drug is developed that appears in laboratory settings to completely prevent people who test positive for human immunodeficiency virus (HIV) from ever developing full-blown acquired immunodeficiency syndrome (AIDS). Putting all ethical considerations aside, design an experiment to test the drug. What ethical considerations might arise during the testing that would force an early end to the experiment?
3. A new weight-loss supplement is to be tested at three different levels (once, twice, and three times a day). Design an experiment, including a control group and including blocking for gender, for 80 overweight volunteers, half of whom are men. Explain carefully how you will use randomization.
4. Two studies are run to measure the health benefits of long-time use of daily high doses of vitamin C. Researchers in the first study send a questionnaire to all 50,000 subscribers to a health magazine, asking whether they have taken large doses of vitamin C for at least a 2-year period and what they perceive to be the health benefits, if any. The response rate is 80%. The 10,000 people who did not respond to the first mailing receive follow-up telephone calls, and eventually responses are registered from 98% of the magazine subscribers. Researchers in a second study take a group of 200 volunteers and randomly select 100 to receive high doses of vitamin C while the others receive a similar-looking, similar-tasting placebo. The volunteers are not told whether they are receiving the vitamin, but their doctors know and are asked to note health changes during a 2-year period. Comment on the designs of the two studies, remarking on their good points and on possible sources of error.
5. Explain how you would design an experiment to evaluate whether subliminal advertising (flashing “BUY POPCORN” on the screen for a fraction of a second) results in more popcorn being sold in a movie theater. Show how you will incorporate comparison, randomization, and blinding.
6. Throughout history millions of people have used garlic to obtain a variety of perceived health benefits. A vitamin production company decides to run a scientific test to assess the value of garlic in promoting a general sense of well-being. They randomly pick 250 of their employees, and once a day for 2 months the employees fill out questionnaires about their sense of well-being that day. For the next 2 months the employees take garlic capsules daily and again fill out the same questionnaires. Finally, for 2 concluding months the employees stop taking the pills and continue to fill out the daily questionnaires. Comment on the design of this experiment.
7. A new pain control procedure has been developed in which the patient uses a small battery pack to vary the intensity and duration of electric signals to electrodes surgically embedded in the afflicted area. Putting all ethical considerations aside, design an experiment to test the procedure. What ethical considerations might arise during the testing that would force an early end to the experiment?
8. A new vegetable fertilizer is to be tested at two different levels (regular concentration and double concentration). Design an experiment, including a control, for 30 test plots, half of which are in shade. Explain carefully how you will use randomization.
9. Two studies are run to measure the extent to which taking zinc lozenges helps to shorten the duration of the common cold. Researchers in the first study send questionnaires to all 5000 employees of a major teaching hospital asking whether they have taken zinc lozenges to fight the common cold and what they perceive to be the benefits, if any. The response rate is 90%. The 500 people who did not respond to the first mailing receive follow-up telephone calls, and eventually responses are obtained from over 99% of the hospital employees. Researchers in the second study take a group of 100 volunteers and randomly select 50 to receive zinc lozenges while the others receive a similar-looking, similar-tasting placebo. The volunteers are not told whether they are taking the zinc lozenges, but their doctors know and are asked to accurately measure the duration of common cold symptoms experienced by the volunteers. Comment on the designs of the two studies, remarking on their good points and on possible sources of error.
10. Explain how you would design an experiment to evaluate whether praying for a hospitalized heart attack patient leads to a speedier recovery. Show how you would incorporate comparison, randomization, and blinding.
11. The computer science department plans to offer three introductory-level CS courses: one using Pascal, one using C++, and one using Java.
(a) The department chairperson plans to give all students the same general programming exam at the end of the year and to compare the relative effectiveness of using each of the programming languages by comparing the mean grades of the students from each course. What is wrong, if anything, with the chairperson’s plan?
(b) The chairperson also wishes to determine whether math majors or science majors do better in the courses. Suppose he calculates that the average grade of science majors was higher than the average grade of math majors in each of the courses. Does it follow that the average grade of all the science majors taking the three courses must be higher than the average grade of all the math majors? Explain.
(c) Suppose 300 students wish to take introductory programming. How would you randomly assign 100 students to each of the three courses?
(d) How would you randomly assign students to the three courses if you wanted the assignment to be independent from student to student with each student in turn having a one-third probability of taking each of the three classes.
(e) Name a lurking variable that all the above methods miss.
AN INVESTIGATIVE TASK
A high school offers two precalculus courses, one that uses a traditional lecture and drill method, and a second that divides students into small groups to work on open-ended problems. To compare the effectiveness of the two methods, the administration proposes to compare average SAT math scores for the students in the two courses.
(a) What is wrong with the administration’s proposal?
(b) Suppose a group of 50 students are willing to take either course. Explain how you would use a random number table to set up an experiment comparing the effectiveness of the two courses.
(c) Apply your setup procedure to the given random number table:
84177 06757 17613 15582 51506 81435 41050 92031 06449
05059 59884 31180 53115 84469 94868 57967 05811 84514
75011 13006 63395 55041 15866 06589 13119 71020 85940
91932 06488 74987 54355 52704 90359 02649 47496 71567
94268 08844 26294 64759 08989 57024 97284 00637 89283
03514 59195 07635 03309 72605 29357 23737 67881 03668
33876 35841 52869 23114 15864 38942
(d) Discuss any variables that your setup doesn’t consider.
MULTIPLE-CHOICE
1. (D) It may well be that very bright students are the same ones who both take AP Statistics and have high college GPAs. If students could be randomly assigned to take or not take AP Statistics, the results would be more meaningful. Of course, ethical considerations might make it impossible to isolate the confounding variable in this way. Only using a sample from the observations gives less information.
2. (B) The desire of the workers for the study to be successful led to a placebo effect.
3. (C) In experiments on people, the subjects can be used as their own controls, with responses noted before and after the treatment. However, with such designs there is always the danger of a placebo effect. Thus the design of choice would involve a separate control group to be used for comparison.
4. (B) Blocking divides the subjects into groups, such as men and women, or political affiliations, and thus reduces variation.
5. (D) Blocking in experiment design first divides the subjects into representative groups called blocks, just as stratification in sampling design first divides the population into representative groups called strata. This procedure can control certain variables by bringing them directly into the picture, and thus conclusions are more specific. The paired comparison design is a special case of blocking in which each pair can be considered a block. Unnecessary blocking detracts from accuracy because of smaller sample sizes.
6. (E) None of the studies has any controls, such as randomization, control groups, or blinding, and so while they may give valuable information, they cannot establish cause and effect.
7. (D) Octane is the only explanatory variable, and it is being tested at four levels. Miles per gallon is the single response variable.
8. (A) There is nothing wrong with using volunteers—what is important is to randomly assign the volunteers into the two treatment groups. There is no way to use blinding in this study—the subjects will clearly know which breakfast they are eating. The main idea behind randomly assigning subjects to the different treatments is to control for various possible confounding variables—it is reasonable to assume that people of various ages, races, ethnic backgrounds, etc., are assigned to receive each of the treatments.
9. (E) In good observational studies, the responses are not influenced during the collecting of data. In good experiments, treatments are compared as to differences in responses. In an experiment, there can be many treatments, each at a different level. Well-designed experiments can show cause and effect.
10. (D) Control, randomization, and replication are all important aspects of well-designed experiments. Care in observing without imposing change refers to observational studies, not experiments.
11. (A) Each subject might receive both treatments, as, for example, in the Pepsi-Coke taste comparison study. The point is to give each subject in a matched pair a different treatment and note any difference in responses. Matched-pair experiments are a particular example of blocking, not vice versa. Stratification refers to a sampling method, not to experimental design. Randomization is used to decide which of a pair gets which treatment or which treatment is given first if one subject is to receive both.
12. (A) Blinding does have to do with whether or not the subjects know which treatment (color in this experiment) they are receiving. However, drinking out of solid colored thermoses makes no sense since the beverages are identical except for color and the point of the experiment is the teenager’s reaction to color. Blinding has nothing to do with blocking (team participation in this experiment).
13. (A) This study is an experiment because a treatment (periodic removal of a pint of blood) is imposed. There is no blinding because the subjects clearly know whether or not they are giving blood. There is no blocking because the subjects are not divided into blocks before random assignment to treatments. For example, blocking would have been used if the subjects had been separated by gender or age before random assignment to give or not give blood donations. There is a single factor—giving or not giving blood.
FREE-RESPONSE
1. (a) These are observational studies as there is no randomization of treatments to subjects.
(b) The excitement of a birthday party is a confounding variable. Without conducting a proper experiment, there is no way of telling whether observed hyperactivity is caused by sugar or by the excitement of a party or by some other variable.
(c) The parent should randomly give the child sugar or sugar-free sweets at parties and observe the child’s behavior. It is important that the parent not know which the child is receiving (double blinding), because the parent might perceive a difference in behavior which is not really there if he/she knows whether or not the child is being given a sugary food.
2. Ask doctors, hospitals, or blood testing laboratories to make known that you are looking for HIV-positive volunteers. As the volunteers arrive, use a random number table to give each one the drug or a placebo (e.g., if the next digit in the table is odd, the volunteer gets the drug, while if the next digit is even, the volunteer gets a placebo). Use double-blinding; that is, both the volunteers and their doctors should not know if they are receiving the drug or the placebo. Ethical considerations will arise, for example, if the drug is very successful. If volunteers on the placebo are steadily developing full-blown AIDS while no one on the drug is, then ethically the test should be stopped and everyone put on the drug. Or if most of the volunteers on the drug are dying from an unexpected fatal side effect, the test should be stopped and everyone taken off the drug.
TIP
Simply saying to “randomly assign” subjects to treatment groups is usually an incomplete response. You need to explain how to make the assignments—for example, by using a random number table or through generating random numbers on a calculator.
3. To achieve blocking by gender, first separate the men and women. Label the 40 men 01 through 40. Use a random number table to pick two digits at a time, ignoring 00 and numbers greater than 40, and ignoring repeats, until a group of ten such numbers is obtained. These men will receive the supplement at the once-a-day level. Follow along in the table, continuing to ignore repeats, until another group of ten is selected. These men will receive the supplement at the twice-a-day level. Again ignore repeats until a third group of ten is selected to receive the supplement at the three-times-a-day level, while the remaining men will be a control group and not receive the supplement. Now repeat the entire procedure, starting by labeling the women 01 through 40. A decision should be made whether or not to use a placebo and have all participants take “something” three times a day. Weigh all 80 overweight volunteers before and after a predetermined length of time. Calculate the change in weight for each individual. Calculate the average change in weight among the ten people in each of the eight groups. Compare the four averages from each block (men and women) to determine the effect, if any, of different levels of the supplement for men and for women.
4. The first study, an observational study, does not suffer from nonresponse bias, as do most mailed questionnaires, because it involved follow-up telephone calls and achieved a high response rate. However, this study suffers terribly from selection bias because people who subscribe to a health magazine are not representative of the general population. One would expect most of them to strongly believe that vitamins improve their health. The second study, a controlled experiment, used comparison between a treatment group and a control group, used randomization in selecting who went into each group, and used blinding to control for a placebo effect on the part of the volunteers. However, it did not use double-blinding; that is, the doctors knew whether their patients were receiving the vitamin, and this could have introduced hidden bias when they made judgments regarding their patients’ health.
5. Every day for some specified period of time, look at the next digit on a random number table. If it is odd, flash the subliminal message all day on the screen, while if it is even, don’t flash the message that day (randomization). Don’t let the customers know what is happening (blinding) and don’t let the clerks selling the popcorn know what is happening (double-blinding). Compare the quantity of popcorn bought by the treatment group, that is, by the people who receive the subliminal message, to the quantity bought by the control group, the people who don’t receive the message (comparison).
6. Any conclusions would probably be meaningless. There is a substantial danger of the placebo effect here; that is, real physical responses could be caused by the psychological effect of knowing the intent of the research. The experiment would be considerably strengthened by using a control group taking a look-alike capsule. Any conclusions are further suspect because of the choice of subjects. Rather than making a random selection from the intended population, the company is using a sample from its own employees, a sample almost guaranteed to have concerns, interests, and backgrounds that will confound the responses or limit their generalizability.
7. Ask doctors and hospitals to make known that you are looking for volunteers from among intractable pain sufferers. As the volunteers arrive, use a random number table to decide which will have the electrodes properly embedded in their pain centers and which will have the electrodes harmlessly embedded in wrong positions. For example, if the next digit in the table is odd, the volunteer receives the proper embedding, while if the next digit is even, the volunteer does not. Use double-blinding; that is, both the volunteers and their doctors should not know if the volunteers are receiving the proper embedding. Ethical considerations will arise, for example, if the procedure is very successful. If volunteers with the wrong embeddings are in constant pain, while everyone with proper embedding is pain-free, then ethically the test should be stopped and everyone given the proper embedding. Or if most of the volunteers with proper embedding develop an unexpected side effect of the pain spreading to several nearby sites, then the test should be stopped and the procedure discontinued for everyone.
8. To achieve blocking by sunlight, first separate the sunlit and shaded plots. Label the 15 sunlit plots 01 through 15. Using a random number table, pick two digits at a time, ignoring 00 and numbers above 15 and ignoring repeats, until a group of five such numbers is obtained. These sunlit plots will receive the fertilizer at regular concentration. Continue in the table, ignoring repeats, until another group of five is selected. These sunlit plots will receive the fertilizer at double concentration, while the remaining sunlit plots will be a control group receiving no fertilizer. Now repeat the procedure, this time labeling the shaded plots 01 through 15. Assuming size is the pertinent outcome, weigh all vegetables at the end of the season, compare the average weights among the three sunlit groups, and compare the average weights among the three shaded groups to determine the effect of the fertilizer, if any, at different levels on sunlit plots and separately on shaded plots.
9. The first study, an observational study, does not suffer from nonresponse bias, as do most studies involving mailed questionnaires, because the researchers made follow-up telephone calls and achieved a very high response rate. However, the first study suffers terribly from selection bias. People who work at a teaching hospital are not representative of the general population. One would expect many of them to have heard about how zinc coats the throat to hinder the propagation of viruses. The second study, a controlled experiment, used comparison between a treatment group and a control group, used randomization in selecting who went into each group, and used blinding to control for a placebo effect on the part of the volunteers. However, they did not use double-blinding; that is, the doctors knew whether their patients were receiving the zinc lozenges, and this could introduce hidden bias as the doctors make judgments about their patients’ health.
10. For each new heart attack patient entering the hospital, look at the next digit from a random number table. If it is odd, give the name to a group of people who will pray for the patient throughout his or her hospitalization, while if it is even, don’t ask the group to pray (randomization). Don’t let the patients know what is happening (blinding) and don’t let the doctors know what is happening (double-blinding). Compare the lengths of hospitalization of patients who receive prayers with those of control group patients who don’t receive prayers (comparison).
11. (a) Allowing the students to self-select which class to take leads to confounding that could be significant. For example, perhaps the brighter students all want to learn a certain one of the three languages.
(b) It is possible for the average score of all science majors to be lower than the average for all math majors even though the science majors averaged higher in each class. For example, suppose that the students taking Java scored much higher than the students in the other two classes. Furthermore, only one science major took Java, and she scored tops in the class. Then the overall average of the math majors could well be higher. This is an example of Simpson’s paradox, in which a comparison can be reversed when more than one group is combined to form a single group.
(c) Number the students 001 through 300. Read off three digits at a time from a random number table, noting all triplets between 001 and 300 and ignoring repeats, until 100 such numbers have been selected. Keep reading off three digits, ignoring repeats, until 100 new numbers between 001 and 300 are selected. These get C++, while the remaining 100 get Java. Even quicker would be to use a calculator to generate random digits between 001 and 300.
(d) Go through the list of students, flipping a die for each. If a 1 or a 2 shows, the student takes Pascal, if a 3 or a 4 shows, C++, and if a 5 or a 6 shows, Java.
(e) Another possible variable are the teachers. For example, perhaps the better teachers teach Java.
AN INVESTIGATIVE TASK
(a) There is no reason to believe that there was anything random about which students took which course. Perhaps all the weaker students self-selected or were advised to choose the traditional course.
(b) The students could be labeled 01 through 50. Pairs of digits could then be read off a random number table, ignoring numbers over 50 and ignoring duplicates, until a set of 25 numbers is obtained. The students corresponding to these numbers could be enrolled in the traditional course, and the remaining students in the other.
(c) Applying the above procedure results in {17, 31, 14, 35, 41, 05, 09, 20, 06, 44, 50, 43, 11, 18, 45, 01, 13, 33, 04, 19, 02, 08, 40, 49, 03}. Enroll the students with these numbers in the traditional course.
(d) Which teachers teach which courses is not considered. Perhaps the more interesting, exciting teachers teach the new version. Even though a control group is selected, there is no blinding, and so students in the new version might work harder because they realize they are part of an experiment.
LAW OF LARGE NUMBERS
BASIC PROBABILITY RULES
MULTISTAGE PROBABILITY CALCULATIONS
BINOMIAL DISTRIBUTION
GEOMETRIC PROBABILITIES
SIMULATION
DISCRETE RANDOM VARIABLES, MEANS (EXPECTED VALUES), AND STANDARD DEVIATIONS
In the world around us, unlikely events sometimes take place. At other times, events that seem inevitable do not occur. Chance is everywhere! The cards you are dealt in a poker game, the particular genes you inherit from your parents, and the coin toss at the beginning of a tennis match to determine who serves first are examples of chance behavior that mathematics can help us understand. Even though we may not be able to foretell a specific result, we can sometimes assign what is called a probability to indicate the likelihood that a particular event will occur.
Probabilities are always between 0 and 1, with a probability close to 0 meaning that an event is unlikely to occur, and a probability close to 1 meaning that the event is likely to occur. The sum of the probabilities of all the separate outcomes of an experiment is always 1.
TIP
Calculators will express very small probabilities in scientific notation such as 3.4211073E–6. Know what this means, and remember that probabilities are never greater than 1.
The relative frequency of an event is the proportion of times the event happened, that is, the number of times the event happened divided by the total number of trials. Relative frequencies may change every time an experiment is performed. The law of large numbers states that when an experiment is performed a large number of times, the relative frequency of an event tends to become closer to the probability of the event, that is, probability is long-term relative frequency.
The law of large numbers says nothing at all about short-run behavior. There is no such thing as a law of small numbers or a law of averages. Gamblers might say that “red” is due on a roulette table, a basketball player is due to make a shot, a player has a hot hand at the craps table, or a certain number is due to come up in a lottery, but if events are independent, the probability of the outcome of the next trial has nothing to do with what happened in previous trials. Even though casinos and life insurance companies might lose money in the short run, they make long-term profits because of their understanding of the law of large numbers.
EXAMPLE 9.1
There are two games involving flipping a fair coin. In the first game, you win a prize if you can throw between 45% and 55% heads. In the second game, you win if you can throw more than 60% heads. For each game would you rather flip 20 times or 200 times?
Answer: The probability of throwing heads is 0.5. By the law of large numbers, the more times you throw the coin, the more the relative frequency tends to become closer to this probability. With fewer tosses, there is greater chance of wide swings in the relative frequency. Thus, in the first game you would rather have 200 flips, whereas in the second game you would rather have only 20 flips.
EXAMPLE 9.2
A standard literacy test consists of 100 multiple-choice questions, each with five possible answers. There is no penalty for guessing. A score of 60 is considered passing and a score of 80 is considered superior. When an answer is completely unknown, test takers employ one of three strategies: guess, choose answer (c), or choose the longest answer. The table below summarizes the results of 1000 test takers.
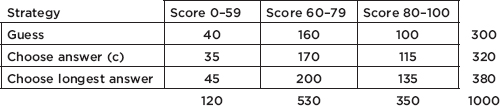
Note that in analyzing tables such as the one above, it is usually helpful to sum rows and columns.
(a) What is the probability that someone in this group uses the “guess” strategy?
Answer: P(guess)=300/1000=0.3
(b) What is the probability that someone in this group scores 60–79?
Answer: P(score 60-79)=530/1000=0.53
(c) What is the probability that someone in this group does not score 60–79?
Answer: P(does not score 60–79) = 1 − P(score 60–79) = 1 − 0.53 = 0.47
[The probability that an event will not occur, that is, the probability of its complement, is equal to 1 minus the probability that the event will occur.]
(d) What is the probability that someone in this group chooses strategy “answer (c)” and scores 80–100?
Answer: ![]()
TIP
The word “or” here means one event or the other event or both events.
(e) What is the probability that someone in this group chooses strategy “longest answer” or scores 0–59?
Answer: ![]()
Note that
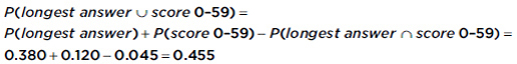
[For any pair of events A and B, $P(A\cup B)=P(A)+P(B)-P(A\cap B)$.]
(f) What is the probability that someone in this group chooses strategy “guess” given that his/her score was 0–59?
Answer: ![]()
Note that we narrowed our attention to the 120 test takers who scored 0–59 to calculate this conditional probability.
(g) What is the probability that someone in this group scored 80–100 given that he/she chose strategy “longest answer”?
Answer: ![]()
Note that we narrowed our attention to the 380 test takers who chose “longest answer” to calculate this conditional probability.
[A formula for conditional probability is given by $P(A|B)=\frac{P(A\cap B)}{P(B)}$]
TIP
If A and B are independent we also have P(A|not B) = P(A).
(h) Are the strategy “guess” and scoring 0–59 independent events? That is, is whether a test taker used the strategy “guess” unaffected by whether he/she scored 0–59?
Answer: We must check if P (guess|score 0–59) = P(guess). From (f) and (a), we see that these probabilities are not equal (0.333 ≠ 0.3), so the strategy “guess” and scoring 0–59 are not independent events.
[Events A and B are independent if P(A|B) = P(A), or equivalently, if P(B|A) = P(B). It is also true that A and B are independent if and only if P(A $\cap$ B) = P(A) P(B), that is, if and only if the probability of both events happening is the product of their probabilities. Yet another insight into independence is that A and B are independent if and only if P(A|B) = P(A|BC).]
TIP
Don’t multiply probabilities unless the events are independent.
(i) Are the strategy “longest answer” and scoring 80–100 mutually exclusive events? That is, are these two events disjoint and cannot simultaneously occur?
Answer: longest answer $\cap$ score 80–100 ≠ Ø and P(longest answer $\cap$ score 80–100) ≠ 0, so the strategy “longest answer” and scoring 80–100 are not mutually exclusive events.
TIP
Don’t confuse independence with mutally exclusive.
Note that if two events are mutually exclusive, then the probability that at least one event will occur is equal to the sum of the respective probabilities of the two events:
If P(A $\cap$ B) = 0, then P(A $\cup$ B) = P(A) + P(B)
TIP
Don’t add probabilities unless the events are mutually exclusive.
[Whether events are mutually exclusive or are independent are two very different properties! One refers to events being disjoint; the other refers to an event having no effect on whether or not the other occurs. Note that mutually exclusive (disjoint) events are not independent (except in the special case that one of the events has probability 0). That is, mutually exclusive gives that P(A $\cap$ B) = 0, whereas independence gives that P(A $\cap$ B) = P(A) P(B) (and the only way these are ever simultaneously true is in the very special case when P(A) = 0 or P(B) = 0).]
MULTISTAGE PROBABILITY CALCULATIONS
EXAMPLE 9.3
On a university campus, 60%, 30%, and 10% of the computers use Windows, Apple, and Linux operating systems, respectively. A new virus affects 3% of the Windows, 2% of the Apple, and 1% of the Linux operating systems. What is the probability a computer on this campus has the virus?
Answer: In such problems it is helpful to start with a tree diagram.
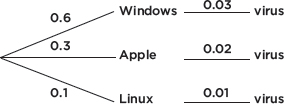
TIP
Tree diagrams can be very useful in working with conditional probabilities.
We then have
P(Windows $\cap$ virus) = (0.6)(0.03) = 0.018
P(Apple $\cap$ virus) = (0.3)(0.02) = 0.006
P(Linux $\cap$ virus) = (0.1)(0.01) = 0.001
At this stage a Venn diagram is helpful in finishing the problem:
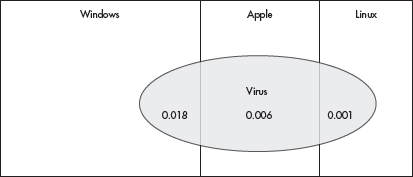
P(virus) = P(Windows $\cap$ virus) + P(Apple $\cap$ virus) + P(Linux $\cap$ virus)
= 0.018 + 0.006 + 0.001 = 0.025
TIP
Naked or bald answers will receive little or no credit. You must show where answers come from.
We can take the above analysis one stage further and answer such questions as: If a randomly chosen computer on this campus has the virus, what is the probability it is a Windows machine? An Apple machine? A Linux machine?

A probability distribution is a listing or formula giving the probability of each outcome.
In many applications, such as coin tossing, there are only two possible outcomes. For applications in which a two-outcome situation is repeated a certain number of times, and the probability of each of the two outcomes remains the same for each repetition, the resulting calculations involve what are known as binomial probabilities.
EXAMPLE 9.4
Suppose the probability that a lightbulb is defective is 0.1 (so probability of being good is 0.9).
(a) What is the probability that four lightbulbs are all defective?
Answer: Because of independence (i.e., whether one lightbulb is defective is not influenced by whether any other lightbulb is defective), we can multiply individual probabilities of being defective to find the probability that all the bulbs are defective:
(0.1)(0.1)(0.1)(0.1) = (0.1)4 = 0.0001.
(b) What is the probability that exactly two out of three lightbulbs are defective?
Answer: The probability that the first two bulbs are defective and the third is good is (0.1)(0.1)(0.9) = 0.009. The probability the first bulb is good and the other two are defective is (0.9)(0.1)(0.1) = 0.009. Finally, the probability that the second bulb is good and the other two are defective is (0.1)(0.9)(0.1) = 0.009. Summing, we find that the probability that exactly two out of three bulbs are defective is 0.009 + 0.009 + 0.009 = 0.027.
(c) What is the probability that exactly three out of eight lightbulbs are defective?
Answer: The probability of any particular arrangement of three defective and five good bulbs is (0.1)3(0.9)5 = 0.00059049. How many such arrangements are there?
The answer is given by combinations: $\bigl(\begin{smallmatrix}8 \\3\end{smallmatrix}\bigr)=\frac{8!}{3!5!}$. Thus, the probability that
exactly three out of eight lightbulbs are defective is 56 × 0.00059049 = 0.03306744. [On the TI-84, binompdf(8,.1,3) = 0.03306744.]
NOTE
On the exam, you should write binompdf (n = 8, p = 0.1, x = 3) = 0.033.
More generally, if an experiment has two possible outcomes, called success and failure, with the probability of success equal to p, and the probability of failure equal to q (of course, p + q = 1), and if the outcome at any particular time has no influence over the outcome at any other time, then if the experiment is repeated n times, the probability of exactly k successes (and thus n – k failures) is
![]()
EXAMPLE 9.5
Super Mario cards were in one-third of cereal boxes advertising enclosed Magic Motion cards. If six boxes of cereal are purchased, what is the probability of exactly two Super Mario cards?
Answer: If the probability of a Mario card is 1/3, then the probability of no Mario card is 1 – 1/3 = 2/3. If two out six boxes have a Mario card, then 6 – 2 = 4 do not. Thus, the desired probability is  [On the TI-84, binompdf(6,1/3,2)≈ 0.329.]
[On the TI-84, binompdf(6,1/3,2)≈ 0.329.]
TIP
On the exam it is sufficient to write: Binomial, n = 6, p = 1/3, P(X = 2) = 0.329.
In some situations it is easier to calculate the probability of the complementary event and subtract this value from 1.
EXAMPLE 9.6
Joe DiMaggio had a career batting average of 0.325. What was the probability that he would get at least one hit in five official times at bat?
Answer: We could sum the probabilities of exactly one hit, two hits, three hits, four hits, and five hits. However, the complement of “at least one hit” is “zero hits.” The probability of no hit is
![]()
and thus the probability of at least one hit in five times at bat is 1 – 0.140 = 0.860.
[Or binomcdf(5, .675, 4) ≈ 0.860.]
Many, perhaps most, applications of probability involve such phrases as at least, at most, less than, and more than. In these cases, solutions involve summing two or more cases. For such calculations, the TI-84 binomcdf is very useful. binomcdf(n,p,x) gives the probability of x or fewer successes in a binomial distribution with number of trials n and probability of success p.
EXAMPLE 9.7
A manufacturer has the following quality control check at the end of a production line: If at least eight of ten randomly picked articles meet all specifications, the whole shipment is approved. If, in reality, 85% of a particular shipment meet all specifications, what is the probability that the shipment will make it through the control check?
Answer: The probability of an item meeting specifications is 0.85, and so the probability of it not meeting specifications must be 0.15. We want to determine the probability that at least eight out of ten articles will meet specifications, that is, the probability that exactly eight or exactly nine or exactly ten articles will meet specifications. We sum the three binomial probabilities:
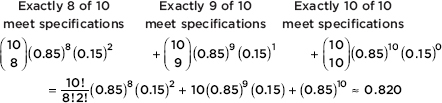
[On the TI-84 one can calculate 1 – binomcdf(10, .85, 7) ≈ 0.820 or binomcdf(10, .15, 2) ≈ 0.820.]
EXAMPLE 9.8
For the problem in Example 9.7, what is the probability that a shipment in which only 70% of the articles meet specifications will make it through the control check?
Answer:
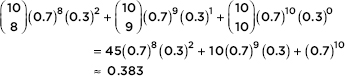
[Or binomcdf(10, .3, 2) ≈ 0.383.]
EXAMPLE 9.9
A grocery store manager notes that 35% of customers who buy a particular product make use of a store coupon to receive a discount. If seven people purchase the product, what is the probability that fewer than four will use a coupon?
Answer: In this situation, “fewer than four” means zero, one, two, or three.
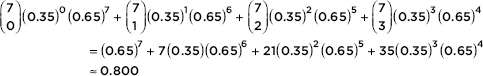
[Or binomcdf(7, .35, 3) ≈ 0.800.]
Sometimes we are asked to calculate the probability of each of the possible outcomes (the results should sum to 1).
EXAMPLE 9.10
If the probability that a male birth will occur is 0.51, what is the probability that a five-child family will have all boys? Exactly four boys? Exactly three boys? Exactly two boys? Exactly one boy? All girls?
Answer:
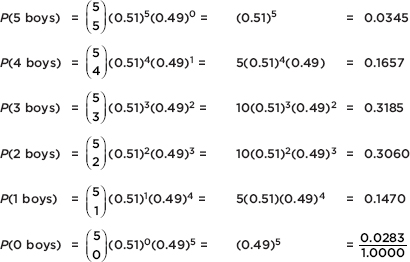
[Or binompdf(5, .49) = {0.0345 0.1657 0.3185 0.3060 0.1470 0.0283}.]
A list such as the one in Example 9.10 shows the entire probability distribution, which in this case refers to a listing of all outcomes and their probabilities.
Suppose an experiment has two possible outcomes, called success and failure, with the probability of success equal to p and the probability of failure equal to q = 1 – p, and the trials are independent. Then the probability that the first success is on trial number X = k is
qk–1p
EXAMPLE 9.11
Suppose only 12% of men in ancient Greece were honest. What is the probability that the first honest man Diogenes encounters will be the third man he meets?
Answer : (0.88)2(0.12) = 0.092928 [or geometpdf (.12, 3) = 0.092928]
What is the probability that the first honest man he encounters will be no later than the fourth man he meets?
Answer : (0.12) + (0.88)(0.12) + (0.88)2(0.12) + (0.88)3(0.12) = 0.40030464
[or geometcdf (.12, 4) = 0.40030464]
Instead of algebraic calculations, sometimes we can use simulation to answer probability questions.
EXAMPLE 9.12
If left alone, 70% of birthmarks gradually fade away. If ten children, 5 of each gender, are born with birthmarks, what is the probability that the same number of boys and girls will lose their birthmarks? Answer the question using simulation.
Answer: Let the digits 1–7 represent having a birthmark that fades away, and 8, 9, and 0 represent having a birthmark that doesn’t fade away. To simulate the 10 children, select 10 digits from the random number table, with the first 5 representing boys and the next 5 representing girls. Note the number of digits 1–7 in each group and see if there is a match. Underlining the digits 1–7 gives
TIP
Probabilities calculated through simulations should always be referred to as estimates or approximations.
For example, in the first set of 10 digits, there are 3 boys and 4 girls whose birthmarks fade, so no match. In the second set of 10 digits, there are 5 boys and 5 girls whose birthmarks fade, so a match. We have 3-4, 5-5, 5-3, 5-5, 4-3; 3-4, 4-5, 5-4, 2-3, 3-3; 4-3, 3-2, 4-4, 4-5, 4-3; 5-2, 3-3, 4-5, 4-4, 2-3; 4-5, 1-4. 4-3, 3-2, 3-4; 4-2, 3-5, 4-3, 4-2, 4-4; 4-4, 4-3, 5-4, 4-5, 5-5; 5-3, 4-3, 3-2, 2-3, 3-4; 5-4, 1-3, 5-5, 4-4, 3-2; 4-3, 2-4, 3-3, 4-4, 3-4
We count 13 matches out of a possible 50, and so estimate the probability that the same number of boys and girls will lose their birthmarks to be 13/50 = 0.26.
TIP
Be able to describe simulations so that others can repeat your procedure.
EXAMPLE 9.13
Babe Ruth had a career batting average of 0.342, quite impressive for a home run hitter! Use simulation to estimate the probability that his first hit in a game is on the first at-bat? On the second at-bat? Not until the third at-bat? Fourth at-bat?
Answer: Using the random number table from the previous example, read off 3 digits at a time, with 001–342 representing a hit and anything else, not a hit, and starting all over again every time there is a hit. So, for example, reading off the first line gives
869-619-414-146 is a first hit on the fourth at-bat,
633-325 is a first hit on the second at-bat,
526-445-234 is a first hit on the third at-bat,
882-462-662-337 is a first hit on the fourth at-bat,
169 is a first hit on the first at-bat, and
214 is also a first hit on the first at-bat.
Continuing in this fashion and tabulating the results, we have
Number of the at-bat | Frequency | Estimated probability |
1 | 22 | 22/64 = 0.344 |
2 | 14 | 14/64 = 0.219 |
3 | 13 | 13/64 = 0.203 |
4 | 6 | 6/64 = 0.094 |
Over 4 | 9 | 9/64 = 0.141 |
Total | 64 |
|
The actual probabilities are 0.342, (0.658)(0.342) = 0.225, (0.658)2(0.342) = 0.148, (0.658)3(0.342) = 0.097, and 1 – (0.342 + 0.225 + 0.148 + 0.094) = 0.188. [On the TI-84, one can calculate these geometric probabilities: geometpdf(0.342,1), …, geometpdf(0.342,4), and 1 – geometcdf(0.342,4).]
In performing a simulation, you must:
1. Set up a correspondence between outcomes and random numbers.
2. Give a procedure for choosing the random numbers (for example, pick three digits at a time from a designated row in a random number table).
3. Give a stopping rule.
4. Note what is to be counted (what is the purpose of the simulation), and give the count if requested.
DISCRETE RANDOM VARIABLES, MEANS (EXPECTED VALUES), AND STANDARD DEVIATIONS
Often each outcome of an experiment has not only an associated probability but also an associated real number. For example, the probability may be 0.5 that a student is taking 0 AP classes, 0.3 that he/she is taking 1 AP class, and 0.2 that he/she is taking 2 AP classes. If X represents the different numbers associated with the potential outcomes of some chance situation, we call X a random variable.
While the mean of the set {2, 7, 12, 15, 24} is (2 + 7 + 12 + 15)/4 = 9 or 2(¼) + 7(¼) + 12(¼) + 15(¼) = 9, the expected value or mean of a random variable takes into account that the various outcomes may not be equally likely. The expected value or mean of a random variable X is given by µX = E(X)=  xP(x) where P(x) is the probability of outcome x. [We also write µX xipi.]
xP(x) where P(x) is the probability of outcome x. [We also write µX xipi.]
EXAMPLE 9.14
In a lottery, 10,000 tickets are sold at $1 each with a prize of $7500 for one winner. What is the average result for each bettor?
Answer: The actual winning payoff is $7499 because the winner paid $1 for a ticket, so we have
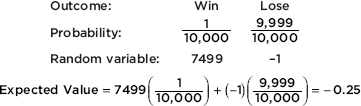
Thus the average result for each person betting on the lottery is a $0.25 loss. Alternatively, we can say that the expected payoff to the lottery system is $0.25 for each ticket sold.
Suppose we have a binomial random variable, that is, a random variable whose values are the numbers of “successes” in some binomial probability distribution.
EXAMPLE 9.15
Of the automobiles produced at a particular plant, 40% had a certain defect. Suppose a company purchases five of these cars. What is the expected value for the number of cars with defects?
Answer: We might guess that the average or mean or expected value is 40% of 5 = 0.4 × 5 = 2, but let’s calculate from the definition. Letting X represent the number of cars with the defect, we have

Thus the answer turns out to be the same as would be obtained by simply multiplying the probability of a “success” by the number of cases.
The following is true: If we have a binomial probability situation with the probability of a success equal to p and the number of trials equal to n, the expected value or mean number of successes for the n trials is np.
EXAMPLE 9.16
An insurance salesperson is able to sell policies to 15% of the people she contacts. Suppose she contacts 120 people during a 2-week period. What is the expected value for the number of policies she sells?
Answer: We have a binomial probability with the probability of a success 0.15 and the number of trials 120, and so the mean or expected value for the number of successes is 120 × 0.15 = 18.
We have seen that the mean of a random variable is $\sum$xipi. However, not only is the mean important, but also we would like to measure the variability for the values taken on by a random variable. Since we are dealing with chance events, the proper tool is variance (along with standard deviation). Variance was defined in Topic Two to be the mean average of the squared deviations (x – µ)2. If we regard the (x – µ)2 terms as the values of some random variable (whose probability is the same as the probability of x), the mean of this new random variable is $\sum$(xi – µx)2pi, which is precisely how we define the variance $\sigma^2$ of a random variable:
![]()
As before, the standard deviation $\sigma$ is the square root of the variance.
EXAMPLE 9.17
A highway engineer knows that his crew can lay 5 miles of highway on a clear day, 2 miles on a rainy day, and only 1 mile on a snowy day. Suppose the probabilities are as follows:
Outcome: | Clear | Rain | Snow |
Probability: | 0.6 | 0.3 | 0.1 |
Random variable (miles of highway): | 5 | 2 | 1 |
What are the mean (expected value) and the variance?
Answer:
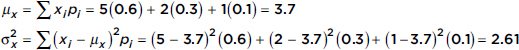
EXAMPLE 9.18
Look again at Example 9.15. We calculated the mean to be 2. What is the variance?
Answer: $\sigma$2 = (0 – 2)2(0.07776) + (1 – 2)2(0.2592) + (2 – 2)2(0.3456) + (3 – 2)2(0.2304) + (4 – 2)2(0.0768) + (5 – 2)2(0.01024) = 1.2
Could we have calculated the above result more easily? In this case, we have a binomial random variable and the variance can be simply calculated as npq = np(1 – p).
How can we use this method to calculate the variance in Example 9.15 more simply?
Answer: np(1 – p) = 5(0.4)(0.6) = 1.2
Thus, for a random variable X,
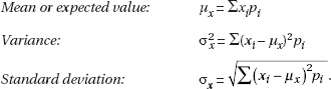
In the case of a binomial probability distribution with probability of a success equal to p and number of trials equal to n, if we let X be the number of successes in the n trials, the above equations become
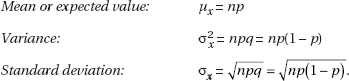
EXAMPLE 9.19
Sixty percent of all buyers of new cars choose automatic transmissions. For a group of five buyers of new cars, calculate the mean and standard deviation for the number of buyers choosing automatic transmissions.
Answer:
![]()
SUMMARY
The law of large numbers states that in the long run, a cumulative relative frequency tends closer and closer to what is called the probability of an event.
The probability of the complement of an event is equal to 1 minus the probability of the event.
Two events are mutually exclusive if they cannot occur simultaneously.
If two events are mutually exclusive, the probability that at least one will occur is the sum of their respective probabilities.
More generally, P(A $\cup$ B) = P(A) + P(B) – P(A $\cap$ B).
The conditional probability of A given B is given by: $P(A|B)=\frac{P(A\cap B)}{P(B)}$
Two events A and B are independent if P(A|B) = P(A); that is, the probability of one event occurring does not influence whether or not the other occurs.
If two events A and B are independent, then P(A $\cap$ B) = P(A) × P(B).
A random variable takes various numeric values, each with a given probability.
The mean or expected value of a random variable is calculated by µ = $\sum$ xP(x), while the variance is $\sigma$2 = $\sum$(x – µ)2 P(x).
The binomial distribution arises when there are two possible outcomes, the probability of success is constant, and the trials are independent.
In a binomial distribution, the mean number of successes is np and the standard deviation is $\sqrt{np(1-p)}$.
Multiple-Choice Questions
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. A student reasons that either he will or will not receive a 5 on the AP Statistics exam, and therefore the probability of receiving a 5 is 0.5. Why is this incorrect reasoning?
(A) The events are mutually exclusive.
(B) The events are independent.
(C) The events are not independent.
(D) The events are complements.
(E) The events are not equally probable.
2. In the November 27, 1994, issue of Parade magazine, the “Ask Marilyn” section contained this question: “Suppose a person was having two surgeries performed at the same time. If the chances of success for surgery A are 85%, and the chances of success for surgery B are 90%, what are the chances that both would fail?” What do you think of Marilyn’s solution: (0.15)(0.10) = 0.015 or 1.5%?
(A) Her solution is mathematically correct but not explained very well.
(B) Her solution is both mathematically correct and intuitively obvious.
(C) Her use of complementary events is incorrect.
(D) Her use of the general addition formula is incorrect.
(E) She assumed independence of events, which is most likely wrong.
3. A weighted die comes up spots with the following probabilities:
Spots | 1 | 2 | 3 | 4 | 5 | 6 |
Probability | 0.10 | 0.15 | 0.20 | 0.25 | 0.20 | 0.10 |
If two of these dice are thrown, what is the probability the sum is 10?
(A) (0.25)(0.10) + (0.20)2
(B) 2(0.25)(0.10) + (0.20)2
(C) 2(0.25)(0.10) + 2(0.20)2
(D) (0.10)(0.20)(0.10) + (0.20)2
(E) (0.10)(0.20)(0.10) + (0.15)(0.25)2 + (0.15)(0.20)(0.20) + (0.25)(0.10)
4. According to a CBS/New York Times poll taken in 1992, 15% of the public have responded to a telephone call-in poll. In a random group of five people, what is the probability that exactly two have responded to a call-in poll?
(A) 0.138
(B) 0.165
(C) 0.300
(D) 0.835
(E) 0.973
5. In a 1974 “Dear Abby” letter a woman lamented that she had just given birth to her eighth child, and all were girls! Her doctor had assured her that the chance of the eighth child being a girl was only 1 in 100. What was the real probability that the eighth child would be a girl?
(A) 0.01
(B) 0.5
(C) (0.5)7
(D) (0.5)8
(E) $\frac{0.5^7+0.5^8}{2}$
6. The yearly mortality rate for American men from prostate cancer has been constant for decades at about 25 of every 100,000 men. (This rate has not changed in spite of new diagnostic techniques and new treatments.) In a group of 100 American men, what is the probability that at least 1 will die from prostate cancer in a given year?
(A) 0.00025
(B) 0.0247
(C) 0.025
(D) 0.9753
(E) 0.99975
7. Alan Dershowitz, one of O. J. Simpson’s lawyers, has stated that only 1 out of every 1000 abusive relationships ends in murder each year. If he is correct, and if there are approximately 1.5 million abusive relationships in the United States, what is the expected value for the number of people who are killed each year by an abusive partner?
(A) 1
(B) 500
(C) 1000
(D) 1500
(E) None of the above
8. For an advertising promotion, an auto dealer hands out 1000 lottery tickets with a prize of a new car worth $25,000. For someone with a single ticket, what is the standard deviation for the amount won?
(A) \$7.07
(B) \$25.00
(C) \$49.95
(D) \$790.17
(E) \$624,375
9. Suppose that among the 6000 students at a high school, 1500 are taking honors courses and 1800 prefer watching basketball to watching football. If taking honors courses and preferring basketball are independent, how many students are both taking honors courses and prefer basketball to football?
(A) 300
(B) 330
(C) 450
(D) 825
(E) There is insufficient information to answer this question.
10. An inspection procedure at a manufacturing plant involves picking three items at random and then accepting the whole lot if at least two of the three items are in perfect condition. If in reality 90% of the whole lot are perfect, what is the probability that the lot will be accepted?
(A) 0.600
(B) 0.667
(C) 0.729
(D) 0.810
(E) 0.972
11. Suppose that, in a certain part of the world, in any 50-year period the probability of a major plague is .39, the probability of a major famine is .52, and the probability of both a plague and a famine is .15. What is the probability of a famine given that there is a plague?
(A) 0.240
(B) 0.288
(C) 0.370
(D) 0.385
(E) 0.760
12. Suppose that, for any given year, the probabilities that the stock market declines, that women’s hemlines are lower, and that both events occur are, respectively, 0.4, 0.35, and 0.3. Are the two events independent?
(A) Yes, because (0.4)(0.35) ≠ 0.3.
(B) No, because (0.4)(0.35) ≠ 0.3.
(C) Yes, because 0.4 > 0.35 > 0.3.
(D) No, because 0.5(0.3 + 0.4) = 0.35.
(E) There is insufficient information to answer this question.
13. If P(A) = 0.2 and P(B) = 0.1, what is P(A $\cup$ B) if A and B are independent?
(A) 0.02
(B) 0.28
(C) 0.30
(D) 0.32
(E) There is insufficient information to answer this question.
14. The following data are from The Commissioner’s Standard Ordinary Table of Mortality:
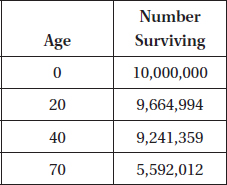
What is the probability that a 20-year-old will survive to be 70?
(A) 0.407
(B) 0.421
(C) 0.559
(D) 0.579
(E) 0.966
15. At a warehouse sale 100 customers are invited to choose one of 100 identical boxes. Five boxes contain \$700 color television sets, 25 boxes contain \$540 camcorders, and the remaining boxes contain \$260 cameras. What should a customer be willing to pay to participate in the sale?
(A) \$260
(B) \$352
(C) \$500
(D) \$540
(E) \$699
16. There are two games involving flipping a coin. In the first game you win a prize if you can throw between 40% and 60% heads. In the second game you win if you can throw more than 75% heads. For each game would you rather flip the coin 50 times or 500 times?
(A) 50 times for each game
(B) 500 times for each game
(C) 50 times for the first game, and 500 for the second
(D) 500 times for the first game, and 50 for the second
(E) The outcomes of the games do not depend on the number of flips.
17. Two cards are picked, without replacement, from a standard deck. Which of the following pairs are independent events?
(A) Getting a heart on the first pick; getting a diamond on the second.
(B) Getting a red card on the first pick; getting a black card on the second.
(C) Getting an ace on the first pick; getting an ace on the second.
(D) Getting two aces; getting two kings.
(E) Getting two aces; getting a black card on the second pick.
18. Two cards are picked, with replacement, from a standard deck. Which of the following pairs are independent events?
(A) Getting two aces; getting two kings.
(B) Getting an ace on the first pick; getting a king on the second.
(C) Getting at least one ace; getting at least one king.
(D) Getting exactly one ace; getting exactly one king.
(E) Getting no aces; getting no kings.
19. The average annual incomes of high school and college graduates in a midwestern town are \$21,000 and \$35,000, respectively. If a company hires only personnel with at least a high school diploma and 20% of its employees have been through college, what is the mean income of the company employees?
(A) \$23,800
(B) \$27,110
(C) \$28,000
(D) \$32,200
(E) \$56,000
20. An insurance company charges \$800 annually for car insurance. The policy specifies that the company will pay \$1000 for a minor accident and \$5000 for a major accident. If the probability of a motorist having a minor accident during the year is 0.2, and of having a major accident, 0.05, how much can the insurance company expect to make on a policy?
(A) \$200
(B) \$250
(C) \$300
(D) \$350
(E) \$450
21. You can choose one of three boxes. Box A has four \$5 bills and a single \$100 bill, box B has 400 \$5 bills and 100 \$100 bills, and box C has 24 \$1 bills. You can have all of box C or blindly pick one bill out of either box A or box B. Which offers the greatest expected winning?
(A) Box A
(B) Box B
(C) Box C
(D) Either A or B, but not C
(E) All offer the same expected winning.
22. Given that 52% of the U.S. population are female and 15% are older than age 65, can we conclude that (0.52)(0.15) = 7.8% are women older than age 65?
(A) Yes, by the multiplication rule.
(B) Yes, by conditional probabilities.
(C) Yes, by the law of large numbers.
(D) No, because the events are not independent.
(E) No, because the events are not mutually exclusive.
Questions 23–27 refer to the following study: One thousand students at a city high school were classified both according to GPA and whether or not they consistently skipped classes.
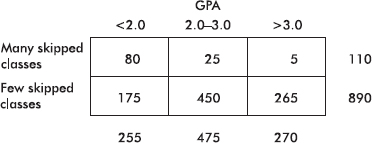
23. What is the probability that a student has a GPA between 2.0 and 3.0?
(A) 0.025
(B) 0.227
(C) 0.450
(D) 0.475
(E) 0.506
24. What is the probability that a student has a GPA under 2.0 and has skipped many classes?
(A) 0.080
(B) 0.281
(C) 0.285
(D) 0.314
(E) 0.727
25. What is the probability that a student has a GPA under 2.0 or has skipped many classes?
(A) 0.080
(B) 0.281
(C) 0.285
(D) 0.314
(E) 0.727
26. What is the probability that a student has a GPA under 2.0 given that he has skipped many classes?
(A) 0.080
(B) 0.281
(C) 0.285
(D) 0.314
(E) 0.727
27. Are “GPA between 2.0 and 3.0” and “skipped few classes” independent?
(A) No, because 0.475 ≠ 0.506.
(B) No, because 0.475 ≠ 0.890.
(C) No, because 0.450 ≠ 0.475.
(D) Yes, because of conditional probabilities.
(E) Yes, because of the product rule.
28. Mathematically speaking, casinos and life insurance companies make a profit because of
(A) their understanding of sampling error and sources of bias.
(B) their use of well-designed, well-conducted surveys and experiments.
(C) their use of simulation of probability distributions.
(D) the central limit theorem.
(E) the law of large numbers.
29. Consider the following table of ages of U.S. senators:
Age (yr): | <40 | 40–49 | 50–59 | 60–69 | 70–79 | >79 |
Number of senators: | 5 | 30 | 36 | 22 | 5 | 2 |
What is the probability that a senator is under 70 years old given that he or she is at least 50 years old?
(A) 0.580
(B) 0.624
(C) 0.643
(D) 0.892
(E) 0.969
Questions 30–33 refer to the following study: Five hundred people used a home test for HIV, and then all underwent more conclusive hospital testing. The accuracy of the home test was evidenced in the following table.

30. What is the predictive value of the test? That is, what is the probability that a person has HIV and tests positive?
(A) 0.070
(B) 0.130
(C) 0.538
(D) 0.583
(E) 0.875
31. What is the false-positive rate? That is, what is the probability of testing positive given that the person does not have HIV?
(A) 0.054
(B) 0.050
(C) 0.130
(D) 0.417
(E) 0.875
32. What is the sensitivity of the test? That is, what is the probability of testing positive given that the person has HIV?
(A) 0.070
(B) 0.130
(C) 0.538
(D) 0.583
(E) 0.875
33. What is the specificity of the test? That is, what is the probability of testing negative given that the person does not have HIV?
(A) 0.125
(B) 0.583
(C) 0.870
(D) 0.950
(E) 0.946
34. Suppose that 2% of a clinic’s patients are known to have cancer. A blood test is developed that is positive in 98% of patients with cancer but is also positive in 3% of patients who do not have cancer. If a person who is chosen at random from the clinic’s patients is given the test and it comes out positive, what is the probability that the person actually has cancer?
(A) 0.02
(B) 0.4
(C) 0.5
(D) 0.6
(E) 0.98
35. Suppose the probability that you will receive an A in AP Statistics is 0.35, the probability that you will receive A’s in both AP Statistics and AP Biology is 0.19, and the probability that you will receive an A in AP Statistics but not in AP Biology is 0.17. Which of the following is a proper conclusion?
(A) The probability that you will receive an A in AP Biology is 0.36.
(B) The probability that you didn’t take AP Biology is .01.
(C) The probability that you will receive an A in AP Biology but not in AP Statistics is 0.18.
(D) The given probabilities are impossible.
(E) None of the above
36. Suppose you are one of 7.5 million people who send in their name for a drawing with 1 top prize of \$1 million, 5 second-place prizes of \$10,000, and 20 third-place prizes of \$100. Is it worth the \$0.44 postage it cost you to send in your name?
(A) Yes, because 1,000,000/0.44=2,272,727 which is less than 7,500,000.
(B) No, because your expected winnings are only \$0.14.
(C) Yes, because 7,500,000/(1+5+20)=288,642
(D) No, because 1,052,000 < 7,500,000.
(E) Yes, because 1,052,000/26=40,462
37. You have a choice of three investments, the first of which gives you a 10% chance of making \$1 million, otherwise you lose \$25,000; the second of which gives you a 50% chance of making $500,000, otherwise you lose \$345,000; and the third of which gives you an 80% chance of making \$50,000, otherwise you make only \$1,000. Assuming you will go bankrupt if you don’t show a profit, which option should you choose for the best chance of avoiding bankruptcy?
(A) First choice
(B) Second choice
(C) Third choice
(D) Either the first or the second choice
(E) All the choices give an equal chance of avoiding bankruptcy.
38. Can the function $f(x)=\frac{x+6}{24}$, for x = 1, 2, and 3, be the probability distribution for some random variable?
(A) Yes.
(B) No, because probabilities cannot be negative.
(C) No, because probabilities cannot be greater than 1.
(D) No, because the probabilities do not sum to 1.
(E) Not enough information is given to answer the question.
39. Sixty-five percent of all divorce cases cite incompatibility as the underlying reason. If four couples file for a divorce, what is the probability that exactly two will state incompatibility as the reason?
(A) 0.104
(B) 0.207
(C) 0.254
(D) 0.311
(E) 0.423
40. Suppose we have a random variable X where for the values k = 0, …, 10, the associated probabilities are $\begin{pmatrix}10 \\k\end{pmatrix}0.37^k0.63^{10-k}$ What is the mean of X?
(A) 0.37
(B) 0.63
(C) 3.7
(D) 6.3
(E) None of the above
41. A computer technician notes that 40% of computers fail because of the hard drive, 25% because of the monitor, 20% because of a disk drive, and 15% because of the microprocessor. If the problem is not in the monitor, what is the probability that it is in the hard drive?
(A) 0.150
(B) 0.400
(C) 0.417
(D) 0.533
(E) 0.650
42. Suppose you toss a fair coin ten times and it comes up heads every time. Which of the following is a true statement?
(A) By the law of large numbers, the next toss is more likely to be tails than another heads.
(B) By the properties of conditional probability, the next toss is more likely to be heads given that ten tosses in a row have been heads.
(C) Coins actually do have memories, and thus what comes up on the next toss is influenced by the past tosses.
(D) The law of large numbers tells how many tosses will be necessary before the percentages of heads and tails are again in balance.
(E) The probability that the next toss will again be heads is 0.5.
43. A city water supply system involves three pumps, the failure of any one of which crashes the system. The probabilities of failure for each pump in a given year are 0.025, 0.034, and 0.02, respectively. Assuming the pumps operate independently of each other, what is the probability that the system does crash during the year?
(A) Less than 0.05
(B) 0.077
(C) 0.079
(D) 0.081
(E) 0.923
44. Which of the following are true statements?
I. The histogram of a binomial distribution with p = 0.5 is always symmetric no matter what n, the number of trials, is.
II. The histogram of a binomial distribution with p = 0.9 is skewed to the right.
III. The histogram of a binomial distribution with p = 0.9 is almost symmetric if n is very large.
(A) I and II
(B) I and III
(C) II and III
(D) I, II, and III
(E) None of the above gives the complete set of true responses.
45. Suppose that 60% of students who take the AP Statistics exam score 4 or 5, 25% score 3, and the rest score 1 or 2. Suppose further that 95% of those scoring 4 or 5 receive college credit, 50% of those scoring 3 receive such credit, and 4% of those scoring 1 or 2 receive credit. If a student who is chosen at random from among those taking the exam receives college credit, what is the probability that she received a 3 on the exam?
(A) 0.125
(B) 0.178
(C) 0.701
(D) 0.813
(E) 0.822
46. Given the probabilities P(A) = 0.4 and P(A $\cup$ B) = 0.6, what is the probability P(B) if A and B are mutually exclusive? If A and B are independent?
(A) 0.2, 0.4
(B) 0.2, 0.33
(C) 0.33, 0.2
(D) 0.6, 0.33
(E) 0.6, 0.4
47. There are 20 students in an AP Statistics class. Suppose all are unprepared and randomly guess on each of ten multiple-choice questions, each with a choice of five possible answers. Which of the following is one run of a simulation to estimate the probability at least one student guesses correctly on over half the questions?
(A) Assume “1” is the correct answer and “2, 3, 4, 5” are incorrect answers. Randomly pick 200 numbers between 1 and 5. Arrange the numbers into 20 groups of 10 each, each group corresponding to one of the students. For each student, count how many correct (“1”) answers there are. Record whether at least one student has six or more correct answers.
(B) Assume “2” is the correct answer and “1, 3, 4, 5” are incorrect answers. Assign the numbers 1–20 to the students. Randomly choose 200 numbers between 1 and 20. For each number chosen, randomly pick a number between 1 and 5. Record how many correct (“2”) answers there are, divide by 20, and record whether this quotient is at least six.
(C) Assume “3” is the correct answer and “1, 2, 4, 5” are incorrect answers. Assign the numbers 1–10 to the questions. Randomly choose 200 numbers between 1 and 10. For each number chosen, randomly pick a number between 1 and 5. Record how many correct (“3”) answers there are, divide by 20, and record whether this quotient is at least six.
(D) Assume “4” is the correct answer and “1, 2, 3, 5” are incorrect answers. Randomly choose 200 numbers between 1 and 5. Record how many correct (“4”) answers there are, divide by 20, and record whether this quotient is at least six.
(E) Assume “5” is the correct answer and “1, 2, 3, 4” are incorrect answers. Randomly pick 20 numbers between 1 and 5. Do this 10 times, and for each group of 20 note how many correct (“5”) answers there are. Record whether at least one group has over half correct answers.
Free-Response Questions
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your final answers.
SEVEN OPEN-ENDED QUESTIONS
1. A manufacturer is considering two options for a quality control check at the end of a production line:
Option A: | If at least five of six randomly picked articles meet all specifications, the day’s production is approved. |
Option B: | If at least ten of twelve randomly picked articles meet all specifications, day’s production is approved. |
If you are a buyer wanting the most assurance that a day’s production will not be accepted if there were only 75% of the articles meeting all specifications, which option would you request the manufacturer to use? Give statistical justification.
2. A sample of applicants for a management position yields the following numbers with regard to age and experience:

(a) What is the probability that an applicant is less than 50 years old? Has more than 10 years’ experience? Is more than 50 years old and has five or fewer years’ experience?
(b) What is the probability that an applicant is less than 50 years old given that she has between 6 and 10 years’ experience?
(c) Are the two events “less than 50 years old” and “more than 10 years’ experience” independent events? How about the two events “more than 50 years old” and “between 6 and 10 years’ experience”? Explain.
3. Suppose USAir accounts for 20% of all U.S. domestic flights. As of mid-1994, USAir was involved in four of the previous seven major disasters. “That’s enough to begin getting suspicious but not enough to hang them,” said Dr. Brad Efton in The New York Times (September 11, 1994, Sec. 4, p. 4). Using a binomial distribution, comment on Dr. Efton’s remark.
4. Assume there is no overlap between the 56% of the population who wear glasses and the 4% who wear contacts. If 55% of those who wear glasses are women and 63% of those who wear contacts are women, what is the probability that the next person you encounter on the street will be a woman with glasses? A woman with contacts? A man with glasses? A man with contacts? A person not wearing glasses or contacts? Explain your reasoning.
5. Explain what is wrong with each of the following statements:
(a) The probability that a student will score high on the AP Statistics exam is 0.43, while the probability that she will not score high is 0.47.
(b) The probability that a student plays tennis is 0.18, while the probability that he plays basketball is six times as great.
(c) The probability that a student enjoys her English class is 0.64, while the probability that she enjoys both her English and her social studies classes is 0.71.
(d) The probability that a student will be accepted by his first choice for college is 0.38, while the probability that he will be accepted by his first or second choice is 0.32.
(e) The probability that a student fails AP Statistics and will still be accepted by an Ivy League school is –0.17.
6. Player A rolls a die with 7 on four sides and 11 on two sides. Player B flips a coin with 6 on one side and 10 on the other. Assume a fair die and a fair coin.
(a) Suppose the winner is the player with the higher number showing. Explain who you would rather be. If player A receives $0.25 for every win, what should player B receive for every win to make the game fair?
(b) Suppose player A receives \$0.70 from player B when the 7 shows and $1.10 when the 11 shows, while player B receives \$0.60 from player A when the 6 shows and \$1.00 when the 10 shows. Explain whom you would rather be.
7. Could hands-free, automatic faucets actually be housing more bacteria than the old-fashioned, manual kind? The concern is that decreased water flow may increase the chance that bacteria grows, because the automatic faucets are not being thoroughly flushed through. It is known that 15% of water cultures from older faucets in hospital patient care areas test positive for Legionella bacteria. A recent study at Johns Hopkins Hospital found Legionella bacteria growing in 10 of cultured water samples from 20 electronic faucets.
(a) If the probability of Legionella bacteria growing in a faucet is 0.15, what is the probability that in a sample of 20 faucets, 10 or more have the bacteria growing?
(b) Does the Johns Hopkins study provide sufficient evidence that the probability of Legionella bacteria growing in electronic faucets is greater than 15%? Explain.
AN INVESTIGATIVE TASK
If a car is stopped for speeding, the probability that the driver has illegal drugs hidden in the car is 0.14. A police officer manning a speed trap plans to thoroughly search cars he stops for speeding until he finds one with illegal drugs.
(a) Use simulation to estimate the probability that illegal drugs will turn up before he stops the tenth car. Explain your work. Use the following random number table to run as many trials as possible.
8417706757 1761315582 5150681435 4105092031 0644905059
5988431180 5311584469 9486857967 0581184514 7501113006
6339555041 1586606589 1311971020 8594091932 0648874987
5435552704 9035902649 4749671567 9426808844 2629464759
0898957024 9728400637 8928303514 5919507635 0330972605
2935723737 6788103668 3387635841 5286923114 1586438942
(b) The results of a 100-trial simulation are shown below. Each trial ends when a car with illegal drugs is found.
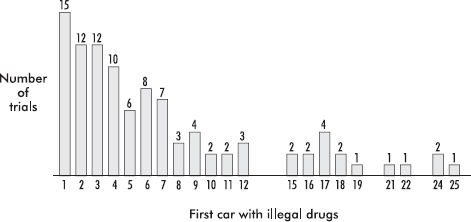
Use the above 100-trial results to estimate the mean number of cars searched before finding one with illegal drugs.
(c) Use probability to calculate the probability that illegal drugs will be found before he stops the tenth car. Show your work.
MULTIPLE-CHOICE
1. (E) There is no reason to assume that the probability of getting a 5 is the same as that of not getting a 5.
2. (E) The probability that both events will occur is the product of their separate probabilities only if the events are independent, that is, only if the chance that one event will happen is not influenced by whether or not the second event happens. In this case the probability of different surgeries failing are probably closely related.
3. (B) P(1st die is 4)P(2nd die is 6) + P(1st die is 6)P(2nd die is 4) + P(1st die is 5)P(2nd die is 5)
4. (A) 10(0.15)2(0.85)3 = 0.138 or binompdf(5, .15, 2) = 0.138
5. (B) The probability of the next child being a girl is independent of the gender of the previous children.
6. (B) 1 – (0.99975)100 = 0.0247
7. (D) 0.001(1,500,000) = 1500
8. (D) 

[Or on the TI-84, put returns and probabilities into two lists and run 1-Var Stats L1,L2]
9. (C)  are honors students, and
are honors students, and  prefer basketball. Because of independence, their intersection is (0.25)(0.3) = 0.075 of the students, and 0.075(6000) = 450.
prefer basketball. Because of independence, their intersection is (0.25)(0.3) = 0.075 of the students, and 0.075(6000) = 450.
10. (E) (0.9)3 + 3(0.9)2(0.1) = 0.972
11. (D) 
12. (B) If E and F are independent, then P(E  F) = P(E)P(F); however, in this problem, (0.4)(0.35) ≠ 0.3.
F) = P(E)P(F); however, in this problem, (0.4)(0.35) ≠ 0.3.
13. (B) Because A and B are independent, we have P(A B) = P(A)P(B), and thus P(A ∪ B) = 0.2 + 0.1 – (0.2)(0.1) = 0.28.
14. (D) 
15. (B) E(X) = µx =  xipi = 700(0.05) + 540(0.25) + 260(0.7) = 352
xipi = 700(0.05) + 540(0.25) + 260(0.7) = 352
16. (D) The probability of throwing heads is 0.5. By the law of large numbers, the more times you flip the coin, the more the relative frequency tends to become closer to this probability. With fewer tosses there is a greater chance of wide swings in the relative frequency.
17. (E) P(diamond on 2nd pick) = 1/4; however,
P(diamond on 2nd pick | heart on first pick) = 13/51
P(black on 2nd pick) = 1/2; however, P(black on 2nd pick | red on 1st pick) = 26/51
P(ace on 2nd pick) = 1/13; however, P(ace on 2nd pick | ace on 1st pick) = 3/51
P(two kings) = (1/13)(3/51); however, P(two kings | two aces) = 0
P(black on 2nd pick) = 1/2 and P(black on 2nd pick | two aces) = 6/12
18. (B) P(two kings) = (1/13)(1/13); however, P(two kings | two aces) = 0
P(king on 2nd pick) = 1/13, and P(king on 2nd pick | ace on 1st pick) = 1/13
P(at least one king) = 1 – (12/13)2 = 25/169; however,
P(at least one king | at least one ace) = [(1/13)(1/13) + (1/13)(1/13)]/[25/169] = 2/25
P(exactly one king) = (1/13)(12/13) + (12/13)(1/13) = 24/169; however,
P(exactly one king | exactly one ace) = (2/169)/(24/169) = 1/12
P(no kings) = (12/13)2; however, P(no kings | no aces) = (11/12)2
19. (A) E(X) = µx = xipi = 21,000(0.8) + 35,000(0.2) = 23,800
20. (D) 1000(0.2) + 5000(0.05) = 450, and 800 – 450 = 350.
21. (E) 
22. (D) P(E F) = P(E)P(F) only if the events are independent. In this case, women live longer than men and so the events are not independent.
For Questions 23–27, we first sum the rows and columns:

23. (D) 
24. (A)  (probability of an intersection)
(probability of an intersection)
25. (C)  (probability of a union)
(probability of a union)
26. (E)  (conditional probability)
(conditional probability)
27. (A)  0.506. If independent, these would have been equal.
0.506. If independent, these would have been equal.
28. (E) While the outcome of any single play on a roulette wheel or the age at death of any particular person is uncertain, the law of large numbers gives that the relative frequencies of specific outcomes in the long run tend to become closer to numbers called probabilities.
29. (D) 
30. (A) 
31. (A) 
32. (E) 
33. (E) 
34. (B)

35. (D) The probability that you will receive an A in AP Statistics but not in AP Biology must be 0.35 – 0.19 = 0.16, not 0.17.
36. (B) Your expected winnings are only

37. (C) Even though the first two choices have a higher expected value than the third choice, the third choice gives a 100% chance of avoiding bankruptcy.
38. (A) The probabilities  are all nonnegative, and they sum to 1.
are all nonnegative, and they sum to 1.
39. (D) 6(0.65)2(0.35)2 = 0.311 or binompdf(4, .65, 2) = 0.311
40. (C) This is a binomial with n = 10 and p = 0.37, and so the mean is np = 10(0.37) = 3.7.
41. (D) 
42. (E) Coins have no memory, and so the probability that the next toss will be heads is .5 and the probability that it will be tails is 0.5. The law of large numbers says that as the number of tosses becomes larger, the percentage of heads tends to become closer to 0.5.
43. (B) The probabilites of each pump not failing are 1 – 0.025 = 0.975, 1 – 0.034 = 0.966, and 1 – 0.02 = 0.98, respectively. The probability of none failing is (0.975)(0.966)(0.98) = .923, and so the probability of at least one failing is 1 – 0.923 = 0.077.
44. (B) If p > 0.5, the more likely numbers of successes are to the right and the lower numbers of successes have small probabilities, and so the histogram is skewed to the left. No matter what p is, if n is sufficiently large, the histogram will look almost symmetric.
45. (B)

46. (B) If A and B are mutually exclusive, P(A B) = 0. Thus 0.6 = 0.4 + P(B) – 0, and so P(B) = 0.2. If A and B are independent, then P(A B) = P(A)P(B). Thus 0.6 = 0.4 + P(B) – 0.4P(B), and so P(B) = 
47. (A) For each of the 20 students, we must generate an answer to each of the 10 questions, and record if any student has at least 6 out of 10 correct answers.
FREE-RESPONSE
1. With Option A, if in reality only 75% of the articles meet all specifications, the probability of rejecting the day’s production is:

[On the TI-84, binomcdf(6,.75,4) = .466]
With Option B, if in reality only 75% of the articles meet all specifications, the probability of rejecting the day’s production is:

[On the TI-84, binomcdf(12,.75,9) = .609]
For the greatest probability of rejecting the day’s production if only 75% of the articles meet all specifications, the buyer should request the manufacturer to use Option B with a probability of rejection of 0.609 as opposed to Option A with a probability of rejection of only 0.466.
2. It’s easiest to first sum the rows and columns:

(a) 
(b) 
(c) 
3. If USAir accounted for 20% of the major disasters, the chance that it would be involved in at least four of seven such disasters is

[Or binomcdf(7, .8, 3) = 0.033.]
Mathematically, if USAir accounted for only 20% of the major disasters, there is only a 0.033 chance of it being involved in four of seven such disasters. This seems more than enough evidence to be suspicious!
4.

If 55% of those who wear glasses are women, 45% of those who wear glasses must be men, and if 63% of those who wear contacts are women, 37% of those who wear contacts must be men. Thus we have

The probability that you will encounter a person not wearing glasses or contacts is 1 – (0.308 + 0.0252 + 0.252 + 0.0148) = 0.4.
5. (a) The probability of the complement is 1 minus the probability of the event, but 1 – 0.43 ≠ 0.47.
(b) Probabilities are never greater than 1, but 6(0.18) = 1.08.
(c) The probability of an intersection cannot be greater than the probability of one of the separate events.
(d) The probability of a union cannot be less than the probability of one of the separate events.
(e) Probabilities are never negative.
6. (a) Player B wins only if both a 10 shows on the coin (a probability of  ) and a 7 shows on the die (a probability of
) and a 7 shows on the die (a probability of  ). These events will both happen
). These events will both happen  of the time, and so player A wins of the time or twice as often as player B. Thus, to make this a fair game, player B should receive $0.50 each time he wins.
of the time, and so player A wins of the time or twice as often as player B. Thus, to make this a fair game, player B should receive $0.50 each time he wins.
TIP
When using a formula, write down the formula and then substitute the values.
(b) Player A’s expected payoff is

while player B’s expected payoff is

7. (a) We have a binomial with n = 20 and p = 0.15, so

[The answer comes quickly from a calculator calculation such as 1-binomcdf(20, .15, 9) on the TI-84.]
(b) If the probability of Legionella bacteria growing in an electric faucet is 0.15, then the probability of a result as extreme or more extreme than what was obtained in the Johns Hopkins study is only 0.00025. With such a low probability, there is strong evidence to conclude that the probability of Legionella bacteria growing in electronic faucets is greater than .15. That is, there is strong evidence that automatic faucets actually house more bacteria than the old-fashioned, manual kind!
INVESTIGATIVE TASK
(a) Let the numbers 01 through 14 represent finding an illegal drug, while 15 through 99 and 00 represent no drugs. Read off pairs of digits from the random number table until a number representing illegal drugs is found or until nine clean cars are allowed to pass. Note whether a car with illegal drugs is found before nine clean cars pass. Repeat this procedure. Underlining numbers representing the presence of illegal drugs gives

The first nine cars are clean. Then 14 is found after four clean cars, then 05 after two clean cars, then 09 before any clean cars, then 06 after two clean cars, then 11 after seven free cars, and so on. Tabulating gives
First nine cars clean: 5
Illegal drugs found before tenth car: 24
The probability that illegal drugs will be found before the tenth car is estimated to be 
(b) xP(x) = 1(0.15) + 2(0.12) + · · · + 25(0.01) = 6.81
(c) The probability that the first stopped car will have illegal drugs is 0.14. The probability that the first will be clean but that the second will have drugs is (0.86)(0.14). The probability that two clean cars will be followed by one with drugs is (0.86)2(0.14). The probability that three clean ones will be followed by one with drugs is (0.86)3(0.14), and so on. The probability of drugs being found before the tenth car is
0.14 + (0.86)(0.14) + (0.86)2(0.14) + · · · + (0.86)8(0.14) = 0.7427
Or more simply we could solve by subtracting the complementary probability from 1, that is, 1 – (0.86)9 = 0.7427.
MEANS AND VARIANCES FOR SUMS AND DIFFERENCES OF SETS
MEANS AND VARIANCES FOR SUMS AND DIFFERENCES OF INDEPENDENT RANDOM VARIABLES
In many experiments, a pair of numbers is associated with each outcome. This situation leads to a study of pairs of random variables. When the random variables are independent, there is an easy calculation for finding both the mean and standard deviation of the sum (and difference) of the two random variables.
MEANS AND VARIANCES FOR SUMS AND DIFFERENCES OF SETS
EXAMPLE 10.1
A casino offers couples at the hotel free chips—each person reaches into a bag and pulls out a card stating the number of free chips—one person’s bag has a set of four cards with X = {1, 9, 20, 74}; the other person’s bag has a set of three cards with Y = {5, 15, 55}. Note that the mean of set X is $\mu_x=\frac{1+9+20+74}{4}=26 $ and that of set $y$ is $\mu_y=\frac{5+15+55}{43}=25$ What is the average amount they should be able to pool together?
Answer: Form the set W of sums: W = {1 + 5, 1 + 15, 1 + 55, 9 + 5, 9 + 15, 9 + 55, 20 + 5, 20 + 15, 20 + 55, 74 + 5, 74 + 15, 74 + 55} = {6, 16, 56, 14, 24, 64, 25, 35, 75, 79, 89, 129} and
![]()
We note that µW = µX + Y = µX + µY.
In general, the mean of a set of sums is equal to the sum of the means of the two original sets. Even more generally, if a sum is formed by picking one element from each of several sets, the mean of such sums is simply the sum of the means of the various sets.
How is the variance of W related to the variances of the original sets?
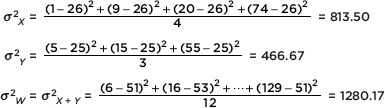
Note that $\sigma^2_W=\sigma^2_{X+Y}=\sigma^2_X+\sigma^2_Y$.
This is true for the variance of any set of sums. More generally, if a sum is formed by picking one element from each of several sets, the variance of such sums is simply the sum of the variances of the various sets.
We can also calculate the standard deviation $\sigma_W=\sqrt{1280.17}=35.78$ and conclude the average pooled number of chips received by a couple is 51 with a standard deviation of 35.78.
EXAMPLE 10.2
In Example 10.1, what is the average difference in number of chips received from bag X and bag Y?
Answer: Form the set of differences: Z = {1 – 5, 1 – 15, 1 – 55, 9 – 5, 9 – 15, 9 – 55, 20 – 5, 20 – 15, 20 – 55, 74 – 5, 74 – 15, 74 – 55} = {–4, –14, –54, 4, –6, –46, 15, 5, –35, 69, 59, 19}
A quick calculation gives µZ = 1. Note that µZ = µX – Y = µX – µY = 26 – 25 = 1. In general, the mean of a set of differences is equal to the difference of the means of the two original sets.
How is the variance of Z related to the variance of the original sets?
A calculation (for example, using 1-Var Stats on the TI-84) yields $\sigma^2_Z$ = 1280.17. Wow, the set of differences has the same variance as the set of sums! We have, $\sigma$2Z = $\sigma$2X – Y = $\sigma$2X + $\sigma$2Y. More generally, if a total is formed by a procedure that adds or subtracts one element from each of several independent sets, the variance of the resulting totals is simply the sum of the variances of the several sets.
Not only can we sum variances as shown above to calculate total variance, but we can also reverse the process and determine how the total variance is split up among its various sources. For example, we can find what portion of the variance in numbers of sales made by a company’s sales representatives is due to the individual salesperson, what portion is due to the territory, what portion is due to the particular products sold by each salesperson, and so on.
EXAMPLE 10.3
A company’s sports shoes sell for an average of \$100 with a standard deviation of \$9. The costs going into their sports shoes are as follows:
Retail store costs and profits: average of \$45 with a standard deviation of \$5.
Brand company costs and profits: average of \$24 with a standard deviation of \$4.
Advertising and publicity costs: average of \$11 with a standard deviation of \$3.
Assuming these various costs are independent of one another, what is the mean and standard deviation for the remaining costs R together (which includes materials, transportation, factory worker wages, etc.)?
Answer: 45 + 24 + 11 + µR = 100 gives µR = $20; and 52 + 42 + 32 + $\sigma$2R = 92 gives $\sigma$2R = 31 and $\sigma_R=\sqrt{31}=5.57$.
MEANS AND VARIANCES FOR SUMS AND DIFFERENCES OF INDEPENDENT RANDOM VARIABLES
The mean of the sum (or difference) of two random variables is equal to the sum (or difference) of the individual means. If two random variables are independent, the variance of the sum (or difference) of the two random variables is equal to the sum of the two individual variances.
TIP
Variances of independent random variables add, but standard deviations don’t!
EXAMPLE 10.4
An insurance salesperson estimates the numbers of new auto and home insurance policies she sells per day as follows:
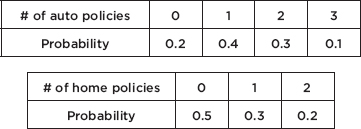
What is the expected value or mean for the overall number of policies sold per day?
Answer: µauto = (0)(0.2) + (1)(0.4) + (2)(0.3) + (3)(0.1) = 1.3,
µhome = (0)(0.5) + (1)(0.3) + (2)(0.2) = 0.7, and so
µtotal = µauto + µhome = 1.3 + 0.7 = 2.0.
Assuming the selling of new auto policies is independent of the selling of new home policies (which may not be true if some new customers buy both), what would be the standard deviation in the number of new policies sold per day?
Answer: $\sigma$2auto = (0 – 1.3)2(0.2) + (1 – 1.3)2(0.4) + (2 – 1.3)2(0.3) + (3 – 1.3)2(0.1) = 0.81,
$\sigma$2home = (0 – 0.7)2(0.5) + (1 – 0.7)2(0.3) + (2 – 0.7)2(0.2) = 0.61, and so, assuming independence, $\sigma$2total = $\sigma$2auto + $\sigma$2home = 0.81 + 0.61 = 1.42 and
$\sigma^2=\sqrt{1.42}=1.192.$
EXAMPLE 10.5
Vitamin C megadoses are claimed by alternative medicine advocates to have effects on diseases such as cancer and AIDS, as well as on the common cold. In one long-term study, participants received either a placebo or a 200-mg Vitamin C tablet each day. Suppose that the mean compliance rate was 73% with a standard deviation of 24%. Furthermore, the daily intake of Vitamin C through foods among the adult population is 94 g with a standard deviation of 39 g. Among those receiving the supplement, what is the mean and standard deviation for their daily Vitamin C intake?
Answer: With a compliance of 73%, the mean intake of Vitamin C from the supplement is (0.73)(200) = 146 with a standard deviation of (0.24)(200) = 48. Thus, the total mean intake of Vitamin C is 146 + 94 = 240 g with a standard deviation of $\sqrt{48^2+39^2}=61.85g$ (with independence, variances add!).
EXAMPLE 10.6
Suppose the mean SAT math, critical reading, and writing scores for students at a particular high school are 515, 501, and 493, respectively, with standard deviations of 65, 40, and 38. What can be said about the mean and standard deviation of the three combined scores for these students?
Answer: The mean combined score is 515 + 501 + 493 = 1509. Can we add the three variances, 652 + 402 + 382 and then take the square root to obtain the desired standard deviation? No, because we don’t have independence—students with high scores on one of the three sections will tend to have high scores on the other two sections. The standard deviation of the combined scores cannot be calculated from the given information.
For random variables X and Y the generalizations for transforming X and for combining X and Y are sometimes written as
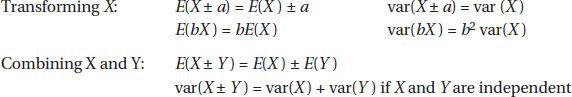
Does it make sense that variances add for both sums and differences of independent random variables? Ranges may illustrate this point more clearly: suppose prices for primary residences in a community go from \$210,000 to \$315,000, while prices for summer cottages go from \$50,000 to \$120,000. Someone wants to purchase a primary residence and a summer cottage. The minimum total spent will be \$260,000, the maximum possible is \$435,000, and thus the range for the total is \$435,000 – \$260,000 = \$175,000. The minimum difference spent between the two homes will be $90,000, the maximum difference will be \$265,000, and thus the range for the difference is \$265,000 – \$90,000 = \$175,000, the same as the range for the total. (Variances and ranges are both measures of spread and behave the same way with regard to the above rule.)
SUMMARY
When combining two random variables, E(X + Y) = E(X) + E(Y) and E(X – Y) = E(X) – E(Y).
When combining two independent random variables, the variances always add: var(X ± Y) = var(X) + var(Y).
Multiple-Choice Questions
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. An auto dealer offers discounts averaging \$2,450 with a standard deviation of \$575. If 50 autos are sold during one month, what is the expected value and standard deviation for the total discounts given?
(A) E(Total) | = \$17,324 | SD(Total) | = \$170 |
(B) E(Total) | = \$17,324 | SD(Total) | = \$4066 |
(C) E(Total) | = \$122,500 | SD(Total) | = \$170 |
(D) E(Total) | = \$122,500 | SD(Total) | = \$4066 |
(E) E(Total) | = \$122,500 | SD(Total) | = \$28,750 |
2. An auto dealer pays an average of \$8,750 with a standard deviation of \$1,200 for used car trade-ins, and sells new cars for an average of \$28,500 with a standard deviation of \$3,100. Assuming independence of trade-in and new car prices for a customer, what is the standard deviation of the revenue the dealer should expect to make if a customer trades in a used car and buys a new one?

3. Suppose a retailer knows that the mean number of broken eggs per carton is 0.3 with a standard deviation of 0.18. In a shipment of 100 cartons, what is the expected number of broken eggs and what is the standard deviation? Assume independence between cartons.
(A) E(broken) | = 3 | SD(broken) | = 1.8 |
(B) E(broken) | = 30 | SD(broken) | = 1.8 |
(C) E(broken) | = 30 | SD(broken) | = 18 |
(D) E(broken) | = 300 | SD(broken) | = 18 |
(E) E(broken) | = 300 | SD(broken) | = 180 |
4. Science majors in college pay an average of \$650 per year for books with a standard deviation of \$130, whereas English majors pay an average of \$465 per year for books with a standard deviation of \$90. What is the mean difference and standard deviation between the amounts paid for books by science and English majors?
(A) E(Diff) | = \$92.50 | SD(Diff) | = \$15 |
(B) E(Diff) | = \$185 | SD(Diff) | = \$110 |
(C) E(Diff) | = \$185 | SD(Diff) | = \$158 |
(D) E(Diff) | = \$185 | SD(Diff) | = \$220 |
(E) E(Diff) | = \$557.50 | SD(Diff) | = \$110 |
5. The auditor working for a veterinary clinic calculates that the mean annual cost of medical care for dogs is \$98 with a standard deviation of \$25 and that the mean annual cost of medical care for pets is \$212 with an average deviation of \$39 for owners who have one dog and one cat. Assuming expenses for dogs and cats are independent for those owning both a dog and a cat, what is the mean annual cost of medical care for cats, and what is the standard deviation?
(A) E(Cats) | = \$114 | SD(Cats) | = \$14 |
(B) E(Cats) | = \$114 | SD(Cats) | = \$46 |
(C) E(Cats) | = \$114 | SD(Cats) | = \$30 |
(D) E(Cats) | = \$155 | SD(Cats) | = \$32 |
(E) E(Cats) | = \$188 | SD(Cats) | = \$30 |
6. A home theater projector system technician knows that based on past experience, for unpacking, assembly, and fine tuning, the mean total setup time is 5.6 hours with a standard deviation of 0.886 hours. The times for the three steps are independent, the mean and standard deviation for the unpacking time are 1.5 hours and 0.2 hours, and for the assembly time are 2.8 hours and 0.85 hours, respectively. What are the mean and standard deviation for the fine tuning time?
(A) E(Fine tuning) | = 1.3 hr | SD(Fine tuning) | = 0.15 hr |
(B) E(Fine tuning) | = 1.3 hr | SD(Fine tuning) | = 1.24 hr |
(C) E(Fine tuning) | = 2.15 hr | SD(Fine tuning) | = 0.164 hr |
(D) E(Fine tuning) | = 2.15 hr | SD(Fine tuning) | = 1.24 hr |
(E) E(Fine tuning) | = 4.61 hr | SD(Fine tuning) | = 0.15 hr |
7. Boxes of 50 “donut holes” weigh an average of 16.0 ounces with a standard deviation of 0.245 ounces. If the empty boxes alone weigh an average of 1.0 ounce with a standard deviation of 0.2 ounces, what are the mean and standard deviation of donut hole weights?
(A) E(Donut hole) | = 0.3 oz | SD(Donut hole) | = 0.0063 oz |
(B) E(Donut hole) | = 0.3 oz | SD(Donut hole) | = 0.02 oz |
(C) E(Donut hole) | = 0.3 oz | SD(Donut hole) | = 0.142 oz |
(D) E(Donut hole) | = 15 oz | SD(Donut hole) | = 0.142 oz |
(E) E(Donut hole) | = 15 oz | SD(Donut hole) | = 0.445 oz |
AN INVESTIGATIVE TASK
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your final answers.
Two researchers at a consumer protection agency ran independent surveys to estimate mean debt of graduating college bachelor’s degree recipients. The first researcher selected a random sample of 800 bachelor’s degree recipients; the second researcher selected a random sample of 600 bachelor’s degree recipients from public schools and 200 from private schools. Summary statistics are as follows:
First researcher:
| n | Mean | Standard |
Debt at graduation | 800 | \$16,300 | \$7800 |
Second researcher:
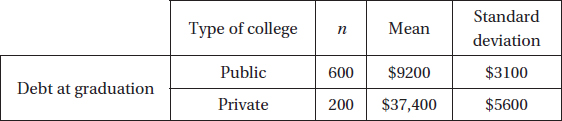
The first researcher used x as an estimator for the mean debt of all bachelor’s degree recipients, and the second researcher used xoverall = (0.75) xpublic + (0.25) xprivate as an estimator for the mean debt of all bachelor’s degree recipients.
(a) For the first researcher, based on the summary statistics, calculate the standard error of the sampling distribution of x.
(b) For the second researcher, based on the summary statistics, calculate the standard error of the sampling distribution of xoverall.
(c) Explain why, based on the summary statistics, it was expected that the answer to (b) would be smaller than the answer to (a).
MULTIPLE-CHOICE
1. (D) Expected values and variances add. Thus,

2. (C) For a set of differences, means subtract, but variances add. Thus,

3. (B) Expected values and variances add. Thus,

4. (C) For a set of differences, means subtract, but variances add. Thus,

5. (C) Means and variances add. Thus,

6. (A) Means and variances add. Thus,

7. (B) Means and variances add. Thus,
E(Total )= E(Box)+50E(Hole), 16.0 = 1.0+50E(Hole), E(Hole)= 0.3
Var(Total) = Var(Box) + 50Var(Hole),
0.2452 = 0.22 + 50(SD(Hole))2, SD(Hole) = 0.02
AN INVESTIGATIVE TASK
(a) 
(b) 
(c) The means for each school type are significantly different, and the variability around the mean for each separate school type is much less than what it was for the first researcher. The second researcher took advantage of this decreased variability within school types, whereas the first researcher has more variability because all the bachelor’s degree recipients are put together in a single sample.
PROPERTIES
USING TABLES
A MODEL FOR MEASUREMENT
COMMONLY USED PROBABILITIES AND Z-SCORES
FINDING MEANS AND STANDARD DEVIATIONS
NORMAL APPROXIMATION TO THE BINOMIAL
CHECKING NORMALITY
Some of the most useful probability distributions are symmetric and bell-shaped:
In this topic we study one such distribution called the normal distribution (not all symmetric, unimodal distributions are normal). The normal distribution is valuable in describing various natural phenomena, especially those involving growth or decay. However, the real importance of the normal distribution in statistics is that it can be used to describe the results of sampling procedures.
The normal distribution can be viewed as a limiting case of the binomial. More specifically, we start with any fixed probability of success p and consider what happens as n becomes arbitrarily large. To obtain a visual representation of the limit, we draw histograms using an increasingly large n for each fixed p.
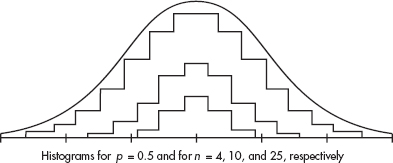
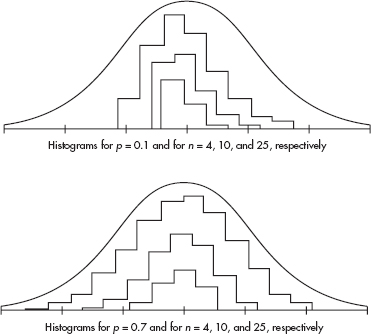
For greater clarity, different scales have been used for the histograms associated with different values of n. From the diagrams above it is reasonable to accept that as n becomes larger without bound, the resulting histograms approach a smooth bell-shaped curve. This is the curve associated with the normal distribution.
PROPERTIES OF THE NORMAL DISTRIBUTION
The normal distribution curve is bell-shaped and symmetric and has an infinite base. Long, flat-looking tails cover many values but only a small proportion of the area. The flat appearance of the tails is deceptive. Actually, far out in the tails, the curve drops proportionately at an ever-increasing rate. In other words, when two intervals of equal length are compared, the one closer to the center may experience a greater numerical drop, but the one further out in the tail experiences a greater drop when measured as a proportion of the height at the beginning of the interval.
The mean here is the same as the median and is located at the center. We want a unit of measurement that applies equally well to any normal distribution, and we choose a unit that arises naturally out of the curve’s shape. There is a point on each side where the slope is steepest. These two points are called points of inflection, and the distance from the mean to either point is precisely equal to one standard deviation. Thus, it is convenient to measure distances under the normal curve in terms of z-scores (recall from Topic 2 that z-scores are fractions or multiples of standard deviations from the mean).
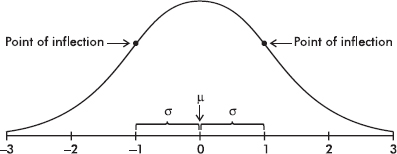
TIP
The notation N(µ,$\sigma$) stands for a normal model with mean µ and standard deviation σ.
Mathematically, the formula for the normal curve turns out to be y = e –z2/2, where y is the relative height above z-score. (By relative height we mean proportion of the height above the mean.) However, our interest is not so much in relative heights under the normal curve as it is in proportionate areas. The probability associated with any interval under the normal curve is equal to the proportionate area found under the curve and above the interval.
A useful property of the normal curve is that approximately 68% of the area (and thus 68% of the observations) falls within one standard deviation of the mean, approximately 95% of the area falls within two standard deviations of the mean, and approximately 99.7% of the area falls within three standard deviations of the mean.

USING TABLES OF THE NORMAL DISTRIBUTION
Table A in the Appendix shows areas under the normal curve. Specifically, this table shows the area to the left of a given point. It shows, for example, that to the left of a z-score of 1.2 there is 0.8849 of the area:
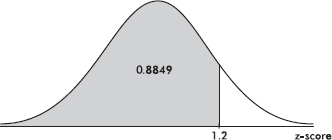
Because the total area is 1, the area to the right of a point can be calculated by calculating 1 minus the area to the left of the point. For example, the area to the right of a z-score of – 2.13 is 1 – 0.0166 = 0.9834. (Alternatively, by symmetry, we could have said that the area to the right of –2.13 is the same as that to the left of +2.13 and then read the answer directly from Table A.)
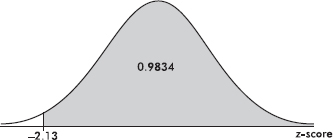
The area between two points can be found by subtraction. For example, the area between the z-scores of 1.23 and 2.71 is equal to 0.9966 – 0.8907 = 0.1059.
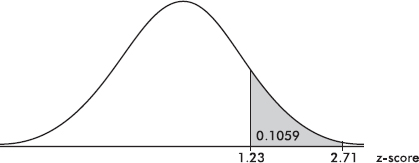
Given a probability, we can use Table A in reverse to find the appropriate z-score. For example, to find the z-score that has an area of 0.8982 to the left of it, we search for the probability closest to 0.8982 in the bulk of the table and read off the corresponding z-score. In this case we find 0.8980 with the z-score 1.27.
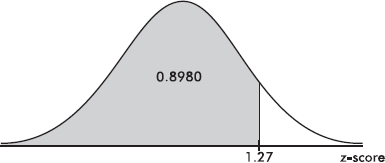
To find the z-score with an area of 0.72 to the right of it, we look for 1– 0.72 = 0.28 in the bulk of the table. The probability 0.2810 corresponds to the z-score –0.58.
USING A CALCULATOR WITH AREAS UNDER A NORMAL CURVE
On the TI-84, normalcdf(lowerbound, upperbound) gives the area (probability) between two z-scores, while invNorm(area) gives the z-score with the given area to its left. So we could have calculated above:
normalcdf(–100, 1.2) = 0.8849
normalcdf(–2.13, 100) = 0.9834
normalcdf(1.23, 2.71) = 0.1060
invNorm(.8982) = 1.271
invNorm(.28) = –0.5828
The TI-84 also has the capability of working directly with raw scores instead of z-scores. In this case, the mean and standard deviation must be given:
normalcdf(lowerbound, upperbound, mean, SD)
invNorm(area, mean, SD)
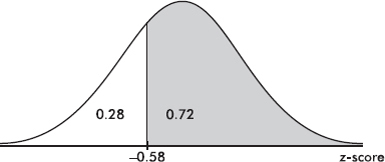
THE NORMAL DISTRIBUTION AS A MODEL FOR MEASUREMENT
In solving a problem using the normal distribution as a model, drawing a picture of a normal curve with horizontal lines showing raw scores and z-scores is usually helpful.
EXAMPLE 11.1
The life expectancy of a particular brand of lightbulb is normally distributed with a mean of 1500 hours and a standard deviation of 75 hours.
TIP
Don’t use the normal model if the distribution isn’t symmetric and unimodal.
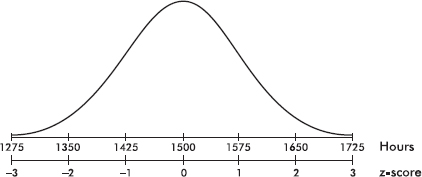
a. What is the probability that a lightbulb will last less than 1410 hours?
TIP
Draw a picture!
Answer: The z-score of 1410 is $\frac{1410-1500}{75}$ = –1.2, and from
Table A the probability to the left of –1.2 is 0.1151. [On the TI-84, normalcdf(0, 1410, 1500, 75) = 0.1151 and normalcdf(–10, –1.2) = 0.1151.]
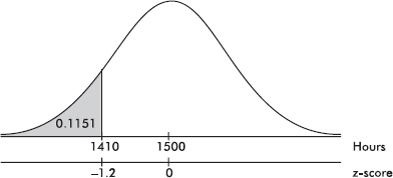
b. What is the probability that a lightbulb will last between 1563 and 1648 hours?
Answer: The z-score of 1563 is $\frac{1563-1500}{75}=0.84$ and the z-score of 1648 is $\frac{1648-1500}{75}=1.97$. In Table A, 0.84 and 1.97 give probabilities of 0.7995 and 0.9756, respectively. Thus between 1563 and 1648 there is a probability of 0.9756 – 0.7995 = 0.1761. [normalcdf(1563, 1648, 1500, 75) = 0.1762 and normalcdf(.84, 1.97) = 0.1760.]
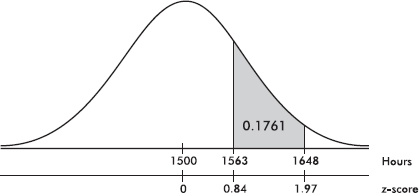
c. What is the probability that a lightbulb will last between 1416 and 1677 hours?
Answer: The z-score of 1416 is $\frac{1416-1500}{75}=-1.2$ and the z-score of 1677 is $\frac{1677-1500}{75}=2.36$. In Table A, –1.12 gives a probability of 0.1314, and 2.36 gives a probability of 0.9909. Thus between 1416 and 1677 there is a probability of 0.9909 – 0.1314 = 0.8595. [normalcdf(1416, 1677, 1500, 75) = 0.8595 and normalcdf(–1.12, 2.36) = 0.8595.]
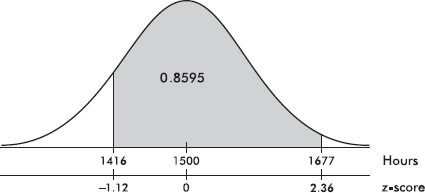
EXAMPLE 11.2
A packing machine is set to fill a cardboard box with a mean of 16.1 ounces of cereal. Suppose the amounts per box form a normal distribution with a standard deviation equal to 0.04 ounce.
a. What percentage of the boxes will end up with at least 1 pound of cereal?
Answer: The z-score of 16 is $\frac{16-16.1}{0.04}=-2.5$ and –2.5 in Table A gives a probability of 0.0062. Thus the probability of having more than 1 pound in a box is 1 – 0.0062 = 0.9938 or 99.38%. [normalcdf(16, 1000, 16.10, .04) = 0.9938 and normalcdf(–2.5, 10) = 0.9938.]
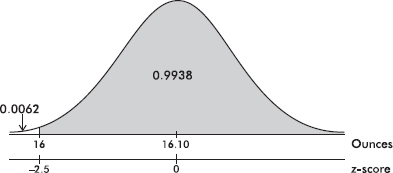
b. Ten percent of the boxes will contain less than what number of ounces?
Answer: In Table A, we note that .1 area (actually 0.1003) is found to the left of a –1.28 z-score. [On the TI-84, invNorm(.1) = –1.2816.] Converting the z-score of –1.28 into a raw score yields $-1.28=\frac{x-16.1}{0.04}$ or $16.1-1.28(0.04)=16.049$ ounces. [Or directly on the TI-84, invNorm(.1, 16.10, .04) = 16.049.]
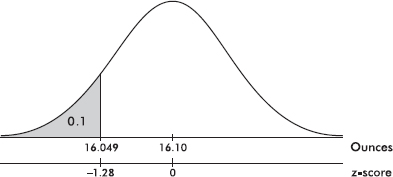
c. Eighty percent of the boxes will contain more than what number of ounces?
Answer: In Table A, we note that 1 – 0.8 = 0.2 area (actually 0.2005) is found to the left of a z-score of –0.84, and so to the right of a –0.84 z-score must be 80% of the area. [Or invNorm(.2) = 0.8416.] Converting the z-score of –0.84 into a raw score yields 16.1 – 0.84(0.04) = 16.066 ounces. [Or directly on the TI-84, invNorm(.2, 16.10, .04) = 16.066.]
d. The middle 90% of the boxes will be between what two weights?
Answer: Ninety percent in the middle leaves five percent in each tail. In Table A, we note that .0505 area is found to the left of a z-score of –1.64, while 0.495 area is found to the left of a z-score of –1.65, and so we use the z-score of –1.645. Then 90% of the area is between z-scores of –1.645 and 1.645. [Or invNorm(.05) = –1.6449 and invNorm(.95) = 1.6449.] Converting z-scores to raw scores yields 16.1 – 1.645(0.04) = 16.034 ounces and 16.1 + 1.645(0.04) = 16.166 ounces, respectively, for the two weights between which we will find the middle 90% of the boxes. [invNorm(.05, 16.10, .04) = 16.034 and invNorm(.95, 16.10, .04) = 16.166.]
COMMONLY USED PROBABILITIES AND Z-SCORES
As can be seen from Example 11.2d, there is often an interest in the limits enclosing some specified middle percentage of the data. For future reference, the limits most frequently asked for are noted below in terms of z-scores.

Ninety percent of the values are between z-scores of –1.645 and +1.645, 95% of the values are between z-scores of –1.96 and +1.96, and 99% of the values are between z-scores of –2.576 and +2.576.
Sometimes the interest is in values with particular percentile rankings. For example,

Ninety percent of the values are below a z-score of 1.282, 95% of the values are below a z-score of 1.645, and 99% of the values are below a z-score of 2.326.
There are corresponding conclusions for negative z-scores:

Ninety percent of the values are above a z-score of –1.282, 95% of the values are above a z-score of –1.645, and 99% of the values are above a z-score of –2.326.
It is also useful to note the percentages corresponding to values falling between integer z-scores. For example,

Note that 68.26% of the values are between z-scores of –1 and +1, 95.44% of the values are between z-scores of –2 and +2, and 99.74% of the values are between z-scores of –3 and +3.
EXAMPLE 11.3
Suppose that the average height of adult males in a particular locality is 70 inches with a standard deviation of 2.5 inches.
a. If the distribution is normal, the middle 95% of males are between what two heights?
Answer: As noted above, the critical z-scores in this case are ±1.96, and so the two limiting heights are 1.96 standard deviations from the mean. Therefore, 70 ± 1.96(2.5) = 70 ± 4.9, or from 65.1 to 74.9 inches.
b. Ninety percent of the heights are below what value?
Answer: The critical z-score is 1.282, and so the value in question is 70 + 1.282(2.5) = 73.205 inches.
c. Ninety-nine percent of the heights are above what value?
Answer: The critical z-score is –2.326, and so the value in question is 70 – 2.326(2.5) = 64.185 inches.
d. What percentage of the heights are between z-scores of ±1? Of ±2? Of ±3?
Answer: 68.26%, 95.44%, and 99.74%, respectively.
FINDING MEANS AND STANDARD DEVIATIONS
If we know that a distribution is normal, we can calculate the mean µ and the standard deviation σ using percentage information from the population.
EXAMPLE 11.4
Given a normal distribution with a mean of 25, what is the standard deviation if 18% of the values are above 29?
Answer: Looking for a 0.82 probability in Table A, we note that the corresponding z-score is 0.92. Thus 29 – 25 = 4 is equal to a standard deviation of 0.92, that is, 0.92σ = 4, and σ=4/0.92=4.35
EXAMPLE 11.5
Given a normal distribution with a standard deviation of 10, what is the mean if 21% of the values are below 50?
Answer: Looking for a 0.21 probability in Table A leads us to a z-score of –0.81. Thus 50 is –0.81 standard deviation from the mean, and so µ = 50 + 0.81(10) = 58.1.
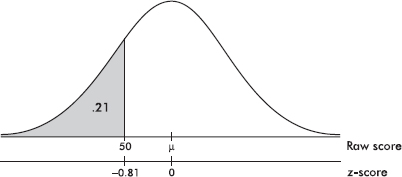
EXAMPLE 11.6
Given a normal distribution with 80% of the values above 125 and 90% of the values above 110, what are the mean and standard deviation?
Answer: Table A gives critical z-scores of –0.84 and –1.28. Thus we have $\frac{125-\mu}{\sigma}=-0.84$ and $\frac{110-\mu}{\sigma}=-1.28$ Solving the system {125 – µ = –0.84σ, 110 – µ = –1.28σ} simultaneously gives µ = 153.64 and σ = 34.09.
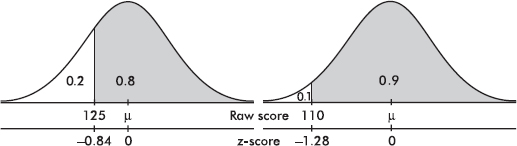
NORMAL APPROXIMATION TO THE BINOMIAL
Many practical applications of the binomial involve examples in which n is large. However, for large n, binomial probabilities can be quite tedious to calculate. Since the normal can be viewed as a limiting case of the binomial, it is natural to use the normal to approximate the binomial in appropriate situations.
TIP
When n is small, you cannot use the normal model to approximate the binomial model.
The binomial takes values only at integers, while the normal is continuous with probabilities corresponding to areas over intervals. Therefore, we establish a technique for converting from one distribution to the other. For approximation purposes we do as follows. Each binomial probability corresponds to the normal probability over a unit interval centered at the desired value. Thus, for example, to approximate the binomial probability of eight successes we determine the normal probability of being between 7.5 and 8.5.
EXAMPLE 11.7
Suppose that 15% of the cars coming out of an assembly plant have some defect. In a delivery of 40 cars what is the probability that exactly 5 cars have defects?
Answer: The actual answer is $\frac{40!}{35!5!}(0.15)^5 (0.85)^{35}$ but clearly this involves a nontrivial calculation. [If one has a calculator such as the TI-84, then binompdf(40, 0.15, 5) = 0.1692.] To approximate the answer using the normal, we first calculate the mean µ and the standard deviation σ as follows:
![]()
We then calculate the appropriate z-scores: $\frac{4.5-6}{2.258}=-0.66$ and $\frac{5.5-6}{2.258}=-0.22$.
Looking up the corresponding probabilities in Table A, we obtain a final answer of 0.4129 – 0.2546 = 0.1583. (The actual answer is 0.1692.)
Even more useful are approximations relating to probabilities over intervals.
EXAMPLE 11.8
If 60% of the population support massive federal budget cuts, what is the probability that in a survey of 250 people at most 155 people support such cuts?
Answer: The actual answer is the sum of 156 binomial expressions:
![]()
However, a good approximation can be obtained quickly and easily by using the normal. We calculate µ and σ:
![]()
The binomial of at most 155 successes corresponds to the normal probability of ≤155.5.
The z-score of 155.5 is $\frac{155.5-150}{7.746}=0.71$. Using Table A leads us to a final answer of 0.7611. [Or binomcdf(250, .6, 155) = 0.7605.]
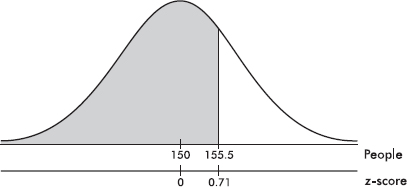
Is the normal a good approximation? The answer, of course, depends on the error tolerances in particular situations. A general rule of thumb is that the normal is a good approximation to the binomial whenever both np and n(1 – p) are greater than 10. (Some authors use 5 instead of 10 here.)
In the examples in this Topic we have assumed the population has a normal distribution. When you collect your own data, before you can apply the procedures developed above, you must decide whether it is reasonable to assume the data come from a normal population. In later Topics we will have to check for normality before applying certain inference procedures.
The initial check should be to draw a picture. Dotplots, stemplots, boxplots, and histograms are all useful graphical displays to show that data is unimodal and roughly symmetric.
EXAMPLE 11.9
The ages at inauguration of U.S. presidents from Washington to G. W. Bush were: {57, 61, 57, 57, 58, 57, 61, 54, 68, 51, 49, 64, 50, 48, 65, 52, 56, 46, 54, 49, 51, 47, 55, 55, 54, 42, 51, 56, 55, 51, 54, 51, 60, 61, 43, 55, 56, 61, 52, 69, 64, 46, 54}. Can we conclude that the distribution is roughly normal?
Answer: Entering the 43 data points in a graphing calculator gives the following histogram:
Alternatively, we could have used a dotplot, stemplot, or boxplot:

All the graphical displays indicate a distribution that is roughly unimodal and symmetric.
A more specialized graphical display to check normality is the normal probability plot. When the data distribution is roughly normal, the plot is roughly a diagonal straight line. While this plot more clearly shows deviations from normality, it is not as easy to understand as a histogram. The normal probability plot is difficult to calculate by hand; however, technology such as the TI-84 readily plots the graph. (On the TI-84, in STATPLOT the sixth choice in TYPE gives the normal probability plot.)
The normal probability plot for the data in Example 11.9 is:
A graph this close to a diagonal straight line indicates that the data have a distribution very close to normal.
Note that alternatively, one could have plotted the data (in this case, inaugural ages) on the x-axis and the normal scores on the y-axis.
SUMMARY
The normal distribution is one particular symmetric, unimodal distribution.
Drawing pictures of normal curves with horizontal lines showing raw scores and z-scores is usually helpful.
Areas (probabilities) under a normal curve can be found using the given table or calculator functions, such as normalcdf on TI calculators.
Critical values corresponding to given probabilities can be found using the given table or calculator functions, such as invNorm on TI calculators.
The normal probability plot is very useful in gauging whether a given distribution of data is approximately normal: If the plot is nearly straight, the data is nearly normal.
Multiple-Choice Questions
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. Which of the following is a true statement?
(A) The area under a normal curve is always equal to 1, no matter what the mean and standard deviation are.
(B) All bell-shaped curves are normal distributions for some choice of µ and σ.
(C) The smaller the standard deviation of a normal curve, the lower and more spread out the graph.
(D) Depending upon the value of the standard deviation, normal curves with different means may be centered around the same number.
(E) Depending upon the value of the standard deviation, the mean and median of a particular normal distribution may be different.
2. Which of the following is a true statement?
(A) The area under the standard normal curve between 0 and 2 is twice the area between 0 and 1.
(B) The area under the standard normal curve between 0 and 2 is half the area between –2 and 2.
(C) For the standard normal curve, the interquartile range is approximately 3.
(D) For the standard normal curve, the range is 6.
(E) For the standard normal curve, the area to the left of 0.1 is the same as the area to the right of 0.9.
3. Populations P1 and P2 are normally distributed and have identical means. However, the standard deviation of P1 is twice the standard deviation of P2. What can be said about the percentage of observations falling within two standard deviations of the mean for each population?
(A) The percentage for P1 is twice the percentage for P2.
(B) The percentage for P1 is greater, but not twice as great, as the percentage for P2.
(C) The percentage for P2 is twice the percentage for P1.
(D) The percentage for P2 is greater, but not twice as great, as the percentage for P1.
(E) The percentages are identical.
4. Consider the following two normal curves:
Which has the larger mean and which has the larger standard deviation?
(A) Larger mean, a; larger standard deviation, a
(B) Larger mean, a; larger standard deviation, b
(C) Larger mean, b; larger standard deviation, a
(D) Larger mean, b; larger standard deviation, b
(E) Larger mean, b; same standard deviation
In Questions 5–15, assume the given distributions are normal.
5. A trucking firm determines that its fleet of trucks averages a mean of 12.4 miles per gallon with a standard deviation of 1.2 miles per gallon on cross-country hauls. What is the probability that one of the trucks averages fewer than 10 miles per gallon?
(A) 0.0082
(B) 0.0228
(C) 0.4772
(D) 0.5228
(E) 0.9772
6. A factory dumps an average of 2.43 tons of pollutants into a river every week. If the standard deviation is 0.88 tons, what is the probability that in a week more than 3 tons are dumped?
(A) 0.2578
(B) 0.2843
(C) 0.6500
(D) 0.7157
(E) 0.7422
7. An electronic product takes an average of 3.4 hours to move through an assembly line. If the standard deviation is 0.5 hour, what is the probability that an item will take between 3 and 4 hours?
(A) 0.2119
(B) 0.2295
(C) 0.3270
(D) 0.3811
(E) 0.6730
8. The mean score on a college placement exam is 500 with a standard deviation of 100. Ninety-five percent of the test takers score above what?
(A) 260
(B) 336
(C) 405
(D) 414
(E) 664
9. The average noise level in a restaurant is 30 decibels with a standard deviation of 4 decibels. Ninety-nine percent of the time it is below what value?
(A) 20.7
(B) 32.0
(C) 33.4
(D) 37.8
(E) 39.3
10. The mean income per household in a certain state is \$9500 with a standard deviation of \$1750. The middle 95% of incomes are between what two values?
(A) \$5422 and\$13,578
(B) \$6070 and \$12,930
(C) \$6621 and \$12,379
(D) \$7260 and \$11,740
(E) \$8049 and \$10,951
11. One company produces movie trailers with mean 150 seconds and standard deviation 40 seconds, while a second company produces trailers with mean 120 seconds and standard deviation 30 seconds. What is the probability that two randomly selected trailers, one produced by each company, will combine to less than three minutes?
(A) 0.000
(B) 0.036
(C) 0.099
(D) 0.180
(E) 0.405
12. Jay Olshansky from the University of Chicago was quoted in Chance News as arguing that for the average life expectancy to reach 100, 18% of people would have to live to 120. What standard deviation is he assuming for this statement to make sense?
(A) 21.7
(B) 24.4
(C) 25.2
(D) 35.0
(E) 111.1
13. Cucumbers grown on a certain farm have weights with a standard deviation of 2 ounces. What is the mean weight if 85% of the cucumbers weigh less than 16 ounces?
(A) 13.92
(B) 14.30
(C) 14.40
(D) 14.88
(E) 15.70
14. If 75% of all families spend more than \$75 weekly for food, while 15% spend more than \$150, what is the mean weekly expenditure and what is the standard deviation?
(A) µ = 83.33, σ = 12.44
(B) µ = 56.26, σ = 11.85
(C) µ = 118.52, σ = 56.26
(D) µ = 104.39, σ = 43.86
(E) µ = 139.45, σ = 83.33
15. A coffee machine can be adjusted to deliver any fixed number of ounces of coffee. If the machine has a standard deviation in delivery equal to 0.4 ounce, what should be the mean setting so that an 8-ounce cup will overflow only 0.5% of the time?
(A) 6.97 ounces
(B) 7.22 ounces
(C) 7.34 ounces
(D) 7.80 ounces
(E) 9.03 ounces
16. Assume that a baseball team has an average pitcher, that is, one whose probability of winning any decision is 0.5. If this pitcher has 30 decisions in a season, what is the probability that he will win at least 20 games?
(A) 0.0505
(B) 0.2514
(C) 0.2743
(D) 0.3333
(E) 0.4300
17. Given that 10% of the nails made using a certain manufacturing process have a length less than 2.48 inches, while 5% have a length greater than 2.54 inches, what are the mean and standard deviation of the lengths of the nails? Assume that the lengths have a normal distribution.
(A) µ = 2.506, σ = 0.0205
(B) µ = 2.506, σ = 0.0410
(C) µ = 2.516, σ = 0.0825
(D) µ = 2.516, σ = 0.1653
(E) The mean and standard deviation cannot be computed from the information given.
Free-Response Questions
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your final answers.
TWO OPEN-ENDED QUESTIONS
1. The time it takes Steve to walk to school follows a normal distribution with mean 30 minutes and standard deviation 5 minutes, while the time it takes Jan to walk to school follows a normal distribution with mean 25 minutes and standard deviation 4 minutes. Assume their walking times are independent of each other.
(a) If they leave at the same time, what is the probability that Steve arrives before Jan?
(b) How much earlier than Jan should Steve leave so that he has a 90% chance of arriving before Jan?
2. (a) Two components are in series so the failure of either will cause the system to fail. The time to failure for a new component is normally distributed with a mean of 3000 hours and a standard deviation of 400 hours. One of the components has already run for 2500 hours, while the other has run for 2800 hours. Assuming component failures are independent, what is the probability the system survives for 10 more days (240 hours)?
(b) If the components are put in parallel, the system will fail only if both components fail. If the two components in (a) are put in parallel, what is the probability that the system survives for 10 more days?
TWO INVESTIGATIVE TASKS
1. When Michael Jordan came up to try for a sixth free throw after having made five straight free throws, the announcer commented that the law of averages would be working against Jordan.
(a) What did the announcer mean? Was this a correct interpretation of probability? Explain.
(b) Jordan makes 90% of his free throws. What is the probability that he will make six straight free throws? That he will make five straight free throws and then miss the next? That he will make the next free throw given that he has made the last five in a row?
(c) How could you set up a simulation using a random number table to analyze the situation the announcer was commenting on?
(d) If Jordan shoots six times from the free throw line, what are the mean and standard deviation for the number of shots he is expected to make?
(e) If Jordan makes only 35 out of 40 free throw tries during the playoffs, is this sufficient evidence that the probability of his making a free throw is really below .90? Explain.
2. Many people have lactose intolerance leading to cramps and diarrhea when they eat dairy products. Substantial relief can be obtained by taking dietary supplements of lactase, an enzyme. One product consists of caplets containing a mean of 9000 FCC lactase units with a standard deviation of 590 units and a normal distribution of lactase units. People with severe lactose intolerance may need to take two such tablets whenever they eat dairy products. Tablets with under 8500 FCC lactase units can produce noticeably less relief.
(a) Determine the probability that a caplet has less than 8500 FCC lactase units. Round off to the nearest tenth.
(b) Using the random number table below, run five simulations for the number of tablets a lab technician samples before finding two with less than 8500 units each.
84177 06757 17613 15582 51506 81435 41050 92031 06449 05059
59884 31180 53115 84469 94868 57967 05811 84514 75011 13006
63395 55041 15866 06589 13119 71020 85940 91932 06488 74987
54355 52704 90359 02649 47496 71567 94268 08844 26294 64759
08989 57024 97284 00637 89283 03514 59195 07635 03309 72605
29357 23737 67881 03668 33876 35841 52869 23114 15864 38942
(c) The results of two 100-trial simulations, one looking for two tablets each less than 8500 units and one looking for two tablets each greater than 9000 units, are shown below. Which distribution is which? Explain your answer.
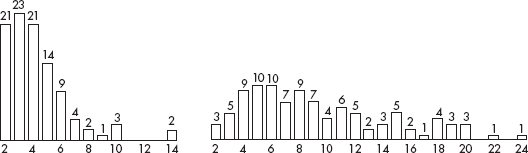
(d) Using the correct barplot above, estimate the expected number of caplets a laboratory will sample before finding two with less than 8500 units each.
MULTIPLE-CHOICE
1. (A) The area under any probability distribution is equal to 1. Many bell-shaped curves are not normal curves. The smaller the standard deviation of a normal curve, the higher and narrower the graph. The mean determines the value around which the curve is centered; different means give different centers. Because of symmetry, the mean and median are identical for normal distributions.
2. (B) Statement (B) is true by symmetry of the normal curve, however 0.4772 is not twice 0.3413, 0.67 – (–0.67) is not 3, the range is not finite, and the P(z < 0.1) is more than 0.5 while P(z > 0.9) is less than 0.5.
3. (E) All normal distributions have about 95% of their observations within two standard deviations of the mean.
4. (C) Curve a has mean 6 and standard deviation 2, while curve b has mean 18 and standard deviation 1.
5. (B) The z-score of 10 is  From Table A, to the left of –2 is an area of
From Table A, to the left of –2 is an area of
0.0228. [normalcdf(0, 10, 12.4, 1.2) = 0.0228.]
6. (A) The z-score of 3 is  From Table A, to the left of 0.65 is an area of 0.7422, and so to the right must be 1 – 0.7422 = 0.2578. [normalcdf(3, 1000, 2.43, .88) = 0.2589.]
From Table A, to the left of 0.65 is an area of 0.7422, and so to the right must be 1 – 0.7422 = 0.2578. [normalcdf(3, 1000, 2.43, .88) = 0.2589.]
7. (E) The z-scores of 3 and 4 are  respectively. From Table A, to the left of –0.8 is an area of 0.2119, and to the left of 1.2 is an area of 0.8849. Thus between 3 and 4 is an area of 0.8849 – 0.2119 = 0.6730. [normalcdf(3, 4, 3.4, .5) = 0.6731.]
respectively. From Table A, to the left of –0.8 is an area of 0.2119, and to the left of 1.2 is an area of 0.8849. Thus between 3 and 4 is an area of 0.8849 – 0.2119 = 0.6730. [normalcdf(3, 4, 3.4, .5) = 0.6731.]
8. (B) If 95% of the area is to the right of a score, 5% is to the left. Looking for 0.05 in the body of Table A, we note the z-score of –1.645. Converting this to a raw score gives 500 – 1.645(100) = 336. [invNorm(.05, 500, 100) = 336.]
9. (E) The critical z-score associated with 99% to the left is 2.326, and 30 + 2.326(4) = 39.3. [invNorm(.99, 30, 4) = 39.3.]
10. (B) The critical z-scores associated with the middle 95% are ±1.96, and 9500 ± 1.96(1750) = 6070 and 12,930. [invNorm(.025, 9500, 1750) = 6070 and invNorm(.975, 9500, 1750) = 12,930.]
11. (B) 
12. (A) The critical z-score associated with 18% to the right or 82% to the left is 0.92. Then 100 + 0.92 = 120 gives = 21.7.
= 120 gives = 21.7.
13. (A) The critical z-score associated with 85% to the left is 1.04. Then µ + 1.04(2) = 16 gives µ = 13.92.
14. (D) The critical z-scores associated with 75% to the right (25% to the left) and with 15% to the right (85% to the left) are –0.67 and 1.04, respectively. Then {µ – 0.67 = 75, µ + 1.04 = 150} gives µ = 104.39 and = 43.86.
15. (A) The critical z-score associated with 0.5% to the right (99.5% to the left) is 2.576. Then c + 2.576(0.4) = 8 gives c = 6.97.
16. (A) Using the normal as an approximation to the binomial, we have µ = 30(0.5) = 15, 2 = 30(0.5)(0.5) = 7.5, = 2.739,  = 1.64, and 1 – 0.9495 = 0.0505. [Or binomcdf(30, .5, 10) = 0.0494.]
= 1.64, and 1 – 0.9495 = 0.0505. [Or binomcdf(30, .5, 10) = 0.0494.]
17. (A) The critical z-scores for 10% to the left and 5% to the right are –1.282 and 1.645, respectively. Then {µ – 1.282 = 2.48, µ + 1.645 = 2.54} gives µ = 2.506 and = 0.0205.
FREE-RESPONSE
1. (a) Let the random variable D be the difference in walking times (Steve–Jan). Then µD = 30 – 25 = 5 and  For Steve to arrive before Jan, the difference in walking times must be < 0.
For Steve to arrive before Jan, the difference in walking times must be < 0.

(b) If m is the number of minutes he should leave early, then the new mean of the differences is 5 – m, and we want  and m = 13.2 minutes.
and m = 13.2 minutes.
2. (a) 
Given independence, the probability that both components last 240 more hours is (0.829825)(0.665506) = 0.552.
(b) The probability that both fail is (1 – 0.829825)(1 – 0.665506) = 0.056923.
The probability that at least one doesn’t fail is 1 – 0.056923 ≈ 0.943.
INVESTIGATIVE TASKS
1. (a) The announcer meant that to maintain his tabulated free throw percentage, Jordan would have to soon miss one. This is not a correct use of probability. If Jordan makes a certain percentage of free throws, that probability applies to each throw irrespective of the previous throws. By the law of large numbers, in the long run the relative frequency tends toward the correct probability, but no conclusion is possible about any given outcome.
(b) P(six in a row) = (0.9)6 = 0.531
P(five, then a miss) = (0.9)5(0.1) = 0.059
P(next|previous five) = P(next) = 0.9
(c) Let the digits 1 through 9 stand for making a free throw, while 0 stands for a miss. Look at blocks of five random numbers. If all stand for “makes” (no 0), look at the very next digit to see if it is a 0 or not. Keep a tally of how many times five makes in a row are followed by a make and how many times five makes in a row are followed by a miss.
(d) This is a binomial distribution with n = 6 and p = 0.9, and so the mean is np = 6(9) = 5.4 while the standard deviation is 
(e) Since nq = 40(1 – 0.90) = 4, the normal approximation to the binomial is not recommended. However, a direct binomial calculation yields

[Or simply use binomcdf(40, .9, 35) on the TI-84.] With such a high probability, there is no evidence to conclude that Jordan’s average has dropped!
2. (a) With  Table A gives a probability of 0.1977 ≈ 0.2.
Table A gives a probability of 0.1977 ≈ 0.2.
(b) For example, letting 0 and 1 represent caplets containing less than 8500 units and 2 through 9 represent caplets containing more than 8500 units, we can read off digits until we find two containing less than 8500 caplets. Five simulations would yield
841770 67571761 31558251 50681 435410
giving 6, 8, 8, 5, and 6 tablets sampled before finding two with less than 8500 units apiece.
(c) The probability of a caplet having more than 9000 units is 0.5, and thus one would expect to find two caplets with more than 9000 units much quicker than finding two caplets with less than 8500 units. Thus the first histogram results from looking for two caplets with more than 9000 units and the second histogram results from looking for two caplets with less than 8500 units.
(d) An estimate for the expected value is obtained by
xP (x) = 2(0.03) + 3(0.05) + 4(0.09) + 5(0.10) + … + 24(0.01) = 9.44
SAMPLE PROPORTION
SAMPLE MEAN
CENTRAL LIMIT THEOREM
DIFFERENCE BETWEEN TWO INDEPENDENT SAMPLE PROPORTIONS
DIFFERENCE BETWEEN TWO INDEPENDENT SAMPLE MEANS
THE t-DISTRIBUTION
THE CHI-SQUARE DISTRIBUTION
THE STANDARD ERROR
BIAS AND ACCURACY
The population is the complete set of items of interest. A sample is a part of a population used to represent the population. The population mean µ and population standard deviation σ are examples of population parameters. The sample mean $\overline{x}$ and the sample standard deviation s are examples of statistics. Statistics are used to make inferences about population parameters. While a population parameter is a fixed quantity, statistics vary depending on the particular sample chosen. The probability distribution showing how a statistic varies is called a sampling distribution. The sampling distribution is unbiased if its mean is equal to the associated population parameter.
IMPORTANT
A sampling distribution is not the same thing as the distribution of a sample.
We want to know some important truth about a population, but in practical terms this truth is unknowable. What’s the average adult human body weight? What proportion of people have high cholesterol? What we can do is carefully collect data from as large and representative a group of individuals as possible and then use this information to estimate the value of the population parameter. How close are we to the truth? We know that different samples would give different estimates, and so sampling error is unavoidable. What is wonderful, and what we will learn in this Topic, is that we can quantify this sampling error! We can make statements like “the average weight must almost surely be within 5 pounds of 176 pounds” or “the proportion of people with high cholesterol must almost surely be within ±3% of 37%.”
SAMPLING DISTRIBUTION OF A SAMPLE PROPORTION
Whereas the mean is basically a quantitative measurement, the proportion represents essentially a qualitative approach. The interest is simply in the presence or absence of some attribute. We count the number of yes responses and form a proportion. For example, what proportion of drivers wear seat belts? What proportion of SCUD missiles can be intercepted? What proportion of new stereo sets have a certain defect?
This separation of the population into “haves” and “have-nots” suggests that we can make use of our earlier work on binomial distributions. We also keep in mind that, when n (trials, or in this case sample size) is large enough, the binomial can be approximated by the normal.
In this topic we are interested in estimating a population proportion p by considering a single sample proportion $\widehat{p}$. This sample proportion is just one of a whole universe of sample proportions, and to judge its significance we must know how sample proportions vary. Consider the set of proportions from all possible samples of a specified size n. It seems reasonable that these proportions will cluster around the population proportion (the sample proportion is an unbiased statistic of the population proportion) and that the larger the chosen sample size, the tighter the clustering.
How do we calculate the mean and standard deviation of the set of population proportions? Suppose the sample size is n and the actual population proportion is p. From our work on binomial distributions, we remember that the mean and standard deviation for the number of successes in a given sample are pn and $\sqrt{np(1-p)}$ respectively, and for large n the complete distribution begins to look “normal.”
Here, however, we are interested in the proportion rather than in the number of successes. From Topic Two we remember that when we multiply or divide every element by a constant, we multiply or divide both the mean and the standard deviation by the same constant. In this case, to change number of successes to proportion of successes, we divide by n:
![]()
Furthermore, if each element in an approximately normal distribution is divided by the same constant, it is reasonable that the result will still be an approximately normal distribution.
Thus the principle forming the basis of the following discussion is
Start with a population with a given proportion p. Take all samples of size n. Compute the proportion in each of these samples. Then
1. the set of all sample proportions is approximately normally distributed (often stated: the distribution of sample proportions is approximately normal).
2. the mean $\mu\widehat{p}$ of the set of sample proportions equals p, the population proportion.
3. the standard deviation $\sigma\widehat{p}$ of the set of sample proportions is approximately equal to $\sqrt{\frac{p(1-p)}{n}}$.
Alternatively, we say that the sampling distribution of $\widehat{p}$ is approximately normal with mean p and standard deviation $\sqrt{\frac{p(1-p)}{n}}$.
Since we are using the normal approximation to the binomial, both np and n(1 – p) should be at least 10. Furthermore, in making calculations and drawing conclusions from a specific sample, it is important that the sample be a simple random sample.
Finally, because sampling is usually done without replacement, the sample cannot be too large; the sample size n should be no larger than 10% of the population. (We’re actually worried about independence, but randomly selecting a relatively small sample allows us to assume independence. Of course, it’s always better to have larger samples—it’s just that if the sample is large relative to the population, then the proper inference techniques are different from those taught in introductory statistics classes.)
TIP
It is sufficient to write: Normal with $\mu_{\widehat{p}}$ = 0.80 and $\sigma_{\widehat{p}}$ = 0.0381; P($\widehat{p}$ < 0.75) = 0.0947.
EXAMPLE 12.1
It is estimated that 80% of people with high math anxiety experience brain activity similar to that experienced under physical pain when anticipating doing a math problem. In a simple random sample of 110 people with high math anxiety, what is the probability that less than 75% experience the physical pain brain activity?
Answer: The sample is given to be random, both np = (110)(0.80) = 88 $\geq$ 10 and n(1 – p) = (110)(0.20) = 22 $\geq$ 10, and our sample is clearly less than 10% of all people with math anxiety. So the sampling distribution of $\widehat{p}$ is approximately normal with mean 0.80 and standard deviation $\sigma_\widehat{p}=\sqrt{\frac{(0.8)(0.2)}{110}}=0.0381$. With a z-score of $\frac{0.75-0.8}{0.0381}=-1.312$ the probability that the sample proportion is less than 0.75 is normalcdf(–1000,–1.312) = 0.0948.
[Or normalcdf(–1000, .75, .80, .0381) = 0.0947.]
SAMPLING DISTRIBUTION OF A SAMPLE MEAN
Suppose we are interested in estimating the mean µ of a population. For our estimate we could simply randomly pick a single element of the population, but then we would have little confidence in our answer. Suppose instead that we pick 100 elements and calculate their average. It is intuitively clear that the resulting sample mean has a greater chance of being closer to the mean of the whole population than the value for any individual member of the population does.
When we pick a sample and measure its mean $\overline{x}$, we are finding exactly one sample mean out of a whole universe of sample means. To judge the significance of a single sample mean, we must know how sample means vary. Consider the set of means from all possible samples of a specified size. It is both apparent and reasonable that the sample means are clustered around the mean of the whole population; furthermore, these sample means have a tighter clustering than the elements of the original population. In fact, we might guess that the larger the chosen sample size, the tighter the clustering.
How do we calculate the standard deviation $\sigma_\overline{x}$ of the set of sample means? Suppose the variance of the population is $\sigma$2 and we are interested in samples of size n. Sample means are obtained by first summing together n elements and then dividing by n. A set of sums has a variance equal to the sum of the variances associated with the original sets. In our case, $\sigma^2_{sums}=\sigma^2+…+\sigma^2=n\sigma^2$ . When each element of a set is divided by some constant, the new variance is the old one divided by the square of the constant. Since the sample means are obtained by dividing the sums by n, the variance of the sample means is obtained by dividing the variance of the sums by n2. Thus if $\sigma_\overline{x}$ symbolizes the standard deviation of the sample means, we find that
![]()
In terms of standard deviations, we have $\sigma_\overline{x}=\frac{\sigma}{\sqrt{n}}$
We have shown the following:
Start with a population with a given mean μ and standard deviation σ. Compute the mean of all samples of size n. Then the mean of the set of sample means will equal μ, the mean of the population, and the standard deviation $\sigma_\overline{x}$ of the set of sample means will equal $\frac{\sigma}{\sqrt{n}}$ that is, the standard deviation of the whole population divided by the square root of the sample size.
Note that the variance of the set of sample means varies directly as the variance of the original population and inversely as the size of the samples, while the standard deviation of the set of sample means varies directly as the standard deviation of the original population and inversely as the square root of the size of the samples.
EXAMPLE 12.2
Emergency room visits after drinking energy drinks is skyrocketing. One particular energy drink has an average of 200 mg of caffeine with a standard deviation of 10 mg. A store sells boxes of six bottles each. What is the mean and standard deviation of the average milligrams of caffeine consumers should expect from the six bottles in each box?
Answer: We have samples of size 6. The mean of these sample means will equal the population mean of 200 mg. The standard deviation of these sample means will
equal $\sigma_\overline{x}=\frac{10}{\sqrt{6}}=4.08mg$
Note that while giving the mean and standard deviation of the set of sample means, we did not describe the shape of the distribution. If we are also given that the original population is normal, then we can conclude that the set of sample means has a normal distribution.
EXAMPLE 12.3
It is estimated that cats, who live in the wild or as indoor pets allowed to roam outdoors, kill an average of 10 birds a year. Assuming a normal distribution with a standard deviation of 3 birds, what is the probability an SRS of 25 cats will kill an average of between 9 and 12 birds in a year?
Answer: The sampling distribution of the sample means is approximately normal (because the original population is normal) with mean µx = 10 and standard deviation $\sigma_\overline{x}=\frac{3}{\sqrt{25}}=0.6$. The z-scores of 9 and 12 are (9-10)/0.6=-1.667 and (12-10)/0.6=3.333 and the probability of a sample mean between 9 and 12 is normalcdf(-1.667,3.333) = 0.952. [Or normalcdf(9,12,10,0.6) = 0.952.]
We assumed above that the original population had a normal distribution. Unfortunately, few populations are normal, let alone exactly normal. However, it can be shown mathematically that no matter how the original population is distributed, if n is large enough, then the set of sample means is approximately normally distributed. For example, there is no reason to suppose that the amounts of money that different people spend in grocery stores are normally distributed. However, if each day we survey 30 people leaving a store and determine the average grocery bill, these daily averages will have a nearly normal distribution.
The following principle forms the basis of much of what we discuss in this topic and in those following. It is a simplified statement of the central limit theorem of statistics.
Start with a population with a given mean μ, a standard deviation σ, and any shape distribution whatsoever. Pick n sufficiently large (at least 30) and take all samples of size n. Compute the mean of each of these samples. Then
1. the set of all sample means is approximately normally distributed (often stated: the distribution of sample means is approximately normal).
2. the mean of the set of sample means equals μ, the mean of the population.
3. the standard deviation $\sigma_\overline{x}$ of the set of sample means is equal to $\frac{\sigma}{\sqrt{n}}$ that is, equal to the standard deviation of the whole population divided by the square root of the sample size.
Alternatively, we say that the sampling distribution of $\overline{x}$ is approximately normal with mean μ and standard deviation $\frac{\sigma}{\sqrt{n}}$.
While we mention n $\geq$ 30 as a rough rule of thumb, n $\geq$ 40 is often used, and n should be chosen even larger if more accuracy is required or if the original population is far from normal. As with proportions, we have the assumptions of a simple random sample and of sample size n no larger than 10% of the population.
EXAMPLE 12.4
The naked mole rat, a hairless East African rodent that lives underground, has a life expectancy of 21 years with a standard deviation of 3 years. In a random sample of 40 such rats, what is the probability that the mean life expectancy is between 20 and 22 years?
Answer: We have a random sample that is less than 10% of the naked mole rat population. With a sample size of 40, the central limit theorem applies, and the sampling distribution of $\overline{x}$ is approximately normal with mean µx = 21 and standard deviation $\sigma_\overline{x}=\frac{3}{\sqrt{40}}=0.474$. The z-scores of 20 and 22 are (20-21)/0.474=-2.11 and (22-21)/0.474=2.11, the probability of sample mean between 20 and 22 is normalcdf(–2.110,2.110) = 0.965. [Or normalcdf(20,22,21,0.474)= 0.965.]
EXAMPLE 12.5
Being bilingual appears to slow the onset of dementia by an average of 4.5 years with a standard deviation of 2 years. In a random sample of 75 bilingual people with dementia, the probability is 0.90 that the average delay in the onset of their dementia was at least how many years?
Answer: We have a random sample that is less than 10% of the total bilingual dementia population. With a sample size of 75, the central limit theorem applies, and the sampling distribution of $\overline{x}$ is approximately normal with mean $\mu_\overline{x}$ = 4.5 and standard deviation $\sigma_\overline{x}=\frac{2}{\sqrt{75}}=0.231$ The critical z-score is invNorm(0.10)= –1.282 with a corresponding raw score of 4.5 – 1.282(0.231) = 4.20 years. [Or invNorm(.10,4.5,.231)= 4.20.]
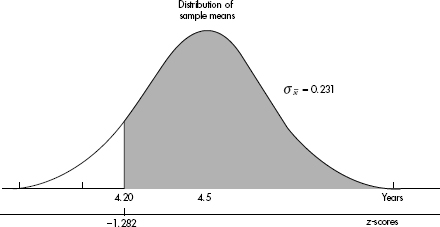
Don’t be confused by the several different distributions being discussed! First, there’s the distribution of the original population, which may be uniform, bell-shaped, strongly skewed—anything at all. Second, there’s the distribution of the data in the sample, and the larger the sample size, the more this will look like the population distribution. Third, there’s the distribution of the means of many samples of a given size, and the amazing fact is that this sampling distribution can be described by a normal model, regardless of the shape of the original population.
SAMPLING DISTRIBUTION OF A DIFFERENCE BETWEEN TWO INDEPENDENT SAMPLE PROPORTIONS
Numerous important and interesting applications of statistics involve the comparison of two population proportions. For example, is the proportion of satisfied purchasers of American automobiles greater than that of buyers of Japanese cars? How does the percentage of surgeons recommending a new cancer treatment compare with the corresponding percentage of oncologists? What can be said about the difference between the proportion of single parents on welfare and the proportion of two-parent families on welfare?
Our procedure involves comparing two sample proportions. When is a difference between two such sample proportions significant? Note that we are dealing with one difference from the set of all possible differences obtained by subtracting sample proportions of one population from sample proportions of a second population. To judge the significance of one particular difference, we must first determine how the differences vary among themselves. Remember that the variance of a set of differences is equal to the sum of the variances of the individual sets; that is,
$\sigma_d^2=\sigma_1^2+\sigma_2^2$
Now if
![]()
then
![]()
Then we have the following about the sampling distribution of $\widehat{p_1}-\widehat{p_2}$:
Start with two populations with given proportions p1 and p2. Take all samples of sizes n1 and n2, respectively. Compute the difference $\widehat{p_1}-\widehat{p_2}$ of the two proportions in each pair of samples. Then
1. the set of all differences of sample proportions is approximately normally distributed (alternatively stated: the distribution of differences of sample proportions is approximately normal).
2. the mean of the set of differences of sample proportions equals p1 – p2, the difference of population proportions.
3. the standard deviation $\sigma$d of the set of differences of sample proportions is approximately equal to
![]()
Since we are using the normal approximation to the binomial, n1p1, n1(1 – p1), n2p2, and n2(1 – p2) should all be at least 10. Furthermore, in making calculations and drawing conclusions from specific samples, it is important both that the samples be simple random samples and that they be taken independently of each other. Finally, each sample cannot be too large; the sample sizes should be no larger than 10% of the populations.
EXAMPLE 12.6
In a study of how environment affects our eating habits, scientists revamped one of two close-to-each-other fast-food restaurants with table cloths, candlelight, and soft music. They then noted that at the revamped restaurant customers ate slower and 25% left at least 100 calories of food on their plates. At the unrevamped garish restaurant, customers tended to wolf down their food, and only 19% left at least 100 calories of food on their plates. In a random sample of 110 customers at the revamped restaurant and an independent random sample of 120 customers at the unrevamped restaurant, what is the probability that the difference in the percentages of customers in the revamped setting and unrevamped setting is more than 10% (where the difference is the revamped restaurant percent minus the unrevamped restaurant percent)?
Answer: We have independent random samples, each less than 10% of all fast-food customers, and we note that n1p1 = 110(0.25) = 27.5, n1(1 – p1) = 110(0.75) = 82.5, n2p2 = 120(0.19) = 22.8, and n2(1 – p2) = 120(0.81) = 97.2 are all $\geq$10. Thus, the sampling distribution of $\widehat{p_1}-\widehat{p_2}$ is roughly normal with mean $\mu\widehat{p_1}-\widehat{p_2}$ = 0.25 – 0.19 = 0.06 and standard deviation $\sigma_{\widehat{p_1}-\widehat{p_2}}=\sqrt{\frac{(0.25)(0.75)}{110}+\frac{(0.19)(0.81)}{120}}=0.0547$. The z-score of 0.10 is (0.1-0.06)/0.0547=0.731 and normalcdf (.731,1000)= 0.232.
[Or normalcdf(0.10,1.0,0.06,0.0547)= 0.232.]
SAMPLING DISTRIBUTION OF A DIFFERENCE BETWEEN TWO INDEPENDENT SAMPLE MEANS
Many real-life applications of statistics involve comparisons of two population means. For example, is the average weight of laboratory rabbits receiving a special diet greater than that of rabbits on a standard diet? Which of two accounting firms pays a higher mean starting salary? Is the life expectancy of a coal miner less than that of a school teacher?
First we consider how to compare the means of samples, one from each population. When is a difference between two such sample means significant? The answer is more apparent when we realize that what we are looking at is one difference from a set of differences. That is, there is the set of all possible differences obtained by subtracting sample means from one set from sample means from a second set. To judge the significance of one particular difference we must first determine how the differences vary among themselves. The necessary key is the fact that the variance of a set of differences is equal to the sum of the variances of the individual sets. Thus,
![]()
Now if
![]()
then
![]()
Then we have the following about the sampling distribution of $\overline{x_1}-\overline{x_2}$:
Start with two normal populations with means μ1 and μ2 and standard deviations σ1 and σ2. Take all samples of sizes n1 and n2, respectively. Compute the difference $\overline{x_1}-\overline{x_2}$ of the two means in each pair of these samples. Then
1. the set of all differences of sample means is approximately normally distributed (alternatively stated: the distribution of differences of sample means is approximately normal).
2. the mean of the set of differences of sample means equals μ1 – μ2, the difference of population means.
3. the standard deviation $\sigma_{\overline{x_1}-\overline{x_2}}$ of the set of differences of sample means is approximately equal to $\sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}$.
The more either population varies from normal, the greater should be the corresponding sample size. We also have the assumptions of independent simple random samples, and of sample sizes no larger than 10% of the populations.
EXAMPLE 12.7
It is estimated that 40-year-old men contribute an average of 65 genetic mutations to their new children, whereas 20-year-old men contribute an average of only 25. Assuming standard deviations of 15 and 5 mutations respectively for the 40- and 20 year olds, what is the probability that the mean number of mutations in a random sample of thirty-five 40-year-old new fathers is between 35 and 45 more than the mean number in a random sample of forty 20-year-old new fathers?
Answer: We have independent random samples, each less than 10% of their age groups, and both sample sizes are over 30, so the sampling distribution of $\overline{x_1}-\overline{x_2}$ is roughly normal with mean $\mu_{\overline{x_1}-\overline{x_2}}$ = 65 – 25 = 40 and standard deviation $\sigma_{\overline{x_1}-\overline{x_2}}=\sqrt{\frac{15^2}{35}+\frac{5^2}{40}}=2.656$. The z-scores of 35 and 45 are (35-40)/2.656=-1.883 and (45-40)/2.656=1.883 and normalcdf(-1.883,1.883)= 0.940.
[Or normalcdf(35,45,40,2.656= 0.940.]
EXAMPLE 12.8
The average number of missed school days for students going to public schools is 8.5 with a standard deviation of 4.1, while students going to private schools miss an average of 5.3 with a standard deviation of 2.9. In an SRS of 200 public school students and an SRS of 150 private school students, with a probability of 0.95 the difference in average missed days (public average minus private average) is above what number?
Answer: We have large (n1 = 200 and n2 = 150) SRSs that are still smaller than 10% of all public and private school students. The mean of the differences is 8.5 – 5.3 = 3.2, while the standard deviation is $\sqrt{\frac{4.1^2}{200}+\frac{2.9^2}{150}}=0.374$. An area of 0.95 to the right corresponds to a z-score of –1.645. The difference in days is 3.2 – 1.645(0.374) = 2.6. Thus there is a 0.95 probability that the difference in average missed days between public and private school samples is over 2.6 days. [invNorm(.05, 3.2, .374) = 2.585.]
When the population standard deviation σ is unknown, we use the sample standard deviation s as an estimate for σ. But then $\frac{\overline{x}-\mu}{s/\sqrt{n}}$ does not follow a normal distribution. If, however, the original population is normally distributed, there is a distribution that can be used when working with the $s/\sqrt{n}$ ratios. This Student t-distribution was introduced in 1908 by W. S. Gosset, a British mathematician employed by the Guiness Breweries. (When we are working with small samples from a population that is not nearly normal, we must use very different “nonparametric” techniques not discussed in this review book.)
Thus, for a sample from a normally distributed population, we work with the variable
![]()
with a resulting t-distribution that is bell-shaped and symmetric, but lower at the mean, higher at the tails, and so more spread out than the normal distribution.
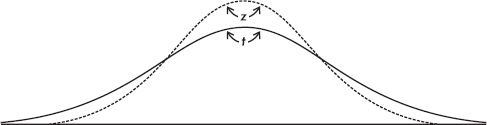
Like the binomial distribution, the t-distribution is different for different values of n. In the tables these distinct t-distributions are associated with the values for degrees of freedom (df). For this discussion the df value is equal to the sample size minus 1. The smaller the df value, the larger the dispersion in the distribution. The larger the df value, that is, the larger the sample size, the closer the distribution to the normal distribution.
Since there is a separate t-distribution for each df value, fairly complete tables would involve many pages; therefore, in Table B of the Appendix we list areas and t-values for only the more commonly used percentages or probabilities. The last row of Table B is the normal distribution, which is a special case of the t-distribution taken when n is infinite. For practical purposes, the two distributions are very close for any n $\geq$ 30 (some use n $\geq$ 40). However, when more accuracy is required, the Student t-distribution can be used for much larger values of n, and the calculations are easy with technology.
Note that, whereas Table A gives areas under the normal curve to the left of given z-values, Table B gives areas to the right of given positive t-values. For example, suppose the sample size is 20, and so df = 20 – 1 = 19. Then a probability of 0.05 in the tail corresponds with a t-value of 1.729, while 0.01 in the tail corresponds to t = 2.539.
Thus the t-distribution is the proper choice whenever the population standard deviation σ is unknown. In the real world σ is almost always unknown, and so we should almost always use the t-distribution. In the past this was difficult because extensive tables were necessary for the various t-distributions. However, with calculators such as the TI-84, this problem has diminished. It is no longer necessary to assume that the t-distribution is close enough to the z-distribution whenever n is greater than the arbitrary number 30.
The issue of sample size is refined even further by some statisticians:
| Unnecessary to make any assumptions about parent population. Sample should show no extreme values and little, if any, skewness; or assume parent population is normal. Sample should show no outliers and no skewness; or assume parent population is normal. |
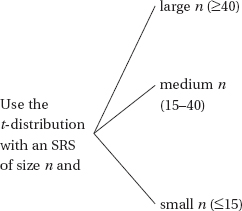
For $\frac{\overline{x}-\mu}{s/\sqrt{n}}$ to have a t-distribution, we actually need that the sampling distribution of x is normal. This follows either if the original population has a normal distribution or if the sample size is large enough (from the central limit theorem).
There is a family of sampling distribution models, called the chi-square models, which we will use for testing (not confidence intervals). The chi-square distribution has a parameter called degrees of freedom (df). For small df the distribution is skewed to the right; however, for large df it becomes more symmetric and bell-shaped (as does the t-distribution). For one or two degrees of freedom the peak occurs at 0, while for three or more degrees of freedom the peak is at df – 2.
The chi-square distribution, like the t-distribution, has a separate curve for each df value; therefore, in Table C of the Appendix we list critical chi-square values for only the more commonly used tail probabilities. The chi-square distribution has numerous applications, two of the best known of which are goodness of fit of an observed distribution to a theoretical one, and independence of two criteria of classification of qualitative data. While we will be using chi-square for categorical data, the chi-square distribution as seen above is a continuous distribution, and applying it to counting data is just an approximation.
TIP
Also of note are that the mean = df, and the variance = 2df.
With proportions and means we typically do not know population parameters. So in calculating standard deviations of the sampling models, we actually estimate using sample statistics. In this case, we use the term standard error. That is, for proportions,
![]()
Similarly, for means,
![]()
Understand that a sampling distribution is a theoretical thing that never happens in real data analysis. When all we have is an estimate, know it is just that, only an estimate. Of course it’s wrong, but it’s the best we’ve got. This leads to a discussion of bias and accuracy.
In Topic 7 we discussed bias in the context of surveys as a tendency to favor the selection of certain members of a population. In the context of sampling distributions, bias means that the sampling distribution is not centered on the population parameter. The sampling distributions of proportions and means are unbiased, that is, for a given sample size, the set of all sample proportions is centered on the population proportion, and the set of all sample means is centered on the population mean.
The other important, quantifiable judgement of how good an estimate is is accuracy, or how narrow the sampling distribution is. For both proportions and means, this is inversely proportional to $\sqrt{n}$ the square root of the sample size.
SUMMARY
Provided that the sample size n is large enough, the sampling distribution of sample proportions is approximately normal with mean p and standard deviation $\sqrt{\frac{p(1-p)}{n}}$ (where p is the population proportion).
Provided that the sample size n is large enough, the sampling distribution of sample means is approximately normal with mean µ and standard deviation $\frac{\sigma}{\sqrt{n}}$ (where µ and σ are the population mean and standard deviation).
When the population standard deviation σ is unknown (which is almost always the case), and provided that the original population is normally distributed or the sample size n is large enough, the sampling distribution of sample means follows a t-distribution with mean µ and standard deviation $\frac{s}{\sqrt{n}}$ (where µ is the population mean and s is the sample standard deviation).
Multiple-Choice Questions
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. Which of the following is a true statement?
(A) The larger the sample, the larger the spread in the sampling distribution.
(B) Bias has to do with the spread of a sampling distribution.
(C) Provided that the population size is significantly greater than the sample size, the spread of the sampling distribution does not depend on the population size.
(D) Sample parameters are used to make inferences about population statistics.
(E) Statistics from smaller samples have less variability.
2. Which of the following is an incorrect statement?
(A) The sampling distribution of $\overline{x}$ has mean equal to the population mean µ even if the population is not normally distributed.
(B) The sampling distribution of $\overline{x}$ has standard deviation $\frac{\sigma}{n}$ even if the population is not normally distributed.
(C) The sampling distribution of $\overline{x}$ is normal if the population has a normal distribution.
(D) When n is large, the sampling distribution of $\overline{x}$ is approximately normal even if the population is not normally distributed.
(E) The larger the value of the sample size n, the closer the standard deviation of the sampling distribution of $\overline{x}$ is to the standard deviation of the population.
3. Which of the following is a true statement?
(A) The sampling distribution of $\widehat{p}$ has a mean equal to the population proportion p.
(B) The sampling distribution of $\widehat{p}$ has a standard deviation equal to $\sqrt{np(1-p)}$
(C) The sampling distribution of $\widehat{p}$ has a standard deviation that becomes larger as the sample size becomes larger.
(D) The sampling distribution of $\widehat{p}$ is considered close to normal provided that n $\geq$ 30.
(E) The sampling distribution of $\widehat{p}$ is always close to normal.
4. In a school of 2500 students, the students in an AP Statistics class are planning a random survey of 100 students to estimate the proportion who would rather drop lacrosse rather than band during this time of severe budget cuts. Their teacher suggests instead to survey 200 students in order to
(A) reduce bias.
(B) reduce variability.
(C) increase bias.
(D) increase variability.
(E) make possible stratification between lacrosse and band.
5. The ages of people who died last year in the United States is skewed left. What happens to the sampling distribution of sample means as the sample size goes from n = 50 to n = 200?
(A) The mean gets closer to the population mean, the standard deviation stays the same, and the shape becomes more skewed left.
(B) The mean gets closer to the population mean, the standard deviation becomes smaller, and the shape becomes more skewed left.
(C) The mean gets closer to the population mean, the standard deviation stays the same, and the shape becomes closer to normal.
(D) The mean gets closer to the population mean, the standard deviation becomes smaller, and the shape becomes closer to normal.
(E) The mean stays the same, the standard deviation becomes smaller, and the shape becomes closer to normal.
6. Which of the following is the best reason that the sample maximum is not used as an estimator for the population maximum?
(A) The sample maximum is biased.
(B) The sampling distribution of the sample maximum is not binomial.
(C) The sampling distribution of the sample maximum is not normal.
(D) The sampling distribution of the sample maximum has too large a standard deviation.
(E) The sample mean plus three sample standard deviations gives a much superior estimate for the population maximum.
7. Which of the following are unbiased estimators for the corresponding population parameters?
I. Sample means
II. Sample proportions
III. Difference of sample means
IV. Difference of sample proportions
(A) None are unbiased.
(B) I and II
(C) I and III
(D) III and IV
(E) All are unbiased.
8. Thirty-four percent of Americans say that math is the most important subject in school. In a random sample of 400 Americans, what is the probability that between 30% and 35% will say that math is the most important subject?
(A) 0.291
(B) 0.337
(C) 0.382
(D) 0.618
(E) 0.709
9. Researchers found that in the aftermath of the 2011 Fukushima nuclear disaster, 12% of the pale grass blue butterfly larvae developed mutations as adults. What is the probability that in a random sample of 300 of these butterfly larvae, more than 15 developed mutations as adults?

10. Suppose using accelerometers in helmets, researchers determine that boys playing high school football absorb an average of 355 hits to the head with a standard deviation of 80 hits during a season (including both practices and games). What is the probability on a randomly selected team of 48 players that the average number of head hits per player is between 340 and 360?
(A) 0.236
(B) 0.429
(C) 0.571
(D) 0.614
(E) 0.764
11. It is estimated that school CO2 levels average 1200 ppm with a standard deviation of 300 ppm. In a random sample of 30 schools, what is the probability that the mean CO2 level is more than 1000, a level at which some researchers feel will cause a drop in academic performance?
12. Binge drinking is a serious problem, killing more than 1700 college students per year. Suppose the incidence of binge drinking is 43% and 37%, respectively, at two large universities. In a random sample of 75 students at the first school and 80 students at the second, what is the probability that the difference (first minus second) between the percentages of binge drinkers is between 5% and 10%?
(A) 0.176
(B) 0.245
(C) 0.473
(D) 0.527
(E) 0.755
13. Suppose “sleep-trained” babies (allowed to cry themselves to sleep) wake up an average of 1.2 times a night with a standard deviation of 0.3 times, while nontrained babies wake up an average of 1.8 times a night with a standard deviation of 0.5 times. In a random sample of 80 babies, half of which are sleep-trained, what is the probability that the nontrained babies in the sample wake up an average number of times greater than 0.75 more than the average of the sleep-trained babies?
(A) 0.0519
(B) 0.1179
(C) 0.4481
(D) 0.3821
(E) 0.9481
14. Which of the following statements are true?
I. Like the normal, t-distributions are always symmetric.
II. Like the normal, t-distributions are always mound-shaped.
III. The t-distributions have less spread than the normal, that is, they have less probability in the tails and more in the center than the normal.
(A) II only
(B) I and II
(C) I and III
(D) II and III
(E) I, II, and III
15. Which of the following statements about t-distributions are true?
I. The greater the number of degrees of freedom, the narrower the tails.
II. The smaller the number of degrees of freedom, the closer the curve is to the normal curve.
III. Thirty degrees of freedom gives the normal curve.
(A) I only
(B) I and II
(C) I and III
(D) II and III
(E) I, II, and III
Free-Response Questions
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your final answers.
FOUR OPEN-ENDED QUESTIONS
1. It is estimated that 58% of all Americans sleep on their sides.
(a) What is the probability that a randomly chosen American sleeps on his/her side?
(b) In a random sample of five Americans, what is the probability that at least three sleep on their sides?
(c) In a random sample of 350 Americans, what is the probability that at least 50% sleep on their sides?
2. Studies have shown that teenage drivers are three times more likely to be involved in a fatal crash than drivers age 20 and older, and so insurance rates for teenagers are higher. The average yearly cost of teenage auto insurance is \$2275 with a standard deviation of \$650. An SRS is taken of 90 teenage drivers.
(a) Explain why there is insufficient information to determine the probability a randomly chosen teenage driver pays over \$2400.
(b) What are the mean and standard deviation for the sampling distribution for $\overline{x}$, the mean amount paid for insurance?
(c) What is the probability that the average amount paid in the sample is more than \$2400?
3. It is estimated that a new baby deprives each of its parents of an average of 374 hours of sleep in the first year with a standard deviation of 38.55 hours. Assume a normal distribution of deprived hours.
(a) What is the interquartile range (IQR) of the distribution of hours deprived?
(b) In a random sample of three parents of new babies, what is the probability that a majority are deprived of more than 400 hours?
(c) In a random sample of three parents of new babies, what is the probability that the mean number of deprived hours is more than 400?
4. The amount of fuel used by jumbo jets to take off is normally distributed with a mean of 4000 gallons and a standard deviation of 125 gallons.
(a) What is the probability that a randomly selected jumbo jet will need more than 4250 gallons of fuel to take off?
(b) What are the shape, mean, and standard deviation of the sampling distribution of the mean gallons of fuel to take off of 40 randomly selected jumbo jets?
(c) In a random sample of 40 jumbo jets, what is the probability that the mean number of gallons of fuel needed to take off is less than 3950?
(d) Would the answers to (a), (b), or (c) be affected if the original population of gallons of fuel used by jumbo jets to take off were skewed instead of normal? Explain.
AN INVESTIGATIVE TASK
Five AP Statistics students want to extend their knowledge beyond the standard course content and read about the finite population correction factor, $\sqrt{\frac{N-n}{N-1}}$ where N is the population size, and n is the sample size. To study this concept, they each make picks for the 32 games in the first round of the March Madness Men’s Division 1 basketball tournament. They note that the number of winners each picked gives a set of size N = 5 consisting of the elements 6, 9, 11, 13, and 21.
(a) Determine the population mean μ and the population standard deviation σ for this set.
(b) List all possible samples of size n = 2 [there are C(5, 2) = 10 of them] and determine the mean $\overline{x}$ of each.
(c) Make a dotplot of the sampling distribution of $\overline{x}$ from (b).
(d) Calculate the mean $\mu_\overline{x}$ and standard deviation $\sigma_\overline{x}$ of the distribution in (c).
(e) Compare $\mu_\overline{x}$ to $\mu$ and $\sigma_\overline{x}$ to $\frac{\sigma}{\sqrt{n}}\sqrt{\frac{N-n}{N-1}}$.
(f) More generally, what can be said about $\frac{\sigma}{\sqrt{n}}\sqrt{\frac{N-n}{N-1}}$ if the population size N is very large?
MULTIPLE-CHOICE
1. (C) The larger the sample, the smaller the spread in the sampling distribution. Bias has to do with the center, not the spread, of a sampling distribution. Sample statistics are used to make inferences about population proportions. Statistics from smaller samples have more variability.
2. (E) It is always true that the sampling distribution of x has mean µ and standard
deviation  . In addition, the sampling distribution will be normal if the population
. In addition, the sampling distribution will be normal if the population
is normal and will be approximately normal if n is large even if the population is not
normal. and σ are not equal unless n = 1.
3. (A) The sampling distribution of  has a standard deviation
has a standard deviation  which is smaller with larger n. While the sampling distribution of is never exactly normal, it is considered close to normal provided that both np and n(1 – p) are large enough (greater than 10 is a standard guide).
which is smaller with larger n. While the sampling distribution of is never exactly normal, it is considered close to normal provided that both np and n(1 – p) are large enough (greater than 10 is a standard guide).
4. (B) Sample proportions are an unbiased estimator for the population proportion, and larger sample sizes lead to reduced variability.
5. (E) The sampling distribution of x has mean µ, standard deviation  and shape, which becomes closer to normal with larger n.
and shape, which becomes closer to normal with larger n.
6. (A) The maximum of a sample is never larger than the maximum of the population, so the mean of the sample maximums will not be equal to the population maximum. (A sampling distribution is unbiased if its mean is equal to the population parameter.)
7. (E) All are unbiased estimators for the corresponding population parameters; that is, the means of their sampling distributions are equal to the population parameters.
8. (D) The sample is given to be random, both np = (400)(0.34) = 136  10 and n(1 – p) = (400)(0.66) = 264 10, and our sample is clearly less than 10% of all people. So the sampling distribution of is approximately normal with mean 0.34 and standard deviation
10 and n(1 – p) = (400)(0.66) = 264 10, and our sample is clearly less than 10% of all people. So the sampling distribution of is approximately normal with mean 0.34 and standard deviation  and
and  the probability that the sample proportion is between 0.30 and 0.35 is normalcdf(–1.688, .422)= 0.618. [Or normalcdf(.3, .35, .34, .0237)= 0.618.]
the probability that the sample proportion is between 0.30 and 0.35 is normalcdf(–1.688, .422)= 0.618. [Or normalcdf(.3, .35, .34, .0237)= 0.618.]

9. (B) The sample is given to be random, both np = (300)(0.12) = 36 10 and n(1 – p) = (300)(0.88) = 264 10, and our sample is clearly less than 10% of all butterfly larvae. So the sampling distribution of is approximately normal with mean µ = 0.12 and standard deviation  the probability that the sample proportion is more than 15% is
the probability that the sample proportion is more than 15% is 

10. (C) We have a random sample that is less than 10% of the high school football population. With a sample size of 48, the central limit theorem applies, and the sampling distribution of x is approximately normal with mean µx = 355 and standard deviation  The z-scores of 340 and 360 are
The z-scores of 340 and 360 are  and
and  the probability of a sample mean between 340 and 360 is normalcdf(-1.299,.433)= 0.571. [Or normalcdf(340,360,355,11.547)= 0.571.]
the probability of a sample mean between 340 and 360 is normalcdf(-1.299,.433)= 0.571. [Or normalcdf(340,360,355,11.547)= 0.571.]

11. (A) We have a random sample that is less than 10% of all schools. With a sample size of 30, the central limit theorem applies, and the sampling distribution of x is approximately normal with mean µx = 1200 and standard deviation  The z-score of 1000 is
The z-score of 1000 is  and the probability of a sample mean over 1000 is
and the probability of a sample mean over 1000 is 

12. (B) We have two independent random samples, each less than 10% of their respective populations, and we note that n1p1 = 75(0.43) = 32.25, n1(1 – p1) = 75(0.57) = 42.75, n2p2 = 80(0.37) = 29.6, and n2(1 – p2) = 80(0.63) = 50.4 are all 10. Thus the sampling distribution of  1 – 2 is roughly normal with mean
1 – 2 is roughly normal with mean  and standard deviation
and standard deviation  The z-score of 0.05 is
The z-score of 0.05 is  the z-score of 0.10 is
the z-score of 0.10 is  and normalcdf(-.127,.509)= 0.245. [Or normalcdf(.05,.10,.06,.0786)= 0.245.]
and normalcdf(-.127,.509)= 0.245. [Or normalcdf(.05,.10,.06,.0786)= 0.245.]

13. (A) We have independent random samples, each less than 10% of babies, and both sample sizes are 40 30, so the sampling distribution of  1 – 2 is roughly normal with mean
1 – 2 is roughly normal with mean  and standard deviation
and standard deviation  The z-score of 0.75 is
The z-score of 0.75 is  and normalcdf(1.627,1000)= 0.0519. [Or normalcdf(.75,1000,.6,.0922)= 0.0519.]
and normalcdf(1.627,1000)= 0.0519. [Or normalcdf(.75,1000,.6,.0922)= 0.0519.]

14. (B) The t-distributions are symmetric and mound-shaped, and they have more, not less, spread than the normal distribution.
15. (A) The larger the number of degrees of freedom, the closer the curve to the normal curve. While around the 30 level is often considered a reasonable approximation to the normal curve, it is not the normal curve.
FREE-RESPONSE
1. (a) 0.58
(b) This is a binomial with n = 3 and p = 0.58.

or 1–binomcdf(5,.58,2)= 0.647.
(c) The sample is given to be random, both np = (350)(0.58) = 203 10 and n(1 – p) = (350)(0.42) = 147 10, and our sample is clearly less than 10% of all Americans. So the sampling distribution of is approximately normal with mean 0.58 and standard deviation  With a z-score of
With a z-score of  the probability that the sample proportion is greater than 0.5 is normalcdf(−3.030,1000)= 0.9988.
the probability that the sample proportion is greater than 0.5 is normalcdf(−3.030,1000)= 0.9988.
[Or normalcdf (.5,1,.58,.0264)= 0.9988.]
2. (a) We do not know the shape of the distribution of the amount individual teenage drivers pay for insurance, so there is no way of calculating the probability a randomly chosen teenage driver pays over $2400 a year for auto insurance.
(b) 
(c) With this large a sample size (90 40), the central limit theorem tells us that the sampling distribution of x is approximately normal. We calculate

3. (a) The z-scores corresponding to cumulative probabilities of 0.25 and 0.75 are ±0.6745. Thus Q1 = 374 – (0.6745)(38.55) = 348.00, Q3 = 374 + (0.6745)(38.55) = 400.00, and IQR = Q3 – Q1 = 400 – 348 = 52 hours.
(b) From part (a), we have that the probability of less than 400 deprived hours is 0.75, and thus the probability of being more than 400 deprived hours is 0.25. Now we have a binomial with n = 3 and p = 0.25. P(majority > 400) = P(2 or 3 are > 400) = 3(0.25)2(0.75) + (0.25)3 = 0.15625.
(c) The sampling distribution of the sample means is approximately normal (because the original population is normal) with mean µx = µ = 374 and standard deviation  The z-score of 400 is
The z-score of 400 is  and the probability of a sample mean over 400 is normalcdf(1.168,1000)= 0.121. [Or normalcdf(400,1000,374,22.257)= 0.121.]
and the probability of a sample mean over 400 is normalcdf(1.168,1000)= 0.121. [Or normalcdf(400,1000,374,22.257)= 0.121.]
4. (a) 
[Or normalcdf(4250,10000,4000,125)= 0.0228.]
(b) The original population is normal so the sampling distribution of is normal with mean µ = µ = 4000 and standard deviation 
(c) 
[Or normalcdf(0,3950,4000,19.764)= 0.0057.]
(d) The answer to part (a) would be affected because it assumes a normal population. The other answers would not be affected because for large enough n, the central limit theorem gives that the sampling distribution of is roughly normal regardless of the distribution of the original population.
INVESTIGATIVE TASK
(a) Using a calculator, find μ = 12 and σ = 5.0596.
(b)

(c) 
(d) µx = 12 and x = 3.0984.
(e) 
(f) If N is very large,  is approximately equal to 1, and so the expression is approximately equal to
is approximately equal to 1, and so the expression is approximately equal to 

 DEFINITION
DEFINITION
FOR A PROPORTION
FOR A DIFFERENCE OF TWO PROPORTIONS
FOR A MEAN
FOR A DIFFERENCE BETWEEN TWO MEANS
FOR THE SLOPE OF A LEAST SQUARES REGRESSION LINE
Using a measurement from a sample, we are never able to say exactly what a population proportion or mean is; rather we always say we have a certain confidence that the population proportion or mean lies in a particular interval. The particular interval is centered around a sample proportion or mean (or other statistic) and can be expressed as the sample estimate plus or minus an associated margin of error.
THE MEANING OF A CONFIDENCE INTERVAL
Using what we know about sampling distributions, we are able to establish a certain confidence that a sample proportion or mean lies within a specified interval around the population proportion or mean. However, we then have the same confidence that the population proportion or mean lies within a specified interval around the sample proportion or mean (e.g., the distance from Missoula to Whitefish is the same as the distance from Whitefish to Missoula).
Typically we consider 90%, 95%, and 99% confidence interval estimates, but any percentage is possible. The percentage is the percentage of samples that would pinpoint the unknown p or µ within plus or minus a certain margin or error. We do not say there is a 0.90, 0.95, or 0.99 probability that p or µ is within a certain margin of error of a given sample proportion or mean. For a given sample proportion or mean, p or µ either is or isn’t within the specified interval, and so the probability is either 1 or 0.
As will be seen, there are two aspects to this concept. First, there is the confidence interval, usually expressed in the form:
estimate ± margin of error
Second, there is the success rate for the method, that is, the proportion of times repeated applications of this method would capture the true population parameter.
CONFIDENCE INTERVAL FOR A PROPORTION
We are interested in estimating a population proportion p by considering a single sample proportion . This sample proportion is just one of a whole universe of sample proportions, and from Topic 12 we remember the following:
1. The set of all sample proportions is approximately normally distributed.
2. The mean µ of the set of sample proportions equals p, the population proportion.
3. The standard deviation of the set of sample proportions is approximately equal to 
In finding confidence interval estimates of the population proportion p, how do we find  since p is unknown? The reasonable procedure is to use the sample proportion :
since p is unknown? The reasonable procedure is to use the sample proportion :

When the standard deviation is estimated in this way (using the sample), we use the term standard error. That is,

Remember that we are really using a normal approximation to the binomial, so n and n(1 – ) should both be at least 10. Furthermore, in making calculations and drawing conclusions from a specific sample, it is important that the sample be a simple random sample. Finally, the population should be large, typically checked by the assumption that the sample is less than 10% of the population. (If the population is small and the sample exceeds 10% of the population, then models other than the normal are more appropriate.)
 EXAMPLE 13.1
EXAMPLE 13.1
IMPORTANT
Verifying assumptions and conditions means more than simply listing them with little check marks. You must show work or give some reason to confirm verification.
If 64% of an SRS of 550 people leaving a shopping mall claim to have spent over $25, determine a 99% confidence interval estimate for the proportion of shopping mall customers who spend over $25.
Answer: We check that n = 550(0.64) = 352 10 and n(1 – ) = 550(0.36) = 198 10, we are given that the sample is an SRS, and it is reasonable to assume that 550 is less than 10% of all mall shoppers. Since = 0.64, the standard deviation of the set of sample proportions is

From Topic 11 we know that 99% of the sample proportions should be within 2.576 standard deviations of the population proportion. Equivalently, we are 99% certain that the population proportion is within 2.576 standard deviations of any sample proportion.1 Thus the 99% confidence interval estimate for the population proportion is 0.64 ± 2.576(0.0205) = 0.64 ± 0.053. We say that the margin of error is ±0.053. We are 99% certain that the proportion of shoppers spending over $25 is between 0.587 and 0.693.
We can also say, using the definition of confidence level, that if the interviewing procedure were repeated many times, about 99% of the resulting confidence intervals would contain the true proportion (thus we’re 99% confident that the method worked for the interval we got).1
TIP
The margin of error accounts for variation inherent in sampling, but it does not account for and is not a redress for bias in sampling.
EXAMPLE 13.2
In a simple random sample of machine parts, 18 out of 225 were found to have been damaged in shipment. Establish a 95% confidence interval estimate for the proportion of machine parts that are damaged in shipment.
TIP
After finding a confidence interval, you must always interpret the interval in context.
Answer: We check that n = 18 10 and n(1 – ) = 225 – 18 = 207 10, we are given that the sample is an SRS, and it is reasonable to assume that 225 is less than 10% of all shipped machine parts.
Calculator software (such as 1-PropZInt on the TI-84) gives (0.04455,0.11545).
[For instructional purposes in this review book, we note that 

Thus we are 95% certain that the proportion of machine parts damaged in shipment is between 0.045 and 0.115.
On the TI-Nspire the result shows as:

Suppose there are 50,000 parts in the entire shipment. We can translate from proportions to actual numbers:
0.045(50,000) = 2250 and 0.115(50,000) = 5750
and so we can be 95% confident that there are between 2250 and 5750 defective parts in the whole shipment.
TIP
On the TI-84, for a confidence interval of a proportion, use 1-PropZInt, not Zinterval; and x must be an integer.
TIP
Finding confidence intervals using formulas is not necessary on free-response questions, but answer choices using formulas may well appear on multiple-choice questions.
EXAMPLE 13.3
A telephone survey of 1000 adults was taken shortly after the United States began bombing Iraq.
a. If 832 voiced their support for this action, with what confidence can it be asserted that 83.2% ± 3% of the adult U.S. population supported the decision to go to war?
Answer: We check that n = 832 10 and n(1 – ) = 1000 – 832 = 168 10, we assume an SRS, and clearly 1000 is <10% of the adult U.S. population.

The relevant z-scores are 
In other words, 83.2% ± 3% is a 98.89% confidence interval estimate for U.S. adult support of the war decision.
b. If the adult U.S. population is 191 million, estimate the actual numerical support.
Answer: Since
0.802(191,000,000) ≈ 153,000,000
while
0.862(191,000,000) ≈ 165,000,000
we can be 98.90% confident that between 153 and 165 million adults supported the initial bombing decision.
EXAMPLE 13.4
A U.S. Department of Labor survey of 6230 unemployed adults classified people by marital status, gender, and race. The raw numbers are as follows:

a. Find a 90% confidence interval estimate for the proportion of unemployed men who are married.
Answer: Totaling the first row across both tables, we find that there are 3499 men in the survey; 1090 + 266 = 1356 of them are married. We check that n = 1356 10 and n(1 – ) = 3499 – 1356 = 2143 10, we assume an SRS, and clearly the sample is <10% of the total unemployed adult population. On the TI-84, 1-PropZInt gives (0.37399, 0.40109). [For instructional purposes we note that  Thus the 90% confidence interval estimate is 0.3875 ± 1.645(0.008236) = 0.3875 ± 0.0135.] We are 90% confident that the true proportion of unemployed men who are married is between 0.374 and 0.401.
Thus the 90% confidence interval estimate is 0.3875 ± 1.645(0.008236) = 0.3875 ± 0.0135.] We are 90% confident that the true proportion of unemployed men who are married is between 0.374 and 0.401.
b. Find a 98% confidence interval estimate of the proportion of unemployed single persons who are women.
Answer: There are 1168 + 632 + 503 + 349 = 2652 singles in the survey. Of these, 632 + 349 = 981 are women [n = 981 10 and n(1 – ) = 2652 – 981 = 1671 10]. On the TI-84, 1-PropZInt gives (0.3481, 0.39172).
[For instructional purposes we note that 

The 98% confidence interval estimate is 0.3699 ± 2.326(0.009375) = 0.3699 ± 0.0218.] We are 98% confident that the true proportion of unemployed single persons who are women is between 0.348 and 0.392.
As we have seen, there are two types of statements that come out of confidence intervals. First, we can interpret the confidence interval and say we are 90% confident that between 60% and 66% of all voters favor a bond issue. Second, we can interpret the confidence level and say that if this survey were conducted many times, then about 90% of the resulting confidence intervals would contain the true proportion of voters who favor the bond issue.
Incorrect statements include “The percentage of all voters who support the bond issue is between 60% and 66%,” “There is a 0.90 probability that the true percentage of all voters who favor the bond issue is between 60% and 66%,” and “If this survey were conducted many times, then about 90% of the sample proportions would be in the interval (0.60, 0.66).”
One important consideration in setting up a survey is the choice of sample size. To obtain a smaller, more precise interval estimate of the population proportion, we must either decrease the degree of confidence or increase the sample size. Similarly, if we want to increase the degree of confidence, we can either accept a wider interval estimate or increase the sample size. Again, while choosing a larger sample size may seem desirable, in the real world this decision involves time and cost considerations.
In setting up a survey to obtain a confidence interval estimate of the population proportion, what should we use for ? To answer this question, we first must consider how large  can be. We plot various values of p:
can be. We plot various values of p:

which gives 0.5 as the intuitive answer. Thus  We make use of this fact to determine sample sizes in problems such as Examples 13.5 and 13.6.
We make use of this fact to determine sample sizes in problems such as Examples 13.5 and 13.6.
TIP
Noting the inequality, the result must be rounded up if it is a decimal.
EXAMPLE 13.5
An Environmental Protection Agency (EPA) investigator wants to know the proportion of fish that are inedible because of chemical pollution downstream of an offending factory. If the answer must be within ±0.03 at the 96% confidence level, how many fish should be in the sample tested?
Answer: We want 2.05  0.03. From the above remark, is at most
0.03. From the above remark, is at most  and so it is sufficient to consider 2.05
and so it is sufficient to consider 2.05  Algebraically, we have
Algebraically, we have  and n 1167.4. Therefore, choosing a sample of 1168 fish gives the inedible proportion to within ±0.03 at the 96% level.
and n 1167.4. Therefore, choosing a sample of 1168 fish gives the inedible proportion to within ±0.03 at the 96% level.
Note that the accuracy of the estimate does not depend on what fraction of the whole population we have sampled. What is critical is the absolute size of the sample. Is some minimal value of n necessary for the procedures we are using to be meaningful? Since we are using the normal approximation to the binomial, both np and n(1 – p) should be at least 10 (see Topic 11).
EXAMPLE 13.6
A study is undertaken to determine the proportion of industry executives who believe that workers’ pay should be based on individual performance. How many executives should be interviewed if an estimate is desired at the 99% confidence level to within ±0.06? To within ±0.03? To within ±0.02?

or 4148 executives should be interviewed, depending on the accuracy desired.
Note that to cut the interval estimate in half (from ±0.06 to ±0.03), we would have to increase the sample size fourfold, and to cut the interval estimate to a third (from ±0.06 to ±0.02), a ninefold increase in the sample size would be required (answers are not exact because of round-off error.)
More generally, to divide the interval estimate by d without affecting the confidence level, we must increase the sample size by a multiple of d2.
A formula for the calculations in Examples 13.5 and 13.6 is

(Note: this formula is not given on the AP Exam formula page.)
CONFIDENCE INTERVAL FOR A DIFFERENCE OF TWO PROPORTIONS
From Topic 12, we have the following information about the sampling distribution of 1 – 2:
1. The set of all differences of sample proportions is approximately normally distributed.
2. The mean of the set of differences of sample proportions equals p1 – p2, the difference of population proportions.
3. The standard deviation d of the set of differences of sample proportions is approximately equal to

Remember that we are using the normal approximation to the binomial, so n1 1, n1(1 – 1), n2 2, and n2(1 – 2) should all be at least 10. In making calculations and drawing conclusions from specific samples, it is important both that the samples be simple random samples and that they be taken independently of each other. Finally, the original populations should be large compared to the sample sizes.
EXAMPLE 13.7
Suppose that 84% of an SRS of 125 nurses working 7 a.m. to 3 p.m. shifts in city hospitals express positive job satisfaction, while only 72% of an SRS of 150 nurses on 11 p.m. to 7 a.m. shifts express similar fulfillment. Establish a 90% confidence interval estimate for the difference.
TIP
When interpreting the confidence interval for a difference, you must indicate which direction the difference is taken.
Answer: Note that n11 = (125)(0.84) = 105, n1(1 – 1) = (125)(0.16) = 20, n22 = (150)(0.72) = 108, and n2(1 – 2) = (150)(0.28) = 42 are all 10, we are given SRSs, and the population of city hospital nurses is assumed to be large. On the TI-84, 2-PropZInt gives (0.0391, 0.2009). [For instructional purposes, we note that

The observed difference is 0.84 – 0.72 = 0.12, and the critical z-scores are ±1.645. The confidence interval estimate is 0.12 ± 1.645(0.0492) = 0.12 ± 0.081.]
We can be 90% certain that the proportion of satisfied nurses on 7 a.m. to 3 p.m. shifts is between 0.039 and 0.201 higher than the proportion for nurses on 11 p.m. to 7 a.m. shifts.
EXAMPLE 13.8
A grocery store manager notes that in an SRS of 85 people going through the express checkout line, only 10 paid with checks, whereas, in an SRS of 92 customers passing through the regular line, 37 paid with checks. Find a 95% confidence interval estimate for the difference between the proportion of customers going through the two different lines who use checks.
Answer: Note that n1 1 = 10, n1(1 – 1) = 75, n2 2 = 37, and n2(1 – 2) = 55 are all at least 10, we are given SRSs, and the total number of customers is large. On the TI-84, 2-PropZInt gives (–0.4059, –0.1632). [For instructional purposes, we note that

The observed difference is 0.118 – 0.402 = – 0.284, and the critical z-scores are ±1.96. Thus, the confidence interval estimate is – 0.284 ± 1.96(0.0619) = –0.284 ± 0.121.] The manager can be 95% sure that the proportion of customers passing through the express line who use checks is between 0.163 and 0.405 lower than the proportion going through the regular line who use checks.
With regard to choosing a sample size,  is at most 0.5. Thus
is at most 0.5. Thus

Now, if we simplify by insisting that n1 = n2 = n, the above statement can be reduced as follows:

(Note: this formula is not given on the AP Exam formula page.)
EXAMPLE 13.9
A pollster wants to determine the difference between the proportions of high-income voters and low-income voters who support a decrease in the capital gains tax. If the answer must be known to within ±0.02 at the 95% confidence level, what size samples should be taken?
Answer: Assuming we will pick the same size samples for the two sample proportions, we have  Algebraically we find that
Algebraically we find that  Therefore, n 69.32 = 4802.5, and the pollster should use 4803 people for each sample.
Therefore, n 69.32 = 4802.5, and the pollster should use 4803 people for each sample.
CONFIDENCE INTERVAL FOR A MEAN
We are interested in estimating a population mean µ by considering a single sample mean x. This sample mean is just one of a whole universe of sample means, and from Topic 12 we remember that if n is sufficiently large,
1. the set of all sample means is approximately normally distributed.
2. the mean of the set of sample means equals µ, the mean of the population.
3. the standard deviation x of the set of sample means is approximately equal to  that is, equal to the standard deviation of the whole population divided by the square root of the sample size.
that is, equal to the standard deviation of the whole population divided by the square root of the sample size.
Frequently we do not know , the population standard deviation. In such cases, we must use s, the standard deviation of the sample, as an estimate of . In this case  is called the standard error, SE(x), and is used as an estimate for x =
is called the standard error, SE(x), and is used as an estimate for x =  (Note that we use t-distributions instead of the standard normal curve whenever is unknown, no matter what the sample size.)
(Note that we use t-distributions instead of the standard normal curve whenever is unknown, no matter what the sample size.)
Remember that in making calculations and drawing conclusions from a specific sample, it is important that the sample be a simple random sample and be no more than 10% of the population.
EXAMPLE 13.10
A bottling machine is operating with a standard deviation of 0.12 ounce. Suppose that in an SRS of 36 bottles the machine inserted an average of 16.1 ounces into each bottle.
a. Estimate the mean number of ounces in all the bottles this machine fills. More specifically, give an interval within which we are 95% certain that the mean lies.
Answer: For samples of size 36, the sample means are approximately normally distributed with a standard deviation of  From Topic 11 we know that 95% of the sample means should be within 1.96 standard deviations of the population mean. Equivalently, we are 95% certain that the population mean is within 1.96 standard deviations of any sample mean. In our case, 16.1 ± 1.96(0.02) = 16.1 ± 0.0392, and we are 95% sure that the mean number of ounces in all bottles is between 16.0608 and 16.1392. This is called a 95% confidence interval estimate. [On the TI-84, under STAT and then TESTS, go to ZInterval. With Inpt:Stats, :.12, x:16.1, n:36, and C-Level:.95, Calculate gives (16.061, 16.139).]
From Topic 11 we know that 95% of the sample means should be within 1.96 standard deviations of the population mean. Equivalently, we are 95% certain that the population mean is within 1.96 standard deviations of any sample mean. In our case, 16.1 ± 1.96(0.02) = 16.1 ± 0.0392, and we are 95% sure that the mean number of ounces in all bottles is between 16.0608 and 16.1392. This is called a 95% confidence interval estimate. [On the TI-84, under STAT and then TESTS, go to ZInterval. With Inpt:Stats, :.12, x:16.1, n:36, and C-Level:.95, Calculate gives (16.061, 16.139).]
b. How about a 99% confidence interval estimate?
Answer: Here, 16.1 ± 2.576(0.02) = 16.1 ± 0.0515, and we are 99% sure that the mean number of ounces in all bottles is between 16.0485 and 16.1515. [On the TI-84, ZInterval gives (16.048, 16.152).] We can also say, using the definition of confidence level, that if the sampling procedure were repeated many times, about 99% of the resulting confidence intervals would contain the true population mean (thus we’re 99% confident that the method worked for the interval we got).
Note that when we wanted a higher certainty (99% instead of 95%), we had to settle for a larger, less specific interval (±0.0515 instead of ±0.0392).
EXAMPLE 13.11
At a certain plant, batteries are being produced with a life expectancy that has a variance of 5.76 months squared. Suppose the mean life expectancy in an SRS of 64 batteries is 12.35 months.
a. Find a 90% confidence interval estimate of life expectancy for all the batteries produced at this plant.
Answer: The standard deviation of the population is  and the standard deviation of the sample means is
and the standard deviation of the sample means is  confidence interval estimate for the population mean is 12.35 ± 1.645(0.3) = 12.35 ± 0.4935. Thus we are 90% certain that the mean life expectancy of the batteries is between 11.8565 and 12.8435 months. [The TI-84 gives (11.857, 12.843).]
confidence interval estimate for the population mean is 12.35 ± 1.645(0.3) = 12.35 ± 0.4935. Thus we are 90% certain that the mean life expectancy of the batteries is between 11.8565 and 12.8435 months. [The TI-84 gives (11.857, 12.843).]
b. What would the 90% confidence interval estimate be if the sample mean of 12.35 had come from a sample of 100 batteries?
Answer: The standard deviation of the sample means would then have been  and the 90% confidence interval estimate would be 12.35 ± 1.645(0.24) = 12.35 ± 0.3948. [The TI-84 gives (11.955, 12.745).]
and the 90% confidence interval estimate would be 12.35 ± 1.645(0.24) = 12.35 ± 0.3948. [The TI-84 gives (11.955, 12.745).]
Note that when the sample size increased (from 64 to 100), the same sample mean resulted in a narrower, more specific interval (±0.3948 versus ±0.4935).
EXAMPLE 13.12
A new drug results in lowering the heart rate by varying amounts with a standard deviation of 2.49 beats per minute.
a. Find a 95% confidence interval estimate for the mean lowering of the heart rate in all patients if a 50-person SRS averages a drop of 5.32 beats per minute.
Answer: The standard deviation of sample means is  We are 95% certain that the mean lowering of the heart rate is in the range 5.32 ± 1.96(0.352) = 5.32 ± 0.69 or between 4.63 and 6.01 heartbeats per minute. [The TI-84 gives (4.6298, 6.0102).]
We are 95% certain that the mean lowering of the heart rate is in the range 5.32 ± 1.96(0.352) = 5.32 ± 0.69 or between 4.63 and 6.01 heartbeats per minute. [The TI-84 gives (4.6298, 6.0102).]
b. With what certainty can we assert that the new drug lowers the heart rate by a mean of 5.32 ± 0.75 beats per minute?
Answer: Converting ±0.75 to z-scores yields  From Table A, these z-scores give probabilities of 0.0166 and 0.9834, respectively, so our answer is 0.9834 – 0.0166 = 0.9668. In other words, 5.32 ± 0.75 beats per minute is a 96.68% confidence interval estimate of the mean lowering of the heart rate effected by this drug.
From Table A, these z-scores give probabilities of 0.0166 and 0.9834, respectively, so our answer is 0.9834 – 0.0166 = 0.9668. In other words, 5.32 ± 0.75 beats per minute is a 96.68% confidence interval estimate of the mean lowering of the heart rate effected by this drug.
Remember, when is unknown (which is almost always the case), we use the t-distribution instead of the z-distribution. This follows if the parent population is normal (or at least nearly normal, which we can roughly check using a dotplot, stemplot, boxplot, histogram, or normal probability plot of the sample data), or if the sample size is large enough for the central limit theorem to apply. If we are not given that the parent population is normal, then for small samples (n ≤ 15) the sample data should be unimodal and symmetric with no outliers and no skewness; for medium samples (15 < n < 40) the sample data should be unimodal and reasonably symmetric with no extreme values and little, if any, skewness; while for large samples (n 40) the t-methods can be used no matter what the sample data show.
TIP
Understand that you are not trying to prove that the sample data are normal, but rather trying to infer something about the parent population.
EXAMPLE 13.13
When a random sample of 10 cars of a new model were tested for gas mileage, the results showed a mean of 27.2 miles per gallon with a standard deviation of 1.8 miles per gallon. What is a 95% confidence interval estimate for the gas mileage achieved by this model? (Assume that the population of mpg results for all the new model cars is approximately normally distributed.)
Answer: The sample is given to be random, 10 cars should be less than 10% of all cars of the new model, the population is approximately normal so the distribution of sample means is approximately normal, and a t-interval may be found. Calculator software (such as TInterval on the TI-84) gives (25.912, 28.488). [For instructional purposes we note that the standard deviation of the sample means is  = 0.569. With 10 – 1 = 9 degrees of freedom and 2.5% in each tail, the appropriate t-scores are ±2.262 (from Table B or InvT on the TI-84). Then 27 ± 2.262(0.569) = 27.2 ± 1.3.] We are 95% confident that the gas mileage of the new model is between 25.9 and 28.5 miles per gallon.
= 0.569. With 10 – 1 = 9 degrees of freedom and 2.5% in each tail, the appropriate t-scores are ±2.262 (from Table B or InvT on the TI-84). Then 27 ± 2.262(0.569) = 27.2 ± 1.3.] We are 95% confident that the gas mileage of the new model is between 25.9 and 28.5 miles per gallon.
EXAMPLE 13.14
A new process for producing synthetic gems yielded six randomly selected stones weighing 0.43, 0.52, 0.46, 0.49, 0.60, and 0.56 carats, respectively, in its first run. Find a 90% confidence interval estimate for the mean carat weight from this process. (Assume that the population of carats of all gems produced by this new process is approximately normally distributed.)
Answer: The sample is given to be random, six stones is assumed to be less than 10% of all stones produced by this process, the population is approximately normal so the distribution of sample means is approximately normal, and a t-interval may be found. Calculator software (such as TInterval on the TI-84 with the data put in a List) gives (0.45797, 0.56203). [For instructional purposes, we note that

With df = 6 – 1 = 5 and 5% in each tail, the t-scores are ±2.015 (from Table B or InvT on the TI-84). Then 0.51 ± 2.015(0.0258) = 0.51 ± 0.052.] We are 90% confident that the mean carat weight for all stones produced by this procedure is between 0.458 and 0.562 carats.
On the TI-Nspire the result shows as:

TIP
Read the question carefully! Be sure you understand exactly what you are being asked to do or find or explain.
EXAMPLE 13.15
A survey was conducted involving 250 out of 125,000 families living in a city. The average amount of income tax paid per family in the sample was $3540 with a standard deviation of $1150. Establish a 99% confidence interval estimate for the total taxes paid by all the families in the city. (Assume that the population of all income taxes paid is approximately normally distributed.)
Answer: We are given x = 3540 and s = 1150. We use s as an estimate for s and calculate the standard deviation of the sample means to be 
Since is unknown, we use a t-distribution. In this case we obtain 3540 ± 2.596(72.73) = 3540 ± 188.8 and then 125,000(3540 ± 188.8) = 442,500,000 ± 23,600,000. That is, we are 99% confident that the total tax paid by all families in the city is between $418,900,000 and $466,100,000.
Statistical principles are useful not only in analyzing data but also in setting up experiments, and one important consideration is the choice of a sample size. In making interval estimates of population means, we have seen that each inference must go hand in hand with an associated confidence level statement. Generally, if we want a smaller, more precise interval estimate, we either decrease the degree of confidence or increase the sample size. Similarly, if we want to increase the degree of confidence, we either accept a wider interval estimate or increase the sample size. Thus, choosing a larger sample size always seems desirable; in the real world, however, time and cost considerations are involved.
EXAMPLE 13.16
Ball bearings are manufactured by a process that results in a standard deviation in diameter of 0.025 inch. What sample size should be chosen if we wish to be 99% sure of knowing the diameter to within ±0.01 inch?
Answer: We have

Thus

Algebraically, we find that

so n 41.5. We choose a sample size of 42.
A formula for the above calculation is

(Note: This formula is not given on the AP Exam formula page.)
Note that we can obtain a better estimate by recalculating using a t-score obtained from df = n – 1 where n is the value obtained from using the z-score. For example, in the above problem, a 99% confidence interval with df = 42 – 1 = 41 gives t = ±2.701. Then 2.701  results in n = 46.
results in n = 46.
TIP
Understand that you use a critical z-value here because to use a t-value you would need to know df, which is unknown without starting with a sample size.
CONFIDENCE INTERVAL FOR A DIFFERENCE BETWEEN TWO MEANS
We have the following information about the sampling distribution of x1 – x2:
1. The set of all differences of sample means is approximately normally distributed.
2. The mean of the set of differences of sample means equals µ1 – µ2, the difference of population means.
3. The standard deviation x1–x2 of the set of differences of sample means is approximately equal to 
In making calculations and drawing conclusions from specific samples, it is important both that the samples be simple random samples and that they be taken independently of each other.
EXAMPLE 13.17
A 30-month study is conducted to determine the difference in the numbers of accidents per month occurring in two departments in an assembly plant. Suppose the first department averages 12.3 accidents per month with a standard deviation of 3.5, while the second averages 7.6 accidents with a standard deviation of 3.4. Determine a 95% confidence interval estimate for the difference in the numbers of accidents per month. (Assume that the two populations are independent and approximately normally distributed.)
Answer: We are not given that the sample is random so must assume that the 30 months are representative. We are given that the two populations are independent and approximately normal, so the distributions of sample means are approximately normal, and a t-interval may be found. Calculator software (such as 2-SampTInt on the TI-84) gives (2.9167, 6.4833). [For instructional purposes we note

The observed difference is 12.3 – 7.6 = 4.7, and with df = (n1 – 1) + (n2 – 1) = 58, the critical t-scores are ±2.00. Thus the confidence interval estimate is 4.7 ± 2.00(0.89) = 4.7 ± 1.78.]
We are 95% confident that the first department has between 2.92 and 6.48 more accidents per month than the second department.
EXAMPLE 13.18
A hardware store owner wishes to determine the difference between the drying times of two brands of paint. Suppose the standard deviation between cans in each population is 2.5 minutes. How large a sample (same number) of each must the store owner use if he wishes to be 98% sure of knowing the difference to within 1 minute?
Answer:

With a critical z-score of 2.326, we have 2.326  Thus the owner should test samples of 68 paint patches from each brand.
Thus the owner should test samples of 68 paint patches from each brand.
In the case of independent samples, there is also a procedure based on the assumption that both original populations not only are normally distributed but also have equal variances. Then we can get a better estimate of the common population variance by pooling the two sample variances. But it’s never wrong not to pool.
The analysis and procedure discussed in this section require that the two samples being compared be independent of each other. However, many experiments and tests involve comparing two populations for which the data naturally occur in pairs. In this case of paired differences, the proper procedure is to run a one-sample analysis on the single variable consisting of the differences from the paired data.
EXAMPLE 13.19
An SAT preparation class of 30 randomly selected students produces the following improvement in scores:
Student | First Score | Second Score | Improvement |
1 | 912 | 1025 | 113 |
2 | 1025 | 1085 | 60 |
3 | 1295 | 1350 | 55 |
4 | 1123 | 1202 | 79 |
5 | 875 | 982 | 107 |
6 | 890 | 950 | 60 |
7 | 1002 | 1089 | 87 |
8 | 998 | 1159 | 161 |
9 | 1235 | 1246 | 11 |
10 | 1045 | 1135 | 90 |
11 | 956 | 1005 | 49 |
12 | 987 | 1010 | 23 |
13 | 1028 | 1015 | –13 |
14 | 954 | 1032 | 78 |
15 | 1152 | 1310 | 158 |
16 | 1215 | 1302 | 87 |
17 | 948 | 1010 | 62 |
18 | 1190 | 1235 | 45 |
19 | 1077 | 1103 | 26 |
20 | 1223 | 1200 | –23 |
21 | 1100 | 1187 | 87 |
22 | 842 | 910 | 68 |
23 | 985 | 1049 | 64 |
24 | 1107 | 1123 | 16 |
25 | 847 | 901 | 54 |
26 | 987 | 1086 | 99 |
27 | 1228 | 1276 | 48 |
28 | 1005 | 1029 | 24 |
29 | 1166 | 1221 | 55 |
30 | 808 | 874 | 66 |
Find a 90% confidence interval estimate of the average improvement in test scores.
Answer: We are given a random sample, and n = 30 is large enough so that by the CLT the distribution of sample means is approximately normal and a t-interval may be found. Putting the data (Improvement) into a List, calculator software (such as T-Interval on the TI-84) gives (50.206, 76.194). We are 90% confident that the average improvement in test scores is between 50.2 and 76.2.
When to do a two-sample analysis versus a matched pair analysis can be confusing. The key idea is whether or not the two groups are independent. The difference has to do with design. What is the average reaction time of people who are sober compared to that of people who have had two beers? If our experimental design calls for randomly assigning half of a group of volunteers to drink two beers and then comparing reaction times with the remaining sober volunteers, then a two-sample analysis is called for. However, if our experimental design calls for testing reaction times of all the volunteers and then giving all the volunteers two beers and retesting, then a matched pair analysis is called for. Matching may come about as above because you have made two measurements on the same person, or measurements might be made on sets of twins, or between salaries of president and provost at a number of universities, etc. The key is whether the two sets of measurements are independent, or related in some way relevant to the question under consideration.
TIP
Note the similarities between b1 ± t∗SE(b1), ± z∗SE(), and x ± t∗SE(x).
CONFIDENCE INTERVAL FOR THE SLOPE OF A LEAST SQUARES REGRESSION LINE
In Topic 4 we discussed the least squares line
 = y + b1 (x – x)
= y + b1 (x – x)
where b1 is the slope of the line. This slope is readily found using the statistical software on a calculator. It is an estimate of the slope  of the true regression line. A confidence interval estimate for can be found using t-scores, where df = n – 2, and the appropriate standard deviation, the standard error of the slope, written sb1 or SE(b1), is
of the true regression line. A confidence interval estimate for can be found using t-scores, where df = n – 2, and the appropriate standard deviation, the standard error of the slope, written sb1 or SE(b1), is

where the sum in the numerator is the sum of the squared residuals (see Topic 4) and the sum in the denominator is the sum of the squared deviations from the mean. The value of sb1 is found at the same time that the statistical software on your calculator finds the value of b1. Some calculators calculate the numerator  and then the denominator can be calculated by
and then the denominator can be calculated by 
Assumptions here include: (1) the sample must be randomly selected; (2) the scatterplot should be approximately linear; (3) there should be no apparent pattern in the residuals plot (On the TI-84, after Stat  Calc LinReg, the list of residuals is stored in RESID under LIST NAMES); and (4) the distribution of the residuals should be approximately normal. (The fourth point can be checked by a histogram, dotplot, stemplot, or a normal probability plot of the residuals.)
Calc LinReg, the list of residuals is stored in RESID under LIST NAMES); and (4) the distribution of the residuals should be approximately normal. (The fourth point can be checked by a histogram, dotplot, stemplot, or a normal probability plot of the residuals.)
TIP
If you refer to a graph, whether it is a histogram, boxplot, stemplot, scatterplot, residuals plot, normal probability plot, or some other kind of graph, you should roughly draw it. It is not enough to simply say, “I did a normal probability plot of the residuals on my calculator and it looked linear.”
EXAMPLE 13.20
A random sample of ten high school students produced the following results for number of hours of television watched per week and GPA.
TV hours | 12 | 21 | 8 | 20 | 16 | 16 | 24 | 0 | 11 | 18 |
GPA | 3.1 | 2.3 | 3.5 | 2.5 | 3.0 | 2.6 | 2.1 | 3.8 | 2.9 | 2.6 |
Determine the least squares line and give a 95% confidence interval estimate for the true slope.
Answer: Checking the assumptions:
We are told that the data come from a random sample of students.

Now using the statistics software on a calculator gives
= 3.892 – 0.07202x
Putting the data into two Lists and using calculator software (such as LinRegTInt on the TI-84) gives (–0.0887, –0.0554).
We are thus 95% confident that each additional hour before the television each week is associated with between a 0.055 and a 0.089 drop in GPA.
On the TI-Nspire one can show the following:

Remember we must be careful about drawing conclusions concerning cause and effect; it is possible that students who have lower GPAs would have these averages no matter how much television they watched per week.
Note that  called the standard deviation of the residuals, is sometimes written se. It is a measure of the spread about the regression line, and is almost always in the regression output (usually simply labeled as s or S). Note that sb1 is sometimes written SE(b1) and is also referred to as the standard error of the slope. So we can also write
called the standard deviation of the residuals, is sometimes written se. It is a measure of the spread about the regression line, and is almost always in the regression output (usually simply labeled as s or S). Note that sb1 is sometimes written SE(b1) and is also referred to as the standard error of the slope. So we can also write  We see that increasing se (that is, increasing spread about the line) increases the slope’s standard error, while increasing sx (that is, increasing the range of x-values) or increasing n (the sample size) decreases the slope’s standard error.
We see that increasing se (that is, increasing spread about the line) increases the slope’s standard error, while increasing sx (that is, increasing the range of x-values) or increasing n (the sample size) decreases the slope’s standard error.
TIP
Practice how to read generic computer output, and note that you usually will not need to use all the information given.
EXAMPLE 13.21
Information concerning SAT verbal scores and SAT math scores was collected from 15 randomly selected subjects. A linear regression performed on the data using a statistical software package produced the following printout:
Dependent variable: Math
Variable | Coef | SE Coef | T | Prob |
Constant | 92.5724 | 31.75 | 2.92 | 0.012 |
Verbal | 0.763604 | 0.05597 | 13.6 | 0.000 |
S = 16.69 | R–Sq = 93.5% | R–Sq(adj) = 93.0% |
|
|

What is the regression equation?
Answer: Assuming that all assumptions for regression are met (we are given that the sample is random, and the scatterplot is approximately linear), the y-intercept and slope of the equation are found in the Coef column of the above printout.

What is a 95% confidence interval estimate for the slope of the regression line?
Answer: The standard deviation of the residuals is S = 16.69 and the standard error of the slope is Sb1 = 0.05597. With 15 data points, df = 15 – 2 = 13, and the critical t-values are ±2.160. The 95% confidence interval of the true slope is:
b1 ± t sb1 = 0.764 ± 2.160(0.05597) = 0.764 ± 0.121
We are 95% confident that for every 1-point increase in verbal SAT score, the average increase in math SAT score is between 0.64 and 0.89.
SUMMARY
 Important assumptions/conditions always must be checked before calculating confidence intervals.
Important assumptions/conditions always must be checked before calculating confidence intervals.
We are never able to say exactly what a population parameter is; rather, we say that we have a certain confidence that it lies in a certain interval.
If we want a narrower interval, we must either decrease the confidence level or increase the sample size.
If we want a higher level of confidence, we must either accept a wider interval or increase the sample size.
The level of confidence refers to the percentage of samples that produce intervals that capture the true population parameter.
QUESTIONS ON TOPIC THIRTEEN: CONFIDENCE INTERVALS
Multiple-Choice Questions
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. Changing from a 95% confidence interval estimate for a population proportion to a 99% confidence interval estimate, with all other things being equal,
(A) increases the interval size by 4%.
(B) decreases the interval size by 4%.
(C) increases the interval size by 31%.
(D) decreases the interval size by 31%.
(E) This question cannot be answered without knowing the sample size.
2. In general, how does doubling the sample size change the confidence interval size?
(A) Doubles the interval size
(B) Halves the interval size
(C) Multiplies the interval size by 1.414
(D) Divides the interval size by 1.414
(E) This question cannot be answered without knowing the sample size.
3. A confidence interval estimate is determined from the GPAs of a simple random sample of n students. All other things being equal, which of the following will result in a smaller margin of error?
(A) A smaller confidence level
(B) A larger sample standard deviation
(C) A smaller sample size
(D) A larger population size
(E) A smaller sample mean
4. A survey was conducted to determine the percentage of high school students who planned to go to college. The results were stated as 82% with a margin of error of ±5%. What is meant by ±5%?
(A) Five percent of the population were not surveyed.
(B) In the sample, the percentage of students who plan to go to college was between 77% and 87%.
(C) The percentage of the entire population of students who plan to go to college is between 77% and 87%.
(D) It is unlikely that the given sample proportion result would be obtained unless the true percentage was between 77% and 87%.
(E) Between 77% and 87% of the population were surveyed.
5. Most recent tests and calculations estimate at the 95% confidence level that the maternal ancestor to all living humans called mitochondrial Eve lived 273,000 ±177,000 years ago. What is meant by “95% confidence” in this context?
(A) A confidence interval of the true age of mitochondrial Eve has been calculated using z-scores of ±1.96.
(B) A confidence interval of the true age of mitochondrial Eve has been calculated using t-scores consistent with df = n – 1 and tail probabilities of ±.025.
(C) There is a .95 probability that mitochondrial Eve lived between 96,000 and 450,000 years ago.
(D) If 20 random samples of data are obtained by this method, and a 95% confidence interval is calculated from each, then the true age of mitochondrial Eve will be in 19 of these intervals.
(E) 95% of all random samples of data obtained by this method will yield intervals that capture the true age of mitochondrial Eve.
6. One month the actual unemployment rate in France was 13.4%. If during that month you took an SRS of 100 Frenchmen and constructed a confidence interval estimate of the unemployment rate, which of the following would have been true?
(A) The center of the interval was 13.4.
(B) The interval contained 13.4.
(C) A 99% confidence interval estimate contained 13.4.
(D) The z-score of 13.4 was between ±2.576.
(E) None of the above are true statements.
7. In a recent Zogby International survey, 11% of 10,000 Americans under 50 said they would be willing to implant a device in their brain to be connected to the Internet if it could be done safely. What is the margin of error at the 99% confidence level?
(A) 
(B) 
(C) 
(D) 
(E) 
8. The margin of error in a confidence interval estimate using z-scores covers which of the following?
(A) Sampling variability
(B) Errors due to undercoverage and nonresponse in obtaining sample surveys
(C) Errors due to using sample standard deviations as estimates for population standard deviations
(D) Type I errors
(E) Type II errors
9. In an SRS of 50 teenagers, two-thirds said they would rather text a friend than call. What is the 98% confidence interval for the proportion of teens who would rather text than call a friend?
(A) 
(B) 
(C) 
(D) 
(E) 
10. In a survey funded by Burroughs-Welcome, 750 of 1000 adult Americans said they didn’t believe they could come down with a sexually transmitted disease (STD). Construct a 95% confidence interval estimate of the proportion of adult Americans who don’t believe they can contract an STD.
(A) (0.728, 0.772)
(B) (0.723, 0.777)
(C) (0.718, 0.782)
(D) (0.713, 0.787)
(E) (0.665, 0.835)
11. A 1993 Los Angeles Times poll of 1703 adults revealed that only 17% thought the media was doing a “very good” job. With what degree of confidence can the newspaper say that 17% ± 2% of adults believe the media is doing a “very good” job?
(A) 72.9%
(B) 90.0%
(C) 95.0%
(D) 97.2%
(E) 98.6%
12. A politician wants to know what percentage of the voters support her position on the issue of forced busing for integration. What size voter sample should be obtained to determine with 90% confidence the support level to within 4%?
(A) 21
(B) 25
(C) 423
(D) 600
(E) 1691
13. In a New York Times poll measuring a candidate’s popularity, the newspaper claimed that in 19 of 20 cases its poll results should be no more than three percentage points off in either direction. What confidence level are the pollsters working with, and what size sample should they have obtained?
(A) 3%, 20
(B) 6%, 20
(C) 6%, 100
(D) 95%, 33
(E) 95%, 1068
14. In an SRS of 80 teenagers, the average number of texts handled in a day was 50 with a standard deviation of 15. What is the 96% confidence interval for the average number of texts handled by teens daily?
(A) 50 ± 2.054(15)
(B) 
(C) 
(D) 
(E) 
15. One gallon of gasoline is put in each of 30 test autos, and the resulting mileage figures are tabulated with x = 28.5 and s = 1.2. Determine a 95% confidence interval estimate of the mean mileage.
(A) (28.46, 28.54)
(B) (28.42, 28.58)
(C) (28.1, 28.9)
(D) (27.36, 29.64)
(E) (27.3, 29.7)
16. The number of accidents per day at a large factory is noted for each of 64 days with x = 3.58 and s = 1.52. With what degree of confidence can we assert that the mean number of accidents per day at the factory is between 3.20 and 3.96?
(A) 48%
(B) 63%
(C) 90%
(D) 95%
(E) 99%
17. A company owns 335 trucks. For an SRS of 30 of these trucks, the average yearly road tax paid is $9540 with a standard deviation of $1205. What is a 99% confidence interval estimate for the total yearly road taxes paid for the 335 trucks?
(A) $9540 ± $103
(B) $9540 ± $567
(C) $3,196,000 ± $606
(D) $3,196,000 ± $35,000
(E) $3,196,000 ± $203,000
18. What sample size should be chosen to find the mean number of absences per month for school children to within ±0.2 at a 95% confidence level if it is known that the standard deviation is 1.1?
(A) 11
(B) 29
(C) 82
(D) 96
(E) 117
19. Hospital administrators wish to learn the average length of stay of all surgical patients. A statistician determines that, for a 95% confidence level estimate of the average length of stay to within ±0.5 days, 50 surgical patients’ records will have to be examined. How many records should be looked at to obtain a 95% confidence level estimate to within ±0.25 days?
(A) 25
(B) 50
(C) 100
(D) 150
(E) 200
20. The National Research Council of the Philippines reported that 210 of 361 members in biology are women, but only 34 of 86 members in mathematics are women. Establish a 95% confidence interval estimate of the difference in proportions of women in biology and women in mathematics in the Philippines.
(A) 0.187 ± 0.115
(B) 0.187 ± 0.154
(C) 0.395 ± 0.103
(D) 0.543 ± 0.154
(E) 0.582 ± 0.051
21. In a simple random sample of 300 elderly men, 65% were married, while in an independent simple random sample of 400 elderly women, 48% were married. Determine a 99% confidence interval estimate for the difference between the proportions of elderly men and women who are married.
(A) 
(B) 
(C) 
(D) 
(E) 
22. A researcher plans to investigate the difference between the proportion of psychiatrists and the proportion of psychologists who believe that most emotional problems have their root causes in childhood. How large a sample should be taken (same number for each group) to be 90% certain of knowing the difference to within ±0.03?
(A) 39
(B) 376
(C) 752
(D) 1504
(E) 3007
23. In a study aimed at reducing developmental problems in low-birth-weight (under 2500 grams) babies (Journal of the American Medical Association, June 13, 1990, page 3040), 347 infants were exposed to a special educational curriculum while 561 did not receive any special help. After 3 years the children exposed to the special curriculum showed a mean IQ of 93.5 with a standard deviation of 19.1; the other children had a mean IQ of 84.5 with a standard deviation of 19.9. Find a 95% confidence interval estimate for the difference in mean IQs of low-birth-weight babies who receive special intervention and those who do not.
(A) 
(B) 
(C) 
(D) 
(E) 
24. Does socioeconomic status relate to age at time of HIV infection? For 274 high-income HIV-positive individuals the average age of infection was 33.0 years with a standard deviation of 6.3, while for 90 low-income individuals the average age was 28.6 years with a standard deviation of 6.3 (The Lancet, October 22, 1994, page 1121). Find a 90% confidence interval estimate for the difference in ages of high- and low-income people at the time of HIV infection.
(A) 4.4 ± 0.963
(B) 4.4 ± 1.27
(C) 4.4 ± 2.51
(D) 30.8 ± 2.51
(E) 30.8 ± 6.3
25. An engineer wishes to determine the difference in life expectancies of two brands of batteries. Suppose the standard deviation of each brand is 4.5 hours. How large a sample (same number) of each type of battery should be taken if the engineer wishes to be 90% certain of knowing the difference in life expectancies to within 1 hour?
(A) 10
(B) 55
(C) 110
(D) 156
(E) 202
26. Two confidence interval estimates from the same sample are (16.4, 29.8) and (14.3, 31.9). What is the sample mean, and if one estimate is at the 95% level while the other is at the 99% level, which is which?
(A) x = 23.1; (16.4, 29.8) is the 95% level.
(B) x = 23.1; (16.4, 29.8) is the 99% level.
(C) It is impossible to completely answer this question without knowing the sample size.
(D) It is impossible to completely answer this question without knowing the sample standard deviation.
(E) It is impossible to completely answer this question without knowing both the sample size and standard deviation.
27. Two 90% confidence interval estimates are obtained: I (28.5, 34.5) and II (30.3, 38.2).
a. If the sample sizes are the same, which has the larger standard deviation?
b. If the sample standard deviations are the same, which has the larger size?
(A) a. Ib. I
(B) a. Ib. II
(C) a. IIb. I
(D) a. IIb. II
(E) More information is needed to answer these questions.
28. Suppose (25, 30) is a 90% confidence interval estimate for a population mean µ. Which of the following are true statements?
(A) There is a 0.90 probability that x is between 25 and 30.
(B) 90% of the sample values are between 25 and 30.
(C) There is a 0.90 probability that µ is between 25 and 30.
(D) If 100 random samples of the given size are picked and a 90% confidence interval estimate is calculated from each, then µ will be in 90 of the resulting intervals.
(E) If 90% confidence intervals are calculated from all possible samples of the given size, µ will be in 90% of these intervals.
29. Under what conditions would it be meaningful to construct a confidence interval estimate when the data consist of the entire population?
(A) If the population size is small (n < 30)
(B) If the population size is large (n 30)
(C) If a higher level of confidence is desired
(D) If the population is truly random
(E) Never
30. A social scientist wishes to determine the difference between the percentage of Los Angeles marriages and the percentage of New York marriages that end in divorce in the first year. How large a sample (same for each group) should be taken to estimate the difference to within ±0.07 at the 94% confidence level?
(A) 181
(B) 361
(C) 722
(D) 1083
(E) 1443
31. What is the critical t-value for finding a 90% confidence interval estimate from a sample of 15 observations?
(A) 1.341
(B) 1.345
(C) 1.350
(D) 1.753
(E) 1.761
32. Acute renal graft rejection can occur years after the graft. In one study (The Lancet, December 24, 1994, page 1737), 21 patients showed such late acute rejection when the ages of their grafts (in years) were 9, 2, 7, 1, 4, 7, 9, 6, 2, 3, 7, 6, 2, 3, 1, 2, 3, 1, 1, 2, and 7, respectively. Establish a 90% confidence interval estimate for the ages of renal grafts that undergo late acute rejection.
(A) 2.024 ± 0.799
(B) 2.024 ± 1.725
(C) 4.048 ± 0.799
(D) 4.048 ± 1.041
(E) 4.048 ± 1.725
33. Nine subjects, 87 to 96 years old, were given 8 weeks of progressive resistance weight training (Journal of the American Medical Association, June 13, 1990, page 3032). Strength before and after training for each individual was measured as maximum weight (in kilograms) lifted by left knee extension:
Before: | 3 | 3.5 | 4 | 6 | 7 | 8 | 8.5 | 12.5 | 15 |
After: | 7 | 17 | 19 | 12 | 19 | 22 | 28 | 20 | 28 |
Find a 95% confidence interval estimate for the strength gain.
(A) 11.61 ± 3.03
(B) 11.61 ± 3.69
(C) 11.61 ± 3.76
(D) 19.11 ± 1.25
(E) 19.11 ± 3.69
34. A catch of five fish of a certain species yielded the following ounces of protein per pound of fish: 3.1, 3.5, 3.2, 2.8, and 3.4. What is a 90% confidence interval estimate for ounces of protein per pound of this species of fish?
(A) 3.2 ± 0.202
(B) 3.2 ± 0.247
(C) 3.2 ± 0.261
(D) 4.0 ± 0.202
(E) 4.0 ± 0.247
35. In a random sample of 25 professional baseball players, their salaries (in millions of dollars) and batting averages result in the following regression analysis:
The regression equation is Batting = 0.234 + 0.00805 Salary
Predictor | Coef | SE Coef | T | P |
Constant | 0.233577 | 0.005883 | 39.70 | 0.000 |
Salary | 0.008051 | 0.001058 | 7.61 | 0.000 |
S = 0.0169461 R-Sq = 71.6% R-Sq(adj) = 70.3%
Which of the following gives a 98% confidence interval for the slope of the regression line?
(A) 0.008051 ± 2.326(0.001058)
(B) 0.008051 ± 2.326(0.0169461)
(C) 
(D) 
(E) 0.008051 ± 2.500(0.001058)
36. Is there a relationship between mishandled-baggage rates (number of mishandled bags per 1000 passengers) and percentage of on-time arrivals? Regression analysis of ten airlines gives the following TI-Nspire output (baggage rate is independent variable):
| We are 95% confident that if an airline averages one more mishandled bag per 1000 passengers than a second airline, then its percentage of on-time arrivals will average |

(A) between 0.15 and 4.19 less than that of the second airline.
(B) between 0.00 and 4.33 less than that of the second airline.
(C) between 4.46 less and 0.13 more than that of the second airline.
(D) between 4.49 less and 0.17 more than that of the second airline.
(E) between 4.54 less and 0.21 more than that of the second airline.
37. Smoking is a known risk factor for cardiovascular and cancer diseases. A recent study (Rusanen et al., Archives of Internal Medicine, October 25, 2010) surveyed 21,123 members of a California health care system looking at smoking levels and risk of dementia (as measured by the Cox hazard ratio). Results are summarized in the following graph of 95% confidence intervals.

Which of the following is an appropriate conclusion?
(A) Dementia somehow causes an urge to smoke.
(B) Heavier smoking leads to a greater risk of dementia.
(C) Cutting down on smoking will lower one’s risk of dementia.
(D) Heavier smoking is associated with more precise confidence intervals of dementia as measured by the hazard ratio.
(E) There is a positive association between smoking and risk of dementia.
Free-Response Questions
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your final answers.
ELEVEN OPEN-ENDED QUESTIONS
1. An SRS of 1000 voters finds that 57% believe that competence is more important than character in voting for President of the United States.
(a) Determine a 95% confidence interval estimate for the percentage of voters who believe competence is more important than character.
(b) If your parents know nothing about statistics, how would you explain to them why you can’t simply say that 57% of voters believe that competence is more important.
(c) Also explain to your parents what is meant by 95% confidence level.
2. During the H1N1 pandemic, one published study concluded that if someone in your family had H1N1, you had a 1 in 8 chance of also coming down with the disease. A state health officer tracks a random sample of new H1N1 cases in her state and notes that 129 out of a potential 876 family members later come down with the disease.
(a) Calculate a 90% confidence interval for the proportion of family members who come down with H1N1 after an initial family member does in this state.
(b) Based on this confidence interval, is there evidence that the proportion of family members who come down with H1N1 after an initial family member does in this state is different from the 1 in 8 chance concluded in the published study? Explain.
(c) Would the conclusion in (b) be any different with a 99% confidence interval? Explain.
3. In a random sample of 500 new births in the United States, 41.2% were to unmarried women, while in a random sample of 400 new births in the United Kingdom, 46.5% were to unmarried women.
(a) Calculate a 95% confidence interval for the difference in the proportions of new births to unmarried women in the United States and United Kingdom.
(b) Does the confidence interval support the belief by a UN health care statistician that the proportions of new births to unmarried women is different in the United States and United Kingdom? Explain.
4. An SRS of 40 inner city gas stations shows a mean price for regular unleaded gasoline to be $3.45 with a standard deviation of $0.05, while an SRS of 120 suburban stations shows a mean of $3.38 with a standard deviation of $0.08.
(a) Construct 95% confidence interval estimates for the mean price of regular gas in inner city and in suburban stations.
(b) The confidence interval for the inner city stations is wider than the interval for the suburban stations even though the standard deviation for inner city stations is less than that for suburban stations. Explain why this happened.
(c) Based on your answer in part (a), are you confident that the mean price of inner city gasoline is less than $3.50? Explain.
5. In a simple random sample of 30 subway cars during rush hour, the average number of riders per car was 83.5 with a standard deviation of 5.9. Assume the sample data are unimodal and reasonably symmetric with no extreme values and little, if any, skewness.
(a) Establish a 90% confidence interval estimate for the average number of riders per car during rush hour. Show your work.
(b) Assuming the same standard deviation of 5.9, how large a sample of cars would be necessary to determine the average number of riders to within ±1 at the 90% confidence level? Show your work.
6. In a sample of ten basketball players the mean income was $196,000 with a standard deviation of $315,000.
(a) Assuming all necessary assumptions are met, find a 95% confidence interval estimate of the mean salary of basketball players.
(b) What assumptions are necessary for the above estimate? Do they seem reasonable here?
7. An SRS of ten brands of breakfast cereals is tested for the number of calories per serving. The following data result: 185, 190, 195, 200, 205, 205, 210, 210, 225, 230.
Establish a 95% confidence interval estimate for the mean number of calories for servings of breakfast cereals. Be sure to check assumptions.
8. Bisphenol A (BPA), a synthetic estrogen found in packaging materials, has been shown to leach into infant formula and beverages. Most recently it has been detected in high concentrations in cash register receipts. Random sample biomonitoring data to see if retail workers carry higher amounts of BPA in their bodies than non-retail workers is as follows:
|
| BPA concentration (µg/L) | |
| Sample size | Mean | Standard deviation |
Non-retail workers | 528 | 2.43 | 0.45 |
Retail workers | 197 | 3.28 | 0.48 |
(a) Calculate a 99% confidence interval for the difference in mean BPA body concentrations of non-retail and retail workers.
(b) Does the confidence interval support the belief that retail workers carry higher amounts of BPA in their bodies than non-retail workers? Explain.
9. A new drug is tested for relief of allergy symptoms. In a double-blind experiment, 12 patients are given varying doses of the drug and report back on the number of hours of relief. The following table summarizes the results:
Dosage (mg) | 2 | 3 | 4 | 4 | 5 | 6 | 6 | 7 | 8 | 8 | 9 | 10 |
Duration of relief (hrs) | 3 | 7 | 6 | 8 | 10 | 8 | 13 | 16 | 15 | 21 | 23 | 24 |
(a) Determine the equation of the least squares regression line.
(b) Construct a 90% confidence interval estimate for the slope of the regression line, and interpret this in context.
10. Information with regard to the assessed values (in $1000) and the selling prices (in $1000) of a random sample of homes sold in an NE market yields the following computer output:
Dependent variable isPrice
R squared = 89.8% R squared (adjusted) = 89.2%
s = 9.508 with 20 – 2 = 18 degrees of freedom
Source | SS | df | MS | F-ratio |
Regression | 14271.2 | 1 | 14271.2 | 158 |
Residual | 1627.31 | 18 | 90.4063 |
|
Variable | Coeff | s.e. of coeff | t-ratio | prob |
Constant | 0.890087 | 16.16 | 0.055 | 0.956 |
Assessed | 1.0292 | 0.08192 | 12.6 | 0.000 |
(a) Determine the equation of the least squares regression line.
(b) Construct a 99% confidence interval estimate for the slope of the regression line, and interpret this in context.
11. In a July 2008 study of 1050 randomly selected smokers, 74% said they would like to give up smoking.
(a) At the 95% confidence level, what is the margin of error?
(b) Explain the meaning of “95% confidence interval” in this example.
(c) Explain the meaning of “95% confidence level” in this example.
(d) Give an example of possible response bias in this example.
(e) If we want instead to be 99% confident, would our confidence interval need to be wider or narrower?
(f) If the sample size were greater, would the margin of error be smaller or greater?
AN INVESTIGATIVE TASK
As of January 1, 2014, Serena Williams had career prize money earnings of $54,380,000 during her 18 year professional career. Among the top active women tennis players, is there a linear relationship between career prize money earnings and years as a pro? Computer output of earnings (millions of $) versus professional years for 10 top active women players are shown below:


Regression Analysis: Earnings versus Pro Years
Predictor | Coef | SE Coef | T | P |
Constant | 2.69 | 10.78 | 0.25 | 0.809 |
Pro Years | 1.6752 | 0.8264 | 2.03 | 0.077 |
S = 10.5317 R-Sq = 33.9% R-Sq(adj) = 25.7%
Analysis of Variance
Source | DF | SS | MS | F | P |
Regression | 1 | 455.8 | 455.8 | 4.11 | 0.077 |
Residual Error | 8 | 887.3 | 110.9 |
|
|
Total | 9 | 1343.1 |
|
|
|
(a) Determine the equation of the least squares regression line.
(b) Comment on the strength of the linear relationship.
(c) Predict the career earnings for Years = 15 and Years = 30 for active women tennis players, and explain your confidence in both of your answers.
(d) Find the 90% confidence interval for the slope of the regression line, and interpret in context.
(e) Assuming all conditions for inference are met, and using a t-distribution with df = n – 2, find the 90% confidence interval for the y-intercept, and if appropriate, interpret in context. Explain.
(f) A second linear model is found: = 1.8712(Years). Explain why you might prefer this model to the one in (a).
1 Note that we cannot say there is a 0.99 probability that the population proportion is within 2.576 standard deviations of a given sample proportion. For a given sample proportion, the population proportion either is or isn’t within the specified interval, and so the probability is either 1 or 0.
DEFINITION
FOR A PROPORTION
FOR A DIFFERENCE OF TWO PROPORTIONS
FOR A MEAN
FOR A DIFFERENCE BETWEEN TWO MEANS
FOR THE SLOPE OF A LEAST SQUARES REGRESSION LINE
Using a measurement from a sample, we are never able to say exactly what a population proportion or mean is; rather we always say we have a certain confidence that the population proportion or mean lies in a particular interval. The particular interval is centered around a sample proportion or mean (or other statistic) and can be expressed as the sample estimate plus or minus an associated margin of error.
THE MEANING OF A CONFIDENCE INTERVAL
Using what we know about sampling distributions, we are able to establish a certain confidence that a sample proportion or mean lies within a specified interval around the population proportion or mean. However, we then have the same confidence that the population proportion or mean lies within a specified interval around the sample proportion or mean (e.g., the distance from Missoula to Whitefish is the same as the distance from Whitefish to Missoula).
Typically we consider 90%, 95%, and 99% confidence interval estimates, but any percentage is possible. The percentage is the percentage of samples that would pinpoint the unknown p or µ within plus or minus a certain margin or error. We do not say there is a 0.90, 0.95, or 0.99 probability that p or µ is within a certain margin of error of a given sample proportion or mean. For a given sample proportion or mean, p or µ either is or isn’t within the specified interval, and so the probability is either 1 or 0.
As will be seen, there are two aspects to this concept. First, there is the confidence interval, usually expressed in the form:
estimate ± margin of error
Second, there is the success rate for the method, that is, the proportion of times repeated applications of this method would capture the true population parameter.
CONFIDENCE INTERVAL FOR A PROPORTION
We are interested in estimating a population proportion p by considering a single sample proportion $\widehat{p}$. This sample proportion is just one of a whole universe of sample proportions, and from Topic 12 we remember the following:
1. The set of all sample proportions is approximately normally distributed.
2. The mean $\mu_\widehat{p}$ of the set of sample proportions equals p, the population proportion.
3. The standard deviation $\sigma_\widehat{p}$ of the set of sample proportions is approximately equal to $\sqrt{\frac{p(1-p)}{n}}$.
In finding confidence interval estimates of the population proportion p, how do we find $\sqrt{\frac{p(1-p)}{n}}$ since p is unknown? The reasonable procedure is to use the sample proportion $\widehat{p}$:
$\sigma_\widehat{p}=\sqrt{\frac{\widehat{p}(1-\widehat{p})}{n}}$
When the standard deviation is estimated in this way (using the sample), we use the term standard error. That is,
![]()
Remember that we are really using a normal approximation to the binomial, so n$\widehat{p}$ and n(1 – $\widehat{p}$) should both be at least 10. Furthermore, in making calculations and drawing conclusions from a specific sample, it is important that the sample be a simple random sample. Finally, the population should be large, typically checked by the assumption that the sample is less than 10% of the population. (If the population is small and the sample exceeds 10% of the population, then models other than the normal are more appropriate.)
EXAMPLE 13.1
IMPORTANT
Verifying assumptions and conditions means more than simply listing them with little check marks. You must show work or give some reason to confirm verification.
If 64% of an SRS of 550 people leaving a shopping mall claim to have spent over \$25, determine a 99% confidence interval estimate for the proportion of shopping mall customers who spend over \$25.
Answer: We check that n$\widehat{p}$ = 550(0.64) = 352 $\geq$ 10 and n(1 – $\widehat{p}$) = 550(0.36) = 198 $\geq$ 10, we are given that the sample is an SRS, and it is reasonable to assume that 550 is less than 10% of all mall shoppers. Since $\widehat{p}$ = 0.64, the standard deviation of the set of sample proportions is
![]()
From Topic 11 we know that 99% of the sample proportions should be within 2.576 standard deviations of the population proportion. Equivalently, we are 99% certain that the population proportion is within 2.576 standard deviations of any sample proportion.1 Thus the 99% confidence interval estimate for the population proportion is 0.64 ± 2.576(0.0205) = 0.64 ± 0.053. We say that the margin of error is ±0.053. We are 99% certain that the proportion of shoppers spending over $25 is between 0.587 and 0.693.
We can also say, using the definition of confidence level, that if the interviewing procedure were repeated many times, about 99% of the resulting confidence intervals would contain the true proportion (thus we’re 99% confident that the method worked for the interval we got).1
TIP
The margin of error accounts for variation inherent in sampling, but it does not account for and is not a redress for bias in sampling.
EXAMPLE 13.2
In a simple random sample of machine parts, 18 out of 225 were found to have been damaged in shipment. Establish a 95% confidence interval estimate for the proportion of machine parts that are damaged in shipment.
TIP
After finding a confidence interval, you must always interpret the interval in context.
Answer: We check that n$\widehat{p}$ = 18 $\geq$ 10 and n(1 – $\widehat{p}$) = 225 – 18 = 207 $\geq$ 10, we are given that the sample is an SRS, and it is reasonable to assume that 225 is less than 10% of all shipped machine parts.
Calculator software (such as 1-PropZInt on the TI-84) gives (0.04455,0.11545).
[For instructional purposes in this review book, we note that ![]()
Thus we are 95% certain that the proportion of machine parts damaged in shipment is between 0.045 and 0.115.
On the TI-Nspire the result shows as:

Suppose there are 50,000 parts in the entire shipment. We can translate from proportions to actual numbers:
0.045(50,000) = 2250 and 0.115(50,000) = 5750
and so we can be 95% confident that there are between 2250 and 5750 defective parts in the whole shipment.
TIP
On the TI-84, for a confidence interval of a proportion, use 1-PropZInt, not Zinterval; and x must be an integer.
TIP
Finding confidence intervals using formulas is not necessary on free-response questions, but answer choices using formulas may well appear on multiple-choice questions.
EXAMPLE 13.3
A telephone survey of 1000 adults was taken shortly after the United States began bombing Iraq.
a. If 832 voiced their support for this action, with what confidence can it be asserted that 83.2% ± 3% of the adult U.S. population supported the decision to go to war?
Answer: We check that n$\widehat{p}$ = 832 $\geq$ 10 and n(1 – $\widehat{p}$) = 1000 – 832 = 168 $\geq$ 10, we assume an SRS, and clearly 1000 is <10% of the adult U.S. population.
![]()
The relevant z-scores are ![]()
In other words, 83.2% ± 3% is a 98.89% confidence interval estimate for U.S. adult support of the war decision.
b. If the adult U.S. population is 191 million, estimate the actual numerical support.
Answer: Since
0.802(191,000,000) ≈ 153,000,000
while
0.862(191,000,000) ≈ 165,000,000
we can be 98.90% confident that between 153 and 165 million adults supported the initial bombing decision.
EXAMPLE 13.4
A U.S. Department of Labor survey of 6230 unemployed adults classified people by marital status, gender, and race. The raw numbers are as follows:
a. Find a 90% confidence interval estimate for the proportion of unemployed men who are married.
Answer: Totaling the first row across both tables, we find that there are 3499 men in the survey; 1090 + 266 = 1356 of them are married. We check that n$\widehat{p}$ = 1356 $\geq$ 10 and n(1 – $\widehat{p}$) = 3499 – 1356 = 2143 $\geq$ 10, we assume an SRS, and clearly the sample is <10% of the total unemployed adult population. On the TI-84, 1-PropZInt gives (0.37399, 0.40109). [For instructional purposes we note that ![]() Thus the 90% confidence interval estimate is 0.3875 ± 1.645(0.008236) = 0.3875 ± 0.0135.] We are 90% confident that the true proportion of unemployed men who are married is between 0.374 and 0.401.
Thus the 90% confidence interval estimate is 0.3875 ± 1.645(0.008236) = 0.3875 ± 0.0135.] We are 90% confident that the true proportion of unemployed men who are married is between 0.374 and 0.401.
b. Find a 98% confidence interval estimate of the proportion of unemployed single persons who are women.
Answer: There are 1168 + 632 + 503 + 349 = 2652 singles in the survey. Of these, 632 + 349 = 981 are women [n$\widehat{p}$ = 981 $\geq$ 10 and n(1 – $\widehat{p}$) = 2652 – 981 = 1671 $\geq$ 10]. On the TI-84, 1-PropZInt gives (0.3481, 0.39172).
[For instructional purposes we note that ![]()
![]()
The 98% confidence interval estimate is 0.3699 ± 2.326(0.009375) = 0.3699 ± 0.0218.] We are 98% confident that the true proportion of unemployed single persons who are women is between 0.348 and 0.392.
As we have seen, there are two types of statements that come out of confidence intervals. First, we can interpret the confidence interval and say we are 90% confident that between 60% and 66% of all voters favor a bond issue. Second, we can interpret the confidence level and say that if this survey were conducted many times, then about 90% of the resulting confidence intervals would contain the true proportion of voters who favor the bond issue.
Incorrect statements include “The percentage of all voters who support the bond issue is between 60% and 66%,” “There is a 0.90 probability that the true percentage of all voters who favor the bond issue is between 60% and 66%,” and “If this survey were conducted many times, then about 90% of the sample proportions would be in the interval (0.60, 0.66).”
One important consideration in setting up a survey is the choice of sample size. To obtain a smaller, more precise interval estimate of the population proportion, we must either decrease the degree of confidence or increase the sample size. Similarly, if we want to increase the degree of confidence, we can either accept a wider interval estimate or increase the sample size. Again, while choosing a larger sample size may seem desirable, in the real world this decision involves time and cost considerations.
In setting up a survey to obtain a confidence interval estimate of the population proportion, what should we use for $\sigma_\widehat{p}$? To answer this question, we first must consider how large $\sqrt{p(1-p)}$ can be. We plot various values of p:
![]()
which gives 0.5 as the intuitive answer. Thus ![]() We make use of this fact to determine sample sizes in problems such as Examples 13.5 and 13.6.
We make use of this fact to determine sample sizes in problems such as Examples 13.5 and 13.6.
TIP
Noting the inequality, the result must be rounded up if it is a decimal.
EXAMPLE 13.5
An Environmental Protection Agency (EPA) investigator wants to know the proportion of fish that are inedible because of chemical pollution downstream of an offending factory. If the answer must be within ±0.03 at the 96% confidence level, how many fish should be in the sample tested?
Answer: We want 2.05$\sigma_\widehat{p}\leq$ 0.03. From the above remark, $\sigma_\widehat{p}$ is at most $\frac{0.5}{\sqrt{n}}$ and so it is sufficient to consider 2.05![]() Algebraically, we have
Algebraically, we have ![]() and n $\geq$ 1167.4. Therefore, choosing a sample of 1168 fish gives the inedible proportion to within ±0.03 at the 96% level.
and n $\geq$ 1167.4. Therefore, choosing a sample of 1168 fish gives the inedible proportion to within ±0.03 at the 96% level.
Note that the accuracy of the estimate does not depend on what fraction of the whole population we have sampled. What is critical is the absolute size of the sample. Is some minimal value of n necessary for the procedures we are using to be meaningful? Since we are using the normal approximation to the binomial, both np and n(1 – p) should be at least 10 (see Topic 11).
EXAMPLE 13.6
A study is undertaken to determine the proportion of industry executives who believe that workers’ pay should be based on individual performance. How many executives should be interviewed if an estimate is desired at the 99% confidence level to within ±0.06? To within ±0.03? To within ±0.02?
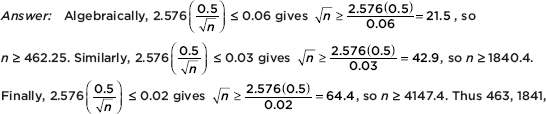
or 4148 executives should be interviewed, depending on the accuracy desired.
Note that to cut the interval estimate in half (from ±0.06 to ±0.03), we would have to increase the sample size fourfold, and to cut the interval estimate to a third (from ±0.06 to ±0.02), a ninefold increase in the sample size would be required (answers are not exact because of round-off error.)
More generally, to divide the interval estimate by d without affecting the confidence level, we must increase the sample size by a multiple of d2.
A formula for the calculations in Examples 13.5 and 13.6 is
![]()
(Note: this formula is not given on the AP Exam formula page.)
CONFIDENCE INTERVAL FOR A DIFFERENCE OF TWO PROPORTIONS
From Topic 12, we have the following information about the sampling distribution of $\widehat{p}$1 – $\widehat{p}$2:
1. The set of all differences of sample proportions is approximately normally distributed.
2. The mean of the set of differences of sample proportions equals p1 – p2, the difference of population proportions.
3. The standard deviation σd of the set of differences of sample proportions is approximately equal to
![]()
Remember that we are using the normal approximation to the binomial, so n1 $\widehat{p}$1, n1(1 – $\widehat{p}$1), n2 $\widehat{p}$2, and n2(1 – $\widehat{p}$2) should all be at least 10. In making calculations and drawing conclusions from specific samples, it is important both that the samples be simple random samples and that they be taken independently of each other. Finally, the original populations should be large compared to the sample sizes.
EXAMPLE 13.7
Suppose that 84% of an SRS of 125 nurses working 7 a.m. to 3 p.m. shifts in city hospitals express positive job satisfaction, while only 72% of an SRS of 150 nurses on 11 p.m. to 7 a.m. shifts express similar fulfillment. Establish a 90% confidence interval estimate for the difference.
TIP
When interpreting the confidence interval for a difference, you must indicate which direction the difference is taken.
Answer: Note that n1 $\widehat{p}$1=(125)(0.84) = 105, n1(1 – $\widehat{p}$1) = (125)(0.16) = 20, n2 $\widehat{p}$2= (150)(0.72) = 108, and n2(1 –$\widehat{p}$2) = (150)(0.28) = 42 are all $\geq$ 10, we are given SRSs, and the population of city hospital nurses is assumed to be large. On the TI-84, 2-PropZInt gives (0.0391, 0.2009). [For instructional purposes, we note that
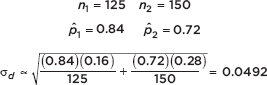
The observed difference is 0.84 – 0.72 = 0.12, and the critical z-scores are ±1.645. The confidence interval estimate is 0.12 ± 1.645(0.0492) = 0.12 ± 0.081.]
We can be 90% certain that the proportion of satisfied nurses on 7 a.m. to 3 p.m. shifts is between 0.039 and 0.201 higher than the proportion for nurses on 11 p.m. to 7 a.m. shifts.
EXAMPLE 13.8
A grocery store manager notes that in an SRS of 85 people going through the express checkout line, only 10 paid with checks, whereas, in an SRS of 92 customers passing through the regular line, 37 paid with checks. Find a 95% confidence interval estimate for the difference between the proportion of customers going through the two different lines who use checks.
Answer: Note that n1 $\widehat{p}$1 = 10, n1(1 – $\widehat{p}$1) = 75, n2 $\widehat{p}$2 = 37, and n2(1 – $\widehat{p}$2) = 55 are all at least 10, we are given SRSs, and the total number of customers is large. On the TI-84, 2-PropZInt gives (–0.4059, –0.1632). [For instructional purposes, we note that
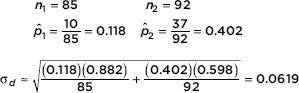
The observed difference is 0.118 – 0.402 = – 0.284, and the critical z-scores are ±1.96. Thus, the confidence interval estimate is – 0.284 ± 1.96(0.0619) = –0.284 ± 0.121.] The manager can be 95% sure that the proportion of customers passing through the express line who use checks is between 0.163 and 0.405 lower than the proportion going through the regular line who use checks.
With regard to choosing a sample size, $\sqrt{p(1-p)}$ is at most 0.5. Thus
![]()
Now, if we simplify by insisting that n1 = n2 = n, the above statement can be reduced as follows:
![]()
(Note: this formula is not given on the AP Exam formula page.)
EXAMPLE 13.9
A pollster wants to determine the difference between the proportions of high-income voters and low-income voters who support a decrease in the capital gains tax. If the answer must be known to within ±0.02 at the 95% confidence level, what size samples should be taken?
Answer: Assuming we will pick the same size samples for the two sample proportions, we have ![]() Algebraically we find that
Algebraically we find that ![]() Therefore, n $\geq$ 69.32 = 4802.5, and the pollster should use 4803 people for each sample.
Therefore, n $\geq$ 69.32 = 4802.5, and the pollster should use 4803 people for each sample.
CONFIDENCE INTERVAL FOR A MEAN
We are interested in estimating a population mean µ by considering a single sample mean x. This sample mean is just one of a whole universe of sample means, and from Topic 12 we remember that if n is sufficiently large,
1. the set of all sample means is approximately normally distributed.
2. the mean of the set of sample means equals µ, the mean of the population.
3. the standard deviation $\sigma_\overline{x}$ of the set of sample means is approximately equal to $\frac{\sigma}{\sqrt{n}}$ that is, equal to the standard deviation of the whole population divided by the square root of the sample size.
Frequently we do not know σ, the population standard deviation. In such cases, we must use s, the standard deviation of the sample, as an estimate of σ. In this case $\frac{s}{\sqrt{n}}$ is called the standard error, SE(x), and is used as an estimate for $\sigma_\overline{x}=\frac{\sigma}{\sqrt{n}}$ (Note that we use t-distributions instead of the standard normal curve whenever σ is unknown, no matter what the sample size.)
Remember that in making calculations and drawing conclusions from a specific sample, it is important that the sample be a simple random sample and be no more than 10% of the population.
EXAMPLE 13.10
A bottling machine is operating with a standard deviation of 0.12 ounce. Suppose that in an SRS of 36 bottles the machine inserted an average of 16.1 ounces into each bottle.
a. Estimate the mean number of ounces in all the bottles this machine fills. More specifically, give an interval within which we are 95% certain that the mean lies.
Answer: For samples of size 36, the sample means are approximately normally distributed with a standard deviation of ![]() From Topic 11 we know that 95% of the sample means should be within 1.96 standard deviations of the population mean. Equivalently, we are 95% certain that the population mean is within 1.96 standard deviations of any sample mean. In our case, 16.1 ± 1.96(0.02) = 16.1 ± 0.0392, and we are 95% sure that the mean number of ounces in all bottles is between 16.0608 and 16.1392. This is called a 95% confidence interval estimate. [On the TI-84, under STAT and then TESTS, go to ZInterval. With Inpt:Stats, σ:.12, $\overline{x}$:16.1, n:36, and C-Level:.95, Calculate gives (16.061, 16.139).]
From Topic 11 we know that 95% of the sample means should be within 1.96 standard deviations of the population mean. Equivalently, we are 95% certain that the population mean is within 1.96 standard deviations of any sample mean. In our case, 16.1 ± 1.96(0.02) = 16.1 ± 0.0392, and we are 95% sure that the mean number of ounces in all bottles is between 16.0608 and 16.1392. This is called a 95% confidence interval estimate. [On the TI-84, under STAT and then TESTS, go to ZInterval. With Inpt:Stats, σ:.12, $\overline{x}$:16.1, n:36, and C-Level:.95, Calculate gives (16.061, 16.139).]
b. How about a 99% confidence interval estimate?
Answer: Here, 16.1 ± 2.576(0.02) = 16.1 ± 0.0515, and we are 99% sure that the mean number of ounces in all bottles is between 16.0485 and 16.1515. [On the TI-84, ZInterval gives (16.048, 16.152).] We can also say, using the definition of confidence level, that if the sampling procedure were repeated many times, about 99% of the resulting confidence intervals would contain the true population mean (thus we’re 99% confident that the method worked for the interval we got).
Note that when we wanted a higher certainty (99% instead of 95%), we had to settle for a larger, less specific interval (±0.0515 instead of ±0.0392).
EXAMPLE 13.11
At a certain plant, batteries are being produced with a life expectancy that has a variance of 5.76 months squared. Suppose the mean life expectancy in an SRS of 64 batteries is 12.35 months.
a. Find a 90% confidence interval estimate of life expectancy for all the batteries produced at this plant.
Answer: The standard deviation of the population is $\sigma=\sqrt{5.76}=2.4$ and the standard deviation of the sample means is ![]() confidence interval estimate for the population mean is 12.35 ± 1.645(0.3) = 12.35 ± 0.4935. Thus we are 90% certain that the mean life expectancy of the batteries is between 11.8565 and 12.8435 months. [The TI-84 gives (11.857, 12.843).]
confidence interval estimate for the population mean is 12.35 ± 1.645(0.3) = 12.35 ± 0.4935. Thus we are 90% certain that the mean life expectancy of the batteries is between 11.8565 and 12.8435 months. [The TI-84 gives (11.857, 12.843).]
b. What would the 90% confidence interval estimate be if the sample mean of 12.35 had come from a sample of 100 batteries?
Answer: The standard deviation of the sample means would then have been ![]() and the 90% confidence interval estimate would be 12.35 ± 1.645(0.24) = 12.35 ± 0.3948. [The TI-84 gives (11.955, 12.745).]
and the 90% confidence interval estimate would be 12.35 ± 1.645(0.24) = 12.35 ± 0.3948. [The TI-84 gives (11.955, 12.745).]
Note that when the sample size increased (from 64 to 100), the same sample mean resulted in a narrower, more specific interval (±0.3948 versus ±0.4935).
EXAMPLE 13.12
A new drug results in lowering the heart rate by varying amounts with a standard deviation of 2.49 beats per minute.
a. Find a 95% confidence interval estimate for the mean lowering of the heart rate in all patients if a 50-person SRS averages a drop of 5.32 beats per minute.
Answer: The standard deviation of sample means is ![]() We are 95% certain that the mean lowering of the heart rate is in the range 5.32 ± 1.96(0.352) = 5.32 ± 0.69 or between 4.63 and 6.01 heartbeats per minute. [The TI-84 gives (4.6298, 6.0102).]
We are 95% certain that the mean lowering of the heart rate is in the range 5.32 ± 1.96(0.352) = 5.32 ± 0.69 or between 4.63 and 6.01 heartbeats per minute. [The TI-84 gives (4.6298, 6.0102).]
b. With what certainty can we assert that the new drug lowers the heart rate by a mean of 5.32 ± 0.75 beats per minute?
Answer: Converting ±0.75 to z-scores yields ![]() From Table A, these z-scores give probabilities of 0.0166 and 0.9834, respectively, so our answer is 0.9834 – 0.0166 = 0.9668. In other words, 5.32 ± 0.75 beats per minute is a 96.68% confidence interval estimate of the mean lowering of the heart rate effected by this drug.
From Table A, these z-scores give probabilities of 0.0166 and 0.9834, respectively, so our answer is 0.9834 – 0.0166 = 0.9668. In other words, 5.32 ± 0.75 beats per minute is a 96.68% confidence interval estimate of the mean lowering of the heart rate effected by this drug.
Remember, when σ is unknown (which is almost always the case), we use the t-distribution instead of the z-distribution. This follows if the parent population is normal (or at least nearly normal, which we can roughly check using a dotplot, stemplot, boxplot, histogram, or normal probability plot of the sample data), or if the sample size is large enough for the central limit theorem to apply. If we are not given that the parent population is normal, then for small samples (n ≤ 15) the sample data should be unimodal and symmetric with no outliers and no skewness; for medium samples (15 < n < 40) the sample data should be unimodal and reasonably symmetric with no extreme values and little, if any, skewness; while for large samples (n $\geq$ 40) the t-methods can be used no matter what the sample data show.
TIP
Understand that you are not trying to prove that the sample data are normal, but rather trying to infer something about the parent population.
EXAMPLE 13.13
When a random sample of 10 cars of a new model were tested for gas mileage, the results showed a mean of 27.2 miles per gallon with a standard deviation of 1.8 miles per gallon. What is a 95% confidence interval estimate for the gas mileage achieved by this model? (Assume that the population of mpg results for all the new model cars is approximately normally distributed.)
Answer: The sample is given to be random, 10 cars should be less than 10% of all cars of the new model, the population is approximately normal so the distribution of sample means is approximately normal, and a t-interval may be found. Calculator software (such as TInterval on the TI-84) gives (25.912, 28.488). [For instructional purposes we note that the standard deviation of the sample means is ![]() = 0.569. With 10 – 1 = 9 degrees of freedom and 2.5% in each tail, the appropriate t-scores are ±2.262 (from Table B or InvT on the TI-84). Then 27 ± 2.262(0.569) = 27.2 ± 1.3.] We are 95% confident that the gas mileage of the new model is between 25.9 and 28.5 miles per gallon.
= 0.569. With 10 – 1 = 9 degrees of freedom and 2.5% in each tail, the appropriate t-scores are ±2.262 (from Table B or InvT on the TI-84). Then 27 ± 2.262(0.569) = 27.2 ± 1.3.] We are 95% confident that the gas mileage of the new model is between 25.9 and 28.5 miles per gallon.
EXAMPLE 13.14
A new process for producing synthetic gems yielded six randomly selected stones weighing 0.43, 0.52, 0.46, 0.49, 0.60, and 0.56 carats, respectively, in its first run. Find a 90% confidence interval estimate for the mean carat weight from this process. (Assume that the population of carats of all gems produced by this new process is approximately normally distributed.)
Answer: The sample is given to be random, six stones is assumed to be less than 10% of all stones produced by this process, the population is approximately normal so the distribution of sample means is approximately normal, and a t-interval may be found. Calculator software (such as TInterval on the TI-84 with the data put in a List) gives (0.45797, 0.56203). [For instructional purposes, we note that
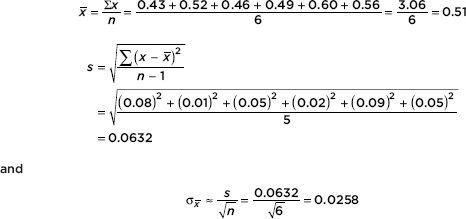
With df = 6 – 1 = 5 and 5% in each tail, the t-scores are ±2.015 (from Table B or InvT on the TI-84). Then 0.51 ± 2.015(0.0258) = 0.51 ± 0.052.] We are 90% confident that the mean carat weight for all stones produced by this procedure is between 0.458 and 0.562 carats.
On the TI-Nspire the result shows as:

TIP
Read the question carefully! Be sure you understand exactly what you are being asked to do or find or explain.
EXAMPLE 13.15
A survey was conducted involving 250 out of 125,000 families living in a city. The average amount of income tax paid per family in the sample was \$3540 with a standard deviation of \$1150. Establish a 99% confidence interval estimate for the total taxes paid by all the families in the city. (Assume that the population of all income taxes paid is approximately normally distributed.)
Answer: We are given x = 3540 and s = 1150. We use s as an estimate for s and calculate the standard deviation of the sample means to be ![]()
Since σ is unknown, we use a t-distribution. In this case we obtain 3540 ± 2.596(72.73) = 3540 ± 188.8 and then 125,000(3540 ± 188.8) = 442,500,000 ± 23,600,000. That is, we are 99% confident that the total tax paid by all families in the city is between \$418,900,000 and \$466,100,000.
Statistical principles are useful not only in analyzing data but also in setting up experiments, and one important consideration is the choice of a sample size. In making interval estimates of population means, we have seen that each inference must go hand in hand with an associated confidence level statement. Generally, if we want a smaller, more precise interval estimate, we either decrease the degree of confidence or increase the sample size. Similarly, if we want to increase the degree of confidence, we either accept a wider interval estimate or increase the sample size. Thus, choosing a larger sample size always seems desirable; in the real world, however, time and cost considerations are involved.
EXAMPLE 13.16
Ball bearings are manufactured by a process that results in a standard deviation in diameter of 0.025 inch. What sample size should be chosen if we wish to be 99% sure of knowing the diameter to within ±0.01 inch?
Answer: We have
![]()
Thus
![]()
Algebraically, we find that
![]()
so n $\geq$ 41.5. We choose a sample size of 42.
A formula for the above calculation is
![]()
(Note: This formula is not given on the AP Exam formula page.)
Note that we can obtain a better estimate by recalculating using a t-score obtained from df = n – 1 where n is the value obtained from using the z-score. For example, in the above problem, a 99% confidence interval with df = 42 – 1 = 41 gives t = ±2.701. Then 2.701 ![]() results in n = 46.
results in n = 46.
TIP
Understand that you use a critical z-value here because to use a t-value you would need to know df, which is unknown without starting with a sample size.
CONFIDENCE INTERVAL FOR A DIFFERENCE BETWEEN TWO MEANS
We have the following information about the sampling distribution of x1 – x2:
1. The set of all differences of sample means is approximately normally distributed.
2. The mean of the set of differences of sample means equals µ1 – µ2, the difference of population means.
3. The standard deviation $\sigma_{\overline{x_1}-\overline{x_2}}$ of the set of differences of sample means is approximately equal to ![]()
In making calculations and drawing conclusions from specific samples, it is important both that the samples be simple random samples and that they be taken independently of each other.
EXAMPLE 13.17
A 30-month study is conducted to determine the difference in the numbers of accidents per month occurring in two departments in an assembly plant. Suppose the first department averages 12.3 accidents per month with a standard deviation of 3.5, while the second averages 7.6 accidents with a standard deviation of 3.4. Determine a 95% confidence interval estimate for the difference in the numbers of accidents per month. (Assume that the two populations are independent and approximately normally distributed.)
Answer: We are not given that the sample is random so must assume that the 30 months are representative. We are given that the two populations are independent and approximately normal, so the distributions of sample means are approximately normal, and a t-interval may be found. Calculator software (such as 2-SampTInt on the TI-84) gives (2.9167, 6.4833). [For instructional purposes we note
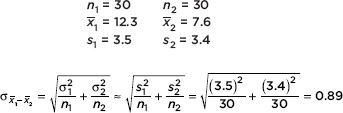
The observed difference is 12.3 – 7.6 = 4.7, and with df = (n1 – 1) + (n2 – 1) = 58, the critical t-scores are ±2.00. Thus the confidence interval estimate is 4.7 ± 2.00(0.89) = 4.7 ± 1.78.]
We are 95% confident that the first department has between 2.92 and 6.48 more accidents per month than the second department.
EXAMPLE 13.18
A hardware store owner wishes to determine the difference between the drying times of two brands of paint. Suppose the standard deviation between cans in each population is 2.5 minutes. How large a sample (same number) of each must the store owner use if he wishes to be 98% sure of knowing the difference to within 1 minute?
Answer:
![]()
With a critical z-score of 2.326, we have 2.326 ![]() Thus the owner should test samples of 68 paint patches from each brand.
Thus the owner should test samples of 68 paint patches from each brand.
In the case of independent samples, there is also a procedure based on the assumption that both original populations not only are normally distributed but also have equal variances. Then we can get a better estimate of the common population variance by pooling the two sample variances. But it’s never wrong not to pool.
The analysis and procedure discussed in this section require that the two samples being compared be independent of each other. However, many experiments and tests involve comparing two populations for which the data naturally occur in pairs. In this case of paired differences, the proper procedure is to run a one-sample analysis on the single variable consisting of the differences from the paired data.
EXAMPLE 13.19
An SAT preparation class of 30 randomly selected students produces the following improvement in scores:
Student | First Score | Second Score | Improvement |
1 | 912 | 1025 | 113 |
2 | 1025 | 1085 | 60 |
3 | 1295 | 1350 | 55 |
4 | 1123 | 1202 | 79 |
5 | 875 | 982 | 107 |
6 | 890 | 950 | 60 |
7 | 1002 | 1089 | 87 |
8 | 998 | 1159 | 161 |
9 | 1235 | 1246 | 11 |
10 | 1045 | 1135 | 90 |
11 | 956 | 1005 | 49 |
12 | 987 | 1010 | 23 |
13 | 1028 | 1015 | –13 |
14 | 954 | 1032 | 78 |
15 | 1152 | 1310 | 158 |
16 | 1215 | 1302 | 87 |
17 | 948 | 1010 | 62 |
18 | 1190 | 1235 | 45 |
19 | 1077 | 1103 | 26 |
20 | 1223 | 1200 | –23 |
21 | 1100 | 1187 | 87 |
22 | 842 | 910 | 68 |
23 | 985 | 1049 | 64 |
24 | 1107 | 1123 | 16 |
25 | 847 | 901 | 54 |
26 | 987 | 1086 | 99 |
27 | 1228 | 1276 | 48 |
28 | 1005 | 1029 | 24 |
29 | 1166 | 1221 | 55 |
30 | 808 | 874 | 66 |
Find a 90% confidence interval estimate of the average improvement in test scores.
Answer: We are given a random sample, and n = 30 is large enough so that by the CLT the distribution of sample means is approximately normal and a t-interval may be found. Putting the data (Improvement) into a List, calculator software (such as T-Interval on the TI-84) gives (50.206, 76.194). We are 90% confident that the average improvement in test scores is between 50.2 and 76.2.
When to do a two-sample analysis versus a matched pair analysis can be confusing. The key idea is whether or not the two groups are independent. The difference has to do with design. What is the average reaction time of people who are sober compared to that of people who have had two beers? If our experimental design calls for randomly assigning half of a group of volunteers to drink two beers and then comparing reaction times with the remaining sober volunteers, then a two-sample analysis is called for. However, if our experimental design calls for testing reaction times of all the volunteers and then giving all the volunteers two beers and retesting, then a matched pair analysis is called for. Matching may come about as above because you have made two measurements on the same person, or measurements might be made on sets of twins, or between salaries of president and provost at a number of universities, etc. The key is whether the two sets of measurements are independent, or related in some way relevant to the question under consideration.
TIP
Note the similarities between ![]()
CONFIDENCE INTERVAL FOR THE SLOPE OF A LEAST SQUARES REGRESSION LINE
In Topic 4 we discussed the least squares line
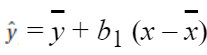
where b1 is the slope of the line. This slope is readily found using the statistical software on a calculator. It is an estimate of the slope $\beta$ of the true regression line. A confidence interval estimate for $\beta$ can be found using t-scores, where df = n – 2, and the appropriate standard deviation, the standard error of the slope, written sb1 or SE(b1), is
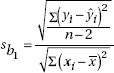
where the sum in the numerator is the sum of the squared residuals (see Topic 4) and the sum in the denominator is the sum of the squared deviations from the mean. The value of sb1 is found at the same time that the statistical software on your calculator finds the value of b1. Some calculators calculate the numerator ![]() and then the denominator can be calculated by
and then the denominator can be calculated by ![]()
Assumptions here include: (1) the sample must be randomly selected; (2) the scatterplot should be approximately linear; (3) there should be no apparent pattern in the residuals plot (On the TI-84, after Stat → Calc → LinReg, the list of residuals is stored in RESID under LIST NAMES); and (4) the distribution of the residuals should be approximately normal. (The fourth point can be checked by a histogram, dotplot, stemplot, or a normal probability plot of the residuals.)
TIP
If you refer to a graph, whether it is a histogram, boxplot, stemplot, scatterplot, residuals plot, normal probability plot, or some other kind of graph, you should roughly draw it. It is not enough to simply say, “I did a normal probability plot of the residuals on my calculator and it looked linear.”
EXAMPLE 13.20
A random sample of ten high school students produced the following results for number of hours of television watched per week and GPA.
TV hours | 12 | 21 | 8 | 20 | 16 | 16 | 24 | 0 | 11 | 18 |
GPA | 3.1 | 2.3 | 3.5 | 2.5 | 3.0 | 2.6 | 2.1 | 3.8 | 2.9 | 2.6 |
Determine the least squares line and give a 95% confidence interval estimate for the true slope.
Answer: Checking the assumptions:
We are told that the data come from a random sample of students.
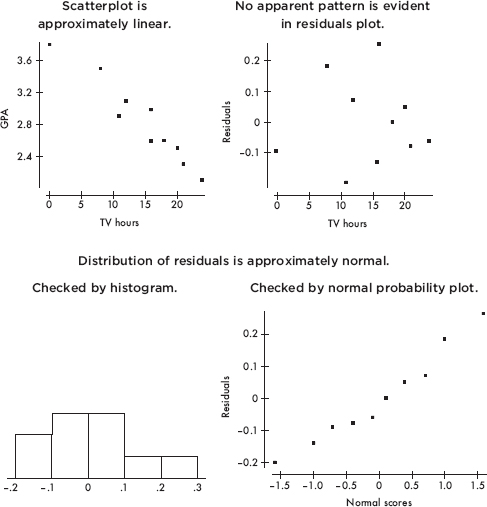
Now using the statistics software on a calculator gives
$\widehat{y}$ = 3.892 – 0.07202x
Putting the data into two Lists and using calculator software (such as LinRegTInt on the TI-84) gives (–0.0887, –0.0554).
We are thus 95% confident that each additional hour before the television each week is associated with between a 0.055 and a 0.089 drop in GPA.
On the TI-Nspire one can show the following:
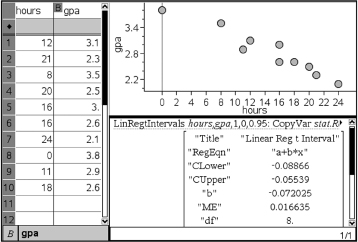
Remember we must be careful about drawing conclusions concerning cause and effect; it is possible that students who have lower GPAs would have these averages no matter how much television they watched per week.
Note that ![]() called the standard deviation of the residuals, is sometimes written se. It is a measure of the spread about the regression line, and is almost always in the regression output (usually simply labeled as s or S). Note that sb1 is sometimes written SE(b1) and is also referred to as the standard error of the slope. So we can also write
called the standard deviation of the residuals, is sometimes written se. It is a measure of the spread about the regression line, and is almost always in the regression output (usually simply labeled as s or S). Note that sb1 is sometimes written SE(b1) and is also referred to as the standard error of the slope. So we can also write ![]() We see that increasing se (that is, increasing spread about the line) increases the slope’s standard error, while increasing sx (that is, increasing the range of x-values) or increasing n (the sample size) decreases the slope’s standard error.
We see that increasing se (that is, increasing spread about the line) increases the slope’s standard error, while increasing sx (that is, increasing the range of x-values) or increasing n (the sample size) decreases the slope’s standard error.
TIP
Practice how to read generic computer output, and note that you usually will not need to use all the information given.
EXAMPLE 13.21
Information concerning SAT verbal scores and SAT math scores was collected from 15 randomly selected subjects. A linear regression performed on the data using a statistical software package produced the following printout:
Dependent variable: Math
Variable | Coef | SE Coef | T | Prob |
Constant | 92.5724 | 31.75 | 2.92 | 0.012 |
Verbal | 0.763604 | 0.05597 | 13.6 | 0.000 |
S = 16.69 | R–Sq = 93.5% | R–Sq(adj) = 93.0% |
|
|
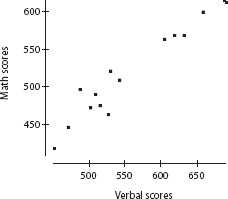
What is the regression equation?
Answer: Assuming that all assumptions for regression are met (we are given that the sample is random, and the scatterplot is approximately linear), the y-intercept and slope of the equation are found in the Coef column of the above printout.
![]()
What is a 95% confidence interval estimate for the slope of the regression line?
Answer: The standard deviation of the residuals is S = 16.69 and the standard error of the slope is Sb1 = 0.05597. With 15 data points, df = 15 – 2 = 13, and the critical t-values are ±2.160. The 95% confidence interval of the true slope is:
b1 ± t sb1 = 0.764 ± 2.160(0.05597) = 0.764 ± 0.121
We are 95% confident that for every 1-point increase in verbal SAT score, the average increase in math SAT score is between 0.64 and 0.89.
SUMMARY
Important assumptions/conditions always must be checked before calculating confidence intervals.
We are never able to say exactly what a population parameter is; rather, we say that we have a certain confidence that it lies in a certain interval.
If we want a narrower interval, we must either decrease the confidence level or increase the sample size.
If we want a higher level of confidence, we must either accept a wider interval or increase the sample size.
The level of confidence refers to the percentage of samples that produce intervals that capture the true population parameter.
Multiple-Choice Questions
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. Changing from a 95% confidence interval estimate for a population proportion to a 99% confidence interval estimate, with all other things being equal,
(A) increases the interval size by 4%.
(B) decreases the interval size by 4%.
(C) increases the interval size by 31%.
(D) decreases the interval size by 31%.
(E) This question cannot be answered without knowing the sample size.
2. In general, how does doubling the sample size change the confidence interval size?
(A) Doubles the interval size
(B) Halves the interval size
(C) Multiplies the interval size by 1.414
(D) Divides the interval size by 1.414
(E) This question cannot be answered without knowing the sample size.
3. A confidence interval estimate is determined from the GPAs of a simple random sample of n students. All other things being equal, which of the following will result in a smaller margin of error?
(A) A smaller confidence level
(B) A larger sample standard deviation
(C) A smaller sample size
(D) A larger population size
(E) A smaller sample mean
4. A survey was conducted to determine the percentage of high school students who planned to go to college. The results were stated as 82% with a margin of error of ±5%. What is meant by ±5%?
(A) Five percent of the population were not surveyed.
(B) In the sample, the percentage of students who plan to go to college was between 77% and 87%.
(C) The percentage of the entire population of students who plan to go to college is between 77% and 87%.
(D) It is unlikely that the given sample proportion result would be obtained unless the true percentage was between 77% and 87%.
(E) Between 77% and 87% of the population were surveyed.
5. Most recent tests and calculations estimate at the 95% confidence level that the maternal ancestor to all living humans called mitochondrial Eve lived 273,000 ±177,000 years ago. What is meant by “95% confidence” in this context?
(A) A confidence interval of the true age of mitochondrial Eve has been calculated using z-scores of ±1.96.
(B) A confidence interval of the true age of mitochondrial Eve has been calculated using t-scores consistent with df = n – 1 and tail probabilities of ±.025.
(C) There is a .95 probability that mitochondrial Eve lived between 96,000 and 450,000 years ago.
(D) If 20 random samples of data are obtained by this method, and a 95% confidence interval is calculated from each, then the true age of mitochondrial Eve will be in 19 of these intervals.
(E) 95% of all random samples of data obtained by this method will yield intervals that capture the true age of mitochondrial Eve.
6. One month the actual unemployment rate in France was 13.4%. If during that month you took an SRS of 100 Frenchmen and constructed a confidence interval estimate of the unemployment rate, which of the following would have been true?
(A) The center of the interval was 13.4.
(B) The interval contained 13.4.
(C) A 99% confidence interval estimate contained 13.4.
(D) The z-score of 13.4 was between ±2.576.
(E) None of the above are true statements.
7. In a recent Zogby International survey, 11% of 10,000 Americans under 50 said they would be willing to implant a device in their brain to be connected to the Internet if it could be done safely. What is the margin of error at the 99% confidence level?
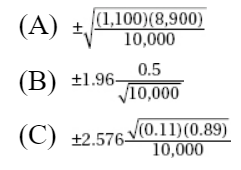
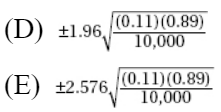
8. The margin of error in a confidence interval estimate using z-scores covers which of the following?
(A) Sampling variability
(B) Errors due to undercoverage and nonresponse in obtaining sample surveys
(C) Errors due to using sample standard deviations as estimates for population standard deviations
(D) Type I errors
(E) Type II errors
9. In an SRS of 50 teenagers, two-thirds said they would rather text a friend than call. What is the 98% confidence interval for the proportion of teens who would rather text than call a friend?

10. In a survey funded by Burroughs-Welcome, 750 of 1000 adult Americans said they didn’t believe they could come down with a sexually transmitted disease (STD). Construct a 95% confidence interval estimate of the proportion of adult Americans who don’t believe they can contract an STD.
(A) (0.728, 0.772)
(B) (0.723, 0.777)
(C) (0.718, 0.782)
(D) (0.713, 0.787)
(E) (0.665, 0.835)
11. A 1993 Los Angeles Times poll of 1703 adults revealed that only 17% thought the media was doing a “very good” job. With what degree of confidence can the newspaper say that 17% ± 2% of adults believe the media is doing a “very good” job?
(A) 72.9%
(B) 90.0%
(C) 95.0%
(D) 97.2%
(E) 98.6%
12. A politician wants to know what percentage of the voters support her position on the issue of forced busing for integration. What size voter sample should be obtained to determine with 90% confidence the support level to within 4%?
(A) 21
(B) 25
(C) 423
(D) 600
(E) 1691
13. In a New York Times poll measuring a candidate’s popularity, the newspaper claimed that in 19 of 20 cases its poll results should be no more than three percentage points off in either direction. What confidence level are the pollsters working with, and what size sample should they have obtained?
(A) 3%, 20
(B) 6%, 20
(C) 6%, 100
(D) 95%, 33
(E) 95%, 1068
14. In an SRS of 80 teenagers, the average number of texts handled in a day was 50 with a standard deviation of 15. What is the 96% confidence interval for the average number of texts handled by teens daily?

15. One gallon of gasoline is put in each of 30 test autos, and the resulting mileage figures are tabulated with x = 28.5 and s = 1.2. Determine a 95% confidence interval estimate of the mean mileage.
(A) (28.46, 28.54)
(B) (28.42, 28.58)
(C) (28.1, 28.9)
(D) (27.36, 29.64)
(E) (27.3, 29.7)
16. The number of accidents per day at a large factory is noted for each of 64 days with x = 3.58 and s = 1.52. With what degree of confidence can we assert that the mean number of accidents per day at the factory is between 3.20 and 3.96?
(A) 48%
(B) 63%
(C) 90%
(D) 95%
(E) 99%
17. A company owns 335 trucks. For an SRS of 30 of these trucks, the average yearly road tax paid is \$9540 with a standard deviation of \$1205. What is a 99% confidence interval estimate for the total yearly road taxes paid for the 335 trucks?
(A) \$9540 ± \$103
(B) \$9540 ± \$567
(C) \$3,196,000 ± \$606
(D) \$3,196,000 ± \$35,000
(E) \$3,196,000 ± \$203,000
18. What sample size should be chosen to find the mean number of absences per month for school children to within ±0.2 at a 95% confidence level if it is known that the standard deviation is 1.1?
(A) 11
(B) 29
(C) 82
(D) 96
(E) 117
19. Hospital administrators wish to learn the average length of stay of all surgical patients. A statistician determines that, for a 95% confidence level estimate of the average length of stay to within ±0.5 days, 50 surgical patients’ records will have to be examined. How many records should be looked at to obtain a 95% confidence level estimate to within ±0.25 days?
(A) 25
(B) 50
(C) 100
(D) 150
(E) 200
20. The National Research Council of the Philippines reported that 210 of 361 members in biology are women, but only 34 of 86 members in mathematics are women. Establish a 95% confidence interval estimate of the difference in proportions of women in biology and women in mathematics in the Philippines.
(A) 0.187 ± 0.115
(B) 0.187 ± 0.154
(C) 0.395 ± 0.103
(D) 0.543 ± 0.154
(E) 0.582 ± 0.051
21. In a simple random sample of 300 elderly men, 65% were married, while in an independent simple random sample of 400 elderly women, 48% were married. Determine a 99% confidence interval estimate for the difference between the proportions of elderly men and women who are married.

![]()
22. A researcher plans to investigate the difference between the proportion of psychiatrists and the proportion of psychologists who believe that most emotional problems have their root causes in childhood. How large a sample should be taken (same number for each group) to be 90% certain of knowing the difference to within ±0.03?
(A) 39
(B) 376
(C) 752
(D) 1504
(E) 3007
23. In a study aimed at reducing developmental problems in low-birth-weight (under 2500 grams) babies (Journal of the American Medical Association, June 13, 1990, page 3040), 347 infants were exposed to a special educational curriculum while 561 did not receive any special help. After 3 years the children exposed to the special curriculum showed a mean IQ of 93.5 with a standard deviation of 19.1; the other children had a mean IQ of 84.5 with a standard deviation of 19.9. Find a 95% confidence interval estimate for the difference in mean IQs of low-birth-weight babies who receive special intervention and those who do not.

24. Does socioeconomic status relate to age at time of HIV infection? For 274 high-income HIV-positive individuals the average age of infection was 33.0 years with a standard deviation of 6.3, while for 90 low-income individuals the average age was 28.6 years with a standard deviation of 6.3 (The Lancet, October 22, 1994, page 1121). Find a 90% confidence interval estimate for the difference in ages of high- and low-income people at the time of HIV infection.
(A) 4.4 ± 0.963
(B) 4.4 ± 1.27
(C) 4.4 ± 2.51
(D) 30.8 ± 2.51
(E) 30.8 ± 6.3
25. An engineer wishes to determine the difference in life expectancies of two brands of batteries. Suppose the standard deviation of each brand is 4.5 hours. How large a sample (same number) of each type of battery should be taken if the engineer wishes to be 90% certain of knowing the difference in life expectancies to within 1 hour?
(A) 10
(B) 55
(C) 110
(D) 156
(E) 202
26. Two confidence interval estimates from the same sample are (16.4, 29.8) and (14.3, 31.9). What is the sample mean, and if one estimate is at the 95% level while the other is at the 99% level, which is which?
(A) x = 23.1; (16.4, 29.8) is the 95% level.
(B) x = 23.1; (16.4, 29.8) is the 99% level.
(C) It is impossible to completely answer this question without knowing the sample size.
(D) It is impossible to completely answer this question without knowing the sample standard deviation.
(E) It is impossible to completely answer this question without knowing both the sample size and standard deviation.
27. Two 90% confidence interval estimates are obtained: I (28.5, 34.5) and II (30.3, 38.2).
a. If the sample sizes are the same, which has the larger standard deviation?
b. If the sample standard deviations are the same, which has the larger size?
(A) a. Ib. I
(B) a. Ib. II
(C) a. IIb. I
(D) a. IIb. II
(E) More information is needed to answer these questions.
28. Suppose (25, 30) is a 90% confidence interval estimate for a population mean µ. Which of the following are true statements?
(A) There is a 0.90 probability that x is between 25 and 30.
(B) 90% of the sample values are between 25 and 30.
(C) There is a 0.90 probability that µ is between 25 and 30.
(D) If 100 random samples of the given size are picked and a 90% confidence interval estimate is calculated from each, then µ will be in 90 of the resulting intervals.
(E) If 90% confidence intervals are calculated from all possible samples of the given size, µ will be in 90% of these intervals.
29. Under what conditions would it be meaningful to construct a confidence interval estimate when the data consist of the entire population?
(A) If the population size is small (n < 30)
(B) If the population size is large (n $\geq$ 30)
(C) If a higher level of confidence is desired
(D) If the population is truly random
(E) Never
30. A social scientist wishes to determine the difference between the percentage of Los Angeles marriages and the percentage of New York marriages that end in divorce in the first year. How large a sample (same for each group) should be taken to estimate the difference to within ±0.07 at the 94% confidence level?
(A) 181
(B) 361
(C) 722
(D) 1083
(E) 1443
31. What is the critical t-value for finding a 90% confidence interval estimate from a sample of 15 observations?
(A) 1.341
(B) 1.345
(C) 1.350
(D) 1.753
(E) 1.761
32. Acute renal graft rejection can occur years after the graft. In one study (The Lancet, December 24, 1994, page 1737), 21 patients showed such late acute rejection when the ages of their grafts (in years) were 9, 2, 7, 1, 4, 7, 9, 6, 2, 3, 7, 6, 2, 3, 1, 2, 3, 1, 1, 2, and 7, respectively. Establish a 90% confidence interval estimate for the ages of renal grafts that undergo late acute rejection.
(A) 2.024 ± 0.799
(B) 2.024 ± 1.725
(C) 4.048 ± 0.799
(D) 4.048 ± 1.041
(E) 4.048 ± 1.725
33. Nine subjects, 87 to 96 years old, were given 8 weeks of progressive resistance weight training (Journal of the American Medical Association, June 13, 1990, page 3032). Strength before and after training for each individual was measured as maximum weight (in kilograms) lifted by left knee extension:
Before: | 3 | 3.5 | 4 | 6 | 7 | 8 | 8.5 | 12.5 | 15 |
After: | 7 | 17 | 19 | 12 | 19 | 22 | 28 | 20 | 28 |
Find a 95% confidence interval estimate for the strength gain.
(A) 11.61 ± 3.03
(B) 11.61 ± 3.69
(C) 11.61 ± 3.76
(D) 19.11 ± 1.25
(E) 19.11 ± 3.69
34. A catch of five fish of a certain species yielded the following ounces of protein per pound of fish: 3.1, 3.5, 3.2, 2.8, and 3.4. What is a 90% confidence interval estimate for ounces of protein per pound of this species of fish?
(A) 3.2 ± 0.202
(B) 3.2 ± 0.247
(C) 3.2 ± 0.261
(D) 4.0 ± 0.202
(E) 4.0 ± 0.247
35. In a random sample of 25 professional baseball players, their salaries (in millions of dollars) and batting averages result in the following regression analysis:
The regression equation is Batting = 0.234 + 0.00805 Salary
Predictor | Coef | SE Coef | T | P |
Constant | 0.233577 | 0.005883 | 39.70 | 0.000 |
Salary | 0.008051 | 0.001058 | 7.61 | 0.000 |
S = 0.0169461 R-Sq = 71.6% R-Sq(adj) = 70.3%
Which of the following gives a 98% confidence interval for the slope of the regression line?

36. Is there a relationship between mishandled-baggage rates (number of mishandled bags per 1000 passengers) and percentage of on-time arrivals? Regression analysis of ten airlines gives the following TI-Nspire output (baggage rate is independent variable):
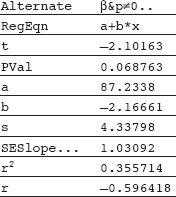 We are 95% confident that if an airline averages one more mishandled bag per 1000 passengers than a second airline, then its percentage of on-time arrivals will average
We are 95% confident that if an airline averages one more mishandled bag per 1000 passengers than a second airline, then its percentage of on-time arrivals will average
(A) between 0.15 and 4.19 less than that of the second airline.
(B) between 0.00 and 4.33 less than that of the second airline.
(C) between 4.46 less and 0.13 more than that of the second airline.
(D) between 4.49 less and 0.17 more than that of the second airline.
(E) between 4.54 less and 0.21 more than that of the second airline.
37. Smoking is a known risk factor for cardiovascular and cancer diseases. A recent study (Rusanen et al., Archives of Internal Medicine, October 25, 2010) surveyed 21,123 members of a California health care system looking at smoking levels and risk of dementia (as measured by the Cox hazard ratio). Results are summarized in the following graph of 95% confidence intervals.
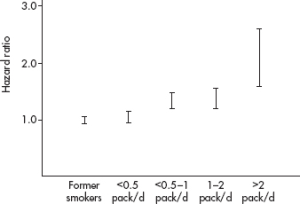
Which of the following is an appropriate conclusion?
(A) Dementia somehow causes an urge to smoke.
(B) Heavier smoking leads to a greater risk of dementia.
(C) Cutting down on smoking will lower one’s risk of dementia.
(D) Heavier smoking is associated with more precise confidence intervals of dementia as measured by the hazard ratio.
(E) There is a positive association between smoking and risk of dementia.
Free-Response Questions
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your final answers.
ELEVEN OPEN-ENDED QUESTIONS
1. An SRS of 1000 voters finds that 57% believe that competence is more important than character in voting for President of the United States.
(a) Determine a 95% confidence interval estimate for the percentage of voters who believe competence is more important than character.
(b) If your parents know nothing about statistics, how would you explain to them why you can’t simply say that 57% of voters believe that competence is more important.
(c) Also explain to your parents what is meant by 95% confidence level.
2. During the H1N1 pandemic, one published study concluded that if someone in your family had H1N1, you had a 1 in 8 chance of also coming down with the disease. A state health officer tracks a random sample of new H1N1 cases in her state and notes that 129 out of a potential 876 family members later come down with the disease.
(a) Calculate a 90% confidence interval for the proportion of family members who come down with H1N1 after an initial family member does in this state.
(b) Based on this confidence interval, is there evidence that the proportion of family members who come down with H1N1 after an initial family member does in this state is different from the 1 in 8 chance concluded in the published study? Explain.
(c) Would the conclusion in (b) be any different with a 99% confidence interval? Explain.
3. In a random sample of 500 new births in the United States, 41.2% were to unmarried women, while in a random sample of 400 new births in the United Kingdom, 46.5% were to unmarried women.
(a) Calculate a 95% confidence interval for the difference in the proportions of new births to unmarried women in the United States and United Kingdom.
(b) Does the confidence interval support the belief by a UN health care statistician that the proportions of new births to unmarried women is different in the United States and United Kingdom? Explain.
4. An SRS of 40 inner city gas stations shows a mean price for regular unleaded gasoline to be \$3.45 with a standard deviation of \$0.05, while an SRS of 120 suburban stations shows a mean of \$3.38 with a standard deviation of \$0.08.
(a) Construct 95% confidence interval estimates for the mean price of regular gas in inner city and in suburban stations.
(b) The confidence interval for the inner city stations is wider than the interval for the suburban stations even though the standard deviation for inner city stations is less than that for suburban stations. Explain why this happened.
(c) Based on your answer in part (a), are you confident that the mean price of inner city gasoline is less than \$3.50? Explain.
5. In a simple random sample of 30 subway cars during rush hour, the average number of riders per car was 83.5 with a standard deviation of 5.9. Assume the sample data are unimodal and reasonably symmetric with no extreme values and little, if any, skewness.
(a) Establish a 90% confidence interval estimate for the average number of riders per car during rush hour. Show your work.
(b) Assuming the same standard deviation of 5.9, how large a sample of cars would be necessary to determine the average number of riders to within ±1 at the 90% confidence level? Show your work.
6. In a sample of ten basketball players the mean income was \$196,000 with a standard deviation of \$315,000.
(a) Assuming all necessary assumptions are met, find a 95% confidence interval estimate of the mean salary of basketball players.
(b) What assumptions are necessary for the above estimate? Do they seem reasonable here?
7. An SRS of ten brands of breakfast cereals is tested for the number of calories per serving. The following data result: 185, 190, 195, 200, 205, 205, 210, 210, 225, 230.
Establish a 95% confidence interval estimate for the mean number of calories for servings of breakfast cereals. Be sure to check assumptions.
8. Bisphenol A (BPA), a synthetic estrogen found in packaging materials, has been shown to leach into infant formula and beverages. Most recently it has been detected in high concentrations in cash register receipts. Random sample biomonitoring data to see if retail workers carry higher amounts of BPA in their bodies than non-retail workers is as follows:
|
| BPA concentration (µg/L) | |
| Sample size | Mean | Standard deviation |
Non-retail workers | 528 | 2.43 | 0.45 |
Retail workers | 197 | 3.28 | 0.48 |
(a) Calculate a 99% confidence interval for the difference in mean BPA body concentrations of non-retail and retail workers.
(b) Does the confidence interval support the belief that retail workers carry higher amounts of BPA in their bodies than non-retail workers? Explain.
9. A new drug is tested for relief of allergy symptoms. In a double-blind experiment, 12 patients are given varying doses of the drug and report back on the number of hours of relief. The following table summarizes the results:
Dosage (mg) | 2 | 3 | 4 | 4 | 5 | 6 | 6 | 7 | 8 | 8 | 9 | 10 |
Duration of relief (hrs) | 3 | 7 | 6 | 8 | 10 | 8 | 13 | 16 | 15 | 21 | 23 | 24 |
(a) Determine the equation of the least squares regression line.
(b) Construct a 90% confidence interval estimate for the slope of the regression line, and interpret this in context.
10. Information with regard to the assessed values (in \$1000) and the selling prices (in \$1000) of a random sample of homes sold in an NE market yields the following computer output:
Dependent variable isPrice
R squared = 89.8% R squared (adjusted) = 89.2%
s = 9.508 with 20 – 2 = 18 degrees of freedom
Source | SS | df | MS | F-ratio |
Regression | 14271.2 | 1 | 14271.2 | 158 |
Residual | 1627.31 | 18 | 90.4063 |
|
Variable | Coeff | s.e. of coeff | t-ratio | prob |
Constant | 0.890087 | 16.16 | 0.055 | 0.956 |
Assessed | 1.0292 | 0.08192 | 12.6 | 0.000 |
(a) Determine the equation of the least squares regression line.
(b) Construct a 99% confidence interval estimate for the slope of the regression line, and interpret this in context.
11. In a July 2008 study of 1050 randomly selected smokers, 74% said they would like to give up smoking.
(a) At the 95% confidence level, what is the margin of error?
(b) Explain the meaning of “95% confidence interval” in this example.
(c) Explain the meaning of “95% confidence level” in this example.
(d) Give an example of possible response bias in this example.
(e) If we want instead to be 99% confident, would our confidence interval need to be wider or narrower?
(f) If the sample size were greater, would the margin of error be smaller or greater?
AN INVESTIGATIVE TASK
As of January 1, 2014, Serena Williams had career prize money earnings of \$54,380,000 during her 18 year professional career. Among the top active women tennis players, is there a linear relationship between career prize money earnings and years as a pro? Computer output of earnings (millions of \$) versus professional years for 10 top active women players are shown below:
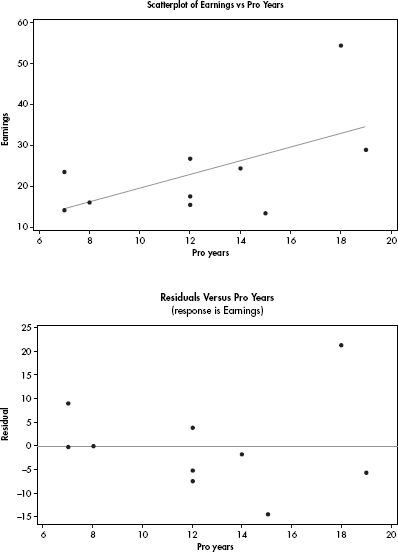
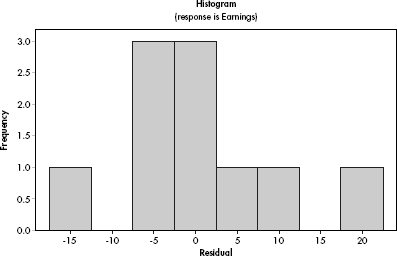
Regression Analysis: Earnings versus Pro Years
Predictor | Coef | SE Coef | T | P |
Constant | 2.69 | 10.78 | 0.25 | 0.809 |
Pro Years | 1.6752 | 0.8264 | 2.03 | 0.077 |
S = 10.5317 R-Sq = 33.9% R-Sq(adj) = 25.7%
Analysis of Variance
Source | DF | SS | MS | F | P |
Regression | 1 | 455.8 | 455.8 | 4.11 | 0.077 |
Residual Error | 8 | 887.3 | 110.9 |
|
|
Total | 9 | 1343.1 |
|
|
|
(a) Determine the equation of the least squares regression line.
(b) Comment on the strength of the linear relationship.
(c) Predict the career earnings for Years = 15 and Years = 30 for active women tennis players, and explain your confidence in both of your answers.
(d) Find the 90% confidence interval for the slope of the regression line, and interpret in context.
(e) Assuming all conditions for inference are met, and using a t-distribution with df = n – 2, find the 90% confidence interval for the y-intercept, and if appropriate, interpret in context. Explain.
(f) A second linear model is found: $\widehat{y}$ = 1.8712(Years). Explain why you might prefer this model to the one in (a).
1 Note that we cannot say there is a 0.99 probability that the population proportion is within 2.576 standard deviations of a given sample proportion. For a given sample proportion, the population proportion either is or isn’t within the specified interval, and so the probability is either 1 or 0.
MULTIPLE-CHOICE
1. (C) The critical z-scores will go from ±1.96 to ±2.576, resulting in an increase in the interval size:  or an increase of 31%.
or an increase of 31%.
2. (D) Increasing the sample size by a multiple of d divides the interval estimate by  .
.
3. (A) The margin of error varies directly with the critical z-value and directly with the standard deviation of the sample, but inversely with the square root of the sample size. The value of the sample mean and the population size do not affect the margin of error.
4. (D) Although the sample proportion is between 77% and 87% (more specifically, it is 82%), this is not the meaning of ±5%. Although the percentage of the entire population is likely to be between 77% and 87%, this is not known for certain.
5. (E) The 95% refers to the method: 95% of all intervals obtained by this method will capture the true population parameter. Nothing is certain about any particular set of 20 intervals. For any particular interval, the probability that it captures the true parameter is 1 or 0 depending upon whether the parameter is or isn’t in it.
6. (E) There is no guarantee that 13.4 is anywhere near the interval, so none of the statements are true.
7. (E) The critical z-score with 0.005 in each tail is 2.576 (from last line on Table B or invNorm(0.005) on the TI-84), and 
8. (A) The margin of error has to do with measuring chance variation but has nothing to do with faulty survey design. As long as n is large, s is a reasonable estimate of ; however, again this is not measured by the margin of error. (With t-scores, there is a correction for using s as an estimate of .)
9. (B) The critical z-score with 0.01 in the tails is 2.326 (invNorm(0.01) on the TI-84), and 
10. (B) 1-PropZInt on the TI-84 gives (0.72316, 0.77684).
11. (D)  z(0.0091) = 0.02 z = 2.20, 0.9861 – 0.0139 = 97.2%
z(0.0091) = 0.02 z = 2.20, 0.9861 – 0.0139 = 97.2%
12. (C) 
13. (E)  and so the pollsters should have obtained a sample size of at least 1068. (They actually interviewed 1148 people.)
and so the pollsters should have obtained a sample size of at least 1068. (They actually interviewed 1148 people.)
14. (E) LOL, OMG, the critical t-score with 0.02 in the tails is 2.088 (Table B or invt(0.02,79) on the TI-84), and 
15. (C) TInterval on the TI-84 gives (28.052, 28.948).
16. (D) 
17. (E) Using t-scores:

18. (E) 
19. (E) To divide the interval estimate by d without affecting the confidence level, multiply the sample size by a multiple of d2. In this case, 4(50) = 200.
20. (A) 2-PropZInt on the TI-84 gives (0.07119, 0.30155) or 0.18637 ± 0.11518.
21. (B)

22. (D)  the researcher should choose a sample size of at least 1504.
the researcher should choose a sample size of at least 1504.
23. (A)  and with df = min(347 – 1, 561 – 1), critical t-scores are ±1.97.
and with df = min(347 – 1, 561 – 1), critical t-scores are ±1.97.
24. (B) 2-SampTInt on the TI-84 gives (3.1333, 5.6667) or 4.4 ± 1.2667.
25. (C) 

26. (A) The sample mean is at the center of the confidence interval; the lower confidence level corresponds to the narrower interval.
27. (C) Narrower intervals result from smaller standard deviations and from larger sample sizes.
28. (E) Only III is true. The 90% refers to the method; 90% of all intervals obtained by this method will capture µ. Nothing is sure about any particular set of 100 intervals. For any particular interval, the probability that it captures µ is either 1 or 0 depending on whether µ is or isn’t in it.
29. (E) In determining confidence intervals, one uses sample statistics to estimate population parameters. If the data are actually the whole population, making an estimate has no meaning.
30. (B) 
31. (E) With df = 15 – 1 = 14 and 0.05 in each tail, the critical t-value is 1.761.
32. (D) x = 4.048, s = 2.765, df = 20, and

33. (C) TInterval on the set of differences gives (7.8514, 15.371) or 11.6112 ± 3.7598.
34. (C) TInterval on the TI-84 gives (2.9389, 3.4611) or 3.2 ± 0.2611.
35. (E) The critical t-values with df = 25 – 2 = 23 are ±2.500. Thus, we have b1 ± t∗ × SE(b1) = 0.008051 ± (2.500)(0.001058).
36. (E) The critical t-values with df = n – 2 = 8 are ±2.306. Thus, we have b ± t∗ × SE(b) = –2.16661 ± 2.306(1.03092) = –2.16661 ± 2.3773 or (–4.54,0.21).
37. (E) While there is clearly a positive association between smoking levels and hazard ratios, this was an observational study, not an experiment, so cause and effect (as implied in I, II, and III) is not an appropriate conclusion. The margins of error of the confidence intervals become greater (less precision) with heavier smoking.
FREE-RESPONSE
1. (a) First, identify the confidence interval and check the conditions: This is a one-sample z-interval for the proportion of all voters who believe competence is more important than character. It is given that this is a random sample, we calculate n = 1000(0.57) = 570 10 and n = 1000(0.43) = 430 10, and n = 1000 is less than 10% of all voters.
= 1000(0.43) = 430 10, and n = 1000 is less than 10% of all voters.
Second, calculate the interval:
Calculator software (such as 1-PropZInt on the TI-84) gives (0.53932, 0.60068). [For instructional purposes in this review book, we note that = 0.57 and  The critical z-scores associated with the 95% level are ±1.96. Thus the confidence interval is 0.57 ± 1.96(0.0157) = 0.57 ± 0.031, or between 53.9% and 60.1%.]
The critical z-scores associated with the 95% level are ±1.96. Thus the confidence interval is 0.57 ± 1.96(0.0157) = 0.57 ± 0.031, or between 53.9% and 60.1%.]
Third, interpret in context:
We are 95% confident that between 53.9% and 60.1% of all voters believe competence is more important than character.
(b) Explain to your parents that by using a measurement from a sample we are never able to say exactly what a population proportion is; rather we are only able to say we are confident that it is within some range of values, in this case between 53.9% and 60.1%.
(c) In 95% of all possible samples of 1000 voters, the method used gives an estimate that is within three percentage points of the true answer.
2. (a) First, identify the confidence interval and check the conditions:
This is a one-sample z-interval for the proportion of family members who come down with H1N1 after an initial family member does in this state, that is, 
It is given that this is a random sample, and we calculate n = 129 10 and n(1 – ) = 747 10.
Second, calculate the interval:
Calculator software (such as 1-PropZInt on the TI-84) gives (0.12757, 0.16695).
[For instructional purposes in this review book, we note that  and 0.147 ± 1.645
and 0.147 ± 1.645 
Third, interpret in context:
We are 90% confident that the proportion of family members who come down with H1N1 after an initial family member does in this state is between 0.127 and 0.167.
(b) Because 1/8 = 0.125 is not in the interval of plausible values for the population proportion, there is evidence that the proportion of family members who come down with H1N1 after an initial family member does in this state is different from the 1 in 8 chance concluded in the published study.
(c) 0.147 ± 2.576  = 0.147 ± 0.031 or (0.116, 0.178) which does include 0.125, so in this case there is not evidence that the proportion of family members who come down with H1N1 after an initial family member does in this state is different from the 1 in 8 chance concluded in the published study.
= 0.147 ± 0.031 or (0.116, 0.178) which does include 0.125, so in this case there is not evidence that the proportion of family members who come down with H1N1 after an initial family member does in this state is different from the 1 in 8 chance concluded in the published study.
3. (a) First, identify the confidence interval and check the conditions:
This is a two-sample z-interval for pUS – pUK, the difference in population proportions of new births to unmarried women in the United States and United Kingdom, that is,

It is given that these are random samples, they are clearly independent, and we calculate nUS US = (500)(0.412) = 206 10,
nUS (1 – US) = (500)(0.588) = 294 10,
nUK UK = (400)(0.465) = 186 10, and
nUK (1 – UK) = (400)(0.535) = 214 10.
Second, calculate the interval:
Calculator software (such as 2-PropZInt on the TI-84) gives (–0.1182, 0.01219). [For instructional purposes in this review book, we note that:

Third, interpret in context:
We are 95% confident that the difference in proportions, pUS – pUK, of new births to unmarried women in the United States and United Kingdom is between –0.118 and 0.012.
(b) Because 0 is in the interval of plausible values for the difference of population proportions, this confidence interval does not support the belief by the UN health care statistician that the proportions of new births to unmarried women is different in the United States and United Kingdom.
4. (a) We are calculating one-sample t-intervals for the mean price of gas in inner city stations and for the mean price of gas in suburban stations. In each case, we are given random samples and the sample sizes of 40 and 120 are large enough so that by the CLT the distributions of sample means are approximately normal and t-intervals may be found. We assume that the sample sizes are less than 10% of the populations of all gas stations. Calculator software (such as TInterval on the TI-84) gives (3.434, 3.466) for inner city stations and (3.3655, 3.3945) for suburban stations. That is, we are 95% confident that the mean price for gas in inner city stations is between $3.434 and $3.466, and are 95% confident that the mean price for gas in suburban stations is between $3.3655 and $3.3945.
(b) Because the sample size of inner city stations is smaller.
(c) Yes, because the standard deviation of the set of sample means is  0.0079, and so $3.50 is more than three standard deviations away from $3.45. Thus the probability that the true mean is this far from the sample mean is extremely small.
0.0079, and so $3.50 is more than three standard deviations away from $3.45. Thus the probability that the true mean is this far from the sample mean is extremely small.
5. (a) We are calculating a one-sample t-interval for the mean number of riders per car during rush hour. We are given a random sample, the sample size of 30 is assumed to be less than 10% of all subway cars, and assuming that the sample data are unimodal and reasonably symmetric with no extreme values, the sample size of 30 is large enough so that by the CLT the distribution of sample means is approximately normal and a t-interval may be found. Calculator software (such as TInterval on the TI-84) gives (81.67, 85.33). [For instructional purposes in this review book, we note that: With df = n – 1 = 29, the critical t-scores from Table B (or from InvT on the TI-84) are ±1.699, and  We are 90% confident that the mean number of riders per car during rush hour is between 81.67 and 85.33.
We are 90% confident that the mean number of riders per car during rush hour is between 81.67 and 85.33.
(b)  so you must choose a random sample of at least 95 subway cars.
so you must choose a random sample of at least 95 subway cars.
6. (a) Calculator software (such as TInterval on the TI-84) gives (–29,337, 421,337), or we are 95% confident that the mean salary of all basketball salaries from the population from which this sample was taken is between –$29,337 and $421,337. [For instructional purposes in this review book, we note that with df = 9,

(b) We must assume the sample is an SRS and that basketball salaries are normally distributed. This does not seem reasonable—the salaries are probably strongly skewed to the right by a few high ones. With the given mean and standard deviation, and noting that salaries are not negative, clearly we do not have a normal distribution, and furthermore, the sample size, n = 10, is too small to invoke the CLT. The calculated confidence interval is not meaningful.
7. This is a one-sample t-interval for the mean number of calories of all breakfast cereals. We are given that we have a random sample, and the nearly normal condition seems reasonable from, for example, either a stemplot or a normal probability plot:

Under these conditions the mean calories can be modeled by a t-distribution with n – 1 = 10 – 1 = 9 degrees of freedom.
Calculator software (such as TInterval using Data on the TI-84) gives (195.32, 215.68). [For instructional purposes in this review book, we note that a one-sample t-interval for the mean gives:

We are 95% confident that the true mean number of calories of all breakfast cereals is between 195.3 and 215.7.
8. (a) First, identify the confidence interval and check the conditions:
This is a two-sample t-interval for µNRW – µRW, the difference in population means of BPA body concentrations in non-retail workers and retail workers, that is,

It is given that these are random samples, it is reasonable to assume the samples are independent, and both samples sizes (528 and 197) are large enough so that by the CLT, the distributions of sample means are approximately normal and a t-interval may be found.
Second, calculate the interval:
Calculator software (such as 2-SampTInt on the TI-84) gives (–0.9521, –0.7479) with df = 332.3.
Third, interpret in context:
We are 99% confident that the difference in means of BPA body concentrations in non-retail and retail workers (non-retail mean minus retail mean) is between –0.75 and –0.95 µg/L.
(b) Because 0 is not in the interval of plausible values for the difference of population means, and the entire interval is negative, the interval does support the belief that retail workers carry higher amounts of BPA in their bodies than non-retail workers.
9. We first check conditions: we must assume use of randomization. The scatterplot is roughly linear, and there is no apparent pattern in the residuals plot.

The distribution of the residuals is very roughly normal.

(a) Now using the statistics software on a calculator gives

(b) Using calculator software (such as LinRegTInt on the TI-84 with the data in Lists) gives (2.1631, 3.1898). We are 90% confident that each additional gram of the new drug is associated with an average of between 2.16 and 3.19 more hours of allergy relief.
10. (a) Assuming that all assumptions for regression are met, the y-intercept and slope of the equation are found in the Coeff column of the computer printout.

where both the selling price and the assessed value are in $1000.
(b) From the printout, the standard error of the slope is sb1= 0.08192. With df = 18 and 0.005 in each tail, the critical t-values are ±2.878. The 99% confidence interval of the true slope is:

We are 99% confident that for every $1 increase in assessed value, the average increase in selling price is between $0.79 and $1.27 (or for every $1000 increase in assessed value, the average increase in selling price is between $790 and $1270).
11. (a)  So the margin of error is ±2.65%.
So the margin of error is ±2.65%.
(b) We are 95% confident that between 71.35% and 76.65% of smokers would like to give up smoking.
(c) If this survey were conducted many times, we would expect about 95% of the resulting confidence intervals to contain the true proportion of smokers who would like to give up smoking.
(d) Smoking is becoming more undesirable in society as a whole, so some smokers may untruthfully say they would like to stop.
(e) To be more confident we must accept a wider interval.
(f) All other things being equal, the greater the sample size, the smaller the margin of error.
AN INVESTIGATIVE TASK
(a) 
(b) 33.9% of the variability in career earnings is associated with years as a pro. However, looking at the scatterplot, if Serena’s data point, (18, 54.38), is removed, there appears to be no linear relationship at all. (Serena’s data point is called an influential point.)
(c) 2.69 + 1.6752(15) = $27.82 million, and 2.69 + 1.6752(30) = $52.95 million. The estimate for 15 years might be reasonable, but the one for 30 years is not; it is an extrapolation far from the given sample data points.
(d) We note that the scatterplot looks very roughly linear, there is no major pattern in the residual plot, and the histogram of residuals is very roughly unimodal and symmetric. With df = n – 2 = 8 and 90% confidence, Table B, the t-distribution table, gives critical t-scores of ±1.860. Then 1.6752 ± 1.860(0.8264) = 1.6752 ± 1.537. We are 90% confident that the true slope of the regression line linking career earnings to years as a pro is between $0.138 million and $3.212 million. The interpretation in context: We are 90% confident that for each additional year as a tennis professional, the career earnings go up by between $0.138 million and $3.212 million, on average.
(e) 2.69 ± 1.860(10.78) = 2.69 ± 20.05. We are 90% confident that the true y-intercept of the regression line linking career earnings to years as a pro is between –$17.36 million and $22.74 million. The interpretation in context: This y-intercept has no meaning in context because it references career earnings when there are 0 years as a pro.
(f) The model with 0 intercept makes more sense in this situation. When there are 0 years as a pro, the career earnings should be 0.
LOGIC OF SIGNIFICANCE TESTING
NULL AND ALTERNATIVE HYPOTHESES
P-VALUES
TYPE I AND TYPE II ERRORS
CONCEPT OF POWER
HYPOTHESIS TESTING
Closely related to the problem of estimating a population proportion or mean is the problem of testing a hypothesis about a population proportion or mean. For example, a travel agency might determine an interval estimate for the proportion of sunny days in the Virgin Islands or, alternatively, might test a tourist bureau’s claim about the proportion of sunny days. A major stockholder in a construction company might ascertain an interval estimate for the proportion of successful contract bids or, alternatively, might test a company spokesperson’s claim about the proportion of successful bids. A consumer protection agency might determine an interval estimate for the mean nicotine content of a particular brand of cigarettes or, alternatively, might test a manufacturer’s claim about the mean nicotine content of its cigarettes. An agricultural researcher could find an interval estimate for the mean productivity gain caused by a specific fertilizer or, alternatively, might test the developer’s claimed mean productivity gain. In each of these cases, the experimenter must decide whether the interest lies in an interval estimate of a population proportion or mean or in a hypothesis test of a claimed proportion or mean.
LOGIC OF SIGNIFICANCE TESTING, NULL AND ALTERNATIVE HYPOTHESIS, P-VALUES, ONE- AND TWO-SIDED TESTS, TYPE I AND TYPE II ERRORS, AND THE CONCEPT OF POWER
The general testing procedure is to choose a specific hypothesis to be tested, called the null hypothesis, pick an appropriate random sample, and then use measurements from the sample to determine the likelihood of the null hypothesis. If the sample statistic is far enough away from the claimed population parameter, we say that there is sufficient evidence to reject the null hypothesis. We attempt to show that the null hypothesis is unacceptable by showing that it is improbable.
Consider the context of the population proportion. The null hypothesis H0 is stated in the form of an equality statement about the population proportion (for example, H0: p = 0.37). There is an alternative hypothesis, stated in the form of an inequality (for example, Ha: p < 0.37 or Ha: p > 0.37 or Ha: p ≠ 0.37). The strength of the sample statistic $\widehat{p}$ can be gauged through its associated P–value, which is the probability of obtaining a sample statistic as extreme (or more extreme) as the one obtained if the null hypothesis is assumed to be true. The smaller the P-value, the more significant the difference between the null hypothesis and the sample results.
TIP
Never base your hypotheses on what you find in the sample data.
Note that only population parameter symbols appear in H0 and Ha. Sample statistics like $\overline{x}$ and $\widehat{p}$ do NOT appear in H0 or Ha.
There are two types of possible errors: the error of mistakenly rejecting a true null hypothesis and the error of mistakenly failing to reject a false null hypothesis. The $\alpha$-risk, also called the significance level of the test, is the probability of committing a Type I error and mistakenly rejecting a true null hypothesis. A Type II error, a mistaken failure to reject a false null hypothesis, has associated probability $\beta$. There is a different value of $\beta$ for each possible correct value for the population parameter p. For each $\beta$, 1 – $\beta$ is called the power of the test against the associated correct value. The power of a hypothesis test is the probability that a Type II error is not committed. That is, given a true alternative, the power is the probability of rejecting the false null hypothesis. Increasing the sample size and increasing the significance level are both ways of increasing the power.
TIP
The P-value relates to the probability of the data given that the null hypothesis is true; it is not the probability of the null hypothesis being true.

A simple illustration of the difference between a Type I and a Type II error is as follows: Suppose the null hypothesis is that all systems are operating satisfactorily with regard to a NASA liftoff. A Type I error would be to delay the liftoff mistakenly thinking that something was malfunctioning when everything was actually OK. A Type II error would be to fail to delay the liftoff mistakenly thinking everything was OK when something was actually malfunctioning. The power is the probability of recognizing a particular malfunction. (Note the complimentary aspect of power, a “good” thing, with Type II error, a “bad” thing.)
TIP
Understand that the sample statistic almost never equals the claimed population parameter. Either the sample statistic differs by random chance, or the claimed parameter is wrong.
Our justice system provides another often quoted illustration. If the null hypothesis is that a person is innocent, then a Type I error results when an innocent person is found guilty, while a Type II error results when a guilty person is not convicted. We try to minimize Type I errors in criminal trials by demanding unanimous jury guilty verdicts. In civil suits, however, many states try to minimize Type II errors by accepting simple majority verdicts.
It should be emphasized that with regard to calculations, questions like “What is the power of this test?” and “What is the probability of a Type II error in this test?” cannot be answered without reference to a specific alternative hypothesis. Furthermore, AP students are not required to know how to calculate these probabilities. However, they are required to understand the concepts and interactions among the concepts.
TIP
Be able to identify Type I and Type II errors and give possible consequences of each.
HYPOTHESIS TEST FOR A PROPORTION
We must check that we have a simple random sample, that both np0 and n(1 – p0) are at least 10, and that the sample size is less than 10% of the population.
TIP
Always check assumptions/conditions before proceeding with a test.
EXAMPLE 14.1
A union spokesperson claims that 75% of union members will support a strike if their basic demands are not met. A company negotiator believes the true percentage is lower and runs a hypothesis test. What is the conclusion if 87 out of an SRS of 125 union members say they will strike?
Answer: We note that np0 = (125)(0.75) = 93.75 and n(1 – p0) = (125)(0.25) = 31.25 are both $\geq$ 10 and that we have an SRS, and we assume that 125 is less than 10% of the total union membership.
![]()
TIP
Hypotheses are always about the population, never about a sample; note H0 is p = 0.75, not $\widehat{p}$ = 0.75.
Calculator software (such as 1-PropZTest on the TI-84) gives z = –1.394 and P = 0.0816. [For instructional purposes in this review book, we note that the observed sample proportion is ![]() and using the claimed proportion, 0.75, we have
and using the claimed proportion, 0.75, we have ![]() with a resulting P-value of 0.0817.]
with a resulting P-value of 0.0817.]
TIP
Always give a conclusion in context.
There are two possible answers: With this large a P-value, 0.0816 > 0.05, there is not sufficient evidence to reject H0, that is, there is not sufficient evidence that the true percentage of union members who support a strike is less than 75%.
OR With this small a P-value, 0.0816 < 0.10, there is sufficient evidence to reject H0, that is, there is sufficient evidence that the true percentage of union members who support a strike is less than 75%.
TIP
We never “accept” a null hypothesis; we either do or do not have evidence to reject it.
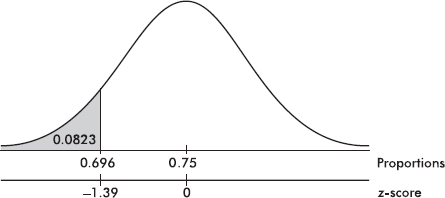
On the TI-Nspire the result shows as:

TIP
Although performing hypotheses tests using formulas is not necessary on free-response questions, answer choices using formulas may well appear on multiple-choice questions.
TIP
If the question does not suggest a direction for the alternative, then use a two-sided test.
EXAMPLE 14.2
A cancer research group surveys a random sample of 500 women more than 40 years old to test the hypothesis that 28% of women in this age group have regularly scheduled mammograms. Should the hypothesis be rejected at the 5% significance level if 151 of the women respond affirmatively?
Answer: Note that np0 = (500)(0.28) = 140 and n(1 – p0) = (500)(0.72) = 360 are both $\geq$10, we are given a random sample, and clearly 500 < 10% of all women over 40 years old. Since no suspicion is voiced that the 28% claim is low or high, we run a two-sided z-test for proportions:
![]()
TIP
Remember: when we fail to reject H0, we are not accepting it; it simply means that there is not sufficient evidence against H0, that is, we cannot rule out random chance as the explanation.
Calculator software (such as 1-PropZTest on the TI-84) gives z = 1.0956 and P = 0.2732. [For instructional purposes, we note that the observed ![]()
![]() which corresponds to a tail probability of 0.1366. Doubling this value (because the test is two-sided) gives a P-value of 0.2732.] With this large a P-value, 0.2732 > 0.05, there is not sufficient evidence to reject H0, that is, the cancer research group should not dispute the 28% claim.
which corresponds to a tail probability of 0.1366. Doubling this value (because the test is two-sided) gives a P-value of 0.2732.] With this large a P-value, 0.2732 > 0.05, there is not sufficient evidence to reject H0, that is, the cancer research group should not dispute the 28% claim.
HYPOTHESIS TEST FOR A DIFFERENCE BETWEEN TWO PROPORTIONS
As with confidence intervals for the difference of two proportions, $n_1\widehat{p}_1$, n1(1 – $\widehat{p}$1), n2$\widehat{p}$2, and n2(1 – $\widehat{p}$2) should all be at least 10, it is important both that the samples be simple random samples and that they be taken independently of each other, and the original populations should be large compared to the sample sizes.
TIP
The samples must be independent to use these two sample proportion methods.
The fact that a sample proportion from one population is greater than a sample proportion from a second population does not automatically justify a similar conclusion about the population proportions themselves. Two points need to be stressed. First, sample proportions from the same population can vary from each other. Second, what we are really comparing are confidence interval estimates, not just single points.
For many problems the null hypothesis states that the population proportions are equal or, equivalently, that their difference is 0:
H0: p1 – p2 = 0
The alternative hypothesis is then
Ha: p1 – p2 < 0 Ha: p1 – p2 > 0 or Ha: p1 – p2 ≠ 0
where the first two possibilities lead to one-sided tests and the third possibility leads to two-sided tests.
Since the null hypothesis is that p1 = p2, we call this common value p and use this pooled value in calculating σd:
![]()
In practice, if ![]() as an estimate of p in calculating σd.
as an estimate of p in calculating σd.
TIP
This is the one situation where it is necessary to use a pooled proportion.
EXAMPLE 14.3
Suppose that early in an election campaign a telephone poll of 800 randomly chosen registered voters shows 460 in favor of a particular candidate. Just before election day, a second poll shows only 520 of 1000 randomly chosen registered voters expressing the same preference. Is there sufficient evidence that the candidate’s popularity has decreased?
Answer: Note that n1 $\widehat{p}$1 = 460, n1(1 – $\widehat{p}$1) = 340, n2 $\widehat{p}$2 = 520, and n2(1 – $\widehat{p}$2) = 480 are all at least 10 (where n1 and $\widehat{p}$1 refer to the first poll, ,and n2 and $\widehat{p}$2 refer to the second poll), we are given that the samples are random and independent by design, and clearly the total population of registered voters is large.
![]()
Calculator software (such as 2-PropZTest on the TI-84) gives z = 2.328 and P = 0.00995. [For instructional purposes, we note that the observed difference is 0.575 – 0.520 = ![]() and the tail probability gives P = 0.0099.] With this small a P-value, 0.00995 < 0.05, there is sufficient evidence to reject H0, that is, there is sufficient evidence that the candidate’s popularity has dropped.
and the tail probability gives P = 0.0099.] With this small a P-value, 0.00995 < 0.05, there is sufficient evidence to reject H0, that is, there is sufficient evidence that the candidate’s popularity has dropped.
TIP
Along with the P-value, you should also give the test statistic, as we have been doing.
EXAMPLE 14.4
An automobile manufacturer tries two distinct assembly procedures. In a random sample of 350 cars coming off the line using the first procedure there are 28 with major defects, while a random sample of 500 autos from the second line shows 32 with defects. Is the difference significant at the 10% significance level?
Answer: Note that n1 $\widehat{p}$1 = 28, n1(1 – $\widehat{p}$1) = 322, n2 $\widehat{p}$2 = 32, and n2(1 – $\widehat{p}$2) = 468 are all at least 10 (where n1 and $\widehat{p}$1 refer to the sample of cars using the first procedure, and n2 and $\widehat{p}$2 refer to the sample of cars using the second procedure), we are given that the samples are random and independent by design, and the total population of autos manufactured at the plant is large. Since there is no mention that one procedure is believed to be better or worse than the other, this is a two-sided test.
![]()
Calculator software (such as 2-PropZTest on the TI-84) gives z = 0.8963 and P = 0.3701. [For instructional purposes, we note that the observed difference is 0.080 – 0.064 = ![]()
![]() which corresponds to a tail probability of 0.1850. Doubling this value (because the test is two-sided) gives a P-value of 0.3700.] With this large a P-value, 0.3700 > 0.05, there is not sufficient evidence to reject H0, that is, there is not sufficient evidence of a significant difference in proportions of cars with major defects coming from the two assembly procedures.
which corresponds to a tail probability of 0.1850. Doubling this value (because the test is two-sided) gives a P-value of 0.3700.] With this large a P-value, 0.3700 > 0.05, there is not sufficient evidence to reject H0, that is, there is not sufficient evidence of a significant difference in proportions of cars with major defects coming from the two assembly procedures.
We must check that we have a simple random sample, that the sample size is less than 10% of the population, and that the distribution of sample means is approximately normal, which follows if either the sample size is large enough for the CLT to apply or the population has an approximately normal distribution (if we are given the sample data, we check the normality assumption with a graph such as a histogram or a normal probability plot: the histogram should be unimodal and reasonably symmetric, although this condition can be relaxed the larger the sample size.)
EXAMPLE 14.5
A manufacturer claims that a new brand of air-conditioning unit uses only 6.5 kilowatts of electricity per day. A consumer agency believes the true figure is higher and runs a test on a random sample of size 50. If the sample mean is 7.0 kilowatts with a standard deviation of 1.4, should the manufacturer’s claim be rejected at a significance level of 5%? Of 1%?
Answer: We are given a random sample, n = 50 is large enough for the CLT to apply so the distribution of sample means is approximately normal, and we can assume that 50 is less than 10% of all of the new AC units. The population SD is unknown, so a t-test is called for with H0: μ = 6.5 and Ha: μ > 6.5. Calculator software (such as T-Test on the TI-84) gives t = 2.525 and P = 0.0074. [For instructional purposes, we note that ![]() with a resulting P-value of 0.0074.] With this small a P-value, 0.0074 < 0.05, there is sufficient evidence to reject H0, that is, there is sufficient evidence for the consumer agency to reject the manufacturer’s claim that the new unit uses a mean of only 6.5 kilowatts of electricity per day.
with a resulting P-value of 0.0074.] With this small a P-value, 0.0074 < 0.05, there is sufficient evidence to reject H0, that is, there is sufficient evidence for the consumer agency to reject the manufacturer’s claim that the new unit uses a mean of only 6.5 kilowatts of electricity per day.
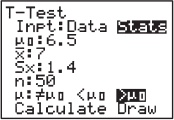
EXAMPLE 14.6
A local chamber of commerce claims that the mean sale price for homes in the city is $90,000. A real estate salesperson notes a random sample of eight recent sales of \$75,000, \$102,000, \$82,000, \$87,000, \$77,000, \$93,000, \$98,000, and \$68,000. How strong is the evidence to reject the chamber of commerce claim?
Answer: We are given a random sample, we can assume n = 8 is less than 10% of all home sales, and we check for normality with a histogram, which yields the roughly unimodal, roughly symmetric:
The population SD is unknown, so a t-test is called for with H0: μ = 90,000 and Ha: μ ≠ 90,000. Putting the data into a List, calculator software (such as T-Test on the TI-84) gives t = –1.131 and P = 0.2953. With such a large P-value, 0.2953 > 0.05, there is not sufficient evidence to reject H0, that is, there is not sufficient evidence to reject the commerce claim of a mean sale price of $90,000 for homes in the city.
On the TI-Nspire the result shows as:
HYPOTHESIS TEST FOR A DIFFERENCE BETWEEN TWO MEANS (UNPAIRED AND PAIRED)
We assume that we have two independent simple random samples, each from an approximately normally distributed population (the normality assumptions can be relaxed if the sample sizes are large).
In this situation the null hypothesis is usually that the means of the populations are the same or, equivalently, that their difference is 0:
H0: µ1 – µ2 = 0
The alternative hypothesis is then
Ha: µ1 – µ2 < 0 Ha: µ1 – µ2 > 0 or Ha: µ1 – µ2 ≠ 0
The first two possibilities lead to one-sided tests, and the third possibility leads to two-sided tests.
EXAMPLE 14.7
A sales representative believes that his company’s computer has more average downtime per week than a similar computer sold by a competitor. Before taking this concern to his director, the sales representative gathers data and runs a hypothesis test. He determines that in a simple random sample of 40 week-long periods at different firms using his company’s product, the average downtime was 125 minutes with a standard deviation of 37 minutes. However, 35 week-long periods involving the competitor’s computer yield an average downtime of only 115 minutes with a standard deviation of 43 minutes. What conclusion should the sales representative draw?
TIP
Avoid “calculator speak.” For example, do not simply write “2-SampTTest…” or “binomcdf…” There are lots of calculators out there, each with its own abbreviations.
Answer: We are given independent SRSs, the sample sizes can be assumed to be less than 10% of all possible weeks and are large enough to relax the normality assumptions. The population SDs are unknown, so a t-test is called for with
H0: µ1 – µ2 = 0 (where µ1 = mean down time of company’s computers
Hα: µ1 – µ2 > 0 and µ2 = mean down time of competitor’s computers)
Calculator software (such as 2-SampTTest on the TI-84) gives t = 1.0718 and P = 0.1438. With this large a P-value, 0.1438 > 0.05, there is not sufficient evidence to reject H0, that is, the sales representative does not have sufficient evidence that his company’s computers have greater mean downtime than that of the competitor’s computers.
TIP
While the normal probability plot is not part of the AP Stat curriculum, it is useful and is accepted on the exam.
EXAMPLE 14.8
A city council member claims that male and female officers wait equal times for promotion in the police department. A women’s spokesperson, however, believes women must wait longer than men. If a random sample of five men waited 8, 7, 10, 5, and 7 years, respectively, for promotion while a random sample of four women waited 9, 5, 12, and 8 years, respectively, what conclusion should be drawn?
Answer: We are given random samples and must assume they are independent and less than 10% of total numbers of male and female officers. These samples are too small for histograms to show anything other than no outliers, but the normal probability plots are fairly linear indicating that it is not unreasonable to assume the data come from roughly normal distributions:
The population SDs are unknown, so a t-test is called for with H0: µM = µF and Hα: µM < µF. Putting the data into Lists, calculator software (such as 2-SampTTest on the TI-84) gives t = –0.6641 and P = 0.2685. With this large a P-value, 0.2685 > 0.05, there is not sufficient evidence to reject H0, that is, there is not sufficient evidence to dispute the council member’s claim that male and female officers wait equal times for promotion.
The analysis and procedure described above require that the two samples being compared be independent of each other. However, many experiments and tests involve comparing two populations for which the data naturally occur in pairs. In this case, the proper procedure is to run a one-sample test on a single variable consisting of the differences from the paired data.
EXAMPLE 14.9
Does a particular drug slow reaction times? If so, the government might require a warning label concerning driving a car while taking the medication. An SRS of 30 people who might benefit from the drug are tested before and after taking the drug, and their reaction times (in seconds) to a standard testing procedure are noted. The resulting data are as follows:
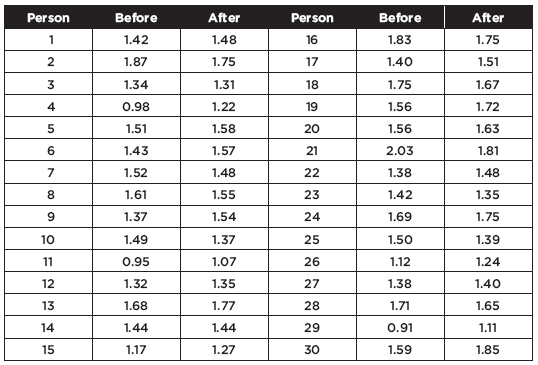
TIP
When the data comes in pairs, you cannot use a two sample t-test.
We can calculate the mean reaction times before and after, 1.46 seconds and 1.50 seconds, respectively, and ask if this observed rise is significant. If we performed a two-sample test, we would calculate the P-value to be 0.2708 and would conclude that with such a large P, the observed rise is not significant. However, this would not be the proper test or conclusion! The two-sample test works for independent sets. However, in this case, there is a clear relationship between the data, in pairs, and this relationship is completely lost in the procedure for the two-sample test. The proper procedure is to form the set of 30 differences, being careful with signs, {–0.06, 0.12, 0.03, –0.24, …}, and to perform a single sample hypothesis test as follows:
Name the test:
We are using a paired t-test, that is, a single sample hypothesis test on the set of differences.
State the hypothesis:
H0: The reaction times of individuals to a standard testing procedure are the same before and after they take a particular drug; the mean difference is zero: µd = 0.
Ha: The reaction time is greater after they take the drug; the mean difference is less than zero: µd < 0.
Check the conditions:
1. The data are paired because they are measurements on the same individuals before and after taking the drug.
2. The reaction times of any individual are independent of the reaction times of the others, so the differences are independent.
3. A random sample of people are tested.
4. The histogram of the differences looks nearly normal (roughly unimodal and symmetric):
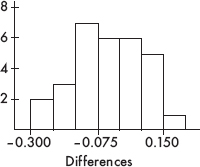
5. The sample size, n = 30, is less than 10% of the population of all people who may take the drug.
Perform the mechanics:
Putting the data into lists, say L1 and L2, then L1 – L2 Æ L3, calculator software (such as T-Test on the TI-84) on the data in L3 gives t = –1.755 with P = 0.0449. [For instructional purposes, we note that a calculator readily gives: n = 30, x = –0.037667, and s = 0.11755.
Then ![]() and
and
![]()
With df = n – 1 = 29, the P-value is P(t < –1.755) = 0.0449.]
Give a conclusion in context:
With this small a P-value, 0.0449 < 0.05, there is sufficient evidence to reject H0, that is, there is sufficient evidence that the mean observed rise in reaction times after taking the drug is significant.
MORE ON POWER AND TYPE II ERRORS
Given a specific alternative hypothesis, a Type II error is a mistaken failure to reject the false null hypothesis, while the power is the probability of rejecting that false null hypothesis.
EXAMPLE 14.10
A candidate claims to have the support of 70% of the people, but you believe that the true figure is lower. You plan to gather an SRS and will reject the 70% claim if in your sample shows 65% or less support. What if in reality only 63% of the people support the candidate?
TIP
You will not have to calculate actual probabilities of Type II errors or power.
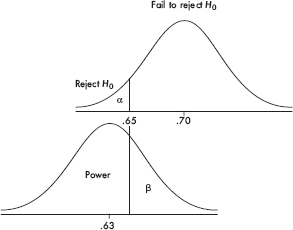
The upper graph shows the null hypothesis model with the claim that p0 = 70, and the plan to reject H0 if $\widehat{p}$ < 0.65. The lower graph shows the true model with p = 0.63. When will we fail to pick up that the null hypothesis is incorrect? Answer: precisely when the sample proportion is greater than 0.65. This is a Type II error with probability $\beta$. When will we rightly conclude that the null hypothesis is incorrect? Answer: when the sample proportion is less than 0.65. This is the power of the test and has probability 1 – $\beta$.
TIP
While calculations are not called for, you must understand the interactions among the errors, confidence level, power, effect, and sample size.
The following points should be emphasized:
Power gives the probability of avoiding a Type II error.
Power has a different value for different possible correct values of the population parameter; thus it is actually a function where the independent variable ranges over specific alternative hypotheses.
Choosing a smaller $\alpha$ (that is, a tougher standard to reject H0) results in a higher risk of Type II error and a lower power—observe in the above graphs how making $\alpha$ smaller (in this case moving the critical cutoff value to the left) makes the power less and $\beta$ more!
The greater the difference between the null hypothesis p0 and the true value p, the smaller the risk of a Type II error and the greater the power—observe in the above picture how moving the lower graph to the left makes the power greater and $\beta$ less. (The difference between p0 and p is sometimes called the effect—thus the greater the effect, the greater is the power to pick it up.)
A larger sample size n will reduce the standard deviations, making both graphs narrower resulting in smaller $\alpha$, smaller $\beta$, and larger power!
TIP
Both blocking in experiments and stratification in sampling reduce variability and so can improve power.
CONFIDENCE INTERVALS VERSUS HYPOTHESIS TESTS
A question sometimes arises as to whether a problem calls for calculating a confidence interval or performing a hypothesis test. Generally, a claim about a population parameter indicates a hypothesis test, while an estimate of a population parameter asks for a confidence interval. However, some confusion may arise because sometimes it is possible to conduct a hypothesis test by constructing a confidence interval estimate of the parameter and then checking whether or not the null parameter value is in the interval. While, when possible, this alternative approach is accepted on the AP exam, it does require very special care in still remembering to state hypotheses, in dealing with one-sided versus two-sided, and in how standard errors are calculated in problems involving proportions. So the recommendation is to conduct a hypothesis test like a hypothesis test. Carefully read the question. If it asks whether or not there is evidence, then this is a hypothesis test; if it involves how much or how effective, then this is a confidence interval calculation. However, it should be noted that there have been AP free-response questions where part (a) calls for a confidence interval calculation and part (b) asks if this calculation provides evidence relating to a hypothesis test.
SUMMARY
Important assumptions/conditions always must be checked before proceeding with a hypothesis test.
The null hypothesis is stated in the form of an equality statement about a population parameter, while the alternative hypothesis is in the form of an inequality.
We attempt to show that a null hypothesis is unacceptable by showing it is improbable.
The P-value is the probability of obtaining a sample statistic as extreme (or more extreme) as the one obtained if the null hypothesis is assumed to be true.
When the P-value is small (typically, less than 0.05 or 0.10), we say we have evidence to reject the null hypothesis.
A Type I error is the probability of mistakenly rejecting a true null hypothesis.
A Type II error is the probability of mistakenly failing to reject a false null hypothesis.
The power of a hypothesis test is the probability that a Type II error is not committed.
Multiple-Choice Questions
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. Which of the following is a true statement?
(A) A well-planned hypothesis test should result in a statement either that the null hypothesis is true or that it is false.
(B) The alternative hypothesis is stated in terms of a sample statistic.
(C) If a sample is large enough, the necessity for it to be a simple random sample is diminished.
(D) When the null hypothesis is rejected, it is because it is not true.
(E) Hypothesis tests are designed to measure the strength of evidence against the null hypothesis.
2. Which of the following is a true statement?
(A) The P-value of a test is the probability of obtaining a result as extreme (or more extreme) as the one obtained assuming the null hypothesis is false.
(B) If the P-value for a test is 0.015, the probability that the null hypothesis is true is 0.015.
(C) The larger the P-value, the more evidence there is against the null hypothesis.
(D) If possible, always examine your data before deciding whether to use a one-sided or two-sided hypothesis test.
(E) The alternative hypothesis is one-sided if there is interest in deviations from the null hypothesis in only one direction.
Questions 3–4 refer to the following:
Video arcades provide a vehicle for competition and status within teenage peer groups and are recognized as places where teens can hang out and meet their friends. The national PTA organization, concerned about the time and money being spent in video arcades by middle school students, commissions a statistical study to investigate whether or not middle school students are spending an average of over two hours per week in video arcades. Twenty communities are randomly chosen, five middle schools are randomly picked in each of the communities, and ten students are randomly interviewed at each school.
3. What is the parameter of interest?
(A) Video arcades
(B) A particular concern of the national PTA organization
(C) 1000 randomly chosen middle school students
(D) The mean amount of money spent in video arcades by middle school students
(E) The mean number of hours per week spent in video arcades by middle school students
4. What are the null and alternative hypotheses which the PTA is testing?
(A) H0: µ = 2Ha: µ < 2
(B) H0: µ = 2Ha: µ ≤ 2
(C) H0: µ = 2Ha: µ > 2
(D) H0: µ = 2Ha: µ $\geq$ 2
(E) H0: µ = 2Ha: µ ≠ 2
5. A hypothesis test comparing two population proportions results in a P-value of 0.032. Which of the following is a proper conclusion?
(A) The probability that the null hypothesis is true is 0.032.
(B) The probability that the alternative hypothesis is true is 0.032.
(C) The difference in sample proportions is 0.032.
(D) The difference in population proportions is 0.032.
(E) None of the above are proper conclusions.
6. A company manufactures a synthetic rubber (jumping) bungee cord with a braided covering of natural rubber and a minimum breaking strength of 450 kg. If the mean breaking strength of a sample drops below a specified level, the production process is halted and the machinery inspected. Which of the following would result from a Type I error?
(A) Halting the production process when too many cords break.
(B) Halting the production process when the breaking strength is below the specified level.
(C) Halting the production process when the breaking strength is within specifications.
(D) Allowing the production process to continue when the breaking strength is below specifications.
(E) Allowing the production process to continue when the breaking strength is within specifications.
7. One ESP test asks the subject to view the backs of cards and identify whether a circle, square, star, or cross is on the front of each card. If p is the proportion of correct answers, this may be viewed as a hypothesis test with H0: p = 0.25 and Ha: p > 0.25. The subject is recognized to have ESP when the null hypothesis is rejected. What would a Type II error result in?
(A) Correctly recognizing someone has ESP
(B) Mistakenly thinking someone has ESP
(C) Not recognizing that someone really has ESP
(D) Correctly realizing that someone doesn’t have ESP
(E) Failing to understand the nature of ESP
8. A coffee-dispensing machine is supposed to deliver 12 ounces of liquid into a large paper cup, but a consumer believes that the actual amount is less. As a test he plans to obtain a sample of 5 cups of the dispensed liquid and if the mean content is less than 11.5 ounces, to reject the 12-ounce claim. If the machine operates with a known standard deviation of 0.9 ounces, what is the probability that the consumer will mistakenly reject the 12-ounce claim even though the claim is true?
(A) 0.054
(B) 0.107
(C) 0.214
(D) 0.289
(E) 0.393
9. A pharmaceutical company claims that a medicine will produce a desired effect for a mean time of 58.4 minutes. A government researcher runs a hypothesis test of 40 patients and calculates a mean of x = 59.5 with a standard deviation of s = 8.3. What is the P-value?

10. You plan to perform a hypothesis test with a level of significance of $\alpha$ = 0.05. What is the effect on the probability of committing a Type I error if the sample size is increased?
(A) The probability of committing a Type I error decreases.
(B) The probability of committing a Type I error is unchanged.
(C) The probability of committing a Type I error increases.
(D) The effect cannot be determined without knowing the relevant standard deviation.
(E) The effect cannot be determined without knowing if a Type II error is committed.
11. A fast food chain advertises that their large bag of french fries has a weight of 150 grams. Some high school students, who enjoy french fries at every lunch, suspect that they are getting less than the advertised amount. With a scale borrowed from their physics teacher, they weigh a random sample of 15 bags. What is the conclusion if the sample mean is 145.8 g and standard deviation is 12.81 g?
(A) There is sufficient evidence to prove the fast food chain advertisement is true.
(B) There is sufficient evidence to prove the fast food chain advertisement is false.
(C) The students have sufficient evidence to reject the fast food chain’s claim.
(D) The students do not have sufficient evidence to reject the fast food chain’s claim.
(E) There is not sufficient data to reach any conclusion.
12. A researcher believes a new diet should improve weight gain in laboratory mice. If ten control mice on the old diet gain an average of 4 ounces with a standard deviation of 0.3 ounces, while the average gain for ten mice on the new diet is 4.8 ounces with a standard deviation of 0.2 ounces, what is the P-value?
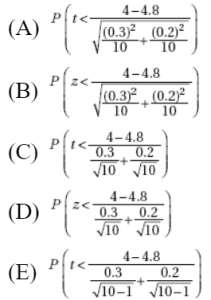
13. A school superintendent must make a decision whether or not to cancel school because of a threatening snow storm. What would the results be of Type I and Type II errors for the null hypothesis: The weather will remain dry?
(A) Type I error: don’t cancel school, but the snow storm hits.
Type II error: weather remains dry, but school is needlessly canceled.
(B) Type I error: weather remains dry, but school is needlessly canceled.
Type II error: don’t cancel school, but the snow storm hits.
(C) Type I error: cancel school, and the storm hits.
Type II error: don’t cancel school, and weather remains dry.
(D) Type I error: don’t cancel school, and snow storm hits.
Type II error: don’t cancel school, and weather remains dry.
(E) Type I error: don’t cancel school, but the snow storm hits.
Type II error: cancel school, and the storm hits.
14. A pharmaceutical company claims that 8% or fewer of the patients taking their new statin drug will have a heart attack in a 5-year period. In a government-sponsored study of 2300 patients taking the new drug, 198 have heart attacks in a 5-year period. Is this strong evidence against the company claim?
(A) Yes, because the P-value is 0.005657.
(B) Yes, because the P-value is 0.086087.
(C) No, because the P-value is only 0.005657.
(D) No, because the P-value is only 0.086087.
(E) No, because the P-value is over 0.10.
15. Is Internet usage different in the Middle East and Latin America? In a random sample of 500 adults in the Middle East, 151 claimed to be regular Internet users, while in a random sample of 1000 adults in Latin America, 345 claimed to be regular users. What is the P-value for the appropriate hypothesis test?

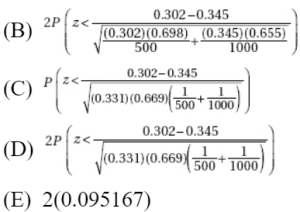
16. What is the probability of mistakenly failing to reject a false null hypothesis when a hypothesis test is being conducted at the 5% significance level ($\alpha$ = 0.05)?
(A) 0.025
(B) 0.05
(C) 0.10
(D) 0.95
(E) There is insufficient information to answer this question.
17. A research dermatologist believes that cancers of the head and neck will occur most often of the left side, the side next to a window when a person is driving. In a review of 565 cases of head/neck cancers, 305 occurred on the left side. What is the resulting p-value?

![]()
18. Suppose you do five independent tests of the form H0: µ = 38 versus Ha: µ > 38, each at the $\alpha$ = 0.01 significance level. What is the probability of committing a Type I error and incorrectly rejecting a true null hypothesis with at least one of the five tests?
(A) 0.01
(B) 0.049
(C) 0.05
(D) 0.226
(E) 0.951
19. Given an experiment with H0: µ = 35, Ha: µ < 35, and a possible correct value of 32, you obtain a sample statistic of $\overline{x}$ = 33. After doing analysis, you realize that the sample size n is actually larger than you first thought. Which of the following results from reworking with the increase in sample size?
(A) Decrease in probability of a Type I error; decrease in probability of a Type II error; decrease in power.
(B) Increase in probability of a Type I error; increase in probability of a Type II error; decrease in power.
(C) Decrease in probability of a Type I error; decrease in probability of a Type II error; increase in power.
(D) Increase in probability of a Type I error; decrease in probability of a Type II error; decrease in power.
(E) Decrease in probability of a Type I error; increase in probability of a Type II error; increase in power.
20. Thirty students volunteer to test which of two strategies for taking multiple-choice exams leads to higher average results. Each student flips a coin, and if heads, uses Strategy A on the first exam and then Strategy B on the second, while if tails, uses Strategy B first and then Strategy A. The average of all 30 Strategy A results is then compared to the average of all 30 Strategy B results. What is the conclusion at the 5% significance level if a two-sample hypothesis test, H0: µ1 = µ2, Ha: µ1 ≠ µ2, results in a P-value of 0.18?
(A) The observed difference in average scores is significant.
(B) The observed difference in average scores is not significant.
(C) A conclusion is not possible without knowing the average scores resulting from using each strategy.
(D) A conclusion is not possible without knowing the average scores and the standard deviations resulting from using each strategy.
(E) A two-sample hypothesis test should not be used here.
21. Choosing a smaller level of significance, that is, a smaller $\alpha$-risk, results in
(A) a lower risk of Type II error and lower power.
(B) a lower risk of Type II error and higher power.
(C) a higher risk of Type II error and lower power.
(D) a higher risk of Type II error and higher power.
(E) no change in risk of Type II error or in power.
22. The greater the difference between the null hypothesis claim and the true value of the population parameter,
(A) the smaller the risk of a Type II error and the smaller the power.
(B) the smaller the risk of a Type II error and the greater the power.
(C) the greater the risk of a Type II error and the smaller the power.
(D) the greater the risk of a Type II error and the greater the power.
(E) the greater the probability of no change in Type II error or in power.
23. A company selling home appliances claims that the accompanying instruction guides are written at a 6th grade reading level. An English teacher believes that the true figure is higher and with the help of an AP Statistics student runs a hypothesis test. The student randomly picks one page from each of 25 of the company’s instruction guides, and the teacher subjects the pages to a standard readability test. The reading levels of the 25 pages are given in the following table:
![]()
Is there statistical evidence to support the English teacher’s belief?
(A) No, because the P-value is greater than 0.10.
(B) Yes, the P-value is between 0.05 and 0.10 indicating some evidence for the teacher’s belief.
(C) Yes, the P-value is between 0.01 and 0.05 indicating evidence for the teacher’s belief.
(D) Yes, the P-value is between 0.001 and 0.01 indicating strong evidence for the teacher’s belief.
(E) Yes, the P-value is less than 0.001 indicating very strong evidence for the teacher’s belief.
24. Suppose H0: p = 0.4, and the power of the test for the alternative hypothesis p = 0.35 is 0.75. Which of the following is a valid conclusion?
(A) The probability of committing a Type I error is 0.05.
(B) The probability of committing a Type II error is 0.65.
(C) If the alternative p = 0.35 is true, the probability of failing to reject H0 is 0.25.
(D) If the null hypothesis is true, the probability of rejecting it is 0.25.
(E) If the null hypothesis is false, the probability of failing to reject it is 0.65.
25. A factory is located close to a city high school. The manager claims that the plant’s smokestacks spew forth an average of no more than 350 pounds of pollution per day. As an AP Statistics project, the class plans a one-sided hypothesis test with a critical value of 375 pounds. Suppose the standard deviation in daily pollution poundage is known to be 150 pounds and the true mean is 385 pounds. If the sample size is 100 days, what is the probability that the class will mistakenly fail to reject the factory manager’s false claim?
(A) 0.0475
(B) 0.2525
(C) 0.7475
(D) 0.7514
(E) 0.9525
Free-Reponse Questions
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your final answers.
TEN OPEN-ENDED QUESTIONS
1. Next to good brakes, proper tire pressure is the most crucial safety issue on your car. Incorrect tire pressure compromises cornering, braking, and stability. Both underinflation and overinflation can lead to problems. The number on the tire is the maximum allowable air pressure—not the recommended pressure for that tire. At a roadside vehicle safety checkpoint, officials randomly select 30 cars for which 35 psi is the recommended tire pressure and calculate the average of the actual tire pressure in the front right tires. What is the parameter of interest, and what are the null and alternative hypotheses that the officials are testing?
2. No vaccinations are 100% risk free, and the theoretical risk of rare complications always have to be balanced against the severity of the disease. Suppose the CDC decides that a risk of one in a million is the maximum acceptable risk of GBS (Guillain-Barre syndrome) complications for a new vaccine for a particularly serious strain of influenza. A large sample study of the new vaccine is conducted with the following hypotheses:
H0: The proportion of GBS complications is 0.000001 (one in a million)
Ha: The proportion of GBS complications is greater than 0.000001 (one in a million)
The P-value of the test is 0.138.
(a) Interpret the P-value in context of this study.
(b) What conclusion should be drawn at the  = 0.10 significance level?
= 0.10 significance level?
(c) Given this conclusion, what possible error, Type I or Type II, might be committed, and give a possible consequence of committing this error.
3. A particular wastewater treatment system aims at reducing the most probable number per ml (MPN/ml) of E. coli to 1000 MPN/100 ml. A random study of 40 of these systems in current use is conducted with the data showing a mean of 1002.4 MPN/100 ml and a standard deviation of 7.12 MPN/100 ml. A test of significance is conducted with:
H0: The mean concentration of E. coli after treatment under this system is 1000 MPN/100 ml.
Ha: The mean concentration of E. coli after treatment under this system is greater than 1000 MPN/100 ml.
The resulting P-value is 0.0197 with df = 39 and t = 2.132.
(a) Interpret the P-value in context of this study.
(b) What conclusion should be drawn at a 5% significance level?
(c) Given this conclusion, what possible error, Type I or Type II, might be committed, and give a possible consequence of committing this error.
4. A 20-year study of 5000 British adults noted four bad habits: smoking, drinking, inactivity, and poor diet. The study looked to show that there is a higher death rate (proportion who die in a 20-year period) among people with all four bad habits than among people with none of the four bad habits.
(a) Was this an experiment or observational study? Explain.
(b) What are the null and alternative hypotheses?
(c) What would be the result of a Type I error?
(d) What would be the result of a Type II error?
Of the 314 people who had all four bad habits, 91 died during the study, while of the 387 people with none of the four bad habits, 32 died during the study.
(e) Calculate and interpret the P-value in context of this study.
5. It is estimated that 17.4% of all U.S. households own a Roth IRA. The American Association of University Professors (AAUP) believes this figure is higher among their members and commissions a study. If 150 out of a random sample of 750 AAUP members own Roth IRAs, is this sufficient evidence to support the AAUP belief?
6. A long accepted measure of the discharge rate (in 1000 ft3/sec) at the mouth of the Mississippi River is 593. To test if this has changed, ten measurements at random times are taken: 590, 596, 592, 588, 589, 594, 590, 586, 591, 589. Is there statistical evidence of a change?
7. A behavior study of high school students looked at whether a higher proportion of boys than girls met a recommended level of physical activity (increased heart rate for 60 minutes/day for at least 5 days during the 7 days before the survey). What is the proper conclusion if 370 out of a random sample of 850 boys and 218 out of an independent random sample of 580 girls met the recommended level of activity?
8. In a random sample of 35 NFL games the average attendance was 68,729 with a standard deviation of 6,110, while in a random sample of 30 Big 10 Conference football games the average attendance was 70,358 with a standard deviation of 9,139. Is there evidence that the average attendance at Big 10 Conference football games is greater than that at NFL games?
9. A study is proposed to compare two treatments for patients with significantly narrowed neck arteries. Some patients will be treated with surgery to remove built-up plaque, while others will be treated with stents to improve circulation. The response variable will be the proportion of patients who suffer a major complication such as a stroke or heart attack within one month of the treatment. The researchers decide to block on whether or not a patient has had a mini stroke in the previous year.
(a) There are 1000 patients available for this study, half of whom have had a mini stroke in the previous year. Explain a block design to assign patients to treatments.
(b) Give two methods other than blocking to increase the power of detecting a difference between using surgery versus stents for patients with this medical condition. Explain your choice of methods.
10. A car simulator was used to compare effect on reaction time between DWI (driving while intoxicated) and DWT (driving while texting). Ten volunteers were instructed to drive at 50 mph and then hit the brakes in response to the sudden image of a child darting into the road. A baseline stopping distance was established for each driver. Then one day each driver was tested for stopping distance while driving while texting, and another day the driver was tested after consuming a quantity of alcohol. For each driver, which test was done on the first day was decided by coin toss. The following table gives the extra number of feet necessary to stop at 50 mph for each driver for DWI and DWT.
![]()
The sample means are $\overline{x}$DWI = 32.2, $\overline{x}$DWT = 33.6, and a two-sample t-test, H0: µDWI = µDWT, Ha: µDWI ≠ µDWT, gives a P-value of 0.590, and a conclusion that there is no evidence of a difference between the effect on reaction time between DWI and DWT. Explain why this is not the proper hypothesis test, and then perform the proper test.
SIX INVESTIGATIVE TASKS
1. An exercise electrocardiogram (EKG) checks for changes in your heart during exercise and is useful in diagnosing coronary artery disease. An EKG has fewer potential side effects but is much less precise than thallium tomography. In one EKG study, 500 volunteers with known coronary artery disease and 500 volunteers with healthy arteries underwent EKG checks. The physicians administering and evaluating the tests did not know the physical condition of any volunteer. The following table gives the numbers of volunteers whom the physicians evaluated as “positive” for coronary disease.
| Test for coronary disease | |
Positive | Negative | |
Healthy volunteers | 100 | 400 |
Volunteers with disease | 305 | 195 |
(a) Sensitivity is defined as the probability of a positive test given that the subject has disease. What was the sensitivity of this study?
(b) Specificity is defined as the probability of a negative test given that the subject is healthy. What was the specificity of this study?
(c) A valuable tool for assessing the accuracy of such studies is the positive diagnostic likelihood ratio (LR+) which gives the ratio of the probability a positive test result will be observed in a diseased person compared to the probability that the same result will be observed in a healthy person.
![]()
What was LR+ in this study, and explain why the larger the value of LR+, the more useful the test.
(d) Suppose in one such sample study, LR+ = 4.7. To determine whether or not this is sufficient evidence that the population LR+ is below the desired value of 5.0, 100 samples from a population with a known LR+ of 5.0 are generated, and the resulting simulated values of LR+ are shown in the dotplot:
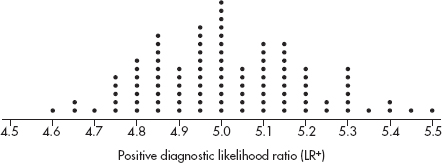
Based on this dotplot and the sample LR+ = 4.7, is there evidence that the population LR+ is below the desired value of 5.0? Explain.
2. An engineer wishes to test which of two drills can more quickly bore holes in various materials. He assembles a random sampling of ten materials of various hardnesses and thicknesses.
(a) Given that a drill’s efficiency is influenced by how long and how hard it has been operating, the engineer decided to randomly choose the order in which the materials will be tested. Design and implement a scheme to place the materials in random order using the following random number table:
51844 73424 84380 82259 28273 58102 18727 69708
(b) Suppose the drilling times (in seconds) are summarized as follows:

What is the mean drilling time for each drill? Is the difference significant? Justify your answer.
3. Paul the octopus, who lives in a tank at Sea Life Centre in Oberhausen, Germany, correctly predicted the winner in 12 out of 14 soccer matches (by choosing to eat mussels from the boxes labeled with national flags of the eventual winning teams). Assume these 14 matches represent a random sample of matches which Paul could predict, and assume that all matches end in a win for one of the teams (using sudden death overtime or penalty kicks to settle tie scores from regulation time).
(a) Why would it be incorrect to perform a one-sample z-test on whether the above is sufficient evidence that Paul can correctly predict the results of more than 50% of soccer matches?
(b) Perform a proper hypothesis test for the question in (a).
4. A marketing company is interested in whether a particular advertisement will increase interest in a new social networking website. A random sample of 15 teenagers is chosen, and their interest level in the new website is measured on a 1–100 scale before and after seeing the advertisement. The individual results are as follows:
![]()
(a) The ad developer claims that after seeing the ad, the interest level is above 30. Do the data support this conclusion? Explain.
(b) The ad developer also claims that after seeing the ad, teenagers have increased interest in the new website. Assuming all assumptions for hypothesis testing are met, do the data support this conclusion? Explain.
(c) Can after-ad interest level be predicted from before-ad interest level? Explain.
(d) Can the change in interest level be predicted by before-ad interest level? Explain.
5. According to one national survey, 20% of 18–24-year-olds have passports.
(a) Assuming the 20% figure is correct, use simulation to determine the approximate probability that in a random sample of ten 18–24-year-olds, at least three have passports.
2498346851 4113296825 1485367833 8663018872 7373275392
5062790330 2367029195 4153038298 7360048279 4207598980
9574649262 4488086249 2651769472 9462095309 4072555345
7894788460 2391904958 0201791131 9856022851 1405559336
6003121057 4154811850 7697586849 9644852135 0811348895
(b) Calculate the above probability exactly.
(c) Suppose you believe that the 20% claim is too high and run a hypothesis test. In a simple random sample of 200 18–24-year-olds you find only 33 who have passports. Is this sufficient evidence to dispute the 20% claim?
(d) If the 20% claim is true, what is the probability that the first 18–24-year-old with a passport will be the third one sampled?
(e) A 100-trial simulation is performed to determine the number of 18–24-year-olds sampled before finding one with a passport. The results are as follows:
Use the above information and barplot to estimate the mean number of 18–24-year-olds sampled before finding one with a passport.
6. Suppose it has been estimated that the number of hours per year that commuters on Los Angles highways sit in congested traffic follows a normal distribution with a mean of 82 hours and a standard deviation of 20 hours.
(a) Given the above, what is the estimate of M, the median number of hours per year that these commuters spend a year sitting in congested traffic? Explain.
Urban planners are concerned that this median M is rising. A random sample of 100 commuters in the year just ended is surveyed, and the median number of hours they spend is noted to be $\overline{x}$ = 85 hours.
(b) State the null and alternative hypotheses the urban planners are interested in testing.
It can be shown that for a normal distribution with mean μ and standard deviation σ and for a large sample size n, the sampling distribution of the sample median is approximately normal with mean μ and variance ![]()
(c) Calculate the value of the variance ![]() in this situation.
in this situation.
(d) Test the hypotheses in part (b).
(e) Would the conclusion have been different if $\overline{x}$ = 85 hours with n = 200? Explain.
MULTIPLE-CHOICE
1. (E) We attempt to show that the null hypothesis is unacceptable by showing that it is improbable; however, we cannot show that it is definitely true or false. Both the null and alternative hypotheses are stated in terms of a population parameter, not a sample statistic. These hypotheses tests assume simple random samples.
2. (E) The P-value of a test is the probability of obtaining a result as extreme (or more extreme) as the one obtained assuming the null hypothesis is true. Small P-values are evidence against the null hypothesis. The null and alternative hypotheses are decided upon before the data come in.
3. (E) The parameter of interest is µ = the mean number of hours per week which middle school students spend in video arcades.
4. (C) The alternative hypothesis is always an inequality, either <, or >, or ≠. In this case, the concern is whether middle school students are spending an average of more than two hours per week in video arcades.
5. (E) The P-value is a conditional probability; in this case, there is a 0.032 probability of an observed difference in sample proportions as extreme (or more extreme) as the one obtained if the null hypothesis is assumed to be true.
6. (C) This is a hypothesis test with H0: breaking strength is within specifications, and Ha: breaking strength is below specifications. A Type I error is committed when a true null hypothesis is mistakenly rejected.
7. (C) A Type II error is a mistaken failure to reject a false null hypothesis or, in this case, a failure to realize that a person really does have ESP.
8. (B) 
[On the TI-84, normalcdf(–1000,–1.242) = 0.107.]
9. (C) Medications having an effect shorter or longer than claimed should be of concern, so this is a two-sided test: Ha: µ ≠ 58.4, and df = n – 1 = 40 – 1 = 39.
10. (B) The level of significance is defined to be the probability of committing a Type I error, that is, of mistakenly rejecting a true null hypothesis.
11. (D)  and with df = 14, P = 0.112. With this high P-value (0.112 > 0.10), the students do not have sufficient evidence to reject the fast food chain’s claim. (On the TI-84, T-Test gives P = 0.112423.)
and with df = 14, P = 0.112. With this high P-value (0.112 > 0.10), the students do not have sufficient evidence to reject the fast food chain’s claim. (On the TI-84, T-Test gives P = 0.112423.)
12. (A) With unknown population standard deviations, the t-distribution must be used, 
13. (B) A Type I error means that the null hypothesis is true (the weather remains dry), but you reject it (thus you needlessly cancel school). A Type II error means that the null hypothesis is wrong (the snow storm hits), but you fail to reject it (so school is not canceled).
14. (E) With  With a P-value this high (0.141 > 0.10), the government does not have sufficient evidence to reject the company’s claim. (On the TI-84, 1PropZTest gives P = 0.140956.)
With a P-value this high (0.141 > 0.10), the government does not have sufficient evidence to reject the company’s claim. (On the TI-84, 1PropZTest gives P = 0.140956.)
15. (D)  This is a two-sided test (H0: p1 – p2 = 0, Ha: p1 – p2 ≠ 0) with
This is a two-sided test (H0: p1 – p2 = 0, Ha: p1 – p2 ≠ 0) with

16. (E) There is a different answer for each possible correct value for the population parameter.
17. (A) This is a one-sided z-test, 
18. (B) P(at least one Type I error) = 1 – P(no Type I errors) = 1 – (0.99)5 = 0.049
19. (C) A larger sample size n reduces the standard deviation of the sampling distributions resulting in narrower sampling distributions so that for the given sample statistic, the P-value is smaller, and the probabilities of mistakenly rejecting a true null hypothesis or mistakenly failing to reject a false null hypothesis are both decreased. Furthermore, a lower Type II error results in higher power.
20. (E) The two-sample hypothesis test is not the proper one and can only be used when the two sets are independent. In this case, there is a clear relationship between the data, in pairs, one pair for each student, and this relationship is completely lost in the procedure for the two-sample test. The proper procedure is to run a one-sample test on the single variable consisting of the differences from the paired data.
21. (C) With a smaller , that is, with a tougher standard to reject H0, there is a greater chance of failing to reject a false null hypothesis, that is, there is a greater chance of committing a Type II error. Power is the probability that a Type II error is not committed, so a higher Type II error results in lower power.
22. (B) If the null hypothesis is far off from the true parameter value, there is a greater chance of rejecting the false null hypothesis and thus a smaller risk of a Type II error. Power is the probability that a Type II error is not committed, so a lower Type II error results in higher power.
23. (C) With  = 6.48 and s = 1.388,
= 6.48 and s = 1.388,  [On the TI-84, T-Test gives P = 0.048322.]
[On the TI-84, T-Test gives P = 0.048322.]
24. (C) If the alternative is true, the probability of failing to reject H0 and thus committing a Type II error is 1 minus the power, that is, 1 – 0.75 = 0.25.
25. (B) 
[On the TI-84, normalcdf(–100, –10/15) = 0.252492.]
FREE-RESPONSE
1. The parameter of interest is µ = the mean tire pressure in the front right tires of cars with recommended tire pressure of 35 psi. H0: µ = 35 and Ha: µ ≠ 35.
2. (a) The P-value of 0.138 gives the probability of observing a sample proportion of GBS complications as great or greater as the proportion found in the study if in fact the proportion of GBS complications is 0.000001.
(b) Since 0.138 > 0.10, there is no evidence to reject H0, that is, there is no evidence that under the new vaccine the proportion of GBS complications is greater than 0.000001 (one in a million).
(c) The null hypothesis is not rejected, so there is the possibility of a Type II error, that is of mistakenly failing to reject a false null hypothesis. A possible consequence is continued use of vaccine with a higher rate of serious complications than is acceptable.
3. (a) The P-value of 0.0197 gives the probability of observing a sample mean of 1002.4 or greater if in fact this system results in a mean E. coli concentration of 1000 MPN/100 ml.
(b) Since 0.0197 < 0.05, there is evidence to reject H0, that is, there is evidence that the mean E. coli concentration is greater than 1000 MPN/100 ml, and the system is not working properly.
(c) With rejection of the null hypothesis, there is the possibility of a Type I error, that is of mistakenly rejecting a true null hypothesis. Possible consequences are that sales of the system drop even though the system is doing what it claims, or that the company performs an overhaul to fix the system even though the system is operating properly.
4. (a) This was an observational study as no treatments were imposed. It would have been highly unethical to impose treatments, that is, to instruct randomly chosen volunteers to smoke, drink, skip exercise, and eat poorly.
(b) H0: p4 = p0, Ha: p4 > p0 where p4 is the proportion of adults with all four bad habits who die during a 20-year period, and p0 is the proportion of adults with none of the four bad habits who die during a 20-year period. (Note that the hypotheses are about the population of all adults with and with none of the four bad habits, not about the volunteers who took part in the study.)
(c) A Type I error, that is, a mistaken rejection of a true null hypothesis, would result in people being encouraged to not smoke, not drink, exercise, and eat well, when these actions actually will not help decrease 20-year death rates.
(d) A Type II error, that is, a mistaken failure to reject a false null hypothesis, would result in people thinking that smoking, drinking, inactivity, and poor diet don’t increase 20-year death rates, when actually they do contribute to higher 20-year death rates.
(e) Calculator software (such as 2-PropZTest on the TI-84) gives P = 0.000.
[For instructional purposes in this review book, we note that:

If the null hypothesis were true, that is, if there was no difference in the 20-year death rates between people with all four bad habits and people with none of the bad habits, then the probability of sample proportions with a difference as extreme or more extreme than observed is 0.000 (to three decimals).
5. First, state the hypotheses:
H0: p = 0.174 and Ha: p > 0.174. (If asked to state the parameter, then state
“where p is the proportion of AAUP members who own Roth IRAs.”)
Second, identify the test by name or formula and check the assumptions.
This is a one-sample z-test for a population proportion.
Assumptions: Random sample (given), np = 750(0.174) = 130.5 10, n(1 – p) = 750(0.826) = 619.5 10, and the sample size, n = 750, is less than 10% of all AAUP members.
Third, calculate the test statistic z and the P-value. Calculator software (such as 1-PropZTest on the TI-84) gives z = 1.878 and P = 0.030.
[For instructional purposes in this review book, we note that

Fourth, linking to the P-value, give a conclusion in context.
With a P-value this small, 0.030 < 0.05, there is sufficient evidence to reject H0, that is, there is evidence that more than 17.4% of AAUP members own Roth IRAs.
6. First, state the hypotheses: H0: µ = 593 and Ha: µ ≠ 593 (If asked to state the parameter, then state “where µ is the mean discharge rate (in 1000 ft3/sec) at the mouth of the Mississippi River.”)
Second, identify the test by name or formula and check the assumptions:
This is a one-sample t-test for the mean with  Assumptions: The measurements were taken at random times, the sample size, n = 10, is less than 10% of all possible measurements, and either a dotplot of the sample is roughly unimodal and symmetric or the normal probability plot is roughly linear:
Assumptions: The measurements were taken at random times, the sample size, n = 10, is less than 10% of all possible measurements, and either a dotplot of the sample is roughly unimodal and symmetric or the normal probability plot is roughly linear:

Third, calculate the test statistic t and the P-value:
Calculator software (such as T-Test using Data on the TI-84) gives t = –2.7116 and P = 0.0239. [For instructional purposes in this review book, we note that x = 590.5 and s = 2.9155 which gives

Since this is a two-sided test, we double this value to find the P-value to be P = 0.0240.]
Fourth, linking to the P-value, give a conclusion in context: With a P-value this small, 0.0239 < 0.05, there is sufficient evidence to reject H0, that is, there is evidence that the long accepted measure of the discharge rate at the mouth of the Mississippi River has changed.
7. First, state the hypotheses: H0: pB – pG = 0 (or pB = pG) and Ha: pB – pG > 0 (or pB > pG). If asked to state the parameters, then state “where pB is the proportion of high school boys who meet the recommended level of physical activity, and pG is the proportion of high school girls who meet the recommended level of physical activity.”)
Second, identify the test by name or formula and check the assumptions:
This is a two-sample z-test for proportions. Assumptions: Independent random samples (given), and nB B = 370 10, nB (1 – B) = 480 10, nGG = 218 10, and nG (1 – G) = 362 10.
Third, calculate the test statistic z and the P-value. Calculator software (such as 2-PropZTest on the TI-84) gives z = 2.2427 and P = 0.012. (For instructional purposes in this review book, we note that

Fourth, linking to the P-value, give a conclusion in context. With a P-value this small (0.012 < 0.05), there is evidence that the proportion of high school boys who meet the recommended level of physical activity is greater than the proportion of high school girls who meet the recommended level of physical activity.
8. First, state the hypotheses: H0: µNFL – µ10 = 0 (or µNFL = µ10) and Ha: µNFL – µ10 < 0 (or µNFL < µ10) (or “>” depending on choice of variables). (If asked to state the parameters, then state “where µNFL is the mean attendance at NFL games and µ10 is the mean attendance at Big 10 football games.”]
Second, identify the test by name or formula and check the assumptions: This is a two-sample t-test for means. Assumptions: Independent random samples (given), both samples sizes, 35 and 30, are large enough so that by the CLT, the distribution of sample means is approximately normal and a t-test may be run, and the sample sizes, nNFL = 35 and n10 = 30, are less than 10% of all NFL and Big 10 football games.
Third, calculate the test statistic t and the P-value. Calculator software (such as 2-SampTTest on the TI-84) gives t = –0.8301, df = 49.3, and P = 0.2052. [For instructional purposes in this review book, we note that:

Fourth, linking to the P-value, give a conclusion in context. With a P-value this large, 0.2052 > 0.05, there is not sufficient evidence to reject H0, that is, there is not sufficient evidence that the average attendance at Big 10 Conference football games is greater than that at NFL games.
9. (a) One block consists of the 500 patients who have had a mini stroke in the previous year, and a second block consists of the 500 patients who have not. In one block, number the patients 1 through 500, and then using a random number generator, pick numbers between 1 and 500, throwing out repeats, until 250 patients are picked. Assign surgery to these patients and stents to the remaining 250. Repeat for the other block.
(b) One method is to increase the sample size, resulting in a reduction in the standard error of the sampling distribution, which in turn increases the probability of rejecting the null hypothesis if it is false. A second method is to increase , the significance level, which in turn also increases the probability of rejecting the null hypothesis if it is false. In either case, there is increased probability of detecting any difference in the proportions of patients suffering major complications between the surgery and stent recipients.
10. The data come in pairs, and the two-sample test does not apply the knowledge of what happened to each individual driver (the condition of independence of the two samples is violated). The appropriate test is a one-population, small-sample hypothesis test on the set of differences: {0, –5, 3, –4, –3, 1, –2, –2, –1, –1}. We proceed as follows:
First, state the hypotheses: H0: µD = 0, Ha: µD ≠ 0 (If asked to state the parameter, then state “where µD is the mean difference in reaction times between DWI and DWT.”)
Second, identify the test and check the assumptions: This is a paired t-test, that is, a single-sample hypothesis test on the set of differences.
The data are paired because they are measurements on the same individuals under DWI and DWT.
The reaction times of any individual are assumed independent of the reaction times of the others, so the differences are independent.
We must assume that the volunteers are a representative sample.
Either a dotplot of the sample is roughly unimodal and symmetric or the normal probability plot is roughly linear:

The sample size, n = 10, is less than 10% of all possible drivers.
Third, calculate the test statistic t and the P-value: Calculator software (such as T-Test and Data on the TI-84) gives t = –1.871 and P = 0.094174. [For instructional purposes in this review book, we note that x = –1.4 and s = 2.366 giving  and with df = 10 – 1 = 9, P(t < –1.871) = 0.0471. Since this is a two-sided test, we double this value to find the P-value to be P = 0.0942.]
and with df = 10 – 1 = 9, P(t < –1.871) = 0.0471. Since this is a two-sided test, we double this value to find the P-value to be P = 0.0942.]
Fourth, linking to the P-value, give a conclusion in context: With a P-value this small, 0.0942 < 0.10, there is sufficient evidence to reject H0, that is, there is evidence at the 10% significance level of a difference between the mean effect on reaction time between DWI and DWT. Or, with a P-value this large, 0.0942 > 0.05, there is not sufficient evidence to reject H0, that is, there is not sufficient evidence at the 5% significance level of a difference between the mean effect on reaction time between DWI and DWT.
INVESTIGATIVE TASKS
1. (a) 
(b) 
(c)  A positive test given a diseased subject and a negative test given a healthy subject are both desired outcomes, so higher values for both Sensitivity and Specificity are good. Higher values of Sensitivity, the numerator of LR+, lead to greater values of LR+. Higher values of Specificity give lower values of 1 – Specificity, the denominator of LR+, again leading to greater values of LR+.
A positive test given a diseased subject and a negative test given a healthy subject are both desired outcomes, so higher values for both Sensitivity and Specificity are good. Higher values of Sensitivity, the numerator of LR+, lead to greater values of LR+. Higher values of Specificity give lower values of 1 – Specificity, the denominator of LR+, again leading to greater values of LR+.
(d) The estimated P-value is the proportion of the simulated statistics that are less than or equal to the sample statistic of 4.7. Counting values in the dotplot gives a P-value of 0.04. With a P-value this small, there is evidence that the population LR+ is below the desired value of 5.0.
2. (a) Different schemes are possible. For example, assign each material a single-digit number, such as A-0, B-1, C-2, D-3, E-4, F-5, G-6, H-7, I-8, J-9. Then read off the digits from the random number list, one at a time, throwing away any repeats, until each of the materials have been picked (or nine have been picked, as the last one left will go last). The order of picking then gives the order of being tested. Using this scheme we would get the following order:

(b) The mean drilling times in the ten materials are 4.69 seconds for Drill 1 and 4.77 seconds for Drill 2.
The proper hypothesis test is a matched pairs t-test on the set of differences, {0, –0.3, 0.1, –0.2, –0.1, –0.4, 0, 0.3, –0.1, –0.1}
First, state the hypotheses: H0: µd = 0, Ha: µd ≠ 0. (If asked to state the parameter, then state “where µd is the difference in mean drilling times of the two drills through different materials.”)
Second, identify the test by name or formula and check the assumptions: This is a one-sample t-test for the mean of paired differences.
Assumptions: random samples (given), n = 10 is less than 10% of all possible materials, hardnesses, and thicknesses, and either a dotplot of the difference sample is roughly unimodal and symmetric, or the normal probability plot is roughly linear:

Third, calculate the test statistic t and the P-value: Calculator software (such as T-Test with Data on the TI-84) gives t = –1.272 and P = 0.2353. [For instructional purposes in this review book, we note that:
x = –0.08 and s = 0.1989 which gives  and with df = 10 – 1 = 9, P(t < –1.272) = 0.1176. Since this is a two-sided test, we double this value to find the P-value to be P = 0.2352.]
and with df = 10 – 1 = 9, P(t < –1.272) = 0.1176. Since this is a two-sided test, we double this value to find the P-value to be P = 0.2352.]
Fourth, linking to the P-value, give a conclusion in context. With a P-value this large, 0.2353 > 0.05, there is not sufficient evidence to reject H0, that is, there is not sufficient evidence of a difference in mean drilling times of the two drills through different materials.
3. (a) The conditions for a one-sample z-test on a population proportion include that both n 10 and n(1 – ) 10. In this case, n = 12 but n(1 – ) = 2.
(b) First, state the hypotheses: H0:p = 0.5 and Ha: p > 0.5, [If asked to state the parameter, then state “where p is the proportion of soccer matches for which Paul the octopus can correctly predict the winning team.”]
Second, identify the test and check the assumptions:
This is a test of a binomial model.
For each trial there are two outcomes (Paul has a choice of two boxes of mussels), the trials are independent, and the probability of Paul picking a winner can be assumed to be the same for each trial. We are given that the 14 matches are a random sample of all matches.
Third, calculate the P-value: With p = 0.5,

Fourth, linking to the P-value, give a conclusion in context: With a P-value this small, 0.00647 < 0.05, there is sufficient evidence to reject H0, that is, there is sufficient evidence that Paul can correctly predict the results of more than 50% of soccer matches.
4. (a) First, state the hypotheses: H0: µ = 30, Ha: µ > 30. (If asked to state the parameter, then state “where µ is the mean interest level of all teenagers after seeing the ad.”)
Second, identify the test and check the assumptions: This is a one-sample t-test for the mean. The sample was randomly chosen, n = 15 is less than 10% of all teenagers, and a dotplot is roughly unimodal and symmetric:

Third, calculate the test statistic t and the P-value: Calculator software (such as T-Test with Data on the TI-84) gives t = 2.526 and P = 0.012113. [For instructional purposes in this review book, we note that = 37.2 and s = 11.04 which gives  and with df = 15 – 1 = 14, P(t > 2.526) = 0.0121.]
and with df = 15 – 1 = 14, P(t > 2.526) = 0.0121.]
Fourth, linking to the P-value, give a conclusion in context: With a P-value this small, 0.0121 < 0.05, there is sufficient evidence to reject H0, that is, there is sufficient evidence to support the ad developer’s claim that after seeing the ad, the mean interest level is above 30.
(b) First, state the hypotheses: H0: µD = 0, Ha: µD ≠ 0, where µD is the mean difference between after-ad and before-ad interest level.
Second, identify the test and check the assumptions: This is a paired t-test, that is, a single sample hypothesis test on the set of differences, and it is given that all assumptions for hypothesis testing are met.
Third, calculate the test statistic t and the P-value: Calculator software (such as T-Test with Data on the TI-84) gives t = 0.9693 and P = 0.174415. [For instructional purposes in this review book, we note that = 0.6667 and s = 2.664 giving t =  and with df = 15 – 1 = 14, P(t > 0.9693) = 0.1744.]
and with df = 15 – 1 = 14, P(t > 0.9693) = 0.1744.]
Fourth, linking to the P-value, give a conclusion in context: With a P-value this large, 0.1744 > 0.05, there is not sufficient evidence to reject H0, that is, there is not sufficient evidence that after seeing the ad, teenagers have increased interest in the new website.
(c) A least square regression line using the after-ad and before-ad interest levels has a high correlation of r = 0.972, which when combined with the scatterplot, indicates a strong association. Thus, after-ad interest level can be predicted from before-ad interest level.

(d) A least square regression line using the before-ad and the change in interest levels yields a very low correlation of r = 0.235, which when combined with the scatterplot, indicates almost no association. Thus, after-ad interest level cannot be predicted from before-ad interest level.

5. (a) One of many ways to proceed: let the digits 1 and 2 represent having a passport, while the remaining single digits represent not having a passport. Read off groups of ten digits, checking for the number of 1s and 2s in each group.
2498346851 4113296825 1485367833 8663018872 7373275392
5062790330 2367029195 4153038298 7360048279 4207598980
9574649262 4488086249 2651769472 9462095309 4072555345
7894788460 2391904958 0201791131 9856022851 1405559336
6003121057 4154811850 7697586849 9644852135 0811348895
Tabulating from the table gives:
No passports (no 1s or 2s): 2
One passport (one 1 or 2): 8
Two passports (two 1s or 2s): 8
Three passports (three 1s or 2s): 5
Four passports (four 1s or 2s): 1
Five passports (five 1s or 2s): 1
The estimated probability of at least three passports among ten 18–24-year-olds is thus 
(b) In a binomial distribution with n = 10 and p = 0.20, P(x 3) = 0.3222. (On the TI-84, 1 – binomcdf(10, 0.20, 2) = 1 – 0.6778 = 0.3222.)
(c) First, state the hypotheses: H0: p = 0.20, Ha: p < 0.20. (If asked to state the parameter, then state “where p is the proportion of all 18–24-year-olds who have passports.”)
Second, identify the test and check the assumptions: This is a one-sample z-test for a population proportion, we have an SRS, np = (200)(0.20) = 40 > 10, n(1 – p) = (200) (0.80) = 160 > 10, and clearly 200 < 10% of all 18–24-year-olds.
Third, calculate the test statistic z and the P-value: Calculator software (such as 1-PropZTest on the TI-84) gives z = –1.2374 and P = 0.107963. [For instructional purposes in this review book, we note that:

Fourth, linking to the P-value, give a conclusion in context. With a P-value this large, 0.1080 > 0.05, there is not sufficient evidence to reject H0, that is, there is not sufficient evidence to dispute the claim that 20% of 18–24-year-olds have passports.
(d) This geometric probability is (0.8)2(0.2) = 0.128.
(e) xP(x) = 1(0.21) + 2(0.15) + 3(0.13) + … + 12(0.02) = 4.31 (On the TI-84, put 1–12 in L1, put the frequencies 21, 15, 13, …, 2 in L2, and then 1-VarStats gives = 4.31.)
6. (a) Normal distributions are symmetric so the mean and median are equal. M = μ = 82.
(b) H0: M = 82, Ha: M > 82
(c) 
(d) The sampling distribution of the sample median,  , is roughly normal with mean 82 and standard deviation
, is roughly normal with mean 82 and standard deviation  p(z > 1.197) and normalcdf(1.197,1000)= 0.1157. [Or normalcdf (85,1000,82,2.507)= 0.1157.] With this large a P-value, 0.1157 > 0.05, there is not sufficient evidence to say that the median number of hours per year that these commuters spend a year sitting in congested traffic is rising.
p(z > 1.197) and normalcdf(1.197,1000)= 0.1157. [Or normalcdf (85,1000,82,2.507)= 0.1157.] With this large a P-value, 0.1157 > 0.05, there is not sufficient evidence to say that the median number of hours per year that these commuters spend a year sitting in congested traffic is rising.
(e) If n = 200, then  and normalcdf (1.693,1000)= 0.0452. [Or normalcdf(85,1000,82,1.772)= 0.0452.] This does change the conclusion because with this small a P-value, 0.0452 < 0.05, there is sufficient evidence to reject the null hypothesis, that is, there is sufficient evidence to say that the median number of hours per year that these commuters spend a year sitting in congested traffic is rising.
and normalcdf (1.693,1000)= 0.0452. [Or normalcdf(85,1000,82,1.772)= 0.0452.] This does change the conclusion because with this small a P-value, 0.0452 < 0.05, there is sufficient evidence to reject the null hypothesis, that is, there is sufficient evidence to say that the median number of hours per year that these commuters spend a year sitting in congested traffic is rising.
CHI-SQUARE TEST FOR GOODNESS OF FIT
CHI-SQUARE TEST FOR INDEPENDENCE
CHI-SQUARE TEST FOR HOMOGENEITY OF PROPORTIONS
HYPOTHESIS TEST FOR SLOPE OF LEAST SQUARES LINE
In this topic we continue our development of tools to analyze data. We learn about inference on distributions of counts using chi-square models. This can be used to solve such problems as “Do test results support Mendel’s genetic principles?” (goodness-of-fit test); “Was surviving the Titanic sinking independent of a passenger’s status?” (independence test); and “Do students, teachers, and staff show the same distributions in types of cars driven?” (homogeneity test). We then learn about inference with regard to linear association of two variables. This can be used to solve such problems as “Is there a linear relationship between the grade received on a term paper and the number of pages turned in?”
TIP
Unless you have counts, you cannot use $\chi$2 methods.
CHI-SQUARE TEST FOR GOODNESS OF FIT
A critical question is often whether or not an observed pattern of data fits some given distribution. A perfect fit cannot be expected, and so we must look at discrepancies and make judgments as to the goodness of fit.
One approach is similar to that developed earlier. There is the null hypothesis of a good fit, that is, the hypothesis that a given theoretical distribution correctly describes the situation, problem, or activity under consideration. Our observed data consist of one possible sample from a whole universe of possible samples. We ask about the chance of obtaining a sample with the observed discrepancies if the null hypothesis is really true. Finally, if the chance is too small, we reject the null hypothesis and say that the fit is not a good one.
TIP
In Topic 14, the tests were about population parameters; however, with $\chi$2, the tests will be about distributions or relationships involving categorical variables.
How do we decide about the significance of observed discrepancies? It should come as no surprise that the best information is obtained from squaring the discrepancy values, as this has been our technique for studying variances from the beginning. Furthermore, since, for example, an observed difference of 23 is more significant if the original values are 105 and 128 than if they are 10,602 and 10,625, we must appropriately weight each difference. Such weighting is accomplished by dividing each difference by the expected values. The sum of these weighted differences or discrepancies is called chi-square and is denoted as $\chi$2 ($\chi$ is the lowercase Greek letter chi):
![]()
The smaller the resulting $\chi$2-value, the better the fit. The P-value is the probability of obtaining a $\chi$2 value as extreme or more extreme than the one obtained if the null hypothesis is assumed true. If the $\chi$2 value is large enough, that is, if the P-value is small enough, we say there is sufficient evidence to reject the null hypothesis and to claim that the fit is poor.
To decide how large a calculated $\chi$2-value must be to be significant, that is, to choose a critical value, we must understand how $\chi$2-values are distributed. A $\chi$2-distribution is not symmetric and is always skewed to the right. There are distinct $\chi$2-distributions, each with an associated number of degrees of freedom (df). The larger the df value, the closer the $\chi$2-distribution to a normal distribution. Note, for example, that squaring the often-used z-scores 1.645, 1.96, and 2.576 results in 2.71, 3.84, and 6.63, respectively, which are entries found in the first row of the $\chi$2-distribution table.
TIP
As long as the observed values do not exactly equal the expected values, $\chi$2 ≠ 0, and the explanation is either random chance or that the claimed distribution is incorrect.
A large $\chi$2-value may or may not be significant—the answer depends on which $\chi$2-distribution we are using. A table is given of critical $\chi$2-values for the more commonly used percentages or probabilities. To use the $\chi$2-distribution for approximations in goodness-of-fit problems, the individual expected values cannot be too small. An often-used rule of thumb is that no expected value should be less than 5. Finally, as in all hypothesis tests we’ve looked at, the sample should be randomly chosen from the given population.
TIP
In Topic 14, the tests could be one-sided or two-sided; however, with $\chi$2, the Ha will always simply be that the H0 is incorrect.
EXAMPLE 15.1
In a recent year, at the 6 p.m. time slot, television channels 2, 3, 4, and 5 captured the entire audience with 30%, 25%, 20%, and 25%, respectively. During the first week of the next season, 500 viewers are interviewed.
a. If viewer preferences have not changed, what number of persons is expected to watch each channel?
Answer: 0.30(500) = 150, 0.25(500) = 125, 0.20(500) = 100, and 0.25(500) = 125, so we have

b. Suppose that the actual observed numbers are as follows:

Do these numbers indicate a change? Are the differences significant?
Answer: Check the conditions:
1. Randomization: We must assume that the 500 viewers are a representative sample.
2. We note that the expected values (150, 125, 100, 125) are all $\geq$ 5.
H0: The television audience is distributed over channels 2, 3, 4, and 5 with percentages 30%, 25%, 20%, and 25%, respectively.
Ha: The audience distribution is not 30%, 25%, 20%, and 25%, respectively.
NOTE
We check that the expected values are all ≥ 5.
We calculate
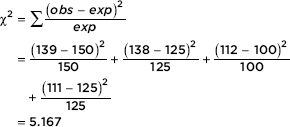
Then the P-value is P = P($\chi$2 > 5.167) = 0.1600. [If n is the number of classes, df = n – 1 = 3, and $\chi$2cdf(5.167, 1000, 3) = 0.1600.] We also note that putting the observed and expected numbers in Lists, calculator software (such as $\chi$2GOF-Test on the TI-84) gives $\chi$2 = 5.167 and P = 0.1600.
NOTE
Sometimes it is useful to note which terms in the summation are larger and which are smaller, that is, which terms contribute the most to the final sum.
Conclusion:
With this large a P-value (0.1600) there is not sufficient evidence to reject H0. That is, there is not sufficient evidence that viewer preferences have changed.
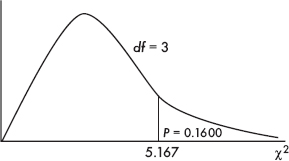
Note: While the TI-83 does not have the goodness of fit download that is available on the TI-84, one can still use a TI-83 to calculate the above $\chi$2 by putting the observed values in list L1 and the expected values in L2, then calculating (L1 – L2)2/L2 → L3 and $\chi$2 = sum(L3), where “sum” is found under LIST → MATH.
TIP
With the t-distribution, the df depends on the sample size, but here, df depends on the number of classes or categories.
EXAMPLE 15.2
TIP
Remember: the hypotheses are always about the population, never about the sample; it would be wrong to say H0: the sample data are uniformly distributed over the five locations.
A grocery store manager wishes to determine whether a certain product will sell equally well in any of five locations in the store. Five displays are set up, one in each location, and the resulting numbers of the product sold are noted.

Is there enough evidence that location makes a difference? Test at both the 5% and 10% significance levels.
Answer:
H0: Sales of the product are uniformly distributed over the five locations.
Ha: Sales are not uniformly distributed over the five locations.
A total of 43 + 29 + 52 + 34 + 48 = 206 units were sold. If location doesn’t matter, we would expect 206/5=41.2 units sold per location (uniform distribution).

TIP
Even though the observed values are counts and thus integers, the expected values might not be integers and should not be rounded to integers.
Check the conditions:
1. Randomization: We must assume that the 206 units sold are a representative sample.
2. We note that the expected values (all 41.2) are all $\geq$ 5.
Putting the observed and expected numbers in Lists, and with df = 5 – 1 = 4, calculator software (such as $\chi$2GOF-Test on the TI-84) gives $\chi$2 = 8.903 and P = 0.0636. [For instructional purposes, we note that
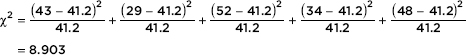
With P = 0.0636 there is sufficient evidence to reject H0 at the 10% level but not at the 5% level. If the grocery store manager is willing to accept a 10% chance of committing a Type I error, there is enough evidence to claim location makes a difference.
CHI-SQUARE TEST FOR INDEPENDENCE
In the goodness-of-fit problems above, a set of expectations was based on an assumption about how the distribution should turn out. We then tested whether an observed sample distribution could reasonably have come from a larger set based on the assumed distribution.
In many real-world problems we want to compare two or more observed samples without any prior assumptions about an expected distribution. In what is called a test of independence, we ask whether the two or more samples might reasonably have come from some larger set. For example, do nonsmokers, light smokers, and heavy smokers all have the same likelihood of being eventually diagnosed with cancer, heart disease, or emphysema? Is there a relationship (association) between smoking status and being diagnosed with one of these diseases?
We classify our observations in two ways and then ask whether the two ways are independent of each other. For example, we might consider several age groups and within each group ask how many employees show various levels of job satisfaction. The null hypothesis is that age and job satisfaction are independent, that is, that the proportion of employees expressing a given level of job satisfaction is the same no matter which age group is considered.
Analysis involves calculating a table of expected values, assuming the null hypothesis about independence is true. We then compare these expected values with the observed values and ask whether the differences are reasonable if H0 is true. The significance of the differences is gauged by the same $\chi$2-value of weighted squared differences. The smaller the resulting $\chi$2-value, the more reasonable the null hypothesis of independence. If the $\chi$2-value is large enough, that is, if the P-value is small enough, we can say that the evidence is sufficient to reject the null hypothesis and to claim that there is some relationship between the two variables or methods of classification.
In this type of problem,
df = (r – 1) (c – 1)
where df is the number of degrees of freedom, r is the number of rows, and c is the number of columns.
A point worth noting is that even if there is sufficient evidence to reject the null hypothesis of independence, we cannot necessarily claim any direct causal relationship. In other words, although we can make a statement about some link or relationship between two variables, we are not justified in claiming that one causes the other. For example, we may demonstrate a relationship between salary level and job satisfaction, but our methods would not show that higher salaries cause higher job satisfaction. Perhaps an employee’s higher job satisfaction impresses his superiors and thus leads to larger increases in pay. Or perhaps there is a third variable, such as training, education, or personality, that has a direct causal relationship to both salary level and job satisfaction.
EXAMPLE 15.3
In a nationwide telephone poll of 1000 randomly selected adults representing Democrats, Republicans, and Independents, respondents were asked two questions: their party affiliation and if their confidence in the U.S. banking system had been shaken by the savings and loan crisis. The answers, cross-classified by party affiliation, are given in the following contingency table.
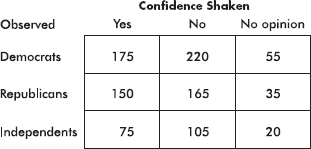
Test the null hypothesis that shaken confidence in the banking system is independent of party affiliation. Use a 10% significance level.
Answer:
H0: Party affiliation and shaken confidence in the banking system are independent.
Ha: Party affiliation and shaken confidence in the banking system are not independent.
Putting the observed data into a Matrix, calculator software (such as $\chi$2-Test on the TI-84) gives $\chi$2 = 3.024 and P = 0.5538, and stores the expected values in a second matrix:
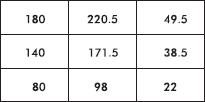
We are given a random sample and note that all expected cells are $\geq$ 5.
TIP
It is not enough to just say that all expected cells are ≥ 5; you must list the expected counts.
With this large a P-value, 0.5538 > 0.05, there is not sufficient evidence to reject H0, that is, there is not sufficient evidence of any relationship between party affiliation and shaken confidence in the banking system. For instructional purposes, we note that the expected values, $\chi$2, and P can be calculated as follows:

To calculate, for example, the expected value in the upper left box, we can proceed in any of several equivalent ways. First, we could note that the proportion of Democrats is 450/1000=0.45 and so, if independent, the expected number of Democrat yes responses is 0.45(400) = 180. Instead, we could note that the proportion of yes responses is 400/1000=0.4 and so, if independent, the expected number of Democrat yes responses is 0.4(450) = 180. Finally, we could note that both these calculations simply involve $\frac{(450)(400)}{1000}=180$.
In other words, the expected value of any box can be calculated by multiplying the corresponding row total by the appropriate column total and then dividing by the grand total. Thus, for example, the expected value for the middle box, which corresponds to Republican no responses, is $\frac{(350)(490)}{1000}=171.5$
Continuing in this manner, we fill in the table as follows:
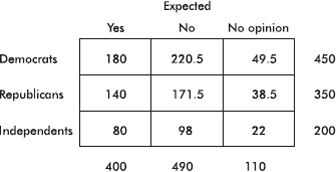
[An appropriate check at this point is that each expected cell count is at least 5.]
Next we calculate the value of chi-square:
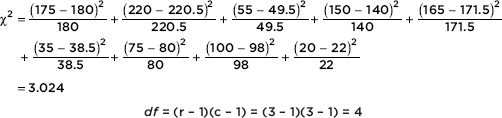
P is then calculated using calculator software such as $\chi$2cdf(3.024, 1000, 4) of the TI-84.] On the TI-Nspire the result shows as:

As for conditions to check for chi-square tests for independence, we should check that the sample is randomly chosen and that the expected values for all cells are at least 5. If a category has one of its expected cell count less than 5, we can combine categories that are logically similar (for example “disagree” and “strongly disagree”), or combine numerically small categories collectively as “other.”
EXAMPLE 15.4
To determine whether men with a combination of childhood abuse and a certain abnormal gene are more likely to commit violent crimes, a study is run on a simple random sample of 575 males in the 25 to 35 age group. The data are summarized in the following table:

a. Is there evidence of a relationship between the four categories (based on childhood abuse and abnormal genetics) and behavior (criminal versus normal)? Explain.
b. Is there evidence that among men with the normal gene, the proportion of abused men who commit violent crimes is greater than the proportion of nonabused men who commit violent crimes? Explain.
c. Is there evidence that among men who were not abused as children, the proportion of men with the abnormal gene who commit violent crimes is greater than the proportion of men with the normal gene who commit violent crimes? Explain.
d. Is there a contradiction in the above results? Explain.
Answers:
a. A chi-square test for independence is indicated. The expected cell counts are as follows:
![]()
The condition that all cell counts are greater than 5 is met.
H0: The four categories (based on childhood abuse and abnormal genetics) and behavior (criminal versus normal) are independent.
Ha: The four categories (based on childhood abuse and abnormal genetics) and behavior (criminal versus normal) are not independent (there is a relationship).
Running a chi-square test gives $\chi$2 = 7.752. With df = (r – 1)(c – 1) = 3, we get P = 0.0514. Since 0.0514 < 0.10, the data do provide some evidence (at least at the 10% significance level) to reject H0 and conclude that there is evidence of a relationship between the four categories (based on childhood abuse and abnormal genetics) and behavior (criminal versus normal).
b. A two-proportion z-test is indicated. We must check that n is large enough: n1$\widehat{p}$1 = 21 $\geq$ 10, n1(1 – $\widehat{p}$1) = 79 $\geq$ 10, n2$\widehat{p}$2 = 48 $\geq$ 10, n2(1 – $\widehat{p}$2) = 201 $\geq$ 10. We are given SRSs that are less than 10% of all males in the 25 to 35 age group.
H0: p1 – p2 = 0 | (where p1 is the proportion of abused men with normal genetics who commit violent crimes and p2 is the proportion of nonabused men with normal genetics who commit violent crimes) |
Ha: p1 – p2 > 0 | (the proportion of abused men with normal genetics who commit violent crimes is greater than the proportion of nonabused men with normal genetics who commit violent crimes) |
Calculator software (such as 2-PropZTest on the TI-84) gives z = 0.3653 and P = 0.3574. With this large a P-value, 0.3574 > 0.05, there is not sufficient evidence to reject H0, that is, there is not sufficient evidence that the proportion of abused men with normal genetics who commit violent crimes is greater than the proportion of nonabused men with normal genetics who commit violent crimes.
c. A two-proportion z-test is indicated. We must check that n is large enough: n1$\widehat{p}$1 = 32 $\geq$ 10, n1(1 – $\widehat{p}$1) = 118 $\geq$ 10, n2$\widehat{p}$2 = 48 $\geq$ 10, n2(1 – $\widehat{p}$2) = 201 $\geq$ 10. We are given SRSs that are less than 10% of all males in the 25 to 35 age group.
H0: p1 – p2 = 0 | (where p1 is the proportion of nonabused men with abnormal genetics who commit violent crimes and p2 is the proportion of nonabused men with normal genetics who commit violent crimes) |
Ha: p1 – p2 > 0 | (the proportion of nonabused men with abnormal genetics who commit violent crimes is greater than the proportion of nonabused men with normal genetics who commit violent crimes) |
Calculator software (such as 2-PropZTest on the TI-84) gives z = 0.4969 and P = 0.3096. With this large a P-value, 0.3096 > 0.05, there is not sufficient evidence to reject H0, that is, there is not sufficient evidence that the proportion of nonabused men with the abnormal gene who commit violent crimes is greater than the proportion of nonabused men with the normal gene who commit violent crimes.
d. There is no contradiction. It is possible to have evidence of an overall relationship without significant evidence showing in a subset of the categories.
CHI-SQUARE TEST FOR HOMOGENEITY OF PROPORTIONS
In chi-square goodness-of-fit tests we work with a single variable in comparing a single sample to a population model. In chi-square independence tests we work with a single sample classified on two variables. Chi-square procedures can also be used with a single variable to compare samples from two or more populations. It is important that the samples be simple random samples, that they be taken independently of each other, that the original populations be large compared to the sample sizes, and that the expected values for all cells be at least 5. The contingency table used has a row for each sample.
EXAMPLE 15.5
In a large city, a group of AP Statistics students work together on a project to determine which group of school employees has the greatest proportion who are satisfied with their jobs. In independent simple random samples of 100 teachers, 60 administrators, 45 custodians, and 55 secretaries, the numbers satisfied with their jobs were found to be 82, 38, 34, and 36, respectively. Is there evidence that the proportion of employees satisfied with their jobs is different in different school system job categories?
Answer:
H0: The proportion of employees satisfied with their jobs is the same across the various school system job categories.
Ha: At least two of the job categories differ in the proportion of employees satisfied with their jobs.
The observed counts are as follows:
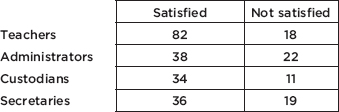
Putting the observed data into a matrix, calculator software (such as $\chi$2-Test on the TI-84) gives $\chi$2 = 8.707 and P = 0.0335, and stores the expected values in a second matrix:
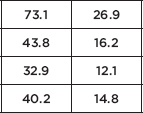
We are given an SRS and note that all expected cells are $\geq$ 5. With this small a P-value, 0.0335 < 0.05, there is sufficient evidence to reject H0, that is, there is sufficient evidence that the proportion of employees satisfied with their jobs is not the same across all the school system job categories.
The difference between the test for independence and the test for homogeneity can be confusing. When we’re simply given a two-way table, it’s not obvious which test is being performed. The crucial difference is in the design of the study. Did we pick samples from each of two or more populations to compare the distribution of some variable among the different populations? If so, we are doing a test for homogeneity. Did we pick one sample from a single population and cross-categorize on two variables to see if there is an association between the variables? If so, we are doing a test for independence.
For example, if we separately sample Democrats, Republicans, and Independents to determine whether they are for, against, or have no opinion with regard to stem cell research (several samples, one variable), then we do a test for homogeneity with a null hypothesis that the distribution of opinions on stem cell research is the same among Democrats, Republicans, and Independents. However, if we sample the general population, noting the political preference and opinions on stem cell research of the respondents (one sample, two variables), then we do a test for independence with a null hypothesis that political preference is independent of opinion on stem cell research.
Finally, it should be remembered that while we used $\chi$2 for categorical data, the $\chi$2 distribution is a continuous distribution, and applying it to counting data is just an approximation.
HYPOTHESIS TEST FOR SLOPE OF LEAST SQUARES LINE
In addition to finding a confidence interval for the true slope, one can also perform a hypothesis test for the value of the slope. Often one uses the null hypothesis H0: $\beta$ = 0, that is, that there is no linear relationship between the two variables. Assumptions for inference for the slope of the least squares line include the following: (1) the sample must be randomly selected; (2) the scatterplot should be approximately linear; (3) there should be no apparent pattern in the residuals plot; and (4) the distribution of the residuals should be approximately normal. (This third point can be checked by a histogram, dotplot, stemplot, or normal probability plot of the residuals.)
TIP
Be careful about abbreviations. For example, your teacher might use LOBF (line of best fit), but the grader may have no idea what this refers to.
Note that a low P-value tells us that if the two variables did not have some linear relationship, it would be highly unlikely to find such a random sample; however, strong evidence that there is some association does not mean the association is strong.
EXAMPLE 15.6
The following table gives serving speeds in mph (using a flat or “cannonball” serve) of ten randomly selected professional tennis players before and after using a newly developed tennis racquet.
TIP
If the data don’t look straight, do not fit a straight line.
![]()
a. Is there evidence of a straight line relationship with positive slope between serving speeds of professionals using their old and the new racquets?
Answer: Checking the assumptions:
We are told that the data come from a random sample of professional players.
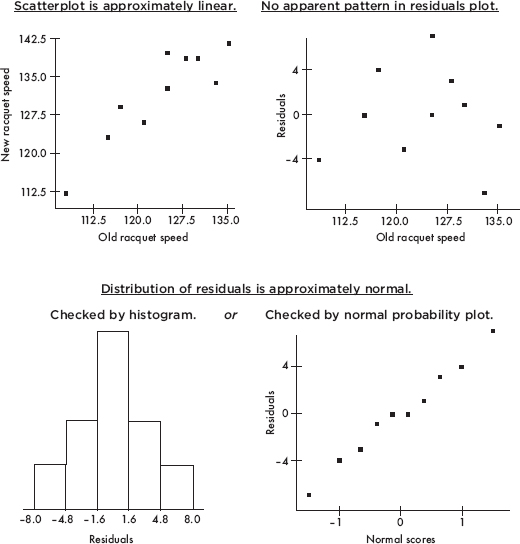
NOTE
A normal probability plot roughly showing a straight line indicates that the data distribution is roughly normal.
We proceed with the hypothesis test for the slope of the regression line.
H0: $\beta$1 = 0 Ha: $\beta$1 > 0
Using the statistics software on a calculator (for example, LinRegTTest on the TI-84), gives:
![]()
With such a small P value, 0.00019 < 0.001, there is very strong evidence to reject H0, that is, there is very strong evidence of a straight line relationship with positive slope between serving speeds of professionals using their old and the new racquets.
b. Interpret in context the least squares line.
Answer: With a slope of approximately 1 and a y-intercept of 8.76, the regression line indicates that use of the new racquet increases serving speed on the average by 8.76 mph regardless of the old racquet speed. That is, players with lower and higher old racquet speeds experience on the average the same numerical (rather than percentage) increase when using the new racquet.
On the TI-Nspire the result shows as:
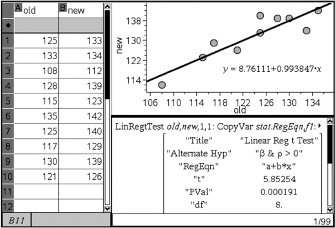
It is important to be able to interpret computer output, and appropriate computer output is helpful in checking the assumptions for inference.
EXAMPLE 15.7
A company offers a 10-lesson program of study to improve students’ SAT scores. A survey is made of a random sampling of 25 students. A scatterplot of improvement in total (math + verbal) SAT score versus number of lessons taken is as follows:
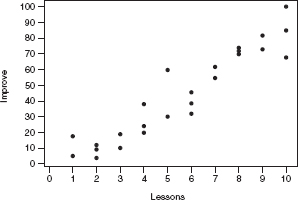
Some computer output of the regression analysis follows, along with a plot and a histogram of the residuals.
Regression Analysis: Improvement Versus Lessons
Dependentvariable:Improvement
Predictor | Coef | SE Coef | T | P |
Constant | –7.718 | 4.272 | –1.81 | 0.084 |
Lessons | 9.2854 | 0.6789 | 13.68 | 0.000 |
S = 9.744R–Sq = 89.1%
Analysis of Variance
Source | DF | SS | MS | F | P |
Regression | 1 | 17761 | 17761 | 187.06 | 0.000 |
Residual Error | 23 | 2184 | 95 |
|
|
Total | 24 | 19945 |
|
|
|
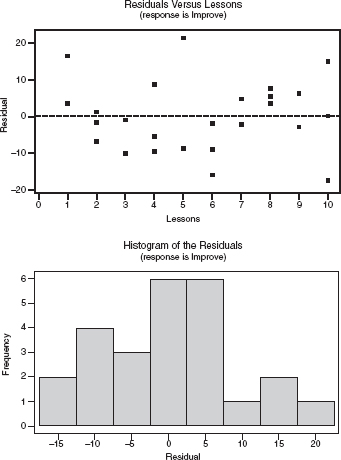
a. What is the equation of the regression line that predicts score improvement as a function of number of lessons?
b. Interpret, in context, the slope of the regression line.
c. What is the meaning of R–Sq in context of this study?
d. Give the value of the correlation coefficient.
e. Perform a test of significance for the slope of the regression line.
Answers:
a. ![]()
b. The slope of the regression line is 9.2854, meaning that on the average, each additional lesson is predicted to improve one’s total SAT score by 9.2854.
c. R–Sq = 89.1% means that 89.1% of the variation in total SAT score improvement can be explained by variation in the number of lessons taken.
d. ![]() where the sign is positive because the slope is positive.
where the sign is positive because the slope is positive.
e. A test of significance of the slope of the regression line with H0: $\beta$ = 0, Ha: $\beta$ ≠ 0 (test of significance of correlation) is as follows:
Assumptions: We are told the data came from a random sample, the scatterplot appears to be approximately linear, there is no apparent pattern in the residuals plot, and the histogram of residuals appears to be approximately normal.
![]()
(Or t and P can simply be read off the computer output!)
With this small a P-value, 0.000 < any reasonable significance level, there is very strong evidence to reject H0 and conclude that the relationship between improvement in total SAT score and number of lessons taken is significant.
Throughout this review book the concept of independence has arisen many times, with different meanings in different contexts, and a quick review is worthwhile.
1. If the outcome of one event, E, doesn’t affect the outcome of another event, F, we say the events are independent, and we have P(E |F) = P(E), P(F |E) = P(F), and P(E $\cap$ F) = P(E)P(F).
2. When the distribution of one variable in a contingency table is the same for all categories of another variable, we say the two variables are independent.
3. When two random variables are independent, we can use the rule for adding variances with regard to the random variables X + Y and X – Y.
4. In a binomial distribution, the trials must be independent; that is, the probability of success must be the same on every trial, irrespective of what happened on a previous trial. However, when we pick a sample from a population, we do change the size and makeup of the remaining population. We typically allow this as long as the sample is not too large—the usual rule of thumb is that the sample size should be smaller than 10% of the population.
5. In inference we wish to make conclusions about a population parameter by analyzing a sample. A crucial assumption is always that the sampled values are independent of each other. This typically involves checking if there was proper randomization in the gathering of data. Also, to minimize the effect on independence from samples being drawn without replacement, we check that less than 10% of the population is sampled.
6. Furthermore, if inference involves the comparison of two groups, the two groups must be independent of each other.
7. With paired data, while the observations in each pair are not independent, the differences must be independent of each other.
8. With regression, the errors in the regression model must be independent, and one may check this by confirming there are no patterns in the residual plot.
SUMMARY
Chi-square analysis is an important tool for inference on distributions of counts.
The chi-square statistic is found by summing the weighted squared differences between observed and expected counts.
A chi-square goodness-of-fit test compares an observed distribution to some expected distribution.
A chi-square test of independence tests for evidence of an association between two categorical variables from a single sample.
A chi-square test of homogeneity compares samples from two or more populations with regard to a single categorical variable.
The sampling distribution for the slope of a regression line can be modeled by a t-distribution with df = n – 2.
Multiple-Choice Questions
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. A random sample of mice is obtained, and each mouse is timed as it moves through a maze to a reward treat at the end. After several days of training, each mouse is timed again. The data should be analyzed using
(A) a z-test of proportions.
(B) a two-sample test of means.
(C) a paired t-test.
(D) a chi-square test.
(E) a regression analysis.
2. To test the claim that dogs bite more or less depending upon the phase of the moon, a university hospital counts admissions for dog bites and classifies with moon phase.
| New moon | First quarter | Full moon | Last quarter |
Dog bite admissions | 32 | 27 | 47 | 38 |
Which of the following is the proper conclusion?
(A) The data prove that dog bites occur equally during all moon phases.
(B) The data prove that dog bites do not occur equally during all moon phases.
(C) The data give evidence that dog bites occur equally during all moon phases.
(D) The data give evidence that dog bites do not occur equally during all moon phases.
(E) The data do not give sufficient evidence to conclude that dog bites are related to moon phases.
3. For a project, a student randomly picks 100 fellow AP Statistics students to survey on whether each has either a PC or Apple at home (all students in the school have a home computer) and what score (1, 2, 3, 4, 5) each expects to receive on the AP exam. A chi-square test of independence results in a test statistic of 8. How many degrees of freedom are there?
(A) 1
(B) 4
(C) 7
(D) 9
(E) 99
4. A random sample of 100 former student-athletes are picked from each of the 16 colleges that are members of the Big East conference. Students are surveyed about whether or not they feel they received a quality education while participating in varsity athletics. A 2 × 16 table of counts is generated. Which of the following is the most appropriate test to determine whether there is a difference among these schools as to the student-athlete perception of having received a quality education.
(A) A chi-square goodness-of-fit test for a uniform distribution
(B) A chi-square test of independence
(C) A chi-square test of homogeneity of proportions
(D) A multiple-sample z-test of proportions
(E) A multiple-population z-test of proportions
5. According to theory, blood types in the general population occur in the following proportions: 46% O, 40% A, 10% B, and 4% AB. Anthropologists come upon a previously unknown civilization living on a remote island. A random sampling of blood types yields the following counts: 77 O, 85 A, 23 B, and 15 AB. Is there sufficient evidence to conclude that the distribution of blood types found among the island population differs from that which occurs in the general population?
(A) The data prove that blood type distribution on the island is different from that of the general population.
(B) The data prove that blood type distribution on the island is not different from that of the general population.
(C) The data give evidence at the 1% significance level that blood type distribution on the island is different from that of the general population.
(D) The data give evidence at the 5% significance level, but not at the 1% significance level, that blood type distribution on the island is different from that of the general population.
(E) The data do not give evidence at the 5% significance level that blood type distribution on the island is different from that of the general population.
6. Is there a relationship between education level and sports interest? A study cross-classified 1500 randomly selected adults in three categories of education level (not a high school graduate, high school graduate, and college graduate) and five categories of major sports interest (baseball, basketball, football, hockey, and tennis). The $\chi$2-value is 13.95. Is there evidence of a relationship between education level and sports interest?
(A) The data prove there is a relationship between education level and sports interest.
(B) The evidence points to a cause-and-effect relationship between education and sports interest.
(C) There is evidence at the 5% significance level of a relationship between education level and sports interest.
(D) There is evidence at the 10% significance level, but not at the 5% significance level, of a relationship between education level and sports interest.
(E) The P-value is greater than 0.10, so there is no evidence of a relationship between education level and sports interest.
7. A disc jockey wants to determine whether middle school students and high school students have similar music tastes. Independent random samples are taken from each group, and each person is asked whether he/she prefers hip-hop, pop, or alternative. A chi-square test of homogeneity of proportions is performed, and the resulting P-value is below 0.05. Which of the following is a proper conclusion?
(A) There is evidence that for all three music choices the proportion of middle school students who prefer each choice is equal to the corresponding proportion of high school students.
(B) There is evidence that the proportion of middle school students who prefer hip-hop is different from the proportion of high school students who prefer hip-hop.
(C) There is evidence that for all three music choices the proportion of middle school students who prefer each choice is different from the corresponding proportion of high school students.
(D) There is evidence that for at least one of the three music choices the proportion of middle school students who prefer that choice is equal to the corresponding proportion of high school students.
(E) There is evidence that for at least one of the three music choices the proportion of middle school students who prefer that choice is different from the corresponding proportion of high school students.
8. A geneticist claims that four species of fruit flies should appear in the ratio 1:3:3:9. Suppose that a sample of 2000 flies contained 110, 345, 360, and 1185 flies of each species, respectively. Is there sufficient evidence to reject the geneticist’s claim?
(A) The data prove the geneticist’s claim.
(B) The data prove the geneticist’s claim is false.
(C) The data do not give sufficient evidence to reject the geneticist’s claim.
(D) The data give sufficient evidence to reject the geneticist’s claim.
(E) The evidence from this data is inconclusive.
9. A food biologist surveys people at an ice cream parlor, noting their taste preferences and cross-classifying against the presence or absence of a particular marker in a saliva swab test.
| Presence | Absence |
Vanilla | 32 | 12 |
Chocolate | 15 | 7 |
Strawberry | 24 | 19 |
Is there evidence of a relationship between taste preference and the marker presence?
(A) At the 10% significance level, the data prove that there is a relationship between taste preference and the presence of the marker.
(B) At the 10% significance level, the data prove that there is no relationship between taste preference and the presence of the marker.
(C) There is evidence at the 5% significance level of a relationship between taste preference and the presence of the marker.
(D) There is evidence at the 10% significance level, but not at the 5% significance level, of a relationship between taste preference and the presence of the marker.
(E) There is no evidence at the 10% significance level of a relationship between taste preference and the presence of the marker.
10. Random samples of 25 students are chosen from each high school class level, students are asked whether or not they are satisfied with the school cafeteria food, and the results are summarized in the following table:
| Freshmen | Sophomores | Juniors | Seniors |
Satisfied | 15 | 12 | 9 | 7 |
Dissatisfied | 10 | 13 | 16 | 18 |
Is there evidence of a difference in cafeteria food satisfaction among the class levels?
(A) The data prove that there is a difference in cafeteria food satisfaction among the class levels.
(B) There is evidence of a linear relationship between food satisfaction and class level.
(C) There is evidence at the 1% significance level of a difference in cafeteria food satisfaction among the class levels.
(D) There is evidence at the 5% significance level, but not at the 1% significance level, of a difference in cafeteria food satisfaction among the class levels.
(E) With P = 0.1117 there is no evidence of a difference in cafeteria food satisfaction among the class levels.
11. Can dress size be predicted from a woman’s height? In a random sample of 20 female high school students, dress size versus height (cm) gives the following regression results:
The regression equation is
Size = –48.8 + 0.374 Height
Predictor | Coef | SE Coef | T | P |
Constant | –48.81 | 30.57 | –1.60 | 0.128 |
Height | 0.3736 | 0.1898 | 1.97 | 0.065 |
S = 4.46720R–Sq = 17.7%R–Sq(adj) = 13.1%
Is there statistical evidence of a linear relationship between dress size and height?
(A) No, because r2, the coefficient of determination, is too small.
(B) No, because 0.128 is above any reasonable significance level.
(C) Yes, because by any reasonable observation, taller women tend to have larger dress sizes.
(D) Yes, because the computer printout does give a regression equation.
(E) There is evidence at the 10% significance level, but not at the 5% level.
12. To study the relationship between calories (kcal) and fat (g) in pizza, slices of 14 randomly selected major brand pizzas are chemically analyzed. Computer printout for regression:
Predictor | Coef | SE Coef | T | P |
Constant | 1.593 | 1.422 | 1.12 | 0.285 |
Calories | 0.035881 | 0.004896 | 7.33 | 0.000 |
S = 1.27515R–Sq = 81.7%R–Sq(adj) = 80.2%
What is measured by S = 1.27515?
(A) Variability in calories among slices
(B) Variability in fat among slices
(C) Variability in the slope (g/kcal) of the regression line
(D) Variability in the y-intercept of the regression line
(E) Variability in the residuals
Free-Reponse Questions
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your final answers.
SEVEN OPEN-ENDED QUESTIONS
1. A candy manufacturer advertises that their fruit-flavored sweets have hard sugar shells in five colors with the following distribution: 35% cherry red, 10% vibrant orange, 10% daffodil yellow, 25% emerald green, and 20% royal purple. A random sample of 300 sweets yielded the counts in the following table:
| Cherry | Vibrant | Daffodil | Emerald | Royal |
| red | orange | yellow | green | purple |
Observed counts | 94 | 34 | 22 | 77 | 73 |
Is there evidence that the distribution is different from what is claimed by the manufacturer?
2. You want to study whether smokers and non-smokers have equal fitness levels (low, medium, high) and are considering two survey designs:
I. Take a random sample of 200 people, asking each whether or not they smoke, and measuring the fitness level of each.
II. Take a random sample of 100 smokers and measure the fitness level of each, and take a random sample of 100 non-smokers and measure the fitness level of each.
(a) Which of the designs results in a test of independence and which results in a test of homogeneity? Explain.
(b) If we are interested in whether the proportion of people who have various fitness levels differs among smokers and non-smokers, which design should be used? Explain.
(c) If we are interested in the conditional distribution of people with given fitness levels who are smokers or are not smokers, which design should be used? Explain.
3. Is there a difference in happiness levels between busy and idle people? In one study, after filling out a survey, 175 randomly chosen high school students were told they could either sit 15 minutes while the survey was being tabulated, or they could walk 15 minutes to another building where the survey was being tabulated. Then they were given a questionnaire asking how good they felt during the past 15 minutes (on a scale of 1, “not good,” to 5, “very good”). The results of the questionnaire were as follows:
| Happiness level | ||||
| 1 | 2 | 3 | 4 | 5 |
Busy (walking) | 8 | 15 | 24 | 26 | 25 |
Idle (sitting) | 18 | 20 | 15 | 10 | 14 |
(a) Does the above data give statistical evidence of a relationship between happiness level and busy/idle choice of the students?
(b) If the answer above is positive for a relationship, is it reasonable to conclude that encouraging high school students to keep more busy will lead to higher happiness levels?
4. A poll, asking a random sample of adults whether or not they eat breakfast and to rate their morning energy level, results in the table:
| Morning energy level | ||
| Low | Medium | High |
Breakfast | 22% | 24% | 24% |
No breakfast | 12% | 10% | 8% |
(a) If the sample size was n = 500, is there evidence of a relationship between eating breakfast and morning energy level?
(b) Does the answer to part (a) change if n = 1000 instead? Explain.
5. A survey on acne treatments randomly selected 100 teenagers using topical treatments, 100 using oral medications, and 50 using laser therapy, and asked each subject about satisfaction level. The resulting counts were:
| Topical | Oral | Laser |
Very satisfied | 61 | 54 | 24 |
Somewhat satisfied | 28 | 21 | 10 |
Unsatisfied | 11 | 25 | 16 |
(a) Do the different treatments lead to different satisfaction levels? Perform an appropriate hypothesis test.
(b) What is a possible confounding variable which could lead you to jump to a misleading conclusion? Explain.
6. A study of 100 randomly selected teenagers, ages 13–17, looked at number of texts per waking hour versus age, yielding the computer regression output below:
Predictor | Coef | SE Coef | T | P |
Constant | –1.055 | 2.815 | –0.37 | 0.709 |
Age | 0.4577 | 0.1866 | 2.45 | 0.016 |
S = 2.66501R–Sq = 5.8%R–Sq(adj) = 4.8%
(a) Interpret the slope in context.
(b) What three graphs should be checked with regard to conditions for a test of significance for the slope of the regression line?
(c) Assuming all conditions for inference are met, perform this test of significance.
(d) Give a conclusion in context, taking into account both your answer to the hypothesis test as well as the value of R–Sq.
7. Can the average women’s life expectancy in a country be predicted from the average fertility rate (children/woman) in that country? Following are the most recent data from 11 randomly selected countries:
Country | Fertility rate (children/woman) | Life expectancy (women) |
Afghanistan | 6.25 | 45.5 |
Angola | 5.33 | 51.4 |
Argentina | 2.16 | 80.0 |
Australia | 1.85 | 84.4 |
France | 1.85 | 85.1 |
Liberia | 4.69 | 61.5 |
Nepal | 2.66 | 69.0 |
Netherlands | 1.77 | 82.6 |
Pakistan | 3.58 | 68.3 |
Poland | 1.29 | 80.4 |
Singapore | 1.29 | 83.4 |
Perform a test of significance for the slope of the regression line that relates fertility rate (children/woman) to life expectancy (women).
THREE INVESTIGATIVE TASKS
1. Use of placebos are now the norm for medical studies, but disclosing the compositions of these placebos is unexplicitly not all that common, even though these placebos could have effects. For example, olive oil has been used as a placebo in cholesterol drug tests, and there is some evidence that olive oil can affect cholesterol level. Composition of a placebo injection is disclosed more often than that of a placebo pill, but still it can be difficult to make this finding. In a survey of 800 studies using placebo injections, three researchers independently try to determine the compositions of the placebos, and the counts of successes are as follows:
| Number of researchers able to determine composition of a placebo | |||
0 | 1 | 2 | 3 | |
Number of studies | 419 | 314 | 56 | 11 |
(a) Find the complete binomial distribution (probabilities of 0 through 3 successes) for n = 3 and p = 0.2.
(b) Given 800 studies, if the number of researchers who determine composition of a placebo follows a binomial with probability of success p = 0.2, what are the expected values for the numbers (0 through 3) of researchers able to determine composition of a placebo?
(c) Test the null hypothesis that the number of researchers who determine composition of a placebo follows a binomial with probability of success p = 0.2.
2. Twelve high schools are randomly selected, and in each, the math teachers, the English teachers, and the students on the honor roll all take a logic puzzle test, and average scores for each group are noted in the following table:
The regression analysis of the data follows.
Regression Analysis: Student versus English
Dependent variable: Student
Predictor | Coef | SE Coef | T | P |
Constant | 2.315 | 4.154 | 0.56 | 0.590 |
English | 0.8038 | 0.4102 | 1.96 | 0.078 |
S = 1.06798R–Sq = 27.8%R–Sq(adj) = 20.5%
Regression Analysis: Student versus Math
Dependent variable: Student
Predictor | Coef | SE Coef | T | P |
Constant | –0.330 | 2.230 | –0.15 | 0.885 |
Math | 1.0701 | 0.2208 | 4.85 | 0.001 |
S = 0.686661R–Sq = 70.1%R–Sq(adj) = 67.1%
(a) Is there evidence that the average student score is greater than that of the English teachers?
(b) Is there evidence that the average student score is greater than that of the math teachers?
(c) Is the score of the English or math teachers a better predictor of the student score? Explain.
(d) Given the analysis in part (c), predict the average student score in a school where the average English teachers’ score is 11.0 and the average math teachers’ score is 10.0.
(e) Given the analysis in parts (c) and (d), what is the approximate range of average student scores at schools where the average English teachers’ score is 11.0 and the average math teachers’ score is 10.0.
3. A heavy backpack can cause chronic shoulder, neck, and back pain. Wide, padded shoulder straps, a waist belt, and avoidance of single-strap bags all help, but weight is the main problem. The recommendation for a safe weight for school backpacks is no more than 10% of body weight. In a study of 500 randomly selected high school students, the weights of their backpacks give rise to the following:
Weight (lb) | Below 12.5 | 12.5–17.5 | 17.5–22.5 | 22.5–27.5 | Above 27.5 |
Observed # | 28 | 134 | 182 | 112 | 44 |
(a) In a normal distribution with µ = 20 and $\sigma$ = 5, what are the probabilities of z < 12.5, 12.5 < z < 17.5, 17.5 < z < 22.5, 22.5 < z < 27.5, and z > 27.5?
(b) Given 500 students, if the data follow a normal distribution with µ = 20 and $\sigma$ = 5, what are the expected values for the numbers of backpacks in each of the indicated weight ranges?
(c) Test the null hypothesis that the data follow a normal distribution with µ = 20 and $\sigma$ = 5.
MULTIPLE-CHOICE
1. (C) There are two observations of each mouse, a before time and an after time. These two times are dependent so a paired t-test is appropriate, not a two-sample test.
2. (E) The expected counts if dog bites occur equally during all moon phases are each  (32 + 27 + 47 + 38) = 36. A chi-square goodness-of-fit test gives
(32 + 27 + 47 + 38) = 36. A chi-square goodness-of-fit test gives  and with df = 4 – 1 = 3, P(
and with df = 4 – 1 = 3, P( 2 > 6.167) = 0.1038. With this large a P-value (0.1038 > 0.10), there is not sufficient evidence to conclude that dog bites are related to moon phases.
2 > 6.167) = 0.1038. With this large a P-value (0.1038 > 0.10), there is not sufficient evidence to conclude that dog bites are related to moon phases.
3. (B) df = (rows – 1)(columns – 1) = (2 – 1)(5 – 1) = 4
4. (C) Picking separate samples from each of 16 populations and classifying according to one variable (perception of quality education) is a survey design which is most appropriately analyzed using a chi-square test of homogeneity of proportions.
5. (D) With 77 + 85 + 23 + 15 = 200 samples, the expected counts if the blood type distribution on the island is the same as that of the general population are 46% of 200 = 92, 40% of 200 = 80, 10% of 200 = 20, and 4% of 200 = 8. A chi-square goodness-of-fit test gives  and with df = 4 – 1 = 3, P(2 > 9.333) = 0.0252. With a P-value this small (0.0252 < 0.05), there is sufficient evidence at the 5% significance level that blood type distribution on the island is different from that of the general population.
and with df = 4 – 1 = 3, P(2 > 9.333) = 0.0252. With a P-value this small (0.0252 < 0.05), there is sufficient evidence at the 5% significance level that blood type distribution on the island is different from that of the general population.
6. (D) With df = (3 – 1)(5 – 1) = 8, P(2 > 13.95) = 0.083. Since 0.05 < 0.083 < 0.10, there is evidence at the 10% significance level, but not at the 5% significance level, of a relationship between education level and sports interest.
7. (E) With a P-value this small (less than 0.05), there is evidence in support of the alternative hypothesis Ha: the distributions of music preferences are different, that is, they differ for at least one of the proportions.
8. (D) With 1 + 3 + 3 + 9 = 16, according to the geneticist the expected number of fruit flies of each species is  1125. A chi-square goodness-of-fit test gives
1125. A chi-square goodness-of-fit test gives

and with df = 4 – 1 = 3, P(2 > 8) = 0.0460. With a P-value this small (0.0460 < 0.05), there is sufficient evidence at the 5% significance level to reject the geneticist’s claim.
9. (E) A chi-square test of independence gives 2 = 2.852, and with df = 2, we find P = 0.2403, and since 0.2403 > 0.10, there is not evidence at the 10% significance level of a relationship between taste preference and the presence of the marker.
10. (E) A chi-square test of homogeneity gives 2 = 5.998, and with df = 3, the P-value is 0.1117. With a P-value this large (0.1117 > 0.10) there is not evidence of a difference in cafeteria food satisfaction among the class levels.
11. (E) The relevant P-value is 0.065 which is less than 0.10 but greater than 0.05.
12. (E) In computer printouts of regression analysis, “S” typically gives the standard deviation of the residuals.
FREE-RESPONSE
1. First, state the hypotheses: H0: The colors of the sugar shells are distributed according to 35% cherry red, 10% vibrant orange, 10% daffodil yellow, 25% emerald green, and 20% royal purple, and Ha: The colors of the sugar shells are not distributed as claimed by the manufacturer. Or [H0: PCR = 0.35, PVO = 0.10, PDY = 0.10, PEG = 0.25, PRP = 0.20, and Ha: at least one proportion is different from this distribution.]
Second, identify the test and check the assumptions: 2 goodness-of-fit test. We are given a random sample, and calculate that all expected cells are at least 5: 35% of 300 = 105, 10% of 300 = 30, 25% of 300 = 75, and 20% of 300 = 60.
Third, calculate the test statistic 2 and the P-value: A calculator gives

Fourth, linking to the P-value, give a conclusion in context: With a P-value this large (0.153 > 0.10), there is not sufficient evidence to reject H0, that is, there is not sufficient evidence that the distribution is different from what is claimed by the manufacturer.
2. (a) Design I, with a single sample from one population classified on two variables (smoking and fitness), will result in a test of independence. Design II, with independent samples from two populations each with the single variable (fitness), will result in a test of homogeneity.
(b) Design II, with its test of homogeneity, and using an equal sample size from each of the two populations (smokers and non-smokers), is best for comparing proportions of smokers who have different fitness levels with proportions of non-smokers who have different fitness levels.
(c) Design I, which classifies one population on the two variables, smoking and fitness, is the only one of these two designs which will give data on the conditional distribution of people with given fitness levels who are smokers or are not smokers.
3. (a) First, state the hypotheses: H0: Happiness level is independent of busy/idle choice for high school students and Ha: Happiness level is not independent of busy/idle choice for high school students.
Second, identify the procedure and check the conditions: This is a chi-square test of independence. It is given that there is a random sample, the data are measured as “counts,” and the expected counts are all at least 5 (put the observed counts in a matrix; then 2-Test on the TI-84 gives expected counts of
14.6 | 19.6 | 21.8 | 20.2 | 21.8 |
11.4 | 15.4 | 17.2 | 15.8 | 17.2 |
Third, calculate the test statistic and the P-value: Calculator software (2-Test on the TI-84) gives 2 = 14.54 with P = 0.0058 and df = 4.
Fourth, give a conclusion in context with linkage to the P-value: With a P-value this small, 0.0058 < 0.01, there is strong evidence to reject H0, that is, there is strong evidence of a relationship between happiness level and busy/idle choice for high school students.
(b) No, it is not reasonable to conclude that encouraging high school students to keep more busy will lead to higher happiness levels. This was not an experiment with students randomly chosen to sit or walk. The students themselves chose whether or not to sit or walk so no cause-and-effect conclusion is possible. For example, it could well be that the happier students choose to walk, whereas the less happy students choose to sit.
4. (a) First, state the hypotheses: H0: Eating breakfast and morning energy level are independent and Ha: Eating breakfast and morning energy level are not independent.
Second, identify the test and check the assumptions: This is a 2 test of independence on
111 | 120 | 120 |
60 | 50 | 40 |
where we are given a random sample, and a calculator gives that all expected cells are at least 5:
119 | 119 | 112 |
51 | 51 | 48 |
Third, calculate the test statistic 2 and the P-value: Calculator software (such as 2-Test on the TI-84) gives 2 = 4.202 and P = 0.1224.
Fourth, linking to the P-value, give a conclusion in context: With this large a P-value, 0.1224 > 0.05, there is not sufficient evidence to reject H0, that is, there is not sufficient evidence of a relationship between eating breakfast and morning energy level.
(b) Yes, the conclusion changes. With n = 1000, the observed numbers are:
220 | 240 | 240 |
120 | 100 | 80 |
with 2 = 8.403 and P = 0.0150. With a P-value this small (0.0150 < 0.05), now there is sufficient evidence of a relationship between eating breakfast and morning energy level.
5. (a) First, state the hypotheses: H0: The different treatments lead to the same satisfaction levels and Ha: The different treatments lead to different satisfaction levels.
Second, identify the test and check the assumptions: 2 test of homogeneity. We are given a random sample, and a calculator gives that all expected cells are at least 5:
55.6 | 55.6 | 27.8 |
23.6 | 23.6 | 11.8 |
20.8 | 20.8 | 10.4 |
Third, calculate the test statistic 2 and the P-value: A calculator gives 2 = 10.9521, and with df = 4, P = 0.0271.
Fourth, linking to the P-value, give a conclusion in context: With this small a P-value, 0.0271 < 0.05, there is sufficient evidence to reject H0, that is, there is sufficient evidence that the different treatments do lead to different satisfaction levels.
(b) An example of a possible confounding variable is severity of the acne outbreak. It could be that those with more severe cases have less satisfaction no matter what the treatment and are also the ones who are encouraged to use oral medications or laser therapy. So it would be wrong to conclude that oral medications or laser therapy are the causes of less satisfaction.
6. (a) Each additional year in age of teenagers is associated with an average of 0.4577 more texts per waking hour.
(b) The scatterplot of texts per hour versus age should be roughly linear, there should be no apparent pattern in the residual plot, and a histogram of the residuals should be approximately normal.
(c) First, state the hypotheses: H0: = 0, Ha: ≠ 0, where is the slope of the regression line that relates average texts per hour to age.
Second, identify the test and check the assumptions: This is a test of significance for the slope of the regression line, and we are given that all conditions for inference are met.
Third, calculate the test statistic t and the P-value: The computer printout gives that t = 2.45 and P = 0.016.
Fourth, linking to the P-value, give a conclusion in context: With this small a P-value, 0.016 < 0.05, there is sufficient evidence to reject H0, that is, there is sufficient evidence of a linear relationship between average texts per hour and age for teenagers ages 13–17.
(d) R–Sq = 5.8%, so even though there is evidence of a linear relationship between average texts per hour and age for teenagers ages 13–17, only 5.8% of the variability in average texts per hour is explained by this regression model (or “is accounted for by the variation in age.”).
7. First, state the hypotheses: H0: = 0, Ha: ≠ 0. (If asked to state the parameter, then state “where is the slope of the regression line that relates average fertility rate to women’s life expectancy.”)
Second, identify the test and check the assumptions: This is a test of significance for the slope of the regression line. We are given that the data come from a random sample of countries.

Third, calculate the test statistic t and the P-value: Using a calculator (for example, LinRegTTest on the TI-84) gives that t = –12.53 and P = 0.0000.
Fourth, linking to the P-value, give a conclusion in context: With a P-value this small, 0.0000 < 0.05, there is sufficient evidence to reject H0, that is, there is sufficient evidence of a linear relationship between average fertility rate (children/woman) and life expectancy (women).
INVESTIGATIVE TASK
1. (a) The binomial distribution with p = 0.2 and n = 3 results in: P(0) = (0.8)3 = 0.512, P(1) = 3(0.2)(0.8)2 = 0.384, P(2) = 3(0.2)2(0.8) = 0.096, P(3) = (0.8)3 = 0.008.
(b) Multiplying each of the probabilities in (a) by 800 gives the expected number of occurrences:
| 0 | 1 | 2 | 3 |
Expected (if binomial) | 409.6 | 307.2 | 76.8 | 6.4 |
(c) First, state the hypotheses: H0: The number of researchers able to determine the composition of a placebo follows a binomial with p = 0.2 and Ha: The number of researchers able to determine the composition of a placebo does not follow a binomial with p = 0.2.
Second, identify the test and check the assumptions: This is a chi-square test of goodness-of-fit. We must assume that the 800 studies form a representative sample. We note from (b) that all expected cells are 5:
Third, calculate the test statistic 2 and the P-value: A calculator gives 
Fourth, linking to the P-value, give a conclusion in context: With a P-value this small, 0.02549 < 0.05, there is sufficient evidence to reject H0, that is, there is sufficient evidence that the number of researchers able to determine the composition of a placebo does not follow a binomial with p = 0.2.
2. (a) This is a matched-pair t-test on the set of differences {–1.7, –0.2, 1.0, 2.0, 1.3, 0.4, –0.1, 0.4, 0.8, –1.2, 0.4, 0.9}, with H0: µd = 0 and Ha: µd > 0. The sample is random (given), and a dotplot of the differences is roughly unimodal and symmetric (so a normal population distribution is a reasonable assumption):

Calculator software (such as T-Test with Data on the TI-84) gives t = 1.121 and P = 0.143. [For instructional purposes in this review book, we note that = 0.3333,  and with df = 12 – 1 = 11, P = 0.143.] With a P-value this large, 0.143 > 0.05, there is not sufficient evidence to reject H0, that is, there is not sufficient evidence that the average student score is greater than that of the English teachers.
and with df = 12 – 1 = 11, P = 0.143.] With a P-value this large, 0.143 > 0.05, there is not sufficient evidence to reject H0, that is, there is not sufficient evidence that the average student score is greater than that of the English teachers.
(b) This is a matched-pair t-test on the set of differences {–0.3, 1.6, 0.7, 0.3, 0.5, –0.1, –0.8, 0.9, 0.5, –0.1, 0.2, 1.1}, with H0: µd = 0 and Ha: µd > 0. The sample is random (given), and a dotplot of the differences is roughly unimodal and symmetric (so a normal population distribution is a reasonable assumption):

Calculator software (such as T-Test with Data on the TI-84) gives t = 1.974 and P = 0.0370. [For instructional purposes in this review book, we note that = 0.375,  and with df = 12 – 1 = 11, P = 0.037.] With a P-value this small, 0.037 < 0.05, there is sufficient evidence to reject H0, that is, there is sufficient evidence that the average student score is greater than that of the math teachers.
and with df = 12 – 1 = 11, P = 0.037.] With a P-value this small, 0.037 < 0.05, there is sufficient evidence to reject H0, that is, there is sufficient evidence that the average student score is greater than that of the math teachers.
(c) In both regression analyses, the scatterplots are roughly linear and the residual plots show no apparent pattern; however, while 70.1% of the variance in student scores is explained by the variance in math teacher scores, only 27.8% of the variance in student scores is explained by variance in English teacher scores. Thus, the math teacher scores are a better predictor of student scores.
(d) Using the regression equation giving predicted student score as a function of math teacher score gives –0.330 + 1.0701(10.0) = 10.37.
(e) The regression output gives a standard deviation of s = 0.6867. Using the 10.37 estimate from part (d) gives a range of scores for students whose math teachers’ average score is 10.0 to be 10.37 ± 3(0.6867) = 10.37 ± 2.06. Thus, for schools where the math teachers’ average score is 10.0, almost all the average student scores will be between 8.31 and 12.4.
3. (a) The z-scores for 22.5 and 27.5 are, respectively,  Similarly, 17.5 and 12.5 have z-scores of –0.5 and –1.5, respectively. Using the normal probability table or a calculator gives the probabilities: P(z < –1.5) = 0.0668, P(–1.5 < z < –0.5) = 0.2417, P(–0.5 < z < 0.5) = 0.3830, P(0.5 < z < 1.5) = 0.2417, P(z > 1.5) = 0.0668.
Similarly, 17.5 and 12.5 have z-scores of –0.5 and –1.5, respectively. Using the normal probability table or a calculator gives the probabilities: P(z < –1.5) = 0.0668, P(–1.5 < z < –0.5) = 0.2417, P(–0.5 < z < 0.5) = 0.3830, P(0.5 < z < 1.5) = 0.2417, P(z > 1.5) = 0.0668.

(b) Multiplying each probability by 500: 0.0668(500) = 33.4, 0.2417(500) = 120.85, 0.3830(500) = 191.5, 0.2417(500) = 120.85, and 0.0668(500) = 33.4.

(c) First, state the hypotheses: H0: The weights of student backpacks follow a normal distribution with µ = 20 and = 5 and Ha: The weights of student backpacks do not follow a normal distribution with µ = 20 and = 5.
Second, identify the test and check the assumptions: This is a chi-square test of goodness-of-fit. We are given that the weights are from a random sample of students. We note from above that all expected cells are 5:
Third, calculate the test statistic 2 and the P-value: A calculator gives

Fourth, linking to the P-value, give a conclusion in context: With a P-value this large, 0.1476 > 0.05, there is not sufficient evidence to reject H0, that is, there is not sufficient evidence that the data do not follow a normal distribution with µ = 20 and = 5.
SECTION I
Questions 1–40
Spend 90 minutes on this part of the exam.
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. Following is a histogram of home sale prices (in thousands of dollars) in one community:
Which of the following conclusions is most correct?
(A) The median price was $125,000.
(B) The mean price was $125,000.
(C) More homes sold for between \$100,000 and \$125,000 than for over \$125,000.
(D) $10,000 is a reasonable estimate of the standard deviation in selling prices.
(E) 1.5 × 109 (\$2) is a reasonable estimate of the variance in selling prices.
2. Which of the following is most useful in establishing cause-and-effect relationships?
(A) A complete census
(B) A least squares regression line showing high correlation
(C) A simple random sample (SRS)
(D) A well-designed, well-conducted survey incorporating chance to ensure a representative sample
(E) An experiment
3. The average yearly snowfall in a city is 55 inches. What is the standard deviation if 15% of the years have snowfalls above 60 inches? Assume yearly snowfalls are normally distributed.
(A) 4.83
(B) 5.18
(C) 6.04
(D) 8.93
(E) The standard deviation cannot be computed from the information given.
4. To determine the average cost of running for a congressional seat, a simple random sample of 50 politicians is chosen and the politicians’ records examined. The cost figures show a mean of \$125,000 with a standard deviation of \$32,000. Which of the following is the best interpretation of a 90% confidence interval estimate for the average cost of running for office?
(A) 90% of politicians running for a congressional seat spend between \$117,500 and \$132,500.
(B) 90% of politicians running for a congressional seat spend a mean dollar amount that is between \$117,500 and \$132,500.
(C) We are 90% confident that politicians running for a congressional seat spend between \$117,500 and \$132,500.
(D) We are 90% confident that politicians running for a congressional seat spend a mean dollar amount between \$117,500 and \$132,500.
(E) We are 90% confident that in the chosen sample, the mean dollar amount spent running for a congressional seat is between \$117,500 and \$132,500.
5. In one study on the effect that eating meat products has on weight level, an SRS of 500 subjects who admitted to eating meat at least once a day had their weights compared with those of an independent SRS of 500 people who claimed to be vegetarians. In a second study, an SRS of 500 subjects were served at least one meat meal per day for 6 months, while an independent SRS of 500 others were chosen to receive a strictly vegetarian diet for 6 months, with weights compared after 6 months.
(A) The first study is a controlled experiment, while the second is an observational study.
(B) The first study is an observational study, while the second is a controlled experiment.
(C) Both studies are controlled experiments.
(D) Both studies are observational studies.
(E) Each study is part controlled experiment and part observational study.
6. A plumbing contractor obtains 60% of her boiler circulators from a company whose defect rate is 0.005, and the rest from a company whose defect rate is 0.010. If a circulator is defective, what is the probability that it came from the first company?
(A) 0.429
(B) 0.500
(C) 0.571
(D) 0.600
(E) 0.750
7. A kidney dialysis center periodically checks a sample of its equipment and performs a major recalibration if readings are sufficiently off target. Similarly, a fabric factory periodically checks the sizes of towels coming off an assembly line and halts production if measurements are sufficiently off target. In both situations, we have the null hypothesis that the equipment is performing satisfactorily. For each situation, which is the more serious concern, a Type I or Type II error?
(A) Dialysis center: Type I error, towel manufacturer: Type I error
(B) Dialysis center: Type I error, towel manufacturer: Type II error
(C) Dialysis center: Type II error, towel manufacturer: Type I error
(D) Dialysis center: Type II error, towel manufacturer: Type II error
(E) This is impossible to answer without making an expected value judgment between human life and accurate towel sizes.
8. A coin is weighted so that the probability of heads is 0.75. The coin is tossed 10 times and the number of heads is noted. This procedure is repeated a total of 50 times, and the number of heads is recorded each time. What kind of distribution has been simulated?
(A) The sampling distribution of the sample proportion with n = 10 and p = 0.75
(B) The sampling distribution of the sample proportion with n = 50 and p = 0.75
(C) The sampling distribution of the sample mean with x = 10(0.75) and 
(D) The binomial distribution with n = 10 and p = 0.75
(E) The binomial distribution with n = 50 and p = 0.75
9. During the years 1886 through 2000 there were an average of 8.7 tropical cyclones per year, of which an average of 5.1 became hurricanes. Assuming that the probability of any cyclone becoming a hurricane is independent of what happens to any other cyclone, if there are five cyclones in one year, what is the probability that at least three become hurricanes?
(A) 0.313
(B) 0.345
(C) 0.586
(D) 0.658
(E) 0.686
10. Given the probabilities P(A) = 0.3 and P(B) = 0.2, what is the probability of the union P(A ∪ B) if A and B are mutually exclusive? If A and B are independent? If B is a subset of A?
(A) 0.44, 0.5, 0.2
(B) .44, 0.5, 0.3
(C) .5, 0.44, 0.2
(D) .5, 0.44, 0.3
(E) 0, 0.5, 0.3
11. A nursery owner claims that a recent drought stunted the growth of 22% of all her evergreens. A botanist tests this claim by examining an SRS of 1100 evergreens and finds that 268 trees in the sample show signs of stunted growth. With H0: p = 0.22 and Ha: p ≠ 0.22, what is the value of the test statistic?

12. A medical research team tests for tumor reduction in a sample of patients using three different dosages of an experimental cancer drug. Which of the following is true?
(A) There are three explanatory variables and one response variable.
(B) There is one explanatory variable with three levels of response.
(C) Tumor reduction is the only explanatory variable, but there are three response variables corresponding to the different dosages.
(D) There are three levels of a single explanatory variable.
(E) Each explanatory level has an associated level of response.
13. The graph below shows cumulative proportion plotted against age for a population.
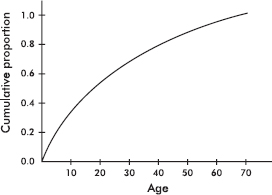
The median is approximately what age?
(A) 17
(B) 30
(C) 35
(D) 40
(E) 45
14. Mr. Bee’s statistics class had a standard deviation of 11.2 on a standardized test, while Mr. Em’s class had a standard deviation of 5.6 on the same test. Which of the following is the most reasonable conclusion concerning the two classes’ performance on the test?
(A) Mr. Bee’s class is less heterogeneous than Mr. Em’s.
(B) Mr. Em’s class is more homogeneous than Mr. Bee’s.
(C) Mr. Bee’s class performed twice as well as Mr. Em’s.
(D) Mr. Em’s class did not do as well as Mr. Bee’s.
(E) Mr. Bee’s class had the higher mean, but this may not be statistically significant.
15. A college admissions officer is interested in comparing the SAT math scores of high school applicants who have and have not taken AP Statistics. She randomly pulls the files of five applicants who took AP Statistics and five applicants who did not, and proceeds to run a t-test to compare the mean SAT math scores of the two groups. Which of the following is a necessary assumption?
(A) The population variances from each group are known.
(B) The population variances from each group are unknown.
(C) The population variances from the two groups are equal.
(D) The population of SAT scores from each group is normally distributed.
(E) The samples must be independent simple random samples, and for each sample np and n(1 – p) must both be at least 10.
16. The appraised values of houses in a city have a mean of \$125,000 with a standard deviation of \$23,000. Because of a new teachers’ contract, the school district needs an extra 10% in funds compared to the previous year. To raise this additional money, the city instructs the assessment office to raise all appraised house values by \$5,000. What will be the new standard deviation of the appraised values of houses in the city?
(A) $23,000
(B) $25,300
(C) $28,000
(D) $30,300
(E) $30,800
17. A psychologist hypothesizes that scores on an aptitude test are normally distributed with a mean of 70 and a standard deviation of 10. In a random sample of size 100, scores are distributed as in the table below. What is the $\chi$2 statistic for a goodness-of-fit test?

18. A talk show host recently reported that in response to his on-air question, 82% of the more than 2500 e-mail messages received through his publicized address supported the death penalty for anyone convicted of selling drugs to children. What does this show?
(A) The survey is meaningless because of voluntary response bias.
(B) No meaningful conclusion is possible without knowing something more about the characteristics of his listeners.
(C) The survey would have been more meaningful if he had picked a random sample of the 2500 listeners who responded.
(D) The survey would have been more meaningful if he had used a control group.
(E) This was a legitimate sample, randomly drawn from his listeners, and of sufficient size to be able to conclude that most of his listeners support the death penalty for such a crime.
19. Define a new measurement as the difference between the 60th and 40th percentile scores in a population. This measurement will give information concerning
(A) central tendency.
(B) variability.
(C) symmetry.
(D) skewness.
(E) clustering.
20. Suppose X and Y are random variables with E(X) = 37, var(X) = 5, E(Y) = 62, and var(Y) = 12. What are the expected value and variance of the random variable X + Y?
(A) E(X + Y) = 99, var(X + Y) = 8.5
(B) E(X + Y) = 99, var(X + Y) = 13
(C) E(X + Y) = 99, var(X + Y) = 17
(D) E(X + Y) = 49.5, var(X + Y) = 17
(E) There is insufficient information to answer this question.
21. Which of the following can affect the value of the correlation r?
(A) A change in measurement units
(B) A change in which variable is called x and which is called y
(C) Adding the same constant to all values of the x-variable
(D) All of the above can affect the r value.
(E) None of the above can affect the r value.
22. The American Medical Association (AMA) wishes to determine the percentage of obstetricians who are considering leaving the profession because of the rapidly increasing number of lawsuits against obstetricians. How large a sample should be taken to find the answer to within ±3% at the 95% confidence level?
(A) 6
(B) 33
(C) 534
(D) 752
(E) 1068
23. Suppose you did 10 independent tests of the form H0: µ = 25 versus Ha: µ < 25, each at the α = 0.05 significance level. What is the probability of committing a Type I error and incorrectly rejecting a true H0 with at least one of the 10 tests?
(A) 0.05
(B) 0.40
(C) 0.50
(D) 0.60
(E) 0.95
24. Which of the following sets has the smallest standard deviation? Which has the largest?
I. 1, 2, 3, 4, 5, 6, 7
II. 1, 1, 1, 4, 7, 7, 7
III. 1, 4, 4, 4, 4, 4, 7
(A) I, II
(B) II, III
(C) III, I
(D) II, I
(E) III, II
25. A researcher plans a study to examine long-term confidence in the U.S. economy among the adult population. She obtains a simple random sample of 30 adults as they leave a Wall Street office building one weekday afternoon. All but two of the adults agree to participate in the survey. Which of the following conclusions is correct?
(A) Proper use of chance as evidenced by the simple random sample makes this a well-designed survey.
(B) The high response rate makes this a well-designed survey.
(C) Selection bias makes this a poorly designed survey.
(D) A voluntary response study like this gives too much emphasis to persons with strong opinions.
(E) Lack of anonymity makes this a poorly designed survey.
26. Which among the following would result in the narrowest confidence interval?
(A) Small sample size and 95% confidence
(B) Small sample size and 99% confidence
(C) Large sample size and 95% confidence
(D) Large sample size and 99% confidence
(E) This cannot be answered without knowing an appropriate standard deviation.
27. Consider the following three scatterplots:
What is the relationship among r1, r2, and r3, the correlations associated with the first, second, and third scatterplots, respectively?
(A) r1 < r2 < r3
(B) r1 < r3 < r2
(C) r2 < r3 < r1
(D) r3 < r1 < r2
(E) r3 < r2 < r1
28. There are two games involving flipping a coin. In the first game you win a prize if you can throw between 45% and 55% heads. In the second game you win if you can throw more than 80% heads. For each game would you rather flip the coin 30 times or 300 times?
(A) 30 times for each game
(B) 300 times for each game
(C) 30 times for the first game and 300 times for the second
(D) 300 times for the first game and 30 times for the second
(E) The outcomes of the games do not depend on the number of flips.
29. City planners are trying to decide among various parking plan options ranging from more on-street spaces to multilevel facilities to spread-out small lots. Before making a decision, they wish to test the downtown merchants’ claim that shoppers park for an average of only 47 minutes in the downtown area. The planners have decided to tabulate parking durations for 225 shoppers and to reject the merchants’ claim if the sample mean exceeds 50 minutes. If the merchants’ claim is wrong and the true mean is 51 minutes, what is the probability that the random sample will lead to a mistaken failure to reject the merchants’ claim? Assume that the standard deviation in parking durations is 27 minutes.
30. Consider the following parallel boxplots indicating the starting salaries (in thousands of dollars) for blue collar and white collar workers at a particular production plant:
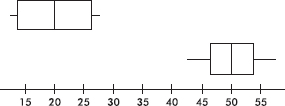
Which of the following is a correct conclusion?
(A) The ranges of the distributions are the same.
(B) In each distribution the mean is equal to the median.
(C) Each distribution is symmetric.
(D) Each distribution is roughly normal.
(E) The distributions are outliers of each other.
31. The mean Law School Aptitude Test (LSAT) score for applicants to a particular law school is 650 with a standard deviation of 45. Suppose that only applicants with scores above 700 are considered. What percentage of the applicants considered have scores below 740? (Assume the scores are normally distributed.)
(A) 13.3%
(B) 17.1%
(C) 82.9%
(D) 86.7%
(E) 97.7%
32. If all the other variables remain constant, which of the following will increase the power of a hypothesis test?
I. Increasing the sample size.
II. Increasing the significance level.
III. Increasing the probability of a Type II error.
(A) I only
(B) II only
(C) III only
(D) I and II
(E) All are true.
33. A researcher planning a survey of school principals in a particular state has lists of the school principals employed in each of the 125 school districts. The procedure is to obtain a random sample of principals from each of the districts rather than grouping all the lists together and obtaining a sample from the entire group. Which of the following is a correct conclusion?
(A) This is a simple random sample obtained in an easier and less costly manner than procedures involving sampling from the entire population of principals.
(B) This is a cluster sample in which the population was divided into heterogeneous groups called clusters.
(C) This is an example of systematic sampling, which gives a reasonable sample as long as the original order of the list is not related to the variables under consideration.
(D) This is an example of proportional sampling based on sizes of the school districts.
(E) This is a stratified sample, which may give comparative information that a simple random sample wouldn’t give.
34. A simple random sample is defined by
(A) the method of selection.
(B) examination of the outcome.
(C) both of the above.
(D) how representative the sample is of the population.
(E) the size of the sample versus the size of the population.
35. Changing from a 90% confidence interval estimate for a population proportion to a 99% confidence interval estimate, with all other things being equal,
(A) increases the interval size by 9%.
(B) decreases the interval size by 9%.
(C) increases the interval size by 57%.
(D) decreases the interval size by 57%.
(E) This question cannot be answered without knowing the sample size.
36. Which of the following is a true statement about hypothesis testing?
(A) If there is sufficient evidence to reject a null hypothesis at the 10% level, then there is sufficient evidence to reject it at the 5% level.
(B) Whether to use a one- or a two-sided test is typically decided after the data are gathered.
(C) If a hypothesis test is conducted at the 1% level, there is a 1% chance of rejecting the null hypothesis.
(D) The probability of a Type I error plus the probability of a Type II error always equal 1.
(E) The power of a test concerns its ability to detect an alternative hypothesis.
37. A population is normally distributed with mean 25. Consider all samples of size 10. The variable 
(A) has a normal distribution.
(B) has a t-distribution with df = 10.
(C) has a t-distribution with df = 9.
(D) has neither a normal distribution or a t-distribution.
(E) has either a normal or a t-distribution depending on the characteristics of the population standard deviation.
38. A correlation of 0.6 indicates that the percentage of variation in y that is explained by the variation in x is how many times the percentage indicated by a correlation of 0.3?
(A) 2
(B) 3
(C) 4
(D) 6
(E) There is insufficient information to answer this question.
39. As reported on CNN, in a May 1999 national poll 43% of high school students expressed fear about going to school. Which of the following best describes what is meant by the poll having a margin of error of 5%?
(A) It is likely that the true proportion of high school students afraid to go to school is between 38% and 48%.
(B) Five percent of the students refused to participate in the poll.
(C) Between 38% and 48% of those surveyed expressed fear about going to school.
(D) There is a 0.05 probability that the 43% result is in error.
(E) If similar size polls were repeatedly taken, they would be wrong about 5% of the time.
40. In a high school of 1650 students, 132 have personal investments in the stock market. To estimate the total stock investment by students in this school, two plans are proposed. Plan I would sample 30 students at random, find a confidence interval estimate of their average investment, and then multiply both ends of this interval by 1650 to get an interval estimate of the total investment. Plan II would sample 30 students at random from among the 132 who have investments in the market, find a confidence interval estimate of their average investment, and then multiply both ends of this interval by 132 to get an interval estimate of the total investment. Which is the better plan for estimating the total stock market investment by students in this school?
(A) Plan I
(B) Plan II
(C) Both plans use random samples and so will produce equivalent results.
(D) Neither plan will give an accurate estimate.
(E) The resulting data must be seen to evaluate which is the better plan.
If there is still time remaining, you may review your answers.
SECTION II
Part A
QUESTIONS 1–5
Spend about 65 minutes on this part of the exam.
Percentage of Section II grade—75
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your results and explanations.
1. Cumulative frequency graphs of the heights (in inches) of athletes playing college baseball (A), basketball (B), and football (C) are given below:
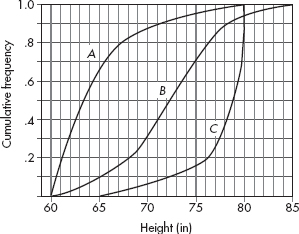
Write a few sentences comparing the distributions of heights of athletes playing the three college sports.
2. When students do not understand an author’s vocabulary, there is no way they can fully understand the text; thus, learning vocabulary is recognized as one of the most important skills in all subject areas. A school system is planning a study to see which of two programs is more effective in ninth grade. Program A involves teaching students to apply morphemic analysis, the process of deriving a word’s meaning by analyzing its meaningful parts, such as roots, prefixes, and suffixes. Program B involves teaching students to apply contextual analysis, the process of inferring the meaning of an unfamiliar word by examining the surrounding text.
(a) Explain the purpose of incorporating a control group in this experiment.
(b) To comply with informed consent laws, parents will be asked their consent for their children to be randomly assigned to be taught in one of the new programs or by the local standard method. Students of parents who do not return the consent forms will continue to be taught by the local standard method. Explain why these students should not be considered part of the control group.
(c) Given 90 students randomly selected from ninth grade students with parental consent, explain how to assign them to the three groups, Program A, Program B, and Control, for a completely randomized design.
3. An experiment is designed to test a home insulation product. Two side-by-side identical houses are chosen, and in one the insulation product is installed (blown into the attic). Both homes use natural gas for heating, and the thermostat in each house is fixed at 68 degrees Fahrenheit. On 30 randomly chosen winter days, the quantity of gas (in hundreds of cubic feet) used to heat each house is measured. The table below summarizes the data.
(a) Is there evidence that the insulation product does result in a lower mean quantity of gas being used?
Two least square regression calculations are performed with the following computer output, where Temp is the average outside temperature, and WithOut and With are the quantities of gas (in hundreds of cubic feet) used to heat the two homes on a day with that outside temperature:
Regression Analysis: WithOut versus Temp
Predictor | Coef | SE Coef | T | P |
Constant | 10.0228 | 0.4009 | 25.00 | 0.000 |
Temp | –0.14926 | 0.01879 | –7.94 | 0.000 |
S = 0.890921R–Sq = 69.3%R–Sq(adj) = 68.2%
Regression Analysis: With versus Temp
Predictor | Coef | SE Coef | T | P |
Constant | 7.5850 | 0.3531 | 21.48 | 0.000 |
Temp | –0.10408 | 0.01655 | –6.29 | 0.000 |
S = 0.784653R–Sq = 58.5%R–Sq(adj) = 57.1%
(b) Compare the slopes of the regression lines in context of this problem.
(c) Compare the y-intercepts of the regression lines in context of this problem.
4. A new anti-spam software program is field tested on 1000 e-mails and the results are summarized in the following table (positive test = program labels e-mail as spam):

Using the above empirical results, determine the following probabilities.
(a) (i) What is the predictive value of the test? That is, what is the probability that an e-mail is spam and the test is positive?
(ii) What is the false-positive rate? That is, what is the probability of testing positive given that the e-mail is legitimate?
(b) (i) What is the sensitivity of the test? That is, what is the probability of testing positive given that the e-mail is spam?
(ii) What is the specificity of the test? That is, what is the probability of testing negative given that the e-mail is legitimate?
(c) (i) Given a random sample of five legitimate e-mails, what is the probability that the program labels at least one as spam?
(ii) Given a random sample of five spam e-mails, what is the probability that the program correctly labels at least three as spam?
(d) (i) If 35% of the incoming e-mails from one source are spam, what is the probability that an e-mail from that source will be labeled as spam?
(ii) If an e-mail from this source is labeled as spam, what is the probability it really is spam?
5. Cumulative exposure to nitrogen dioxide (NO2) is a major risk factor for lung disease in tunnel construction workers. In a 2004 study, researchers compared cumulative exposure to NO2 for a random sample of drill and blast workers and for an independent random sample of concrete workers. Summary statistics are shown below.
Tunnel worker activity | Sample size | Mean cumulative NO2 exposure (ppm*/yr) | Standard deviation in cumulative NO2 exposure (ppm*/yr) |
Drill and blast | 115 | 4.1 | 1.8 |
Concrete | 69 | 4.8 | 2.4 |
*Parts per million
(a) Find a 95% confidence interval estimate for the difference in mean cumulative NO2 exposure for drill and blast workers and concrete workers.
(b) Using this confidence interval, is there evidence of a difference in mean cumulative NO2 exposure for drill and blast workers and concrete workers? Explain.
(c) It turns out that both data sets were somewhat skewed. Does this invalidate your analysis? Explain.
SECTION II
Part B
QUESTION 6
Spend about 25 minutes on this part of the exam.
Percentage of Section II grade—25
6. Do strong magnetic fields have an effect on the early development of mice? A study is performed on a random sample of 120 one-month-old mice. Each is subjected to a strong magnetic field for one week and no magnetic field for one week, the order being decided randomly for each mouse. The weight gain in grams during each week for each mouse is recorded. The weight gains with no magnetic field are approximately normally distributed with a mean of 25.1 grams and a standard deviation of 3.1 grams, while the weight gains in the magnetic field are approximately normally distributed with a mean of 17.3 grams and a standard deviation of 5.7 grams. Of the 120 mice, 101 gained more weight with no magnetic field.
(a) Calculate and interpret a 95% confidence interval for the proportion of mice that gain more weight with no magnetic field.
(b) Suppose two of these mice were chosen at random. What is the probability that the first mouse gained more weight with no magnetic field than the second mouse gained in the magnetic field?
(c) Based on your answers to (a) and (b), is there evidence that for mice, weight gain with no magnetic field and in a magnetic field are independent?
(d) In a test for variances on whether or not the variances of the two sets of weight gains are significantly different, ![]() with α = 0.05, for samples of this size, the critical cut-off scores for
with α = 0.05, for samples of this size, the critical cut-off scores for ![]() are 0.698 (left tail of 0.025) and 1.43 (right tail of 0.025). What is the resulting conclusion about variances?
are 0.698 (left tail of 0.025) and 1.43 (right tail of 0.025). What is the resulting conclusion about variances?
If there is still time remaining, you may review your answers.
SECTION I
Questions 1–40
Spend 90 minutes on this part of the exam.
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. Suppose that the regression line for a set of data, $\widehat{y}$ = mx + 3, passes through the point (2, 7). If $\overline{x}$ and $\overline{y}$ are the sample means of the x– and y-values, respectively, then $\overline{y}$ =
(A) $\overline{x}$.
(B) $\overline{x}$ – 2.
(C) $\overline{x}$ + 3.
(D) 2$\overline{x}$ + 3.
(E) 3.5$\overline{x}$ + 3.
2. A study is made to determine whether more hours of academic studying leads to higher point scoring by basketball players. In surveying 50 basketball players, it is noted that the 25 who claim to study the most hours have a higher point average than the 25 who study less. Based on this study, the coach begins requiring the players to spend more time studying. Which of the following is a correct statement?
(A) While this study may have its faults, it still does prove causation.
(B) There could well be a confounding variable responsible for the seeming relationship.
(C) While this is a controlled experiment, the conclusion of the coach is not justified.
(D) To get the athletes to study more, it would be more meaningful to have them put in more practice time on the court to boost their point averages, as higher point averages seem to be associated with more study time.
(E) No proper conclusion is possible without somehow introducing blinding.
3. The longevity of people living in a certain locality has a standard deviation of 14 years. What is the mean longevity if 30% of the people live longer than 75 years? Assume a normal distribution for life spans.
(A) 61.00
(B) 67.65
(C) 74.48
(D) 82.35
(E) The mean cannot be computed from the information given.
4. Which of the following is a correct statement about correlation?
(A) If the slope of the regression line is exactly 1, then the correlation is exactly 1.
(B) If the correlation is 0, then the slope of the regression line is undefined.
(C) Switching which variable is called x and which is called y changes the sign of the correlation.
(D) The correlation r is equal to the slope of the regression line when z-scores for the y-variable are plotted against z-scores for the x-variable.
(E) Changes in the measurement units of the variables may change the correlation.
5. Which of the following are affected by outliers?
I. Mean
II. Median
III. Standard deviation
IV. Range
V. Interquartile range
(A) I, III, and V
(B) II and IV
(C) I and V
(D) III and IV
(E) I, III, and IV
6. An engineer wishes to determine the quantity of heat being generated by a particular electronic component. If she knows that the standard deviation is 2.4, how many of these components should she consider to be 99% sure of knowing the mean quantity to within ±0.6?
(A) 27
(B) 87
(C) 107
(D) 212
(E) 425
7. A company that produces facial tissues continually monitors tissue strength. If the mean strength from sample data drops below a specified level, the production process is halted and the machinery inspected. Which of the following would result from a Type I error?
(A) Halting the production process when sufficient customer complaints are received.
(B) Halting the production process when the tissue strength is below specifications.
(C) Halting the production process when the tissue strength is within specifications.
(D) Allowing the production process to continue when the tissue strength is below specifications.
(E) Allowing the production process to continue when the tissue strength is within specifications.
8. Two possible wordings for a questionnaire on a proposed school budget increase are as follows:
I. This school district has one of the highest per student expenditure rates in the state. This has resulted in low failure rates, high standardized test scores, and most students going on to good colleges and universities. Do you support the proposed school budget increase?
II. This school district has one of the highest per student expenditure rates in the state. This has resulted in high property taxes, with many people on fixed incomes having to give up their homes because they cannot pay the school tax. Do you support the proposed school budget increase?
One of these questions showed that 58% of the population favor the proposed school budget increase, while the other question showed that only 13% of the population support the proposed increase. Which produced which result and why?
(A) The first showed 58% and the second 13% because of the lack of randomization as evidenced by the wording of the questions.
(B) The first showed 13% and the second 58% because of a placebo effect due to the wording of the questions.
(C) The first showed 58% and the second 13% because of the lack of a control group.
(D) The first showed 13% and the second 58% because of response bias due to the wording of the questions.
(E) The first showed 58% and the second 13% because of response bias due to the wording of the questions.
9. Suppose that for a certain Caribbean island in any 3-year period the probability of a major hurricane is 0.25, the probability of water damage is 0.44, and the probability of both a hurricane and water damage is 0.22. What is the probability of water damage given that there is a hurricane?
(A) 0.25 + 0.44 – 0.22
(B) 0.22/0.44
(C) 0.25 + 0.44
(D) 0.22/0.25
(E) 0.25 + 0.44 + 0.22
10. A union spokesperson is trying to encourage a college faculty to join the union. She would like to argue that faculty salaries are not truly based on years of service as most faculty believe. She gathers data and notes the following scatterplot of salary versus years of service.
Which of the following most correctly interprets the overall scatterplot?
(A) The faculty member with the fewest years of service makes the lowest salary, and the faculty member with the most service makes the highest salary.
(B) A faculty member with more service than another has the greater salary than the other.
(C) There is a strong positive correlation with little deviation.
(D) There is no clear relationship between salary and years of service.
(E) While there is a strong positive correlation, there is a distinct deviation from the overall pattern for faculty with fewer than ten years of service.
11. Two random samples of students are chosen, one from those taking an AP Statistics class and one from those not. The following back-to-back stemplots compare the GPAs.

Which of the following is true about the ranges and standard deviations?
(A) The first set has both a greater range and a greater standard deviation.
(B) The first set has a greater range, while the second has a greater standard deviation.
(C) The first set has a greater standard deviation, while the second has a greater range.
(D) The second set has both a greater range and a greater standard deviation.
(E) The two sets have equal ranges and equal standard deviations.
12. In a group of 10 scores, the largest score is increased by 40 points. What will happen to the mean?
(A) It will remain the same.
(B) It will increase by 4 points.
(C) It will increase by 10 points.
(D) It will increase by 40 points.
(E) There is not sufficient information to answer this question.
13. Suppose X and Y are random variables with µx = 32, $\sigma$x = 5, µy = 44, and $\sigma$y = 12. Given that X and Y are independent, what are the mean and standard deviation of the random variable X + Y?
(A) µx+y = 76, $\sigma$x+y = 8.5
(B) µx+y = 76, $\sigma$x+y = 13
(C) µx+y = 76, $\sigma$x+y = 17
(D) µx+y = 38, $\sigma$x+y = 17
(E) There is insufficient information to answer this question.
14. Suppose you toss a fair die three times and it comes up an even number each time. Which of the following is a true statement?
(A) By the law of large numbers, the next toss is more likely to be an odd number than another even number.
(B) Based on the properties of conditional probability the next toss is more likely to be an even number given that three in a row have been even.
(C) Dice actually do have memories, and thus the number that comes up on the next toss will be influenced by the previous tosses.
(D) The law of large numbers tells how many tosses will be necessary before the percentages of evens and odds are again in balance.
(E) The probability that the next toss will again be even is 0.5.
15. A pharmaceutical company is interested in the association between advertising expenditures and sales for various over-the-counter products. A sales associate collects data on nine products, looking at sales (in \$1000) versus advertising expenditures (in \$1000). The results of the regression analysis are shown below.
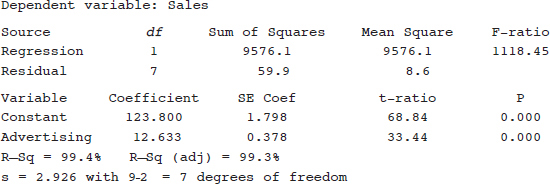
Which of the following gives a 90% confidence interval for the slope of the regression line?
(A) 12.633 ± 1.415(0.378)
(B) 12.633 ± 1.895(0.378)
(C) 123.800 ± 1.414(1.798)
(D) 123.800 ± 1.895(1.798)
(E) 123.800 ± 1.645(1.798/$\sqrt{9}$)
16. Suppose you wish to compare the AP Statistics exam results for the male and female students taking AP Statistics at your high school. Which is the most appropriate technique for gathering the needed data?
(A) Census
(B) Sample survey
(C) Experiment
(D) Observational study
(E) None of these is appropriate.
17. Jonathan obtained a score of 80 on a statistics exam, placing him at the 90th percentile. Suppose five points are added to everyone’s score. Jonathan’s new score will be at the
(A) 80th percentile.
(B) 85th percentile.
(C) 90th percentile.
(D) 95th percentile.
(E) There is not sufficient information to answer this question.
18. To study the effect of music on piecework output at a clothing manufacturer, two experimental treatments are planned: day-long classical music for one group versus day-long light rock music for another. Which one of the following groups would serve best as a control for this study?
(A) A third group for which no music is played
(B) A third group that randomly hears either classical or light rock music each day
(C) A third group that hears day-long R & B music
(D) A third group that hears classical music every morning and light rock every afternoon
(E) A third group in which each worker has earphones and chooses his or her own favorite music
19. Suppose H0: p = 0.6, and the power of the test for Ha: p = 0.7 is 0.8. Which of the following is a valid conclusion?
(A) The probability of committing a Type I error is 0.1.
(B) If Ha is true, the probability of failing to reject H0 is 0.2.
(C) The probability of committing a Type II error is 0.3.
(D) All of the above are valid conclusions.
(E) None of the above are valid conclusions.
20. Following is a histogram of the numbers of ties owned by bank executives.
Which of the following is a correct statement?
(A) The median number of ties is five.
(B) More than four executives own over eight ties each.
(C) An executive is equally likely to own fewer than five ties or more than seven ties.
(D) One tie is a reasonable estimate for the standard deviation.
(E) Removing all the executives with three, nine, and ten ties may change the median.
21. Which of the following is a binomial random variable?
(A) The number of tosses before a “5” appears when tossing a fair die.
(B) The number of points a hockey team receives in 10 games, where two points are awarded for wins, one point for ties, and no points for losses.
(C) The number of hearts out of five cards randomly drawn from a deck of 52 cards, without replacement.
(D) The number of motorists not wearing seat belts in a random sample of five drivers.
(E) None of the above.
22. Company I manufactures bomb fuses that burn an average of 50 minutes with a standard deviation of 10 minutes, while company II advertises fuses that burn an average of 55 minutes with a standard deviation of 5 minutes. Which company’s fuse is more likely to last at least 1 hour? Assume normal distributions of fuse times.
(A) Company I’s, because of its greater standard deviation
(B) Company II’s, because of its greater mean
(C) For both companies, the probability that a fuse will last at least 1 hour is 15.9%
(D) For both companies, the probability that a fuse will last at least 1 hour is 84.1%
(E) The problem cannot be solved from the information given.
23. Which of the following is not important in the design of experiments?
(A) Control of confounding variables
(B) Randomization in assigning subjects to different treatments
(C) Use of a lurking variable to control the placebo effect
(D) Replication of the experiment using sufficient numbers of subjects
(E) All of the above are important in the design of experiments.
24. The travel miles claimed in weekly expense reports of the sales personnel at a corporation are summarized in the following boxplot.
Which of the following is the most reasonable conclusion?
(A) The mean and median numbers of travel miles are roughly equal.
(B) The mean number of travel miles is greater than the median number.
(C) Most of the claimed numbers of travel miles are in the [0, 200] interval.
(D) Most of the claimed numbers of travel miles are in the [200, 240] interval.
(E) The left and right whiskers contain the same number of values from the set of personnel travel mile claims.
25. Which of the following statements about residuals is true?
(A) Influential scores have large residuals.
(B) If the linear model is good, the number of positive residuals will be the same as the number of negative residuals.
(C) The mean of the residuals is always zero.
(D) If the correlation is 0, there will be a distinct pattern in the residual plot.
(E) If the correlation is 1, there will not be a distinct pattern in the residual plot.
26. Four pairs of data are used in determining a regression line $\widehat{y}$ = 3x + 4. If the four values of the independent variable are 32, 24, 29, and 27, respectively, what is the mean of the four values of the dependent variable?
(A) 68
(B) 84
(C) 88
(D) 100
(E) The mean cannot be determined from the given information.
27. According to one poll, 12% of the public favor legalizing all drugs. In a simple random sample of six people, what is the probability that at least one person favors legalization?
(A) 6(0.12)(0.88)5
(B) (0.88)6
(C) 1 – (0.88)6
(D) 1 – 6(0.12)(0.88)5
(E) 6(0.12)(0.88)5 + (0.88)6
28. Sampling error occurs
(A) when interviewers make mistakes resulting in bias.
(B) because a sample statistic is used to estimate a population parameter.
(C) when interviewers use judgment instead of random choice in picking the sample.
(D) when samples are too small.
(E) in all of the above cases.
29. A telephone executive instructs an associate to contact 104 customers using their service to obtain their opinions in regard to an idea for a new pricing package. The associate notes the number of customers whose names begin with A and uses a random number table to pick four of these names. She then proceeds to use the same procedure for each letter of the alphabet and combines the 4 × 26 = 104 results into a group to be contacted. Which of the following is a correct conclusion?
(A) Her procedure makes use of chance.
(B) Her procedure results in a simple random sample.
(C) Each customer has an equal probability of being included in the survey.
(D) Her procedure introduces bias through sampling error.
(E) With this small a sample size, it is better to let the surveyor pick representative customers to be surveyed based on as many features such as gender, political preference, income level, race, age, and so on, as are in the company’s data banks.
30. The graph below shows cumulative proportions plotted against GPAs for high school seniors.
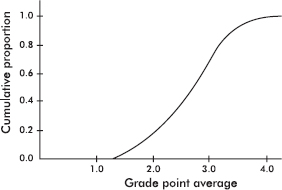
What is the approximate interquartile range?
(A) 0.85
(B) 2.25
(C) 2.7
(D) 2.75
(E) 3.1
31. PCB contamination of a river by a manufacturer is being measured by amounts of the pollutant found in fish. A company scientist claims that the fish contain only 5 parts per million, but an investigator believes the figure is higher. The investigator catches six fish that show the following amounts of PCB (in parts per million): 6.8, 5.6, 5.2, 4.7, 6.3, and 5.4. In performing a hypothesis test with H0: µ = 5 and Ha: µ > 5, what is the test statistic?
32. The distribution of weights of 16-ounce bags of a particular brand of potato chips is approximately normal with a standard deviation of 0.28 ounce. How does the weight of a bag at the 40th percentile compare with the mean weight?
(A) 0.40 ounce above the mean
(B) 0.25 ounce above the mean
(C) 0.07 ounce above the mean
(D) 0.07 ounce below the mean
(E) 0.25 ounce below the mean
33. In general, how does tripling the sample size change the confidence interval size?
(A) It triples the interval size.
(B) It divides the interval size by 3.
(C) It multiples the interval size by 1.732.
(D) It divides the interval size by 1.732.
(E) This question cannot be answered without knowing the sample size.
34. Which of the following statements is false?
(A) Like the normal distribution, the t-distributions are symmetric.
(B) The t-distributions are lower at the mean and higher at the tails, and so are more spread out than the normal distribution.
(C) The greater the df, the closer the t-distributions are to the normal distribution.
(D) The smaller the df, the better the 68–95–99.7 Rule works for t-models.
(E) The area under all t-distribution curves is 1.
35. A study on school budget approval among people with different party affiliations resulted in the following segmented bar chart:
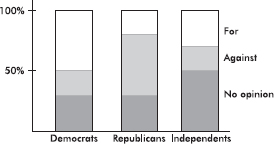
Which of the following is greatest?
(A) Number of Democrats who are for the proposed budget
(B) Number of Republicans who are against the budget
(C) Number of Independents who have no opinion on the budget
(D) The above are all equal.
(E) The answer is impossible to determine without additional information.
36. The sampling distribution of the sample mean is close to the normal distribution
(A) only if both the original population has a normal distribution and n is large.
(B) if the standard deviation of the original population is known.
(C) if n is large, no matter what the distribution of the original population.
(D) no matter what the value of n or what the distribution of the original population.
(E) only if the original population is not badly skewed and does not have outliers.
37. What is the probability of a Type II error when a hypothesis test is being conducted at the 10% significance level (α = 0.10)?
(A) 0.05
(B) 0.10
(C) 0.90
(D) 0.95
(E) There is insufficient information to answer this question.
38.

Above is the dotplot for a set of numbers. One element is labeled X. Which of the following is a correct statement?
(A) X has the largest z-score, in absolute value, of any element in the set.
(B) A modified boxplot will plot an outlier like X as an isolated point.
(C) A stemplot will show X isolated from two clusters.
(D) Because of X, the mean and median are different.
(E) The IQR is exactly half the range.
39. A 2008 survey of 500 households concluded that 82% of the population uses grocery coupons. Which of the following best describes what is meant by the poll having a margin of error of 3%?
(A) Three percent of those surveyed refused to participate in the poll.
(B) It would not be unexpected for 3% of the population to begin using coupons or stop using coupons.
(C) Between 395 and 425 of the 500 households surveyed responded that they used grocery coupons.
(D) If a similar survey of 500 households were taken weekly, a 3% change in each week’s results would not be unexpected.
(E) It is likely that between 79% and 85% of the population use grocery coupons.
40.
The above two-way table summarizes the results of a survey of high school seniors conducted to determine if there is a relationship between whether or not a student is taking AP Statistics and whether he or she plans to attend a public or a private college after graduation. Which of the following is the most reasonable conclusion about the relationship between taking AP Statistics and the type of college a student plans to attend?
(A) There appears to be no association since the proportion of AP Statistics students planning to attend public schools is almost identical to the proportion of students not taking AP Statistics who plan to attend public schools.
(B) There appears to be an association since the proportion of AP Statistics students planning to attend public schools is almost identical to the proportion of students not taking AP Statistics who plan to attend public schools.
(C) There appears to be an association since more students plan to attend private than public schools.
(D) There appears to be an association since fewer students are taking AP Statistics than are not taking AP Statistics.
(E) These data do not address the question of association.
If there is still time remaining, you may review your answers.
SECTION II
Part A
QUESTIONS 1–5
Spend about 65 minutes on this part of the exam.
Percentage of Section II grade—75
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your results and explanations.
1. Ten volunteer male subjects are to be used for an experiment to study four drugs (aloe, camphor, eucalyptus oil, and benzocaine) and a placebo with regard to itching relief. Itching is induced on a forearm with an itch stimulus (cowage), a drug is topically administered, and the duration of itching is recorded.
(a) If the experiment is to be done in one sitting, how would you assign treatments for a completely randomized design?
(b) If 5 days are set aside for the experiment, with one sitting a day, how would you assign treatments for a randomized block design where the subjects are the blocks?
(c) What limits are there on generalization of any results?
2. A comprehensive study of more than 3,000 baseball games results in the graph below showing relative frequencies of runs scored by home teams.
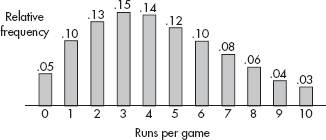
(a) Calculate the mean and the median.
(b) Between the mean and the median, is the one that is greater what was to be expected? Explain.
(c) What is the probability that in 4 randomly selected games, the home team is shut out (scores no runs) in at least one of the games?
(d) If X is the random variable for the runs scored per game by home teams, its standard deviation is 2.578. Suppose 200 games are selected at random, and x, the mean number of runs scored by the home teams, is calculated. Describe the sampling distribution of x.
3. A study is performed to explore the relationship, if any, between 24-hour urinary metabolite 3-methoxy-4-hydroxyphenylglycol (MHPG) levels and depression in bipolar patients. The MHPG level is measured in micrograms per 24 hours while the manic-depression (MD) scale used goes from 0 (manic delirium), through 5 (euthymic), up to 10 (depressive stupor). A partial computer printout of regression analysis with MHPG as the independent variable follows:
Average MHPG = 1243.1 with SD = 384.9
Average MD = 5.4 with SD = 2.875
95% confidence interval for slope b1 = (–0.0096, –0.0016)
(a) Calculate the slope of the regression line and interpret it in the context of this problem.
(b) Find the equation of the regression line.
(c) Calculate and interpret the value of r2 in the context of this problem.
(d) What does the correlation say about causation in the context of this problem.
4. An experiment is run to test whether daily stimulation of specific reflexes in young infants will lead to earlier walking. Twenty infants were recruited through a pediatrician’s service, and were randomly split into two groups of ten. One group received the daily stimulation while the other was considered a control group. The ages (in months) at which the infants first walked alone were recorded.
Is there statistical evidence that infants walk earlier with daily stimulation of specific reflexes?
5. A city sponsors two charity runs during the year, one 5 miles and the other 10 kilometers. Both runs attract many thousands of participants. A statistician is interested in comparing the types of runners attracted to each race. She obtains a random sample of 100 runners from each race, calculates five-number summaries of the times, and displays the results in the parallel boxplots below.
(a) Compare the distributions of times above.
The statistician notes that 5 miles equals 8 kilometers and so decides to multiply the times from the 5-mile event by 10/8 and then compare box plots. This display is below.
(b) How do the distributions now compare?
(c) Given that the 10-kilometer race was a longer distance than the 5-mile race, was the change from the first set of boxplots to the second set as expected? Explain.
(d) Based on the boxplots, would you expect the difference in mean times in the first set of parallel boxplots to be less than, greater than, or about the same as the difference in mean times in the second set of parallel boxplots? Explain.
SECTION II
Part B
QUESTION 6
Spend about 25 minutes on this part of the exam.
Percentage of Section II grade—25
6. A random sample of 250 SAT mathematics scores tabulates as follows:

(a) Find a 95% confidence interval for the proportion of scores over 500.
(b) Test the null hypothesis that the data follow a normal distribution with µ = 500 and $\sigma$ = 100.
(c) Assume the above data comes from a normally distributed population with unknown µ and $\sigma$. In this case, the sampling distribution of ![]() follows a chi-square distribution. If computer output of the above data yields n = 250, $\overline{x}$ = 504.8, and s = 114.4, and if in this problem the $\chi$2-values for tails of 0.025 and 0.975 are 294.6 and 207.2, respectively, find a 95% confidence interval for the standard deviation $\sigma$.
follows a chi-square distribution. If computer output of the above data yields n = 250, $\overline{x}$ = 504.8, and s = 114.4, and if in this problem the $\chi$2-values for tails of 0.025 and 0.975 are 294.6 and 207.2, respectively, find a 95% confidence interval for the standard deviation $\sigma$.
If there is still time remaining, you may review your answers.
SECTION I
Questions 1–40
Spend 90 minutes on this part of the exam.
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. Which of the following is a true statement?
(A) While properly designed experiments can strongly suggest cause-and-effect relationships, a complete census is the only way of establishing such a relationship.
(B) If properly designed, observational studies can establish cause-and-effect relationships just as strongly as properly designed experiments.
(C) Controlled experiments are often undertaken later to establish cause-and-effect relationships first suggested by observational studies.
(D) A useful approach to overcome bias in observational studies is to increase the sample size.
(E) In an experiment, the control group is a self-selected group who choose not to receive a designated treatment.
2. Two classes take the same exam. Suppose a certain score is at the 40th percentile for the first class and at the 80th percentile for the second class. Which of the following is the most reasonable conclusion?
(A) Students in the first class generally scored higher than students in the second class.
(B) Students in the second class generally scored higher than students in the first class.
(C) A score at the 20th percentile for the first class is at the 40th percentile for the second class.
(D) A score at the 50th percentile for the first class is at the 90th percentile for the second class.
(E) One of the classes has twice the number of students as the other.
3. In an experiment, the control group should receive
(A) treatment opposite that given the experimental group.
(B) the same treatment given the experimental group without knowing they are receiving the treatment.
(C) a procedure identical to that given the experimental group except for receiving the treatment under examination.
(D) a procedure identical to that given the experimental group except for a random decision on receiving the treatment under examination.
(E) none of the procedures given the experimental group.
4. In a random sample of Toyota car owners, 83 out of 112 said they were satisfied with the Toyota front-wheel drive, while in a similar survey of Subaru owners, 76 out of 81 said they were satisfied with the Subaru four-wheel drive. A 90% confidence interval estimate for the difference in proportions between Toyota and Subaru car owners who are satisfied with their drive systems is reported to be –0.197 ± 0.081. Which is a proper conclusion?
(A) The interval is invalid because probabilities cannot be negative.
(B) The interval is invalid because it does not contain zero.
(C) Subaru owners are approximately 19.7% more satisfied with their drive systems than are Toyota owners.
(D) 90% of Subaru owners are approximately 19.7% more satisfied with their drive systems than are Toyota owners.
(E) We are 90% confident that the difference in proportions between Toyota and Subaru car owners who are satisfied with their drive systems is between –0.278 and –0.116.
5. In a study on the effect of music on worker productivity, employees were told that a different genre of background music would be played each day and the corresponding production outputs noted. Every change in music resulted in an increase in production. This is an example of
(A) the effect of a treatment unit.
(B) the placebo effect.
(C) the control group effect.
(D) sampling error.
(E) voluntary response bias.
6. A computer manufacturer sets up three locations to provide technical support for its customers. Logs are kept noting whether or not calls about problems are solved successfully. Data from a sample of 1000 calls are summarized in the following table:
Assuming there is no association between location and whether or not a problem is resolved successfully, what is the expected number of successful calls (problem solved) from location 1?

7. Which of the following statements about the correlation coefficient is true?
(A) The correlation coefficient and the slope of the regression line may have opposite signs.
(B) A correlation of 1 indicates a perfect cause-and-effect relationship between the variables.
(C) Correlations of +0.87 and –0.87 indicate the same degree of clustering around the regression line.
(D) Correlation applies equally well to quantitative and categorical data.
(E) A correlation of 0 shows little or no association between two variables.
8. Suppose X and Y are random variables with E(X) = 780, var(X) = 75, E(Y) = 430, and var(Y) = 25. Given that X and Y are independent, what is the variance of the random variable X – Y?

9. What is a sample?
(A) A measurable characteristic of a population
(B) A set of individuals having a characteristic in common
(C) A value calculated from raw data
(D) A subset of a population
(E) None of the above
10. A histogram of the cholesterol levels of all employees at a large law firm is as follows:
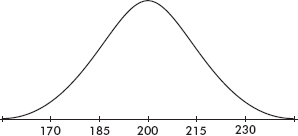
Which of the following is the best estimate of the standard deviation of this distribution?

11. A soft drink dispenser can be adjusted to deliver any fixed number of ounces. If the machine is operating with a standard deviation in delivery equal to 0.3 ounce, what should be the mean setting so that a 12-ounce cup will overflow less than 1% of the time? Assume a normal distribution for ounces delivered.
(A) 11.23 ounces
(B) 11.30 ounces
(C) 11.70 ounces
(D) 12.70 ounces
(E) 12.77 ounces
12. An insurance company wishes to study the number of years drivers in a large city go between automobile accidents. They plan to obtain and analyze the data from a sample of drivers. Which of the following is a true statement?
(A) A reasonable time-and-cost-saving procedure would be to use systematic sampling on an available list of all AAA (Automobile Association of America) members in the city.
(B) A reasonable time-and-cost-saving procedure would be to randomly choose families and include all drivers in each of these families in the sample.
(C) To determine the mean number of years between accidents, randomness in choosing a sample of drivers is not important as long as the sample size is very large.
(D) The larger a simple random sample, the more likely its standard deviation will be close to the population standard deviation divided by the square root of the sample size.
(E) None of the above are true statements.
13. The probability that a person will show a certain gene-transmitted trait is 0.8 if the father shows the trait and 0.06 if the father doesn’t show the trait. Suppose that the children in a certain community come from families in 25% of which the father shows the trait. Given that a child shows the trait, what is the probability that her father shows the trait?
(A) 0.245
(B) 0.250
(C) 0.750
(D) 0.816
(E) 0.860
14. Given an experiment with H0 : µ = 10, Ha : µ > 10, and a possible correct value of 11, which of the following increases as n increases?
I. The probability of a Type I error.
II. The probability of a Type II error.
III. The power of the test.
(A) I only
(B) II only
(C) III only
(D) II and III
(E) None will increase.
15. If all the values of a data set are the same, all of the following must equal zero except for which one?
(A) Mean
(B) Standard deviation
(C) Variance
(D) Range
(E) Interquartile range
16. To determine the average number of minutes it takes to manufacture one unit of a new product, an assembly line manager tracks a random sample of 15 units and records the number of minutes it takes to make each unit. The assembly times are assumed to have a normal distribution. If the mean and standard deviation of the sample are 3.92 and 0.45 minutes respectively, which of the following gives a 90% confidence interval for the mean assembly time, in minutes, for units of the new product?

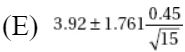
17. A company has 1000 employees evenly distributed throughout five assembly plants. A sample of 30 employees is to be chosen as follows. Each of the five managers will be asked to place the 200 time cards of their respective employees in a bag, shake them up, and randomly draw out six names. The six names from each plant will be put together to make up the sample. Will this method result in a simple random sample of the 1000 employees?
(A) Yes, because every employee has the same chance of being selected.
(B) Yes, because every plant is equally represented.
(C) Yes, because this is an example of stratified sampling, which is a special case of simple random sampling.
(D) No, because the plants are not chosen randomly.
(E) No, because not every group of 30 employees has the same chance of being selected.
18. Given that P(E) = 0.32, P(F) = 0.15, and P(E $\cap$ F) = 0.048, which of the following is a correct conclusion?
(A) The events E and F are both independent and mutually exclusive.
(B) The events E and F are neither independent nor mutually exclusive.
(C) The events E and F are mutually exclusive but not independent.
(D) The events E and F are independent but not mutually exclusive.
(E) The events E and F are independent, but there is insufficient information to determine whether or not they are mutually exclusive.
19. The number of leasable square feet of office space available in a city on any given day has a normal distribution with mean 640,000 square feet and standard deviation 18,000 square feet. What is the interquartile range for this distribution?
(A) 652,000 – 628,000
(B) 658,000 – 622,000
(C) 667,000 – 613,000
(D) 676,000 – 604,000
(E) 694,000 – 586,000
20. Consider the following back-to-back stemplot:

Which of the following is a correct statement?
(A) The distributions have the same mean.
(B) The distributions have the same median.
(C) The interquartile range of the distribution to the left is 20 greater than the interquartile range of the distribution to the right.
(D) The distributions have the same variance.
(E) None of the above is correct.
21. Which of the following is a correct statement?
(A) A study results in a 99% confidence interval estimate of (34.2, 67.3). This means that in about 99% of all samples selected by this method, the sample means will fall between 34.2 and 67.3.
(B) A high confidence level may be obtained no matter what the sample size.
(C) The central limit theorem is most useful when drawing samples from normally distributed populations.
(D) The sampling distribution for a mean has standard deviation $\frac{\sigma}{\sqrt{n}}$ only when n is sufficiently large (typically one uses n $\geq$ 30).
(E) The center of any confidence interval is the population parameter.
22. The binomial distribution is an appropriate model for which of the following?
(A) The number of minutes in an hour for which the Dow-Jones average is above its beginning average for the day.
(B) The number of cities among the 10 largest in New York State for which the weather is cloudy for most of a given day.
(C) The number of drivers wearing seat belts if 10 consecutive drivers are stopped at a police roadblock.
(D) The number of A’s a student receives in his/her five college classes.
(E) None of the above.
23. Suppose two events, E and F, have nonzero probabilities p and q, respectively. Which of the following is impossible?
(A) p + q > 1
(B) p – q < 0
(C) p/q > 1
(D) E and F are neither independent nor mutually exclusive.
(E) E and F are both independent and mutually exclusive.
24. An inspection procedure at a manufacturing plant involves picking four items at random and accepting the whole lot if at least three of the four items are in perfect condition. If in reality 90% of the whole lot are perfect, what is the probability that the lot will be accepted?
(A) (0.9)4
(B) 1 – (0.9)4
(C) 4(0.9)3(0.1)
(D) 0.1 – 4(0.9)3(0.1)
(E) 4(0.9)3(0.1) + (0.9)4
25. A town has one high school, which buses students from urban, suburban, and rural communities. Which of the following samples is recommended in studying attitudes toward tracking of students in honors, regular, and below-grade classes?
(A) Convenience sample
(B) Simple random sample (SRS)
(C) Stratified sample
(D) Systematic sample
(E) Voluntary response sample
26. Suppose there is a correlation of r = 0.9 between number of hours per day students study and GPAs. Which of the following is a reasonable conclusion?
(A) 90% of students who study receive high grades.
(B) 90% of students who receive high grades study a lot.
(C) 90% of the variation in GPAs can be explained by variation in number of study hours per day.
(D) 10% of the variation in GPAs cannot be explained by variation in number of study hours per day.
(E) 81% of the variation in GPAs can be explained by variation in number of study hours per day.
27. To determine the average number of children living in single-family homes, a researcher picks a simple random sample of 50 such homes. However, even after one follow-up visit the interviewer is unable to make contact with anyone in 8 of these homes. Concerned about nonresponse bias, the researcher picks another simple random sample and instructs the interviewer to keep trying until contact is made with someone in a total of 50 homes. The average number of children is determined to be 1.73. Is this estimate probably too low or too high?
(A) Too low, because of undercoverage bias.
(B) Too low, because convenience samples overestimate average results.
(C) Too high, because of undercoverage bias.
(D) Too high, because convenience samples overestimate average results.
(E) Too high, because voluntary response samples overestimate average results.
28. The graph below shows cumulative proportions plotted against land values (in dollars per acre) for farms on sale in a rural community.
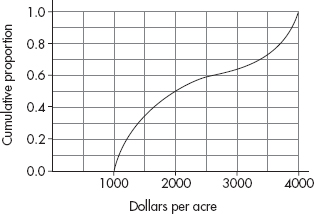
What is the median land value?
(A) $2000
(B) $2250
(C) $2500
(D) $2750
(E) $3000
29. An experiment is to be conducted to determine whether taking fish oil capsules or garlic capsules has more of an effect on cholesterol levels. In past studies it was noted that daily exercise intensity (low, moderate, high) is associated with cholesterol level, but average sleep length (< 5, 5 – 8, > 8 hours) is not associated with cholesterol level. This experiment should be done
(A) by blocking on exercise intensity
(B) by blocking on sleep length
(C) by blocking on cholesterol level
(D) by blocking on capsule type
(E) without blocking
30. A confidence interval estimate is determined from the monthly grocery expenditures in a random sample of n families. Which of the following will result in a smaller margin of error?
I. A smaller confidence level
II. A smaller sample standard deviation
III. A smaller sample size
(A) II only
(B) I and II
(C) I and III
(D) II and III
(E) I, II, and III
31. A medical research team claims that high vitamin C intake increases endurance. In particular, 1000 milligrams of vitamin C per day for a month should add an average of 4.3 minutes to the length of maximum physical effort that can be tolerated. Army training officers believe the claim is exaggerated and plan a test on an SRS of 400 soldiers in which they will reject the medical team’s claim if the sample mean is less than 4.0 minutes. Suppose the standard deviation of added minutes is 3.2. If the true mean increase is only 4.2 minutes, what is the probability that the officers will fail to reject the false claim of 4.3 minutes?
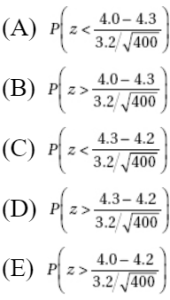
32. Consider the two sets X = {10, 30, 45, 50, 55, 70, 90} and Y = {10, 30, 35, 50, 65, 70, 90}. Which of the following is false?
(A) The sets have identical medians.
(B) The sets have identical means.
(C) The sets have identical ranges.
(D) The sets have identical boxplots.
(E) None of the above are false.
33. The weight of an aspirin tablet is 300 milligrams according to the bottle label. An FDA investigator weighs a simple random sample of seven tablets, obtains weights of 299, 300, 305, 302, 299, 301, and 303, and runs a hypothesis test of the manufacturer’s claim. Which of the following gives the P-value of this test?
(A) P(t > 1.54) with df = 6
(B) 2P(t > 1.54) with df = 6
(C) P(t > 1.54) with df = 7
(D) 2P(t > 1.54) with df = 7
(E) 0.5P(t > 1.54) with df = 7
34. A teacher believes that giving her students a practice quiz every week will motivate them to study harder, leading to a greater overall understanding of the course material. She tries this technique for a year, and everyone in the class achieves a grade of at least C. Is this an experiment or an observational study?
(A) An experiment, but with no reasonable conclusion possible about cause and effect
(B) An experiment, thus making cause and effect a reasonable conclusion
(C) An observational study, because there was no use of a control group
(D) An observational study, but a poorly designed one because randomization was not used
(E) An observational study, and thus a reasonable conclusion of association but not of cause and effect
35. Which of the following is not true with regard to contingency tables for chi-square tests for independence?
(A) The categories are not numerical for either variable.
(B) Observed frequencies should be whole numbers.
(C) Expected frequencies should be whole numbers.
(D) Expected frequencies in each cell should be at least 5, and to achieve this, one sometimes combines categories for one or the other or both of the variables.
(E) The expected frequency for any cell can be found by multiplying the row total by the column total and dividing by the sample size.
36. Which of the following is a correct statement?
(A) The probability of a Type II error does not depend on the probability of a Type I error.
(B) In conducting a hypothesis test, it is possible to simultaneously make both a Type I and a Type II error.
(C) A Type II error will result if one incorrectly assumes the data are normally distributed.
(D) In medical disease testing with the null hypothesis that the patient is healthy, a Type I error is associated with a false negative; that is, the test incorrectly indicates that the patient is disease free.
(E) When you choose a significance level α, you’re setting the probability of a Type I error to exactly α.
37.
Above is a scatterplot with one point labeled X. Suppose you find the least squares regression line. Which of the following is a correct statement?
(A) X has the largest residual, in absolute value, of any point on the scatterplot.
(B) X is an influential point.
(C) The residual plot will show a curved pattern.
(D) The association between the x and y variables is very weak.
(E) If the point X were removed, the correlation would be 1.
38. A banking corporation advertises that 90% of the loan applications it receives are approved within 24 hours. In a random sample of 50 applications, what is the expected number of loan applications that will be turned down?

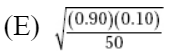
39. The parallel boxplots below show monthly rainfall summaries for Liberia, West Africa.
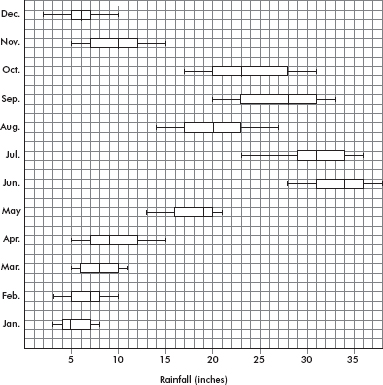
Which of the following months has the least variability as measured by interquartile range?
(A) January
(B) February
(C) March
(D) May
(E) December
40. In comparing the life expectancies of two models of refrigerators, the average years before complete breakdown of 10 model A refrigerators is compared with that of 15 model B refrigerators. The 90% confidence interval estimate of the difference is (6, 12). Which of the following is the most reasonable conclusion?
(A) The mean life expectancy of one model is twice that of the other.
(B) The mean life expectancy of one model is 6 years, while the mean life expectancy of the other is 12 years.
(C) The probability that the life expectancies are different is 0.90.
(D) The probability that the difference in life expectancies is greater than 6 years is 0.90.
(E) We should be 90% confident that the difference in life expectancies is between 6 and 12 years.
If there is still time remaining, you may review your answers.
SECTION II
Part A
QUESTIONS 1–5
Spend about 65 minutes on this part of the exam.
Percentage of Section II grade—75
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your results and explanations.
1. The Information Technology Services division at a university is considering installing a new spam filter software product on all campus computers to combat unwanted advertising and spyware. A sample of 60 campus computers was randomly divided into two groups of 30 computers each. One group of 30 was considered to be a control group, while each computer in the other group had the spam filter software installed. During a two-week period each computer user was instructed to keep track of the number of unwanted spam e-mails received. The back-to-back stemplot below shows the distribution of such e-mails received for the control and treatment groups.
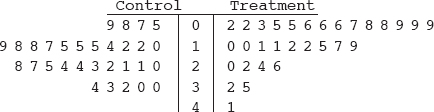
(a) Compare the distribution of spam e-mails from the control and treatment groups.
(b) The standard deviation of the numbers of e-mails in the control group is 8.1. How does this value summarize variability for the control group data?
(c) A researcher in Information Technology Services calculates a 95% confidence interval for the difference in mean number of spam e-mails received between the control group and the treatment group with the new software and obtains (1.5, 10.9). Assuming all conditions for a two-sample t-interval are met, comment on whether or not there is evidence of a difference in the means for the number of spam e-mails received during a two-week period by computers with and without the software.
(d) The computer users on campus fall into four groups: administrators, staff, faculty, and students. Explain why a researcher might decide to use blocking in setting up this experiment.
2. A game contestant flips three fair coins and receives a score equal to the absolute value of the difference between the number of heads and number of tails showing.
(a) Construct the probability distribution table for the possible scores in this game.
(b) Calculate the expected value of the score for a player.
(c) What is the probability that if a player plays this game three times the total score will be 3?
(d) Suppose a player wins a major prize if he or she can average a score of at least 2. Given the choice, should he or she try for this average by playing 10 times or by playing 15 times? Explain.
3. A high school has a room set aside after school for students to play games. The attendance data are summarized in the following table.
![]()
A student plugs these data into his calculator and comes up with:
![]()
(a) Interpret the slope of the regression line in context. Does this seem to adequately explain the data? Why or why not?
Another student points out that during the first 4 weeks the school allowed computer games, but then the policy changed.
(b) Give a more appropriate regression analysis modeling attendance in terms of week. Include correlation and interpretation of slope in your analysis.
(c) Explain the above results in terms of a scatterplot.
4. State investigators believe that a particular auto repair facility is fraudulently charging customers for repairs they don’t need. As part of their investigation they pick a random sample of ten damaged cars, do their own cost estimate for repair work, and then send the cars to the facility under suspicion for an estimate. The data obtained are shown in the table below.

Is the mean estimate of the facility under suspicion significantly greater than the mean estimate by the investigators? Justify your answer.
5. Five new estimators are being evaluated with regard to quality control in manufacturing professional baseballs of a given weight. Each estimator is tested every day for a month on samples of sizes n = 10, n = 20, and n = 40. The baseballs actually produced that month had a consistent mean weight of 146 grams. The distributions given by each estimator are as follows:
(a) Which of the above appear to be unbiased estimators of the population parameter? Explain.
(b) Which of the above exhibits the lowest variability for n = 40? Explain.
(c) Which of the above is the best estimator if the selected estimator will eventually be used with a sample of size n = 100? Explain.
SECTION II
Part B
QUESTION 6
Spend about 25 minutes on this part of the exam.
Percentage of Section II grade—25
6. Dose intensity in chemotherapy is a balance between minimizing adverse side effects and maximizing therapeutic effect of the treatment. A study is performed on a random sample of 800 patients with stage 4 colon cancer to determine the relationship between nausea (a side effect of most types of chemotherapy) and dosage of an experimental chemotherapy agent. Each patient is randomly placed in one of eight groups, each group receiving a different dose intensity, and the numbers of patients experiencing severe nausea are noted. The table below summarizes the data collected.
Dose intensity (mg/week) | Number of patients | Number experiencing severe nausea | Proportion experiencing severe nausea |
10 | 110 | 34 | 0.31 |
15 | 105 | 15 | 0.14 |
20 | 85 | 22 | 0.26 |
25 | 95 | 17 | 0.18 |
50 | 100 | 47 | 0.47 |
55 | 95 | 54 | 0.57 |
60 | 110 | 42 | 0.38 |
65 | 100 | 62 | 0.62 |
(a) A medical researcher notes that a total of 205 out of 405 patients given higher doses ($\geq$ 50 mg/week) experienced severe nausea, while only 88 of the 395 patients given lower doses (≤ 25 mg/week) experienced severe nausea. Do these data support that a greater proportion of patients receiving higher doses experience severe nausea than patients receiving lower doses?
(b) Another researcher thinks there is more of a relation between dose intensity and proportion experiencing severe nausea than one can see by simply looking at low and high doses. She runs a regression analysis with the following computer output.

Find a 95% confidence interval for the slope of the regression line, and interpret your answer in context.
(c) A researcher plans to interview five patients randomly chosen from among the 800 participants in this experiment. What is the probability that a majority of those chosen will have experienced severe nausea?
If there is still time remaining, you may review your answers.
SECTION I
Questions 1–40
Spend 90 minutes on this part of the exam.
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. A company wishes to determine the relationship between the number of days spent training employees and their performances on a job aptitude test. Collected data result in a least squares regression line, $\widehat{y}$ = 12.1 + 6.2x, where x is the number of training days and $\widehat{y}$ is the predicted score on the aptitude test. Which of the following statements best interprets the slope and y-intercept of the regression line?
(A) The base score on the test is 12.1, and for every day of training one would expect, on average, an increase of 6.2 on the aptitude test.
(B) The base score on the test is 6.2, and for every day of training one would expect, on average, an increase of 12.1 on the aptitude test.
(C) The mean number of training days is 12.1, and for every additional 6.2 days of training one would expect, on average, an increase of one unit on the aptitude test.
(D) The mean number of training days is 6.2, and for every additional 12.1 days of training one would expect, on average, an increase of one unit on the aptitude test.
(E) The mean number of training days is 12.1, and for every day of training one would expect, on average, an increase of 6.2 on the aptitude test.
2. To survey the opinions of the students at your high school, a researcher plans to select every twenty-fifth student entering the school in the morning. Assuming there are no absences, will this result in a simple random sample of students attending your school?
(A) Yes, because every student has the same chance of being selected.
(B) Yes, but only if there is a single entrance to the school.
(C) Yes, because the 24 out of every 25 students who are not selected will form a control group.
(D) Yes, because this is an example of systematic sampling, which is a special case of simple random sampling.
(E) No, because not every sample of the intended size has an equal chance of being selected.
3. Consider a hypothesis test with H0 : µ = 70 and Ha : µ < 70. Which of the following choices of significance level and sample size results in the greatest power of the test when µ = 65?
(A) α = 0.05, n = 15
(B) α = 0.01, n = 15
(C) α = 0.05, n = 30
(D) α = 0.01, n = 30
(E) There is no way of answering without knowing the strength of the given power.
4. Suppose that 60% of a particular electronic part last over 3 years, while 70% last less than 6 years. Assuming a normal distribution, what are the mean and standard deviation with regard to length of life of these parts?
(A) µ = 3.677, $\sigma$ = 3.561
(B) µ = 3.977, $\sigma$ = 3.861
(C) µ = 4.177, $\sigma$ = 3.561
(D) µ = 4.377, $\sigma$ = 3.261
(E) The mean and standard deviation cannot be computed from the information given.
5. The label on a package of cords claims that the breaking strength of a cord is 3.5 pounds, but a hardware store owner believes the real value is less. She plans to test 36 such cords; if their mean breaking strength is less than 3.25 pounds, she will reject the claim on the label. If the standard deviation for the breaking strengths of all such cords is 0.9 pounds, what is the probability of mistakenly rejecting a true claim?
(A) 0.05
(B) 0.10
(C) 0.15
(D) 0.45
(E) 0.94
6. The graph below shows cumulative proportions plotted against numbers of employees working in mid-sized retail establishments.
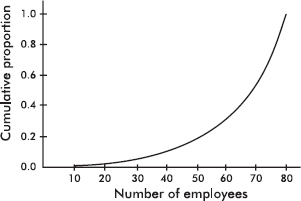
What is the approximate interquartile range?
(A) 18
(B) 35
(C) 57
(D) 68
(E) 75
7. What is a placebo?
(A) A method of selection
(B) An experimental treatment
(C) A control treatment
(D) A parameter
(E) A statistic
8. To study the effect of alcohol on reaction time, subjects were randomly selected and given three beers to consume. Their reaction time to a simple stimulus was measured before and after drinking the alcohol. Which of the following is a correct statement?
(A) This study was an observational study.
(B) Lack of blocking makes this a poorly designed study.
(C) The placebo effect is irrelevant in this type of study.
(D) This study was an experiment with no controls.
(E) This study was an experiment in which the subjects were used as their own controls.
9. Suppose that the regression line for a set of data, y = 7x + b, passes through the point (–2, 4). If $\overline{x}$ and $\overline{y}$ are the sample means of the x– and y-values, respectively, then y =
(A) $\overline{x}$
(B) $\overline{x}$ + 2
(C) $\overline{x}$ – 4
(D) 7$\overline{x}$
(E) 7$\overline{x}$ + 18
10. Which of the following is a false statement about simple random samples?
(A) A sample must be reasonably large to be properly considered a simple random sample.
(B) Inspection of a sample will give no indication of whether or not it is a simple random sample.
(C) Attributes of a simple random sample may be very different from attributes of the population.
(D) Every element of the population has an equal chance of being picked.
(E) Every sample of the desired size has an equal chance of being picked.
11. A local school has seven math teachers and seven English teachers. When comparing their mean salaries, which of the following is most appropriate?
(A) A two-sample z-test of population means.
(B) A two-sample t-test of population means.
(C) A one-sample z-test on a set of differences.
(D) A one-sample t-test on a set of differences.
(E) None of the above are appropriate.
12. Following is a histogram of ages of people applying for a particular high school teaching position.
Which of the following is a correct statement?
(A) The median age is between 24 and 25.
(B) The mean age is between 22 and 23.
(C) The mean age is greater than the median age.
(D) More applicants are under 23 years of age than are over 23.
(E) There are a total of 10 applicants.
13. To conduct a survey of which long distance carriers are used in a particular locality, a researcher opens a telephone book to a random page, closes his eyes, puts his finger down on the page, and then calls the next 75 names. Which of the following is a correct statement?
(A) The procedure results in a simple random sample.
(B) While the survey design does incorporate chance, the procedure could easily result in selection bias.
(C) This is an example of cluster sampling with 26 clusters.
(D) This is an example of stratified sampling with 26 strata.
(E) Given that the researcher truly keeps his eyes closed, this is a good example of blinding.
14. Which of the following is not true about t-distributions?
(A) There are different t-distributions for different values of df (degrees of freedom).
(B) t-distributions are bell-shaped and symmetric.
(C) t-distributions always have mean 0 and standard deviation 1.
(D) t-distributions are more spread out than the normal distribution.
(E) The larger the df value, the closer the distribution is to the normal distribution.
15. Suppose the probability that a person picked at random has lung cancer is 0.035 and the probability that the person both has lung cancer and is a heavy smoker is 0.014. Given that someone picked at random has lung cancer, what is the probability that the person is a heavy smoker?
16. Taxicabs in a metropolitan area are driven an average of 75,000 miles per year with a standard deviation of 12,000 miles. What is the probability that a randomly selected cab has been driven less than 100,000 miles if it is known that it has been driven over 80,000 miles? Assume a normal distribution of miles per year among cabs.
(A) 0.06
(B) 0.34
(C) 0.66
(D) 0.68
(E) 0.94
17. A plant manager wishes to determine the difference in number of accidents per day between two departments. How many days’ records should be examined to be 90% certain of the difference in daily averages to within 0.25 accidents per day? Assume standard deviations of 0.8 and 0.5 accidents per day in the two departments, respectively.
(A) 39
(B) 55
(C) 78
(D) 109
(E) 155
18. Suppose the correlation between two variables is r = 0.19. What is the new correlation if 0.23 is added to all values of the x-variable, every value of the y-variable is doubled, and the two variables are interchanged?
(A) 0.19
(B) 0.42
(C) 0.84
(D) –0.19
(E) –0.84
19. Two commercial flights per day are made from a small county airport. The airport manager tabulates the number of on-time departures for a sample of 200 days.
Number of on-time departures | 0 | 1 | 2 |
Observed number of days | 10 | 80 | 110 |
What is the $\chi$2 statistic for a goodness-of-fit test that the distribution is binomial with probability equal to 0.8 that a flight leaves on time?

20. A company has a choice of three investment schemes. Option I gives a sure $25,000 return on investment. Option II gives a 50% chance of returning \$50,000 and a 50% chance of returning \$10,000. Option III gives a 5% chance of returning \$100,000 and a 95% chance of returning nothing. Which option should the company choose?
(A) Option II if it wants to maximize expected return
(B) Option I if it needs at least $20,000 to pay off an overdue loan
(C) Option III if it needs at least $80,000 to pay off an overdue loan
(D) All of the above answers are correct.
(E) Because of chance, it really doesn’t matter which option it chooses.
21. Suppose P(X) = 0.35 and P(Y) = 0.40. If P(X|Y) = 0.28, what is P(Y|X)?

![]()
22. To test whether extensive exercise lowers the resting heart rate, a study is performed by randomly selecting half of a group of volunteers to exercise 1 hour each morning, while the rest are instructed to perform no exercise. Is this study an experiment or an observational study?
(A) An experiment with a control group and blinding
(B) An experiment with blocking
(C) An observational study with comparison and randomization
(D) An observational study with little if any bias
(E) None of the above
23. The waiting times for a new roller coaster ride are normally distributed with a mean of 35 minutes and a standard deviation of 10 minutes. If there are 150,000 riders the first summer, which of the following is the shortest time interval associated with 100,000 riders?
(A) 0 to 31.7 minutes
(B) 31.7 to 39.3 minutes
(C) 25.3 to 44.7 minutes
(D) 25.3 to 35 minutes
(E) 39.3 to 95 minutes
24. A medical researcher, studying the effective durations of three over-the-counter pain relievers, obtains the following boxplots from three equal-sized groups of patients, one group using each of the pain relievers.
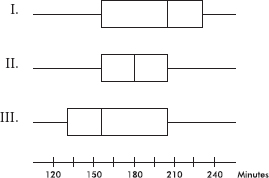
Which of the following is a correct statement with regard to comparing the effective durations in minutes of the three pain relievers?
(A) All three have the same interquartile range.
(B) More patients had over 210 minutes of pain relief in the (I) group than in either of the other two groups.
(C) More patients had over 240 minutes of pain relief in the (I) group than in either of the other two groups.
(D) More patients had less than 120 minutes of pain relief in the (III) group than in either of the other two groups.
(E) The durations of pain relief in the (II) group form a normal distribution.
25. For their first exam, students in an AP Statistics class studied an average of 4 hours with a standard deviation of 1 hour. Almost everyone did poorly on the exam, and so for the second exam every student studied 10 hours. What is the correlation between the numbers of hours students studied for each exam?
(A) –1
(B) 0
(C) 0.4
(D) 1
(E) There is not sufficient information to answer this question.
26. Suppose that 54% of the graduates from your high school go on to 4-year colleges, 20% go on to 2-year colleges, 19% find employment, and the remaining 7% search for a job. If a randomly selected student is not going on to a 2-year college, what is the probability she will be going on to a 4-year college?
(A) 0.460
(B) 0.540
(C) 0.630
(D) 0.675
(E) 0.730
27. We are interested in the proportion p of people who are unemployed in a large city. Eight percent of a simple random sample of 500 people are unemployed. What is the midpoint for a 95% confidence interval estimate of p?
(A) 0.012
(B) 0.025
(C) 0.475
(D) p
(E) None of the above.
28. Random samples of size n are drawn from a population. The mean of each sample is calculated, and the standard deviation of this set of sample means is found. Then the procedure is repeated, this time with samples of size 4n. How does the standard deviation of the second group compare with the standard deviation of the first group?
(A) It will be the same.
(B) It will be twice as large.
(C) It will be four times as large.
(D) It will be half as large.
(E) It will be one-quarter as large.
29. Leech therapy is used in traditional medicine for treating localized pain. In a double blind experiment on 50 patients with osteoarthritis of the knee, half are randomly selected to receive injections of leech saliva while the rest receive a placebo. Pain levels 7 days later among those receiving the saliva show a mean of 19.5, while pain levels among those receiving the placebo show a mean of 25.6 (higher numbers indicate more pain). Partial calculator output is shown below.

Which of the following is a correct conclusion?
(A) After 7 days, the mean pain level with the leech treatment is significantly lower than the mean pain level with the placebo at the 0.01 significance level.
(B) After 7 days, the mean pain level with the leech treatment is significantly lower than the mean pain level with the placebo at the 0.05 significance level, but not at the 0.01 level.
(C) After 7 days, the mean pain level with the leech treatment is significantly lower than the mean pain level with the placebo at the 0.10 significance level, but not at the 0.05 level.
(D) After 7 days, the mean pain level with the leech treatment is not significantly lower than the mean pain level with the placebo at the 0.10 significance level.
(E) The proper test should be a one-sample t-test on a set of differences.
30. A survey was conducted to determine the percentage of parents who would support raising the legal driving age to 18. The results were stated as 67% with a margin of error of ±3%. What is meant by ±3%?
(A) Three percent of the population were not surveyed.
(B) In the sample, the percentage of parents who would support raising the driving age is between 64% and 70%.
(C) The percentage of the entire population of parents who would support raising the driving age is between 64% and 70%.
(D) It is unlikely that the given sample proportion result could be obtained unless the true percentage was between 64% and 70%.
(E) Between 64% and 70% of the population were surveyed.
31. It is estimated that 30% of all cars parked in a metered lot outside City Hall receive tickets for meter violations. In a random sample of 5 cars parked in this lot, what is the probability that at least one receives a parking ticket?
(A) 1 – (0.3)5
(B) 1 – (0.7)5
(C) 5(0.3)(0.7)4
(D) 5(0.3)4 (0.7)
(E) 5(0.3)4(0.7) + 10(0.3)3(0.7)2 + 10(0.3)2(0.7)3 + 5(0.3)(0.7)4 + (0.7)5
32. Data are collected on income levels x versus number of bank accounts y. Summary calculations give x = 32,000; sx = 11,500; y = 1.7; sy = 0.4, and r = 0.42. What is the slope of the least squares regression line of number of bank accounts on income level?
(A) 0.000015
(B) 0.000022
(C) 0.000035
(D) 0.000053
(E) 0.000083
33. Given that the sample has a standard deviation of zero, which of the following is a true statement?
(A) The standard deviation of the population is also zero.
(B) The sample mean and sample median are equal.
(C) The sample may have outliers.
(D) The population has a symmetric distribution.
(E) All samples from the same population will also have a standard deviation of zero.
34. In one study half of a class were instructed to watch exactly 1 hour of television per day, the other half were told to watch 5 hours per day, and then their class grades were compared. In a second study students in a class responded to a questionnaire asking about their television usage and their class grades.
(A) The first study was an experiment without a control group, while the second was an observational study.
(B) The first study was an observational study, while the second was a controlled experiment.
(C) Both studies were controlled experiments.
(D) Both studies were observational studies.
(E) Each study was part controlled experiment and part observational study.
35. All of the following statements are true for all discrete random variables except for which one?
(A) The possible outcomes must all be numerical.
(B) The possible outcomes must be mutually exclusive.
(C) The mean (expected value) always equals the sum of the products obtained by multiplying each value by its corresponding probability.
(D) The standard deviation of a random variable can never be negative.
(E) Approximately 95% of the outcomes will be within two standard deviations of the mean.
36. In leaving for school on an overcast April morning you make a judgment on the null hypothesis: The weather will remain dry. What would the results be of Type I and Type II errors?
(A) Type I error: get drenched
Type II error: needlessly carry around an umbrella
(B) Type I error: needlessly carry around an umbrella
Type II error: get drenched
(C) Type I error: carry an umbrella, and it rains
Type II error: carry no umbrella, but weather remains dry
(D) Type I error: get drenched
Type II error: carry no umbrella, but weather remains dry
(E) Type I error: get drenched
Type II error: carry an umbrella, and it rains
37. The mean thrust of a certain model jet engine is 9500 pounds. Concerned that a production process change might have lowered the thrust, an inspector tests a sample of units, calculating a mean of 9350 pounds with a z-score of –2.46 and a P-value of 0.0069. Which of the following is the most reasonable conclusion?
(A) 99.31% of the engines produced under the new process will have a thrust under 9350 pounds.
(B) 99.31% of the engines produced under the new process will have a thrust under 9500 pounds.
(C) 0.69% of the time an engine produced under the new process will have a thrust over 9500 pounds.
(D) There is evidence to conclude that the new process is producing engines with a mean thrust under 9350 pounds.
(E) There is evidence to conclude that the new process is producing engines with a mean thrust under 9500 pounds.
38. In a group of 10 third graders, the mean height is 50 inches with a median of 47 inches, while in a group of 12 fourth graders, the mean height is 54 inches with a median of 49 inches. What is the median height of the combined group?

(E) The median of the combined group cannot be determined from the given information.
39. A reading specialist in a large public school system believes that the more time students spend reading, the better they will do in school. She plans a middle school experiment in which an SRS of 30 eighth graders will be assigned four extra hours of reading per week, an SRS of 30 seventh graders will be assigned two extra hours of reading per week, and an SRS of 30 sixth graders with no extra assigned reading will be a control group. After one school year, the mean GPAs from each group will be compared. Is this a good experimental design?
(A) Yes
(B) No, because while this design may point out an association between reading and GPA, it cannot establish a cause-and-effect relationship.
(C) No, because without blinding, there is a strong chance of a placebo effect.
(D) No, because any conclusion would be flawed because of blocking bias.
(E) No, because grade level is a lurking variable which may well be confounded with the variables under consideration.
40. A study at 35 large city high schools gives the following back-to-back stemplot of the percentages of students who say they have tried alcohol.
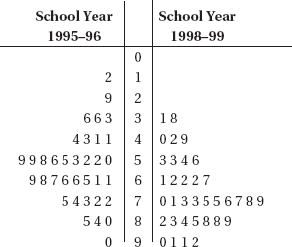
Which of the following does not follow from the above data?
(A) In general, the percentage of students trying alcohol seems to have increased from 1995–96 to 1998–99.
(B) The median alcohol percentage among the 35 schools increased from 1995–96 to 1998–99.
(C) The spread between the lowest and highest alcohol percentages decreased from 1995–96 to 1998–99.
(D) For both school years in most of the 35 schools, most of the students said they had tried alcohol.
(E) The percentage of students trying alcohol increased in each of the schools between 1995–96 and 1998–99.
If there is still time remaining, you may review your answers.
SECTION II
Part A
QUESTIONS 1–5
Spend about 65 minutes on this part of the exam.
Percentage of Section II grade—75
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your results and explanations.
1. A student is interested in estimating the average length of words in a 600-page textbook, and plans the following three-stage sampling procedure:
(1) Noting that each of the 12 chapters has a different author, the student decides to obtain a sample of words from each chapter.
(2) Each chapter is approximately 50 pages long. The student uses a random number generator to pick three pages from each chapter.
(3) On each chosen page the student notes the length of every tenth word.
(a) The first stage above represents what kind of sampling procedure? Give an advantage in using it in this context.
(b) The second stage above represents what kind of sampling procedure? Give an advantage in using it in this context.
(c) The third stage above represents what kind of sampling procedure? Give a disadvantage to using it dependent upon an author’s writing style.
2. (a) Suppose that nationwide, 69% of all registered voters would answer “Yes” to the question “Do you consider yourself highly focused on this year’s presidential election?” Which of the following is more likely: an SRS of 50 registered voters having over 75% answer “Yes,” or an SRS of 100 registered voters having over 75% answer “Yes” to the given question? Explain.
(b) A particular company with 95 employees wishes to survey their employees with regard to interest in the presidential election. They pick an SRS of 30 employees and ask “Do you consider yourself highly focused on this year’s presidential election?” Suppose that in fact 60% of all 95 employees would have answered “Yes.” Explain why it is not reasonable to say that the distribution for the count in the sample who say “Yes” is a binomial with n = 30 and p = 0.6.
(c) Suppose that nationwide, 78% of all registered voters would answer “Yes” to the question “Do you consider yourself highly focused on this year’s presidential election?” You plan to interview an SRS of 20 registered voters. Explain why it is not reasonable to say that the distribution for the proportion in the sample who say “Yes” is approximately a normal distribution.
3. An instructor takes an anonymous survey and notes exam score, hours studied, and gender for the first exam in a large college statistics class (n = 250). A resulting regression model is:
![]()
where Gender takes the value 0 for males and 1 for females.
(a) Provide an interpretation in context for each of the three numbers appearing in the above model formula.
(b) Sketch the separate prediction lines for males and females resulting from using 0 or 1 in the above model.
Looking at the data separately by gender results in the following two regression models:
![]()
(c) What comparative information do the slope coefficients from these two models give that does not show in the original model?
(d) Sketch the prediction lines given by these last two models.
4. A laboratory is testing the concentration level in milligrams per milliliter for the active ingredient found in a pharmaceutical product. In a random sample of five vials of the product, the concentrations were measured at 2.46, 2.57, 2.70, 2.64, and 2.54 mg/ml.
(a) Determine a 95% confidence interval for the mean concentration level in milligrams per milliliter for the active ingredient found in this pharmaceutical product.
(b) Explain in words what effect an increase in confidence level would have on the width of the confidence interval.
(c) Suppose a concentration above 2.70 milligrams per milliliter is considered dangerous. What conclusion is justified by your answers to (a) and (b)?
5. A point is said to have high leverage if it is an outlier in the x-direction, and a point is said to be influential if its removal sharply changes the regression line.
(a) In the scatterplots below, compare points A and B with regard to having high leverage and with regard to being influential.
(b) In the scatterplots below, compare points C and D with regard to residuals and influence on $\beta$1, the slope of the regression line.
(c) In the scatterplot below, compare the effect of removing point E or point F to that of removing both E and F.

(d) In the scatterplot below, compare the effect of removing point G or point H to that of removing both G and H.
SECTION II
Part B
QUESTION 6
Spend about 25 minutes on this part of the exam.
Percentage of Section II grade—25
6. In two random samples of adults, one from each of two communities, counts were made of the number of people with different years of schooling and tabulated as follows:
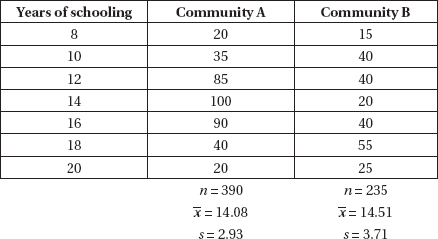
(a) Is there evidence of a difference in the mean years of schooling between the two communities?
(b) Is there evidence of a difference in the distribution of years of schooling in the two communities?
(c) Use histograms to help explain the above results.
If there is still time remaining, you may review your answers.
SECTION I
Questions 1–40
Spend 90 minutes on this part of the exam.
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. The mean and standard deviation of the population {1, 5, 8, 11, 15} are µ = 8 and σ = 4.8, respectively. Let S be the set of the 125 ordered triples (repeats allowed) of elements of the original population. Which of the following is a correct statement about the mean $\mu_\overline{x}$ and standard deviation $\sigma_\overline{x}$ of the means of the triples in S?
(A) $\mu_\overline{x}$ = 8, $\sigma_\overline{x}$ = 4.8
(B) $\mu_\overline{x}$ = 8, $\sigma_\overline{x}$ < 4.8
(C) $\mu_\overline{x}$ = 8, $\sigma_\overline{x}$ > 4.8
(D) $\mu_\overline{x}$ < 8, $\sigma_\overline{x}$ = 4.8
(E) $\mu_\overline{x}$ > 8, $\sigma_\overline{x}$ > 4.8
2. Consider the following studies being run by three different AP Statistics instructors.
I. One rewards students every day with lollipops for relaxation, encouragement, and motivation to learn the material.
II. One promises that all students will receive A’s as long as they give their best efforts to learn the material.
III. One is available every day after school and on weekends so that students with questions can come in and learn the material.
(A) None of these studies use randomization.
(B) None of these studies use control groups.
(C) None of these studies use blinding.
(D) Important information can be found from all these studies, but none can establish causal relationships.
(E) All of the above.
3. A survey to measure job satisfaction of high school mathematics teachers was taken in 1993 and repeated 5 years later in 1998. Each year a random sample of 50 teachers rated their job satisfaction on a 1-to-100 scale with higher numbers indicating greater satisfaction. The results are given in the following back-to-back stemplot.
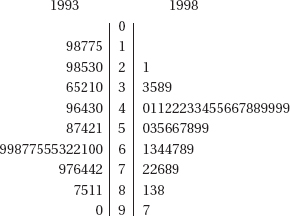
What is the trend from 1993 to 1998 with regard to the standard deviation and range of the two samples?
(A) Both the standard deviation and range increased.
(B) The standard deviation increased, while the range decreased.
(C) The range increased, while the standard deviation decreased.
(D) Both the standard deviation and range decreased.
(E) Both the standard deviation and range remained unchanged.
4. The number of days it takes to build a new house has a variance of 386. A sample of 40 new homes shows an average building time of 83 days. With what confidence can we assert that the average building time for a new house is between 80 and 90 days?
(A) 15.4%
(B) 17.8%
(C) 20.0%
(D) 38.8%
(E) 82.2%
5. A shipment of resistors have an average resistance of 200 ohms with a standard deviation of 5 ohms, and the resistances are normally distributed. Suppose a randomly chosen resistor has a resistance under 194 ohms. What is the probability that its resistance is greater than 188 ohms?
(A) 0.07
(B) 0.12
(C) 0.50
(D) 0.93
(E) 0.97
6. Suppose 4% of the population have a certain disease. A laboratory blood test gives a positive reading for 95% of people who have the disease and for 5% of people who do not have the disease. If a person tests positive, what is the probability the person has the disease?
(A) 0.038
(B) 0.086
(C) 0.442
(D) 0.558
(E) 0.950
7. For which of the following is it appropriate to use a census?
(A) A 95% confidence interval of mean height of teachers in a small town.
(B) A 95% confidence interval of the proportion of students in a small town who are taking some AP class.
(C) A two-tailed hypothesis test where the null hypothesis was that the mean expenditure on entertainment by male students at a high school is the same as that of female students.
(D) None of the above.
(E) All of the above.
8. On the same test, Mary and Pam scored at the 64th and 56th percentiles, respectively. Which of the following is a true statement?
(A) Mary scored eight more points than Pam.
(B) Mary’s score is 8% higher than Pam’s.
(C) Eight percent of those who took the test scored between Pam and Mary.
(D) Thirty-six people scored higher than both Mary and Pam.
(E) None of the above.
9. Which of the following is a true statement?
(A) While observational studies gather information on an already existing condition, they still often involve intentionally forcing some treatment to note the response.
(B) In an experiment, researchers decide on the treatment but typically allow the subjects to self-select into the control group.
(C) If properly designed, either observational studies or controlled experiments can easily be used to establish cause and effect.
(D) Wording to disguise hidden interests in observational studies is the same idea as blinding in experimental design.
(E) Stratifying in sampling is the same idea as blocking for experiments.
10. The random variable describing the number of minutes high school students spend in front of a computer daily has a mean of 200 minutes. Samples of two different sizes result in sampling distributions with the two graphs below.
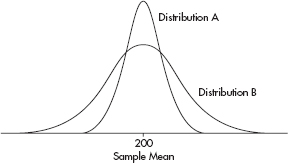
Which of the following is a true statement?
(A) Based on these graphs, no comparison between the two sample sizes is possible.
(B) More generally, sample sizes have no effect on sampling distributions.
(C) The sample size in A is the same as the sample size in B.
(D) The sample size in A is less than the sample size in B.
(E) The sample size in A is greater than the sample size in B.
11. To determine the mean cost of groceries in a certain city, an identical grocery basket of food is purchased at each store in a random sample of ten stores. If the average cost is \$47.52 with a standard deviation of \$1.59, find a 98% confidence interval estimate for the cost of these groceries in the city.

12. A set consists of four numbers. The largest value is 200, and the range is 50. Which of the following statements is true?
(A) The mean is less than 185.
(B) The mean is greater than 165.
(C) The median is less than 195.
(D) The median is greater than 155.
(E) The median is the mean of the second and third numbers if the set is arranged in ascending order.
13. A telephone survey of 400 registered voters showed that 256 had not yet made up their minds 1 month before the election. How sure can we be that between 60% and 68% of the electorate were still undecided at that time?
(A) 2.4%
(B) 8.0%
(C) 64.0%
(D) 90.5%
(E) 95.3%
14. Suppose we have a random variable X where the probability associated with the value k is ![]()
What is the mean of X?
(A) 0.29
(B) 0.71
(C) 4.35
(D) 10.65
(E) None of the above
15. The financial aid office at a state university conducts a study to determine the total student costs per semester. All students are charged \$4500 for tuition. The mean cost for books is \$350 with a standard deviation of \$65. The mean outlay for room and board is \$2800 with a standard deviation of \$380. The mean personal expenditure is \$675 with a standard deviation of \$125. Assuming independence among categories, what is the standard deviation of the total student costs?
(A) $24
(B) $91
(C) $190
(D) $405
(E) $570
16. Suppose X and Y are random variables with E(X) = 312, var(X) = 6, E(X) = 307, and var(Y) = 8. What are the expected value and variance of the random variable X + Y?
(A) E(X + Y) = 619, var(X + Y) = 7
(B) E(X + Y) = 619, var(X + Y) = 10
(C) E(X + Y) = 619, var(X + Y) = 14
(D) E(X + Y) = 309.5, var(X + Y) = 14
(E) There is insufficient information to answer this question.
17. In sample surveys, what is meant by bias?
(A) A systematic error in a sampling method that leads to an unrepresentative sample.
(B) Prejudice, for example in ethnic and gender related studies.
(C) Natural variability seen between samples.
(D) Tendency for some distributions to be skewed.
(E) Tendency for some distributions to vary from normality.
18. The following histogram gives the shoe sizes of people in an elementary school building one morning.
Which of the following is a true statement?
(A) The distribution of shoe sizes is bimodal.
(B) The median shoe size is $7\frac{1}{2}$.
(C) The mean shoe size is less than the median shoe size.
(D) The five-number summary is: ![]()
(E) Only 10% of the people had size 5 shoes.
19. When comparing the standard normal (z) distribution to the t-distribution with df = 30, which of (A)–(D), if any, are false?
(A) Both are symmetric.
(B) Both are bell-shaped.
(C) Both have center 0.
(D) Both have standard deviation 1.
(E) All the above are true statements.
20. Given a probability of 0.65 that interest rates will jump this year, and a probability of 0.72 that if interest rates jump the stock market will decline, what is the probability that interest rates will jump and the stock market will decline?

21. Sampling error is
(A) the mean of a sample statistic.
(B) the standard deviation of a sample statistic.
(C) the standard error of a sample statistic.
(D) the result of bias.
(E) the difference between a population parameter and an estimate of that parameter.
22. Suppose that the weights of trucks traveling on the interstate highway system are normally distributed. If 70% of the trucks weigh more than 12,000 pounds and 80% weigh more than 10,000 pounds, what are the mean and standard deviation for the weights of trucks traveling on the interstate system?
(A) µ = 14,900; σ = 6100
(B) µ = 15,100; σ = 6200
(C) µ = 15,300; σ = 6300
(D) µ = 15,500; σ = 6400
(E) The mean and standard deviation cannot be computed from the information given.
23. If the correlation coefficient r = 0.78, what percentage of variation in y is explained by variation in x?
(A) 22%
(B) 39%
(C) 44%
(D) 61%
(E) 78%
24. Consider the following scatterplot:
Which of the following is the best estimate of the correlation between x and y?
(A) –0.95
(B) –0.15
(C) 0
(D) 0.15
(E) 0.95
25. For one NBA playoff game the actual percentage of the television viewing public who watched the game was 24%. If you had taken a survey of 50 television viewers that night and constructed a confidence interval estimate of the percentage watching the game, which of the following would have been true?
I. The center of the interval would have been 24%.
II. The interval would have contained 24%.
III. A 99% confidence interval estimate would have contained 24%.
(A) I and II
(B) I and III
(C) II and III
(D) All are true.
(E) None is true.
26. Which of the following is a true statement?
(A) In a well-designed, well-conducted sample survey, sampling error is effectively eliminated.
(B) In a well-designed observational study, responses are influenced through an orderly, carefully planned procedure during the collection of data.
(C) In a well-designed experiment, the treatments are carefully planned to result in responses that are as similar as possible.
(D) In a well-designed experiment, double-blinding is a useful matched pairs design.
(E) None of the above is a true statement.
27. Consider the following scatterplot showing the relationship between caffeine intake and job performance.
Which of the following is a reasonable conclusion?
(A) Low caffeine intake is associated with low job performance.
(B) Low caffeine intake is associated with high job performance.
(C) High caffeine intake is associated with low job performance.
(D) High caffeine intake is associated with high job performance.
(E) Job performance cannot be predicted from caffeine intake.
28. An author of a new book claims that anyone following his suggested diet program will lose an average of 2.8 pounds per week. A researcher believes that the true figure will be lower and plans a test involving a random sample of 36 overweight people. She will reject the author’s claim if the mean weight loss in the volunteer group is less than 2.5 pounds per week. Assume that the standard deviation among individuals is 1.2 pounds per week. If the true mean value is 2.4 pounds per week, what is the probability that the researcher will mistakenly fail to reject the author’s false claim of 2.8 pounds?

29. Which of the following is the central limit theorem?
(A) No matter how the population is distributed, as the sample size increases, the mean of the sample means becomes closer to the mean of the population.
(B) No matter how the population is distributed, as the sample size increases, the standard deviation of the sample means becomes closer to the standard deviation of the population divided by the square root of the sample size.
(C) If the population is normally distributed, then as the sample size increases, the sampling distribution of the sample mean becomes closer to a normal distribution.
(D) All of the above together make up the central limit theorem.
(E) The central limit theorem refers to something else.
30. What is a sampling distribution?
(A) A distribution of all the statistics that can be found in a given sample
(B) A histogram, or other such visual representation, showing the distribution of a sample
(C) A normal distribution of some statistic
(D) A distribution of all the values taken by a statistic from all possible samples of a given size
(E) All of the above
31. A judge chosen at random reaches a just decision roughly 80% of the time. What is the probability that in randomly chosen cases at least two out of three judges reach a just decision?
(A) 3(0.8)2(0.2)
(B) 1 – 3(0.8)2(0.2)
(C) (0.8)3
(D) 1 – (0.8)3
(E) 3(0.8)2(0.2) + (0.8)3
32. Miles per gallon versus speed (miles per hour) for a new model automobile is fitted with a least squares regression line. Following is computer output of the statistical analysis of the data.
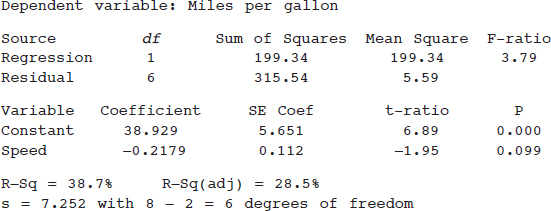
Which of the following gives a 99% confidence interval for the slope of the regression line?

33. What fault do all these sampling designs have in common?
I. The Parent-Teacher Association (PTA), concerned about rising teenage pregnancy rates at a high school, randomly picks a sample of high school students and interviews them concerning unprotected sex they have engaged in during the past year.
II. A radio talk show host asks people to phone in their views on whether the United States should keep troops in Bosnia indefinitely to enforce the cease-fire.
III. The Ladies Home Journal plans to predict the winner of a national election based on a survey of its readers.
(A) All the designs make improper use of stratification.
(B) All the designs have errors that can lead to strong bias.
(C) All the designs confuse association with cause and effect.
(D) All the designs suffer from sampling error.
(E) None of the designs makes use of chance in selecting a sample.
34. Hospital administrators wish to determine the average length of stay for all surgical patients. A statistician determines that for a 95% confidence level estimate of the average length of stay to within ±0.50 days, 100 surgical patients’ records would have to be examined. How many records should be looked at for a 95% confidence level estimate to within ±0.25 days?
(A) 25
(B) 50
(C) 200
(D) 400
(E) There is not enough information given to determine the necessary sample size.
35. A chess master wins 80% of her games, loses 5%, and draws the rest. If she receives 1 point for a win, 1/2 point for a draw, and no points for a loss, what is true about the sampling distribution X of the points scored in two independent games?
(A) X takes on the values 0, 1, and 2 with respective probabilities 0.10, 0.26, and 0.64.
(B) X takes on the values ![]() and 2 with respective probabilities 0.0025, 0.015, 0.1025, 0.24, and 0.64.
and 2 with respective probabilities 0.0025, 0.015, 0.1025, 0.24, and 0.64.
(C) X takes on values according to a binomial distribution with n = 2 and P = 0.8.
(D) X takes on values according to a binomial distribution with mean ![]()
(E) X takes on values according to a distribution with mean (2)(0.8) and standard deviation ![]()
36. Which of the following is a true statement?
(A) The P-value is a conditional probability.
(B) The P-value is usually chosen before an experiment is conducted.
(C) The P-value is based on a specific test statistic and thus should not be used in a two-sided test.
(D) P-values are more appropriately used with t-distributions than with z-distributions.
(E) If the P-value is less than the level of significance, then the null hypothesis is proved false.
37. An assembly line machine is supposed to turn out ball bearings with a diameter of 1.25 centimeters. Each morning the first 30 bearings produced are pulled and measured. If their mean diameter is under 1.23 centimeters or over 1.27 centimeters, the machinery is stopped and an engineer is called to make adjustments before production is resumed. The quality control procedure may be viewed as a hypothesis test with the null hypothesis H0: µ = 1.25 and the alternative hypothesis Ha: µ ≠ 1.25. The engineer is asked to make adjustments when the null hypothesis is rejected. In test terminology, what would a Type II error result in?
(A) A warranted halt in production to adjust the machinery
(B) An unnecessary stoppage of the production process
(C) Continued production of wrong size ball bearings
(D) Continued production of proper size ball bearings
(E) Continued production of ball bearings that randomly are the right or wrong size
38. Both over-the-counter niacin and the prescription drug Lipitor are known to lower blood cholesterol levels. In one double-blind study Lipitor outperformed niacin. The 95% confidence interval estimate of the difference in mean cholesterol level lowering was (18, 41). Which of the following is a reasonable conclusion?
(A) Niacin lowers cholesterol an average of 18 points, while Lipitor lowers cholesterol an average of 41 points.
(B) There is a 0.95 probability that Lipitor will outperform niacin in lowering the cholesterol level of any given individual.
(C) There is a 0.95 probability that Lipitor will outperform niacin by at least 23 points in lowering the cholesterol level of any given individual.
(D) We should be 95% confident that Lipitor will outperform niacin as a cholesterol-lowering drug.
(E) None of the above.
39. The following parallel boxplots show the average daily hours of bright sunshine in Liberia, West Africa:
For how many months is the median below 4 hours?
(A) One
(B) Two
(C) Three
(D) Four
(E) Five
40. Following is a cumulative probability graph for the number of births per day in a city hospital.
Assuming that a birthing room can be used by only one woman per day, how many rooms must the hospital have available to be able to meet the demand at least 90 percent of the days?
(A) 5
(B) 10
(C) 15
(D) 20
(E) 25
If there is still time remaining, you may review your answers.
SECTION II
Part A
QUESTIONS 1–5
Spend about 65 minutes on this part of the exam.
Percentage of Section II grade—75
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your results and explanations.
1. An experiment is being planned to study urban land use practices aimed at reviving and sustaining native bird populations. Vegetation types A and B are to be compared, and eight test sites are available. After planting, volunteer skilled birdwatchers will collect data on the abundance of bird species making each of the two habitat types their home. The east side of the city borders a river, while the south side borders an industrial park.
(a) Suppose the decision is made to block using the scheme below (one block is white, one gray). How would you use randomization, and what is the purpose of the randomization?
(b) Comment on the strength and weakness of the above scheme as compared to the following blocking scheme (one block is white, one gray).
2. A world organization report gives the following percentages for primary-school-age children enrolled in school in the 17 countries of each of two geographic regions.
Region A: 36, 45, 52, 56, 56, 58, 60, 63, 65, 66, 69, 71, 72, 74, 77, 82, 92
Region B: 35, 37, 41, 43, 43, 48, 50, 54, 65, 71, 78, 82, 83, 87, 89, 91, 92
(a) Draw a back-to-back stemplot of this data.
(b) The report describes both regions as having the same median percentage (for primary-school-age children enrolled in school) among their 17 countries and approximately the same range. What about the distributions is missed by the report?
(c) If the organization has education funds to help only one region, give an argument for which should be helped.
(d) A researcher plans to run a two-sample t-test to study the difference in means between the percentages from each region. Comment on his plan.
3. Data were collected from a random sample of 100 student athletes at a large state university. The plot below shows grade point average (GPA) versus standard normal value (z-score) corresponding to the percentile of each GPA (when arranged in order). Also shown is the normal line, that is, a line passing through expected values for a normal distribution with the mean and SD of the given data.
(a) What is the shape of this distribution? Explain.
(b) What is the 95th percentile of the data? Explain.
(c) In a normal distribution with the mean and SD of this data, what is the 95th percentile? Explain.
4. Although blood type frequencies in the United States are in the ratios of 9:8:2:1 for types O, A, B, and AB, respectively, local differences are often found depending upon a variety of demographic characteristics. Two researchers are independently assigned to determine if patients at a particular large city general hospital exhibit blood types supporting the above model. The table below gives the data results from what each researcher claims to be random samples of 500 patient lab results.

(a) Do the data reported by Researcher 1 support the 9:8:2:1 model for blood types of patients at the particular hospital? Justify your answer.
(b) The editorial board of a medical publication rejects the findings of Researcher 2, claiming that his data are suspicious in that they are too good to be true. Give a statistical justification for the board’s decision.
5. In a random sample of automobiles the highway mileage (in mpg) and the engine size (in liters) are measured, and the following computer output for regression is obtained:

Assume all conditions for regression inference are met.
(a) One of the points on the regression line corresponds to an auto with an engine size of 1.5 liters and highway mileage of 35 miles per gallon. What is the residual of this point?
Suppose another auto with an engine size of 5.0 liters and highway mileage of 17 mpg is added to the data set.
(b) Explain whether the new slope will be greater than, less than, or about the same as the slope given by the output above.
(c) Explain whether the new correlation will be greater than, less than, or about the same in absolute value as the correlation given by the output above.
SECTION II
Part B
QUESTION 6
Spend about 25 minutes on this part of the exam.
Percentage of Section II grade—25
6. A demographer randomly selects five northern and five southern U.S. states and notes the populations in 1990 and 2000:
She calculates the following summary statistics:
Assuming that all conditions for inference are met,
(a) at the $\alpha$ = 0.05 significance level, test the null hypothesis that southern states did not grow between 1990 and 2000;
(b) find a 95% confidence interval for the difference in populations between northern and southern states in 1990;
(c) test the hypothesis that southern states grew faster than northern states between 1990 and 2000.
If there is still time remaining, you may review your answers.
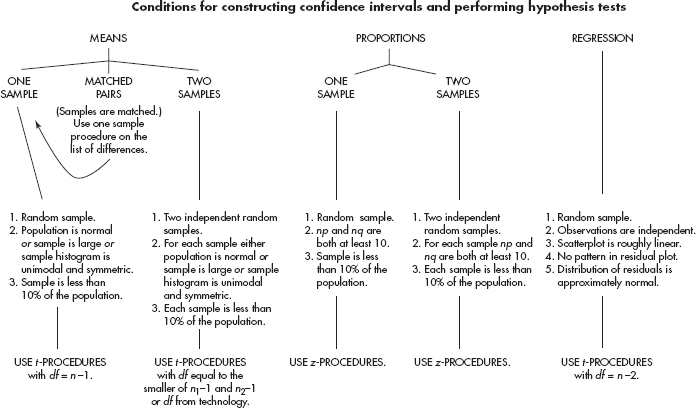
THE TOP TEN
1. Graders want to give you credit—help them! Make them understand what you are doing, why you are doing it, and how you are doing it. Don’t make the reader guess at what you are doing. Communication is just as important as statistical knowledge!
2. For both multiple-choice and free-response questions, read the question carefully! Be sure you understand exactly what you are being asked to do or find or explain.
3. Check assumptions. Don’t just state them! Be sure the assumptions to be checked are stated correctly. Verifying assumptions and conditions means more than simply listing them with little check marks—you must show work or give some reason to confirm verification.
4. Learn and practice how to read generic computer output. And in answering questions using computer output, realize that you usually will not need to use all the information given.
5. Naked or bald answers will receive little or no credit! You must show where answers come from. On the other hand, don’t give more than one solution to the same problem—you will receive credit only for the weaker one.
6. If you refer to a graph, whether it is a histogram, boxplot, stemplot, scatterplot, residuals plot, normal probability plot, or some other kind of graph, you should roughly draw it. It is not enough to simply say, “I did a normal probability plot of the residuals on my calculator and it looked linear.” Be sure to label axes and show number scales whenever possible.
7. Use proper terminology! For example, the language of experiments is different from the language of observational studies—you shouldn’t mix up blocking and stratification. Know what confounding means and when it is proper to use this term. Replication on many subjects to reduce chance variation is different from replication of an experiment itself to achieve validation.
8. Avoid “calculator speak”! For example, do not simply write “2-SampTTest …” or “binomcdf…” There are lots of calculators out there, each with its own abbreviations. Some abbreviated function notation can be referenced IF the parameters used are identified.
9. Be careful about using abbreviations in general. For example, your teacher might use LOBF (line of best fit), but the grader may have no idea what this refers to.
10. Don’t automatically “parrot” the stem of the problem! For example, the question might refer to sample data; however, your hypotheses must be stated in terms of a population parameter.
25 MORE HINTS
11. Insert new calculator batteries or carry replacement batteries with you.
12. Underline key words and phrases while reading questions.
13. Some problems look scary on first reading but are not overly difficult and are surprisingly straightforward if you approach them systematically. And some questions might take you beyond the scope of the AP curriculum; however, remember that they will be phrased in such ways that you should be able to answer them based on what you have learned in your AP Stat class.
14. Read through all six free-response questions, underlining key points. Go back and do those questions you think are easiest (this will usually, but not always, include Problem 1). Then tackle the heavily weighted Problem 6 for a while. Finally, try the remaining problems. If you have a few minutes at the end to try some more on Problem 6, that’s great!
15. Answers do not have to be in paragraph form. Symbols and algebra are fine. Just be sure that your method, reasoning, and calculations will be clear to the reader, and that the explanations and conclusions are given in context of the problem.
16. If you show calculations carefully, a wrong answer due to a computational error might still result in full credit.
17. If you can’t solve part of a problem, but that solution is necessary to proceed, make up a reasonable answer to the first part and use this to proceed to the remaining parts of the problem.
18. When using a formula, write down the formula and then substitute the values.
19. Conclusions should be stated in proper English. For example, don’t use double negatives.
20. Read carefully and recognize that sometimes very different tests are required in different parts of the same problem.
21. Realize that there may be several reasonable approaches to a given problem. In such cases pick either the one you feel most comfortable with or the one you feel will require the least time.
22. Realize that there may not be one clear, correct answer. Some questions are designed to give you an opportunity to creatively synthesize a relationship among the problem’s statistical components.
23. Punching a long list of data into the calculator doesn’t show statistical knowledge. Be sure it’s necessary!
24. Remember that uniform and symmetric are not the same, and that not all symmetric unimodal distributions are normal.
25. When making predictions and interpreting slopes and intercepts, don’t become confused between your original data and your regression model.
26. If the slope is close to ±1, it does not follow that the correlation is strong.
27. When describing residual graphs, “randomly scattered” does not mean the same as “half below and half above.” You should comment on whether or not there are nonlinear patterns, and increasing or decreasing spread, and on whether the residuals are small or large compared to the associated y-values.
28. Simply using a calculator to find a regression line is not enough; you must understand it (for example, be able to interpret the slope and intercepts in context).
29. With regard to hypothesis test problems, (1) the hypotheses must be stated in terms of population parameters with all variables clearly defined; (2) the test must be specified by name or formula, and you must show how the test assumptions are met; (3) the test statistic and associated P-value should be calculated; (4) the P-value must be linked to a decision; and (5) a conclusion must be stated in the context of the problem.
30. For any inference problem, be sure to ask yourself whether the variable is categorical (usually leading to proportions) or quantitative (usually leading to means), whether you are working with raw data or summary statistics, whether there is a single population of interest or two populations being compared, and in the case of comparison whether there are independent samples or a paired comparison.
31. A simple random sample (SRS) and a random assignment of treatments to subjects both have to do with randomness, but they are not the same. Understand the difference!
32. Simply saying to “randomly assign” subjects to treatment groups is usually an incomplete response. You need to explain how to make the assignments, for example, using a random number table or through generating random numbers on a calculator.
33. Blinding and placebos in experiments are important but are not always feasible. You can still have “experiments” without these.
34. The distribution of a particular sample (data set) is not the same as the sampling distribution of a statistic. Understand the difference!
35. Just because a sample is large does not imply that the distribution of the sample will be close to a normal distribution.
The Multiple-Choice and Free-Response sections are weighted equally.
There is no penalty for guessing in the Multiple-Choice section.
The Investigative Task counts for 25% of the Free-Response section. Each of the Free-Response questions has a possible four points.
To find your score use the following guide:
Multiple-Choice section (40 questions)
Number correct × 1.25 = …
Free-Response section (5 Open-Ended questions plus an Investigative Task)

Total points from Multiple-Choice and Free-Response sections = …
Conversion chart based on a recent AP exam
In the past, roughly 10% of students scored 5, 20% scored 4, 25% scored 3, 20% scored 2, and 25% scored 1 on the AP Statistics exam. Colleges generally require a score of at least 3 for a student to receive college credit.
There are many more useful features than introduced below—see the guidebook that comes with the calculator. For reference, following is a listing of the basic uses with which all students should be familiar. However, always remember that the calculator is only a tool, that it will find minimal use in the multiple-choice section, and that “calculator talk” (calculator syntax) should NOT be used in the free-response section.
Plotting statistical data:
STAT PLOT allows one to show scatterplots, histograms, modified boxplots, and regular boxplots of data stored in lists. Note the use of TRACE with the various plots.
Numerical statistical data:
1-Var Stats gives the mean, standard deviation, and 5-number summary of a list of data.
Binomial probabilities:
binompdf (n, p, x) gives the probability of exactly x successes in n trials where p is the probability of success on a single trial.
binomcdf (n, p, x) gives the cumulative probability of x or fewer successes in n trials where p is the probability of success on a single trial.
Geometric probabilities:
geometpdf (p, x) gives the probability that the first success occurs on the x-th trial, where p is the probability of success on a single trial.
geometcdf (p, x) gives the cumulative probability that the first success occurs on or before the x-th trial, where p is the probability of success on a single trial.
The normal distribution:
normalcdf (lowerbound, upperbound, µ, $\sigma$) gives the probability that a score is between the two bounds for the designated mean µ and standard deviation $\sigma$. The defaults are µ = 0 and $\sigma$ = 1.
InvNorm (area, µ, $\sigma$) gives the score associated with an area (probability) to the left of the score for the designated mean µ and standard deviation $\sigma$. The defaults are µ = 0 and $\sigma$ = 1.
The t-distribution:
tcdf (lowerbound, upperbound, df) gives the probability a score is between the two bounds for the specified df (degrees of freedom).
invT(area, df) gives the t-score associated with an area (probability) to the left of the score under the student t-probability function for the specified df (degrees of freedom). [Note: this is available on the new operating system for the TI-84+.]
The chi-square distribution:
$\chi$2cdf (lowerbound, upperbound, df) gives the probability a score is between the two bounds for the specified df (degrees of freedom).
$\chi$2GOF-Test is a chi-square goodness-of-fit test to confirm whether sample data conforms to a specified distribution. [Note: this is available on the new operating system for the TI-84+.]
Linear regression and correlation:
LinReg (ax + b) fits the equation y = ax + b to the data in lists L1 and L2 using a least-squares fit. When DiagnosticOn is set, the values for r2 and r are also displayed.
Confidence intervals:
For proportions—
1-PropZInt gives a confidence interval for a proportion of successes.
2-PropZInt gives a confidence interval for the difference between the proportion of successes in two populations.
For means—
TInterval gives a confidence interval for a population mean (use the t-distribution because population variances are never really known).
2-SampTInt gives a confidence interval for the difference between two population means.
Hypothesis tests:
For proportions—
1-PropZTest
2-PropZTest compares the proportion of successes from two populations (making use of the pooled sample proportion).
For means—
T-Test
2-SampTTest
For chi-square test for association—
$\chi$2-Test gives the $\chi$2-value and P-value for the null hypothesis H0: no association between row and column variables, and the alternative hypothesis Ha: the variables are related. The observed counts must first be entered into a matrix.
For linear regression—
LinRegTTest calculates a linear regression and performs a t-test on the null hypothesis H0: $\beta$ = 0 (H0: ρ = 0). The regression equation is stored in RegEQ (under VARS Statistics EQ) and the list of residuals is stored in RESID (under LIST NAMES).
Catalog help:
To activate Catalog Help, press APPS, choose CtlgHelp, and press ENTER. Then, for example, if you press 2nd, DISTR, arrow down to normalcdf, and press +, you are prompted to insert (lowerbound, upperbound, [µ,$\sigma$]), that is, to insert the bounds and, optionally, the mean and SD.
The following are in the form and notation as recommended by the College Board.

![]()
Confidence interval:
Estimate ± (critical value) · (standard deviation of the estimate)
SINGLE SAMPLE
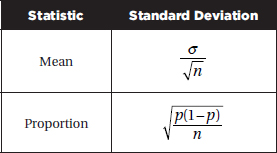
TWO SAMPLE
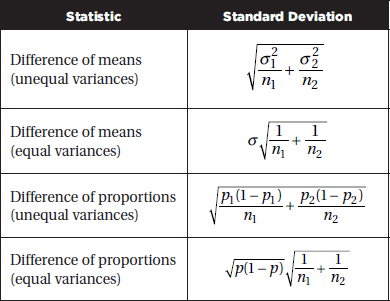
![]()
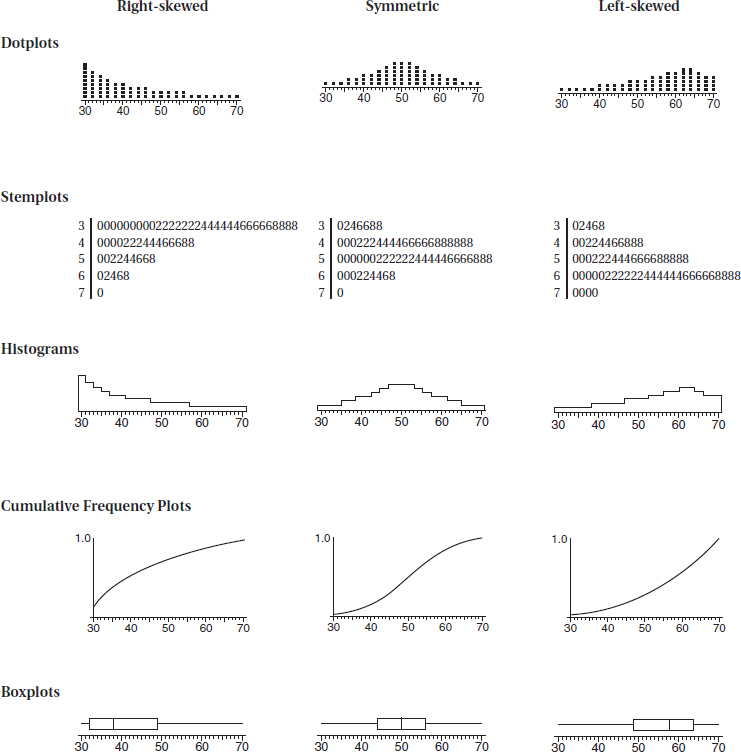
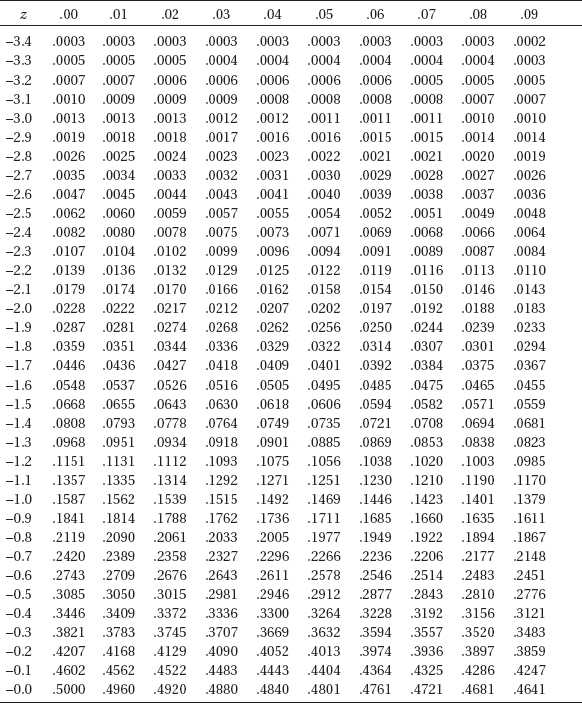
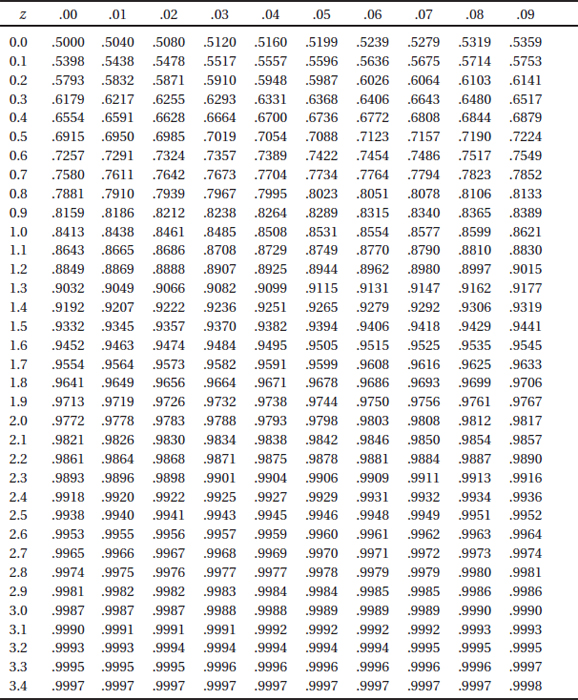
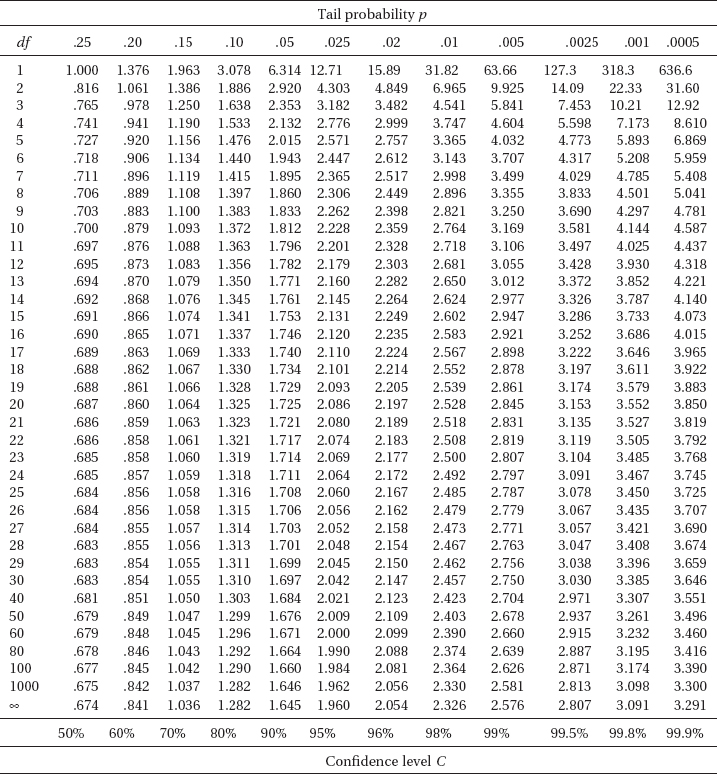

SECTION I
Questions 1–40
Spend 90 minutes on this part of the exam.
Directions: The questions or incomplete statements that follow are each followed by five suggested answers or completions. Choose the response that best answers the question or completes the statement.
1. The statistician for a professional basketball team calculates the percentages of points scored through 3-point shots, 2-point shots, and foul shots over two seasons. They are summarized in the following segmented bar chart.
Which of the following is an incorrect conclusion?
(A) More points were scored through foul shots in the second season than in the first.
(B) In the first season, twice as many points were scored through 2-point shots than through foul shots.
(C) In the second season, the same number of points were scored through 3-point shots and through foul shots.
(D) In both seasons, the same proportion of total points were scored through 2-point shots.
(E) In the first season, a greater proportion of the points were scored through 3-point shots than in the second season.
2. Is there a linear relationship between calories and sodium content in beef hot dogs? A study of 20 beef hot dogs gives the following regression output:
Which of the following gives a 99% confidence interval for the slope of the regression line?

3. In tossing a fair coin, which of the following sequences is more likely to appear?
(A) HHHHH
(B) HTHTHT
(C) HTHHTTH
(D) TTHTHHTH
(E) All are equally likely.
4. An entomologist hypothesizes that the mean life expectancy of a particular species of insect is 12.5 days. Researchers believing that the true mean is less than 12.5 days plan a hypothesis test at the 5% significance level on a random sample of 50 of these insects. If the alternative hypothesis is correct, for which of the following values of µ will the power of the test be greatest?
(A) 9
(B) 11
(C) 12.5
(D) 14
(E) 17
5. A simple random sample is defined by
(A) the method of selection
(B) how representative the sample is of the population
(C) whether or not a random number generator is used
(D) the assignment of different numbers associated with the outcomes of some chance situation
(E) examination of the outcome
6. Can shoe size be predicted from height? In a random sample of 50 adults, the standard deviation in heights was 8.7 cm, while the standard deviation in shoe size was 2.3. The least squares regression equation was:
Predicted shoe size = –33.6 + 0.25 (Height in cm). What was the correlation?
(E) There is not enough information to calculate the correlation.
Questions 7–9 refer to the following situation:
A researcher would like to show that a new oral diabetes medication he developed helps control blood sugar level better than insulin injection. He plans to run a hypothesis test at the 5% significance level.
7. What would be a Type I error?
(A) The researcher concludes he has evidence his new medication helps more than insulin injection, and his medication really is better than insulin injection.
(B) The researcher concludes he has evidence his new medication helps more than insulin injection, when in reality his medication is not better than insulin injection.
(C) The researcher concludes he has no evidence his new medication helps more than insulin injection, and his medication really is not better than insulin injection.
(D) The researcher concludes he has no evidence his new medication helps more than insulin injection, when in reality his medication is better than insulin injection.
(E) The researcher concludes he has evidence his new medication controls blood sugar level the same as insulin injection, and in reality there is a difference.
8. What would be a Type II error?
(A) The researcher concludes he has evidence his new medication helps more than insulin injection, and his medication really is better than insulin injection.
(B) The researcher concludes he has evidence his new medication helps more than insulin injection, when in reality his medication is not better than insulin injection.
(C) The researcher concludes he has no evidence his new medication helps more than insulin injection, and his medication really is not better than insulin injection.
(D) The researcher concludes he has no evidence his new medication helps more than insulin injection, when in reality his medication is better than insulin injection.
(E) The researcher concludes he has evidence his new medication controls blood sugar level the same as insulin injection, and in reality there is a difference.
9. The researcher thinks he can improve his chances by running five such identical hypotheses tests, each using a different group of diabetic volunteers, hoping that at least one of the tests will show that his new oral diabetes medication helps control blood sugar level better than insulin injection. What is the probability of committing at least one Type I error?
(A) 0.05
(B) 0.204
(C) 0.226
(D) 0.774
(E) 0.95
10. A financial analyst determines the yearly research and development investments for 50 blue chip companies. She notes that the distribution is distinctly not bell-shaped. If the 50 dollar amounts are converted to z-scores, what can be said about the standard deviation of the 50 z-scores?
(A) It depends on the distribution of the raw scores.
(B) It is less than the standard deviation of the raw scores.
(C) It is greater than the standard deviation of the raw scores.
(D) It is equal to the standard deviation of the raw scores.
(E) It equals 1.
11. Tossing a fair die has outcomes {1,2,3,4,5,6} with mean 3.5 and standard deviation 1.708. If a fair die is thrown three times, and the mean of the resulting triplet is calculated, the mean and standard deviation of the set of all possible such triplets is
12. A 40-question multiple-choice statistics exam is graded as number correct minus ¼ number incorrect, so scores can range from –10 to +40. Suppose the standard deviation for one class’s results is reported to be –3.14. What is the proper conclusion?
(A) More students received negative scores than positive scores.
(B) At least half the class received negative scores.
(C) Some students must have received negative scores.
(D) Some students must have received positive scores.
(E) An error was made in calculating the standard deviation.
13. Of the 423 seniors graduating this year from a city high school, 322 plan to go on to college. When the principal asks an AP student to calculate a 95% confidence interval for the proportion of this year’s graduates who plan to go to college, the student says that this would be inappropriate. Why?
(A) The independence assumption may have been violated (students tend to do what their friends do).
(B) There is no evidence that the data come from a normal or nearly normal population (GPAs help determine college admission and may be skewed).
(C) Randomization was not used.
(D) There is a difference between a confidence interval and a hypothesis test with regard to the proportion of graduates planning on college.
(E) Some other reason.
14. An AP Statistics student in a large high school plans to survey his fellow students with regard to their preference between using a laptop or using an iPad. Which of the following survey methods would result in an unbiased result?
(A) The student comes to school early and surveys the first 50 students who arrive.
(B) The student passes a survey card to every student with instructions to fill it out at home and drop the filled out card in a box by the school entrance the next day.
(C) The student posts the survey on his Facebook page, asking everyone to respond.
(D) The student goes to all of the high school sports events for a week, hands out the survey, and waits for each student to fill it out and hand it back.
(E) All the above would lead to biased results.
15. The mean combined SAT score for students in one state is 1758 with a standard deviation of 213, while for a second state the mean is 1725 with a standard deviation of 228. Assuming both distributions are approximately normal, what is the probability that a randomly selected student in the first state scores higher than a randomly selected student in the second state?
(A) 0.458
(B) 0.500
(C) 0.524
(D) 0.542
(E) 0.559
16. In a random sample of 10 insects of a newly discovered species, an entomologist measures an average life expectancy of 17.3 days with a standard deviation of 2.3 days. Assuming all conditions for inference are met, what is a 95% confidence interval for the mean life expectancy for insects of this species?

17. A coin is weighted so that heads is twice as likely to occur as tails. The coin is flipped repeatedly until a tail occurs. Let X be the number of flips made. What is the most probable value for X?
(A) 1
(B) 2
(C) 3
(D) 4
(E) 5
18. Suppose we are interested in determining whether or not a student’s score on the AP Statistics Exam is a reasonable predictor of the student’s GPA in the first year of college. Which of the following is the best statistical test?
(A) Two-sample t-test of population means
(B) Linear regression t-test
(C) Chi-square test of independence
(D) Chi-square test of homogeneity
(E) Chi-square test of goodness of fit
19. Following are the graphs of three normal curves and three cumulative distribution graphs:
Which normal curve corresponds to which cumulative curve?
(A) X-1, Y-2, Z-3
(B) X-1, Y-3, Z-2
(C) X-2, Y-1, Z-3
(D) X-3, Y-1, Z-2
(E) X-3, Y-2, Z-1
20. A campus has 55% male students. Suppose 30% of the male students pick basketball as their favorite sport compared to 20% of the females. If a randomly chosen student picks basketball as the student’s favorite sport, what is the probability the student is male?

21. The kelvin is a unit of measurement for temperature; 0 K is absolute zero, the temperature at which all thermal motion ceases. Conversion from Fahrenheit to Kelvin is given by K = 5/9 × (F – 32) + 273. The average daily temperature in Monrovia, Liberia, is 78.35°F with a standard deviation of 6.3°F. If a scientist converts Monrovia daily temperatures to the Kelvin scale, what will be the new mean and standard deviation?
(A) Mean, 25.75 K; standard deviation, 3.5 K
(B) Mean, 231.75 K; standard deviation, 3.5 K
(C) Mean, 298.75 K; standard deviation, 3.5 K
(D) Mean, 298.75 K; standard deviation, 258.72 K
(E) Mean, 298.75 K; standard deviation, 276.5 K
22. A cattle veterinarian is considering two experimental designs to compare two sources of bovine growth hormone, or BVH, to spur increased milk production in Guernsey cattle. Design 1 involves flipping a coin as each cow enters the stockade, and if heads, giving it BVH from bovine cadavers, and if tails, giving it BVH from engineered E. coli. Design 2 involves flipping a coin as each cow enters the stockade, and if heads, giving it BVH from bovine cadavers for a specified period of time and then switching to BVH from engineered E. coli for the same period of time, and if tails, the order is reversed. With both designs, daily milk production is noted. Which of the following is accurate?
(A) Neither design uses randomization since there is no indication that cows will be randomly picked from the population of all Guernsey cattle.
(B) Design 1 is a completely randomized design, while Design 2 is a block design.
(C) Both designs use double-blinding, but neither uses a placebo.
(D) In the second design, BVH from bovine cadavers and BVH from engineered E. coli are confounded.
(E) One of the two designs is actually an observational study, while the other is an experiment.
23. The purpose of the linear regression t-test is
(A) to determine if there is a linear association between two numerical variables
(B) to find a confidence interval for the slope of a regression line
(C) to find the y-intercept of a regression line
(D) to be able to calculate residuals
(E) to be able to determine the consequences of Type I and Type II errors
24. A fair die is tossed 12 times, and the number of 3’s is noted. This is repeated 200 times. Which of the following distributions is the most likely to occur?
25. Which of the following is a true statement about sampling?
(A) If the sample is random, the size of the sample doesn’t matter.
(B) If the sample is random, the size of the population doesn’t matter.
(C) A sample of less than 1% of the population is too small for statistical inference.
(D) A sample of more than 10% of the population is too large for statistical inference.
(E) All of the above are true statements.
26. Suppose, in a study of mated pairs of soldier beetles, it is found that the measure of the elytron (hardened forewing) length is always 0.5 millimeters longer in the female. What is the correlation between elytron lengths of mated females and males?
(A) –1
(B) –0.5
(C) 0
(D) 0.5
(E) 1
27. A random sample of 100 individuals who were singled out at an international airport security checkpoint is reviewed, and the individuals are classified according to country of origin:
 The proportion of travelers in each category who use this airport follows:
The proportion of travelers in each category who use this airport follows:

We wish to test whether the distribution of people singled out is the same as the distribution of people who use the airport with regard to country of origin. What is the appropriate $\chi$2 statistic?
28. The age distribution for a particular debilitating disease has a mean greater than the median. Which of the following graphs most likely illustrates this distribution?
29. Suppose we have a random variable X where the probability associated with the value
![]()
What is the mean of X?
(A) 0.38
(B) 0.62
(C) 3.8
(D) 5.0
(E) 6.2
30. It is hypothesized that high school varsity pitchers throw fastballs at an average of 80 mph. A random sample of varsity pitchers are timed with radar guns resulting in a 95% confidence interval of (74.5, 80.5). Which of the following is a correct statement?
(A) There is a 95% chance that the mean fastball speed of all varsity pitchers is 80 mph.
(B) There is a 95% chance that the mean fastball speed of all varsity pitchers is 77.5 mph.
(C) Most of the interval is below 80, so there is evidence at the 5% significance level that the mean of all varsity pitchers is something different than 80 mph.
(D) The test H0: µ = 80, Ha: µ ≠ 80 is not significant at the 5% significance level, but it would be at the 1% level.
(E) It is likely that the true mean fastball speed of all varsity pitchers is within 3 mph of the sample mean fastball speed.
31. A recent study noted prices and battery lives of 10 top-selling tablet computers. The data follow:
The residual plot of the least squares model is
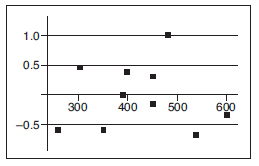
What is the model’s predicted battery life for the tablet computer costing $480?
(A) 10 hr
(B) 10.5 hr
(C) 11 hr
(D) 11.5 hr
(E) 12 hr
32. Should college athletes be required to give their coaches their Facebook IDs and passwords? A survey of student-athletes is to be taken. The statistician believes that Division I, II, and III players may differ in their views, so she selects a random sample of athletes from each Division to survey. This is a
(A) simple random sample
(B) stratified sample
(C) cluster sample
(D) systematic sample
(E) convenience sample
33. Which of the following use of a random number table would be appropriate to simulate tossing 3 fair coins and noting the number of heads?
(A) Assign “0,1” to 0 heads, “2,3” to 1 head, “4,5” to 2 heads, “6,7” to 3 heads, and ignore “8,9.”
(B) Assign “0,1” to 0 heads, “2,3,4” to 1 head, “5,6,7” to 2 heads, and “8,9” to 3 heads.
(C) Assign “0” to 0 heads, “1,2” to 1 head, “3,4” to 2 heads, “5” to 3 heads, and ignore “6,7,8,9.”
(D) Assign “0” to 0 heads, “1,2,3” to 1 head, “4,5,6” to 2 heads, “7” to 3 heads, and ignore “8,9.”
(E) Assign “0” to 0 heads, “1,2,3,4” to 1 head, “5,6,7,8” to 2 heads, and “9” to 3 heads.
34. The population of the Greater Tokyo area is 34,400,000 and of Karachi is 17,200,000. A random sample of citizens is to be taken in each city, and confidence intervals for the mean age in each city will be calculated. Assuming roughly equal sample standard deviations, to obtain the same margin of error for each confidence interval,
(A) the sample sizes should be the same
(B) the sample in Greater Tokyo should be twice the size of the sample in Karachi
(C) the sample in Karachi should be twice the size of the sample in Greater Tokyo
(D) the sample in Greater Tokyo should be four times the size of the sample in Karachi
(E) the sample in Karachi should be four times the size of the sample in Greater Tokyo
35. The midhinge is defined to be the average of the first and third quartiles. If the midhinge is 20 and the interquartile range is also 20, what is the first quartile?
(A) 0
(B) 10
(C) 20
(D) 30
(E) Impossible to determine from the given information
36. Which of the following is an incorrect statement?
(A) Statistics are random variables with their own probability distributions.
(B) The standard error does not depend on the size of the population.
(C) Bias means that, on average, our estimate of a parameter is different from the true value of the parameter.
(D) There are some statistics for which the sampling distribution is not approximately normal, no matter how large the sample size.
(E) The larger the sample size, the closer the sample distribution is to a normal distribution.
37. For male Air Force cadets, the recommended fitness level with regard to the number of push-ups is 34. In a test whether or not current classes of recruits can meet this standard, a t-test of H0: µ = 34 against Ha: µ < 34 gives a P-value of 0.068. Using this data, among the following, which is the largest level of confidence for a two-sided confidence interval that does not contain 34?
(A) 85%
(B) 90%
(C) 92%
(D) 95%
(E) 96%
38. A particular car is tested for stopping distance in feet on wet pavement at 30 mph using tires with one tread design and then tires with another tread design. For each set of tires, the test is repeated 30 times, and the following parallel boxplots give a comparison of the resulting five-number summaries.
Which of the following is a reasonable conclusion?
(A) Distribution I is skewed right, while distribution II is bell-shaped.
(B) Distribution I is skewed left, while distribution II is a normal distribution.
(C) The mean of distribution I is greater than the mean of distribution II.
(D) The range of distribution I is approximately 46 – 33 = 13.
(E) The upper 50% of the values in distribution I are all greater than the lower 50% of the values in distribution II.
39. In American roulette there are 18 red pockets, 18 black pockets, and two green pockets (labeled 0 and 00). The ball is equally likely to land in any of the 38 pockets. What is the probability that a player ends up with a positive outcome, that is, makes money, after 50 equal bets on “red” (that is, for each of 50 spins of the wheel, the player wins or loses the specified identical dollar bet depending on whether or not the ball lands in a red or non-red pocket, respectively)?
(A) 0.105
(B) 0.212
(C) 0.303
(D) 0.408
(E) 0.500
40. Do middle school and high school students have different views on what makes someone popular? Random samples of 100 middle school and 100 high school students yield the following counts with regard to three choices: lots of money, good at sports, and handsome or pretty:
A chi-square test of homogeneity yields which of the following test statistics?
If there is still time remaining, you may review your answers.
SECTION II
Part A
QUESTIONS 1–5
Spend about 65 minutes on this part of the exam.
Percentage of Section II grade—75
Directions: You must show all work and indicate the methods you use. You will be graded on the correctness of your methods and on the accuracy of your results and explanations.
1. A horticulturist plans a study on the use of compost tea for plant disease management. She obtains 16 identical beds, each containing a random selection of five mini-pink rose plants. She plans to use two different composting times (two and five days), two different compost preparations (aerobic and anaerobic), and two different spraying techniques (with and without adjuvants). Midway into the growing season she will check all plants for rose powdery mildew disease.
(a) List the complete set of treatments.
(b) Describe a completely randomized design for the treatments above.
(c) Explain the advantage of using only mini-pink roses in this experiment.
(d) Explain a disadvantage of using only mini-pink roses in this experiment.
2. A top-100, 7.0-rated tennis pro wishes to compare a new Wilson N1 racquet against his current model. He strings the new racquet with the same Luxilon strings at 60 pounds tension that he uses on his old racquet. From past testing he knows that the average forehand cross court volley with his old racquet is 82 miles per hour (mph). On an indoor court, using a ball machine set at 70 mph, the same speed he had his old racquet tested against, he takes 47 swings with the new racquet. An associate with a speed gun records an average of 83.5 mph with a standard deviation of 3.4 mph. Assuming that the 47 swings represents a random sample of his swings, is there statistical evidence that his speed with the new racquet is an improvement over the old? Justify your answer.
3. In October 2014, a comprehensive residential college in upstate New York reported undergraduate enrollment by ethnic/racial categories as follows: 2.7% non-Hispanic Black, 3.7% Asian or Pacific Islander, 4.0% Hispanic, 80.0% non-Hispanic White, and the rest other/unknown. While racial/ethnic status is not considered in the admissions process, an admissions counselor is interested in whether or not the makeup of the new freshman class will change, and plans to do a statistical analysis on an appropriately drawn simple random sample.
(a) What statistical test/procedure should be used?
(b) State the null and alternative hypotheses. Is the test appropriate for an intended sample size of 200?
(c) If the admissions counselor performs the indicated test on the following data, is there statistical evidence of a change in ethnic/racial composition? Explain.
Non-Hispanic Black | Asian or Pacific Islander | Hispanic | Non-Hispanic White | Other/Unknown | |
Number of Students | 3 | 4 | 14 | 150 | 29 |
(d) Suppose the data was obtained by noting the racial/ethnic status of a simple random sample of 200 potential new students visiting the campus during fall 2014. Did the test/procedure target the intended population? Explain.
4. Concrete is made by mixing sand and pebbles with water and cement and then hardening through hydration. Different densities result from different proportions of the aggregates. Assume that concrete densities are normally distributed with mean 2317 kilograms per cubic meter and standard deviation 128 kilograms per cubic meter.
(a) What is the probability that a given concrete density is over 2400 kg/m3?
(b) In a random sample of five independent concrete densities, what is the probability that a majority have densities over 2400 kg/m3?
(c) What is the probability that the mean of the five independent concrete densities is over 2400 kg/m3?
5. A small art gallery in Laguna Beach has the choice of stocking either oil paintings or finger paintings for a given tourist season. The oil paintings require a substantial investment, but the potential returns are also greater. The return (profit or loss) depends on whether or not the tourists that season are primarily serious art collectors or more casual buyers. A sales analysis gives the following expectations.
Season return ($1000) | Type of tourists | |
Stock decision | Art collectors | Casual buyers |
Oil paintings | 135 | –35 |
Finger paintings | –5 | 25 |
Let p be the probability that the type of tourist is primarily art collectors, so (1 – p) is the probability of primarily casual buyers.
(a) As a function of p, what is the expected return for stocking oil paintings?
(b) As a function of p, what is the expected return for stocking finger paintings?
(c) For what value of p are the two expected returns the same, and what does it mean in context for p to be greater or less than this value?
(d) In a random sample of similar establishments in similar tourist regions, 33 out of 150 reported seasons with tourists who were primarily art collectors. Construct a 95% confidence interval for the proportion of similar establishments with tourists who were primarily art collectors.
(e) Use the above results to justify a decision to stock finger paintings.
SECTION II
Part B
QUESTION 6
Spend about 25 minutes on this part of the exam.
Percentage of Section II grade—25
6. A national retail chain classifies cashiers as “entry level” for the first ten years. The series of boxplots below shows the relationship between yearly wages (in $1000) and years of experience (YOE) for a random sample of these employees. Below the boxplots are computer regression outputs.
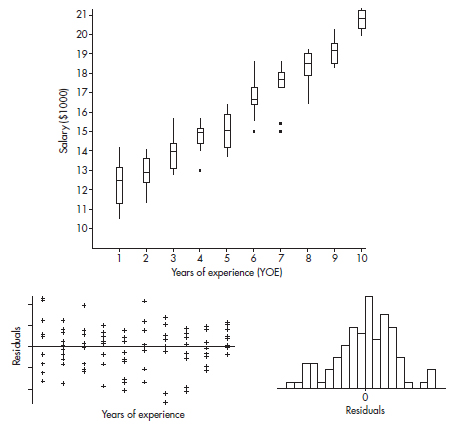
Dependent variable is: WAGES
Var | Coef | s.e. Coef | t | p |
Constant | 11.1113 | 0.2031 | 54.7 | ≤ 0.0001 |
YOE | 0.910485 | 0.03273 | 27.8 | ≤ 0.0001 |
R–Sq = 88.8% R–Sq(adj) = 88.6%
s = 0.9402 with 100 – 2 = 98 degrees of freedom
(a) Discuss the relationship between salary and experience based on the boxplots.
(b) Discuss how conditions for regression inference are met.
(c) Determine a 95% confidence interval for the regression slope, and interpret in context.
(d) Using only the given information, give a rough estimate of the probability that a salary is at least $1000 over what is predicted by the regression line.
If there is still time remaining, you may review your answers.
AP SCORE FOR THE DIAGNOSTIC EXAM
Multiple-Choice section (40 questions)
Number correct × 1.25 = _____________
Free-Response section (5 open-ended questions plus an investigative task)

Total points from Multiple-Choice and Free-Response sections = _____________
Conversion chart based on a recent AP exam:

STUDY GUIDE FOR THE DIAGNOSTIC TEST MULTIPLE-CHOICE QUESTIONS
Note in which Themes your missed questions fall. Then give special note to the Topics corresponding to the missed questions. Additionally, whenever you wish to test yourself on a particular Theme, go back to the designated questions.
Theme One: Exploratory Analysis
Question 1 | Topic Five: Exploring Categorical Data |
Question 6 | Topic Four: Exploring Bivariate Data |
Question 10 | Topic Two: Summarizing Distributions |
Question 12 | Topic Two: Summarizing Distributions |
Question 19 | Topic One: Graphical Displays |
Question 21 | Topic Two: Summarizing Distributions |
Question 26 | Topic Four: Exploring Bivariate Data |
Question 28 | Topic One: Graphical Displays |
Question 31 | Topic Four: Exploring Bivariate Data |
Question 35 | Topic Two: Summarizing Distributions |
Question 38 | Topic One: Graphical Displays |
Theme Two: Planning a Study
Question 5 | Topic Seven: Planning and Conducting Surveys |
Question 14 | Topic Seven: Planning and Conducting Surveys |
Question 22 | Topic Eight: Planning and Conducting Experiments |
Question 25 | Topic Seven: Planning and Conducting Surveys |
Question 32 | Topic Seven: Planning and Conducting Surveys |
Theme Three: Probability
Question 3 | Topic Nine: Probability as Relative Frequency |
Question 9 | Topic Nine: Probability as Relative Frequency |
Question 11 | Topic Twelve: Sampling Distributions |
Question 15 | Topic Ten: Combining Independent Random Variables |
Question 17 | Topic Nine: Probability as Relative Frequency |
Question 19 | Topic Eleven: The Normal Distribution |
Question 20 | Topic Nine: Probability as Relative Frequency |
Question 24 | Topic Nine: Probability as Relative Frequency |
Question 29 | Topic Nine: Probability as Relative Frequency |
Question 33 | Topic Nine: Probability as Relative Frequency |
Question 36 | Topic Twelve: Sampling Distributions |
Question 39 | Topic Nine: Probability as Relative Frequency |
Theme Four: Statistical Inference
Question 2 | Topic Thirteen: Confidence Intervals |
Question 4 | Topic Fourteen: Tests of Significance—Proportions and Means |
Question 7 | Topic Fourteen: Tests of Significance—Proportions and Means |
Question 8 | Topic Fourteen: Tests of Significance—Proportions and Means |
Question 9 | Topic Fourteen: Tests of Significance—Proportions and Means |
Question 13 | Topic Thirteen: Confidence Intervals |
Question 16 | Topic Thirteen: Confidence Intervals |
Question 18 | Topic Fifteen: Tests of Significance—Chi-Square and Slope of Least Squares Line |
Question 23 | Topic Fifteen: Tests of Significance—Chi-Square and Slope of Least Squares Line |
Question 27 | Topic Fifteen: Tests of Significance—Chi-Square and Slope of Least Squares Line |
Question 30 | Topic Thirteen: Confidence Intervals |
Question 34 | Topic Thirteen: Confidence Intervals |
Question 37 | Topic Thirteen: Confidence Intervals |
Question 40 | Topic Fifteen: Tests of Significance—Chi-Square and Slope of Least Squares Line |
SECTION I
1. (A) Without knowing the actual number of points scored each season, only proportions, not numbers of points, can be compared between seasons.
2. (C) The critical t-values with df = 20 – 2 = 18 are ± 2.878. Thus, we have b1 ± t∗ × SE(b1) = 4.0133 ± (2.878)(0.4922).
3. (A) The shortest sequence has a greater probability than any longer sequence.
4. (A) Power, the probability of rejecting a false null hypothesis, will be the greatest for parameter values farthest from the hypothesized value, in the direction of the alternative hypothesis.
5. (A) A simple random sample may or may not be representative of the population. It is a method of selection in which every possible sample of the desired size has an equal chance of being selected.
6. (A) A formula relating the given statistics is ![]() which in this case gives
which in this case gives ![]()
7. (B) The null hypothesis is that the new medication is no better than insulin injection, while the alternative hypothesis is that the new medication is better. A Type I error means a mistaken rejection of a true null hypothesis.
8. (D) A Type II error means a mistaken failure to reject a false null hypothesis.
9. (C) Running a hypothesis test at the 5% significance level means that the probability of committing a Type I error is 0.05. Then the probability of not committing a Type I error is 0.95. Assuming the tests are independent, the probability of not committing a Type I error on any of the five tests is (0.95)5 = 0.77378, and the probability of at least one Type I error is 1 – 0.77378 = 0.22622.
10. (E) No matter what the distribution of raw scores, the set of z-scores always has mean 0 and standard deviation 1.
11. (B) In the sampling distribution of x, the mean is equal to the population mean, and the standard deviation is equal to the population standard deviation divided by the
square root of the sample size, in this case, ![]()
12. (E) The standard deviation can never be negative.
13. (E) When a complete census is taken (all 423 seniors were in the study), the population proportion is known and a confidence interval has no meaning.
14. (E) The method described in (A) is a convenience sample, (B) and (C) are voluntary response surveys, and (D) suffers from undercoverage bias.
15. (D) Since each set is normally distributed so is the set of differences, X1 – X2. We calculate µx1 – x2 = 1758 – 1725 = 33 and ![]()
So ![]()
16. (E) With df = n – 1 = 10 – 1 = 9 and 95% confidence, the critical t-values are ±2.262.
Also ![]()
17. (A) ![]()
![]() , …, and we see that the distribution has its maximum value
, …, and we see that the distribution has its maximum value
at X = 1.
18. (B) The chi-square tests all involve counts, and comparing means doesn’t make sense in this context.
19. (A) The median of X is –2, and this is also true of distribution 1 (note that a horizontal line from 0.5 strikes curve 1 above –2 on the x-axis). Y has a smaller standard deviation than Z (tighter clustering around the mean), so Y must correspond to distribution 2, which shows almost all values are between –1 and 1.
20. (E)

21. (C) Adding the same constant to every value in a set adds the same constant to the mean but leaves the standard deviation unchanged. Multiplying every value in a set by the same constant multiplies the mean and standard deviation by that constant. So the new mean is 5/9 × (78.35 – 32) + 273 = 298.75, and the new standard deviation is 5/9 × 6.3 = 3.5.
22. (B) Design 2 is an example of a matched pairs design, a special case of a block design; here, each subject is compared to itself with respect to the two treatments. Both designs definitely use randomization with regard to assignment of treatments, but since they do not use randomization in selecting subjects from the general population, care must be taken in generalizing any conclusions. It’s not clear whether or not the researchers who do the observations and measurements know which treatment individual cows are receiving, so there is no way to conclude if there is or is not blinding. The two sources of BVH are different treatments, and so they are not being confounded. In both designs treatments are randomly applied, so neither is an observational study.
23. (A) The linear regression t-test has null hypothesis H0: $\beta$ = 0 that there is no linear relationship; if the P-value is small enough, then there is evidence of a linear association, that is, there is evidence that $\beta$ ≠ 0.
24. (A) We have a binomial distribution with mean ![]() Answer
Answer
(A) is the only reasonable choice.
25. (B) The size of the sample always matters; the larger the sample, the greater the power of statistical tests. One percent of a large population is large. Larger samples are better, but if the sample is greater than 10% of the population, the best statistical techniques are not those covered in the AP curriculum.
26. (E) The points on the scatterplot all fall on the straight line:
Female length = Male length + 0.5
27. (A) 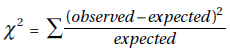 and expected are found by multiplying the proportions times the sample size of 100.
and expected are found by multiplying the proportions times the sample size of 100.
28. (D) The distributions in (A), (B), and (C) appear roughly symmetric, so the mean and median will be roughly the same. The distribution in (D) is skewed to the right, so the mean will be greater than the median, while the distribution in (E) is skewed to the left, so the mean will be less than the median.
29. (C) This is a binomial with n = 10 and p = 0.38, so the mean is np = 10(0.38) = 3.8.
30. (E) Answers (A), (B), and (C) are common misconceptions. Since the 95% confidence interval contains 80, a two-sided test would not be significant at the 5% significance level or lower. The interval can be expressed as 77.5 ± 3, that is, we are 95% confident that the true mean fastball speed is within 3 mph of 77.5 mph.
31. (A) Residual = Observed – Predicted, so 1.0 = 11 – Predicted and Predicted = 10.
32. (B) Stratified sampling is when the population is divided into homogeneous groups (the three Divisions in this example), and a random sample of individuals is chosen from each group.
33. (D) There are 8 outcomes {TTT, TTH, THT, THH, HTT, HTH, HHT, HHH}, so P(0 heads) = 1/8, P(1 head) = 3/8, P(2 heads) = 3/8, and P(3 heads) = 1/8. Thus, we assign one digit to the results of 0 heads and 3 heads and 3 digits to the results of 1 head and 2 heads and ignore the other 2 digits (of the 10 available digits).
34. (A) The margin of error, ![]() depends on the sample size, not the population size.
depends on the sample size, not the population size.
35. (B) We have (Q1 + Q3)/2 = 20 or Q3 + Q1 = 40, and Q3 – Q1 = 20, which algebraically gives Q1 = 10 and Q3 = 30 [add the equations to obtain 2Q3 = 60 so Q3 = 30; then plugging into either equation and solving for Q1 gives Q1 = 10].
36. (E) The larger the sample size, the closer the sample distribution is to the population distribution. The central limit theorem roughly says that if multiple samples of size n are drawn randomly and independently from a population, then the histogram of the means of those samples will be approximately normal. Statistics have probability distributions called sampling distributions. The standard error is based on the spread of the population and on the sample size. The central limit theorem does not apply to all statistics as it does to sample means. Many sampling distributions are not normal; for example, the sampling distribution of the sample max is not a normal distribution. An estimator of a parameter is unbiased if we have a method that, through repeated samples, is on average the same value as the parameter.
37. (A) With 0.068 in a tail, the confidence interval with 34 at one end would have a confidence level of 1 – 2(0.068) = 0.864, so anything higher than 86.4% confidence will contain 34.
38. (C) From a boxplot there is no way of telling if a distribution is bell-shaped (very different distributions can have the same five-number summary). Distribution I appears strongly skewed right, and so its mean is probably much greater than its median, while distribution II appears roughly symmetric, and so its mean is probably close to its median. The interquartile range, not the range, in I is 13.
39. (C) To make money, there must be more wins than losses, so with 50 plays, we need to calculate P(X > 25). We have a binomial distribution with n = 50 and probability of success p = 18/38. On a calculator such as the TI-84 we find P(X > 25) = 1 – P(X ≤ 25) = 1-binomcdf(50,18/38,25) = 0.303 [or on the Nspire: binomcdf(50,18/38,26,50)].
40. (B) 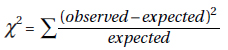 and cell calculations [expected value of a cell equals (row total)(column total)/(table total)] or $\chi$2-test on a calculator such as the TI-84 will yield expected cells of 29, 36, 35, 29, 36, 35.
and cell calculations [expected value of a cell equals (row total)(column total)/(table total)] or $\chi$2-test on a calculator such as the TI-84 will yield expected cells of 29, 36, 35, 29, 36, 35.
SECTION II
1. (a) There are 2 × 2 × 2 = 8 different treatments:
Two-day, aerobic, with adjuvant
Two-day, aerobic, without adjuvant
Two-day, anaerobic, with adjuvant
Two-day, anaerobic, without adjuvant
Five-day, aerobic, with adjuvant
Five-day, aerobic, without adjuvant
Five-day, anaerobic, with adjuvant
Five-day, anaerobic, without adjuvant
(b) We must randomly assign the treatment combinations to the beds. (Roses have already been randomly assigned to the beds.) With 8 treatments and 16 beds, each treatment should be assigned to 2 beds. For example, give each bed a random number between 1 and 16 (no repeats), and then assign the first treatment in the above list to the beds with the numbers 1 and 2, assign the second treatment in the above list to the beds with the numbers 3 and 4, and so on.
(c) Using only mini-pink roses in this experiment gives reduced variability and increases the likelihood of determining differences among the treatments.
(d) Using only mini-pink roses in this experiment limits the scope and makes it difficult to generalize the results to other species of roses.
SCORING
Part (a) is essentially correct for correctly listing all eight treatment combinations and is incorrect otherwise.
Part (b) is essentially correct if each treatment combination is randomly assigned to two beds of roses. Part (b) is partially correct if each treatment is randomly assigned to two beds but the method is unclear, or if a method of randomization is correctly described but the method may not assure that each treatment is assigned to two beds.
Part (c) is essentially correct for noting reduced variability and for explaining that this increases likelihood of determining differences among the treatments. Part (c) is partially correct for only one of these two components.
Part (d) is essentially correct noting limited scope and for explaining that this makes generalization to other species difficult. Part (d) is partially correct for only one of these two components.
Count partially correct answers as one-half an essentially correct answer.
4 Complete Answer | Four essentially correct answers. |
3 Substantial Answer | Three essentially correct answers. |
2 Developing Answer | Two essentially correct answers. |
1 Minimal Answer | One essentially correct answer. |
Use a holistic approach to decide a score totaling between two numbers.
TIP
Graders want to give you credit. Help them! Make them understand what you are doing, why you are doing it, and how you are doing it. Don’t make the reader guess at what you are doing. Communication is just as important as statistical knowledge!
2. Part 1: State the correct hypotheses.
H0 : µ = 82 and Ha : µ > 82
Part 2: Identify the correct test and check appropriate conditions.
One-sample ![]()
Conditions: Random sample (given), n = 47 is less than 10% of all possible swings with the new racquet, and n = 47 is sufficiently large for the CLT to apply.
Part 3: Calculate the test statistic t and the P-value.
Calculator software (such as T-Test on the TI-84) gives t = 3.0246 and P = 0.00203.
Part 4: Give a conclusion in context with linkage to the P-value.
With this small a P-value, 0.00203 < 0.05, there is sufficient evidence to reject H0, that is, there is sufficient evidence that his mean speed with the new racquet is an improvement over the old.
SCORING
Part 1 either is essentially correct or is incorrect.
Part 2 is essentially correct if the test is correctly identified by name or formula and the assumptions are checked. Part 2 is partially correct if only one of these two elements is correct.
Part 3 is essentially correct if the t-value and p are stated. Part 3 is partially correct if only one of these two elements is correct.
Part 4 is essentially correct if the correct conclusion is given in context and the conclusion is linked to the p-value. Part 4 is partially correct if the correct conclusion is given in context but there is no linkage to the p-value.
Count partially correct answers as one-half an essentially correct answer.
4 Complete Answer | Four essentially correct answers. |
3 Substantial Answer | Three essentially correct answers. |
2 Developing Answer | Two essentially correct answers. |
1 Minimal Answer | One essentially correct answer. |
Use a holistic approach to decide a score totaling between two numbers.
3. (a) Chi-square goodness-of-fit test
(b) H0: The new freshman class is distributed 2.7% non-Hispanic Black, 3.7% Asian or Pacific Islander, 4.0% Hispanic, 80.0% non-Hispanic White, and 9.6% other/unknown.
Ha: The new freshman class has a distribution different from that in October 2008.
Randomization is given and the expected cell frequencies—2.7% × 200 = 5.4, 3.7% × 200 = 7.4, 4.0% × 200 = 8.0, 80.0% × 200 = 160.0, and 9.6% × 200 = 19.2—are all at least 5.
(c)![]()
with df = 5 – 1 = 4, and a P-value of 0.013. With such a small P-value, 0.013 < 0.05, there is evidence to reject H0 and conclude that there is statistical evidence of a change in ethnic/racial composition.
(d) No, this test/procedure targeted students visiting the campus, and such students might be different from the targeted population of students making up the new freshman class. For example, some students who eventually make up the freshman class might not have the funds or the time to visit the campus. Or it can be argued that even if all potential students do visit the campus, there is no reason to conclude that the distribution of visiting students is the same as the distribution of students who both are accepted and decide to attend this college.
SCORING
Part (a–b) is essentially correct if the correct test is named, the hypotheses are correctly stated, and the assumption of all expected cell frequencies being at least five is checked. Part (a–b) is partially correct if only two of these three elements are correct. Part (a–b) is incorrect if only one of these three elements is correct.
Part (c1) is essentially correct if the chi-square value is calculated and both df and p are stated. Part (c1) is partially correct if only one of these two elements is correct.
Part (c2) is essentially correct if the correct conclusion is given in context and the conclusion is linked to the p-value. Part (c2) is partially correct if the correct conclusion is given in context but there is no linkage to the p-value.
Part (d) is essentially correct or incorrect. It is essentially correct for both stating that the intended population is not targeted and giving a clear argument for this answer.
Count partially correct answers as one-half an essentially correct answer.
4 Complete Answer | Four essentially correct answers. |
3 Substantial Answer | Three essentially correct answers. |
2 Developing Answer | Two essentially correct answers. |
1 Minimal Answer | One essentially correct answer. |
Use a holistic approach to decide a score totaling between two numbers.
4. (a) ![]()
(b) P(at least 3 out of 5 are > 2400) = 10(0.258)3(0.742)2 + 5(0.258)4(0.742) + (0.258)5 = 0.112
[On the TI-84, 1 – binomcdf(5,0.258,2) = 0.112]
(c) The distribution of $\overline{x}$ is normal with mean $\mu_\overline{x}$= 2317 and standard deviation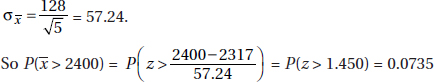
SCORING
Part (a) is essentially correct if the correct probability is calculated and the derivation is clear. Simply writing normalcdf(2400,$\infty$,2317,128) = 0.258 is a partially correct response.
Part (b) is essentially correct if the correct probability is calculated and the derivation is clear. Part (b) is partially correct for indicating a binomial with n = 5 and p = answer from (a) but calculating incorrectly. Simply writing 1-binomcdf(5,.258,2) = 0.112 is also a partially correct response.
Part (c) is essentially correct for specifying both $\mu_\overline{x}$ and $\sigma_\overline{x}$ and correctly calculating the probability. Part (c) is partially correct for specifying both $\mu_\overline{x}$ and $\sigma_\overline{x}$ but incorrectly calculating the probability, or for failing to specify both $\mu_\overline{x}$ and $\sigma_\overline{x}$ but correctly calculating the probability.
4 Complete Answer | All three parts essentially correct. |
3 Substantial Answer | Two parts essentially correct and one part partially correct. |
2 Developing Answer | Two parts essentially correct OR one part essentially correct and one or two parts partially correct OR all three parts partially correct. |
1 Minimal Answer | One part essentially correct OR two parts partially correct. |
5. (a) $\sum$ xP(x) = 135p + (–35)(1 – p) = –35 + 170p
(b) $\sum$ xP(x) = (–5)p + 25(1 – p) = 25 – 30p
(c) –35 + 170p = 25 – 30p gives p = 0.3. When p > 0.3, the expected return for oil paintings is greater than that for finger paintings, and when p < 0.3, the expected return for finger paintings is greater than for oil paintings. (These statements follow from the positive slope of R = –35 + 170p and the negative slope of R = 25 – 30p.)
(d) First, name the confidence interval: a 95% confidence interval for the proportion p of similar establishments with tourists who were primarily art collectors.
Second, check conditions: We are given that this is a random sample, it is reasonable to assume that the sample is less than 10 percent of all similar establishments, and the sample size is large enough (np = 33 and n(1 – p) = 117 are both greater than 10).
Third, correct mechanics: calculator software (such as 1-PropZInt on the TI-84) gives (0.154, 0.286).
Fourth, interpret in context: We are 95% confident that the true proportion of similar establishments with tourists who were primarily art collectors is between 0.154 and 0.286.
(e) The entire interval in (d) is below p = 0.3, so based on (c), the expected return for finger paintings is greater than for oil paintings for all p in this interval.
SCORING
Parts (a) and (b) are scored together. They are essentially correct if both answers are correct and partially correct if one answer is correct.
Part (c) is essentially correct for a correct calculation of the intersection together with a correct conclusion of what it means when p is greater or less than 0.3. Part (c) is partially correct if the intersection is not correctly calculated, but the conclusions are correct based on the incorrect intersection value.
Part (d) is essentially correct if steps 2, 3, and 4 are correct. (Step 1 is only a restatement from the question.) Part 3 is partially correct if only two of these three steps are correct.
Part (e) is essentially correct if the correct conclusion is given with clear linkage to the results from both (c) and (d). Part (e) is partially correct if the explanation of the linkage is present but weak.
Give 1 point for each essentially correct part and one-half point for each partially correct part.
4 Complete Answer | 4 points |
3 Substantial Answer | 3 points |
2 Developing Answer | 2 points |
1 Minimal Answer | 1 point |
Use a holistic approach to decide a score totaling between two numbers.
TIP
Read carefully and recognize that sometimes very different tests are required in different parts of the same problem.
Section II
Part B
6. (a) Salary and years of experience exhibit an approximately linear relationship. As years of experience increase, so does the median salary. The third-quartile, Q3, salary also increases with years, and so does the Q1 salary with the exception of one year. As years of experience increase, there are only minor differences in measures of variability in the salaries, with roughly the same range (except for the last two) and fairly consistent interquartile ranges.
(b) First, the boxplots indicate that an overall scatterplot pattern would be roughly linear. Second, the residual plot shows no pattern. Third, the histogram of residuals appears roughly normal (unimodal, symmetric, and without clear skewness or outliers).
(c) With df = 98 and 0.025 in each tail, the critical t-values are ±1.984.
b1 ± tsb1 = 0.910 ± 1.984(0.03273) = 0.910 ± 0.065. We are 95% confident that for each additional year of experience, the average increase in salary is between \$845 and \$975.
(d) The sum and thus the mean of the residuals is always 0. The standard deviation of the residuals is $\sigma$, which can be estimated with s = 0.9402. With a roughly normal distribution, we have P(X $\geq$ 1) = 0.14.
SCORING
Part (a) is essentially correct for correctly noting a linear relationship, noting that as years of experience increase so does the median salary (or Q3 or generally Q1), and noting that measures of variability (range or IQR) stay roughly the same. Part (a) is partially correct for correctly noting two of the three features.
Part (b) is essentially correct for noting the three conditions (roughly linear scatterplot, no pattern in the residual plot, and roughly normal histogram of residuals). Part (b) is partially correct for correctly noting two of the three conditions.
Part (c) is essentially correct for both a correct calculation of the confidence interval and a correct interpretation in context. Part (c) is partially correct for a correct calculation without the interpretation in context, or for a correct interpretation based on an incorrect calculation.
Part (d) is essentially correct noting that the distribution of residuals is roughly normal with mean 0 and standard deviation 0.9402, and then using this to correctly calculate the probability. Part (d) is partially correct for correctly noting the distribution of residuals but incorrectly calculating the probability, or for making a calculation based on a normal distribution with mean 0 but using an incorrect standard deviation.
Count partially correct answers as one-half an essentially correct answer.
4 Complete Answer | Four essentially correct answers. |
3 Substantial Answer | Three essentially correct answers. |
2 Developing Answer | Two essentially correct answers. |
1 Minimal Answer | One essentially correct answer. |
Use a holistic approach to decide a score totaling between two numbers.
Note in which Themes your missed questions fall. Then give special note to the Topics corresponding to the missed questions. Additionally, whenever you wish to test yourself on a particular Theme, go back to the designated questions.
Theme One: Exploratory Analysis
Question 1 | Topic Five: Exploring Categorical Data |
Question 6 | Topic Four: Exploring Bivariate Data |
Question 10 | Topic Two: Summarizing Distributions |
Question 12 | Topic Two: Summarizing Distributions |
Question 19 | Topic One: Graphical Displays |
Question 21 | Topic Two: Summarizing Distributions |
Question 26 | Topic Four: Exploring Bivariate Data |
Question 28 | Topic One: Graphical Displays |
Question 31 | Topic Four: Exploring Bivariate Data |
Question 35 | Topic Two: Summarizing Distributions |
Question 38 | Topic One: Graphical Displays |
Theme Two: Planning a Study
Question 5 | Topic Seven: Planning and Conducting Surveys |
Question 14 | Topic Seven: Planning and Conducting Surveys |
Question 22 | Topic Eight: Planning and Conducting Experiments |
Question 25 | Topic Seven: Planning and Conducting Surveys |
Question 32 | Topic Seven: Planning and Conducting Surveys |
Theme Three: Probability
Question 3 | Topic Nine: Probability as Relative Frequency |
Question 9 | Topic Nine: Probability as Relative Frequency |
Question 11 | Topic Twelve: Sampling Distributions |
Question 15 | Topic Ten: Combining Independent Random Variables |
Question 17 | Topic Nine: Probability as Relative Frequency |
Question 19 | Topic Eleven: The Normal Distribution |
Question 20 | Topic Nine: Probability as Relative Frequency |
Question 24 | Topic Nine: Probability as Relative Frequency |
Question 29 | Topic Nine: Probability as Relative Frequency |
Question 33 | Topic Nine: Probability as Relative Frequency |
Question 36 | Topic Twelve: Sampling Distributions |
Question 39 | Topic Nine: Probability as Relative Frequency |
Theme Four: Statistical Inference
Question 2 | Topic Thirteen: Confidence Intervals |
Question 4 | Topic Fourteen: Tests of Significance—Proportions and Means |
Question 7 | Topic Fourteen: Tests of Significance—Proportions and Means |
Question 8 | Topic Fourteen: Tests of Significance—Proportions and Means |
Question 9 | Topic Fourteen: Tests of Significance—Proportions and Means |
Question 13 | Topic Thirteen: Confidence Intervals |
Question 16 | Topic Thirteen: Confidence Intervals |
Question 18 | Topic Fifteen: Tests of Significance—Chi-Square and Slope of Least Squares Line |
Question 23 | Topic Fifteen: Tests of Significance—Chi-Square and Slope of Least Squares Line |
Question 27 | Topic Fifteen: Tests of Significance—Chi-Square and Slope of Least Squares Line |
Question 30 | Topic Thirteen: Confidence Intervals |
Question 34 | Topic Thirteen: Confidence Intervals |
Question 37 | Topic Thirteen: Confidence Intervals |
Question 40 | Topic Fifteen: Tests of Significance—Chi-Square and Slope of Least Squares Line |